大数据团队每天处理数亿条访问日志,每条日志都需要解析IP归属地用于用户画像和风控审计。在线API方案受限于QPS和网络延迟,不仅成本高昂,还无法满足海量数据的处理需求。IP数据云专注于为大数据场景提供高性能本地方案,通过将全球IP归属地数据打包成可私有化部署的文件,帮助企业实现毫秒级批量查询,单机日处理能力突破10亿次,同时确保数据不出内网、满足合规要求。

一、为什么本地方案是大数据IP解析的首选?
|------|-------------------|------------|
| 对比维度 | 在线API | 本地方案 |
| 处理能力 | 受限于QPS,日处理千万级已到极限 | 单机日处理10亿+ |
| 延迟 | 单次30-80ms,批量需串行 | 批量并行微秒级 |
| 成本 | 按次计费,亿级调用年费数百万 | 固定授权,量越大越省 |
| 数据安全 | IP外发第三方 | 内网闭环 |
| 网络依赖 | 必须公网 | 零依赖 |
在线API适合低频、实时单次查询;但面对TB级日志分析,本地方案才是正确选择。
二、技术方案:如何用本地库批量解析日志
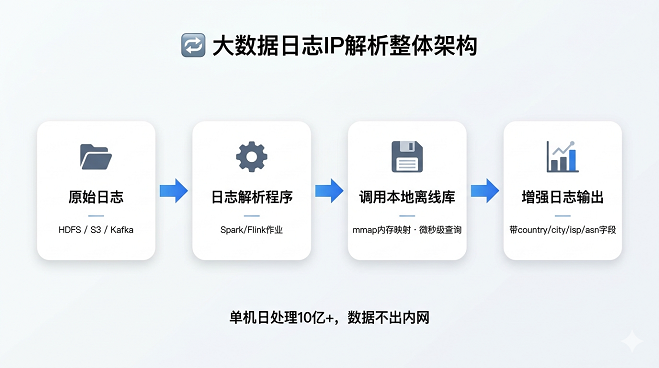
2.1 整体架构
原始日志(HDFS/S3) → 日志解析程序 → 调用本地库 → 输出带归属地的增强日志核心思路:在数据处理管道中嵌入本地查询,将IP字段替换为country|province|city|isp|asn等结构化字段。
2.2 数据准备:获取本地文件
下载IP离线数据库(.mmdb格式,约数百MB),部署到Hadoop/Spark集群的所有节点,或放在共享存储中。
2.3 代码实现:Spark批量解析示例
from pyspark.sql import SparkSession
import ipdatacloud_sdk
# 初始化本地库(在每个Executor中加载一次)
def init_ip_db():
# 使用 IP数据云 离线库,加载本地 mmdb 文件
return ipdatacloud_sdk.load("/data/ipdb/ip_data_cloud.mmdb", enable_risk=True)
# 解析UDF
def parse_ip(ip):
db = init_ip_db() # 实际应用可做单例缓存
info = db.query(ip)
return (info.get("country"), info.get("province"), info.get("city"),
info.get("isp"), info.get("asn"), info.get("risk_score"))
spark = SparkSession.builder.appName("IPBatchAnalysis").getOrCreate()
# 注册UDF
spark.udf.register("parse_ip", parse_ip,
StructType([StructField("country", StringType()), ...]))
# 读取日志,批量解析
df = spark.read.parquet("/log_data/day=20260515")
df_enhanced = df.select("ip", parse_ip("ip").alias("ip_geo"), "*")
df_enhanced.write.parquet("/output/enriched_logs")关键点:本地库在每个Executor内存中独立加载,查询完全本地化,无网络开销。
2.4 性能调优技巧
|--------|-------------------|-------------|
| 优化项 | 方法 | 预期效果 |
| 预加载到内存 | 使用mmap将数据库文件映射到内存 | 查询延迟<0.5ms |
| 分区并行 | Spark分区数=CPU核心数×2 | 充分利用并发 |
| 缓存热点结果 | 对重复IP使用本地字典缓存 | 命中率>80% |
| 列式存储 | 输出Parquet/ORC格式 | 减少IO,加速下游分析 |
三、实际案例:某广告平台的日志分析
某广告技术公司每日处理约8亿次曝光日志,需要将IP映射到城市用于投放归因。原使用在线API,日均成本超2万元,且因限流导致延迟积压。切换到本地方案后:
|--------|---------------|---------------|
| 指标 | 优化前(在线API) | 优化后(本地方案) |
| 日处理日志量 | 3亿条(受限于API配额) | 8亿条 |
| 单条解析耗时 | 50ms(含网络) | 0.25ms |
| 单日成本 | 2.1万元 | 固定授权,日均<500元 |
| 数据安全 | IP外发,合规风险 | 内网闭环,无风险 |
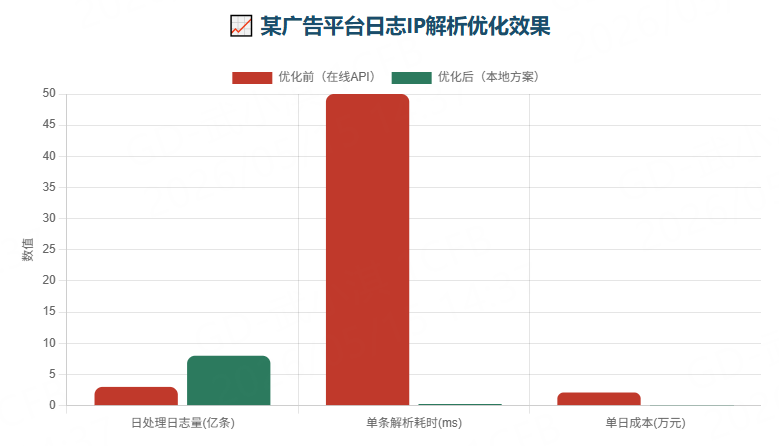
关键收益:成本下降95%,处理能力提升2.7倍,且通过银保监会数据安全审计。
四、选型与落地检查清单
- 数据覆盖:本地库是否包含IPv4和IPv6?
- 更新频率:是否支持日更?黑产IP段变化快,周更可能滞后。
- 性能指标:单机QPS是否>100万?P99延迟<1ms?
- 字段丰富度:是否提供
- 部署方式:是否支持内网私有化?能否直接集成到Spark/Flink?
满足以上条件,才适合大数据场景。
五、总结
大数据环境下,日志IP解析不应依赖在线API。IP数据云的本地方案将查询能力下沉到计算节点本地,实现微秒级解析、线性扩展和成本可控。通过Spark/Flink等计算引擎集成,单集群每日可处理数十亿条日志,同时保障数据不出内网、满足合规要求。从TB级日志到实时流处理,该方案是大数据工程师提升IP解析效率的可靠选择。