我承认,我之前搞 AI 应用的时候,有很长一段时间陷入了一个特别傻的误区。
就是觉得啊,这玩意儿拼的就是模型能力。谁的模型强,谁就赢麻了。所以我就天天盯着各大厂商的参数对比,ChatGPT又更新了,Claude又变强了,DeepSeek又开源了,搞得跟军备竞赛似的。
结果呢?
模型换了七八个,应用做了一大堆,全是本地跑得欢,一部署就拉胯。
这个坑,我踩了挺久。所以今天这篇文章,我想聊聊我最近终于跑通的一条路,就是怎么用 Dify 搭智能分析工作流,再用 EdgeOne 把它变成真正能对外服务的在线系统。
不画饼,直接上干货。
目录
[Python 节点:几行代码定胜负](#Python 节点:几行代码定胜负)
[EdgeOne 部署:让工作流真正上线](#EdgeOne 部署:让工作流真正上线)
[第一步:获取 Dify API Key](#第一步:获取 Dify API Key)
[第二步:在 EdgeOne 创建 AI 应用](#第二步:在 EdgeOne 创建 AI 应用)
财经分析的真正痛点
财经分析这事儿,说起来简单,做起来真尼玛吐血。
市场上的信息从来不缺。宏观政策、行业新闻、上市公司公告、财务数据、市场情绪,每天都在快速更新。真正困难的地方在于,信息彼此分散,噪声远远大于有效内容。
研究者往往需要在多个网站之间来回切换,不断检索、筛选、记录,再手动整理成完整的分析逻辑。这个过程耗时且低效。
我想解决的问题很简单,就是能不能让 AI 像一个真正的研究员一样,一步一步地推进分析,而不是扔一个问题出去就完事了?
你问它「分析某新能源汽车企业近期的供应链风险」,它可能返回给你一堆碎片:
电池原材料价格上涨;
某供应商产能下降;
企业库存水平增加。
这些信息都有价值,但问题在于,它们之间没有自动建立联系。第一条和第三条是什么关系?原材料上涨会不会传导到库存策略的调整?这些都需要人去做判断。
所以我想要的不是「会搜索」,而是「会分析」。
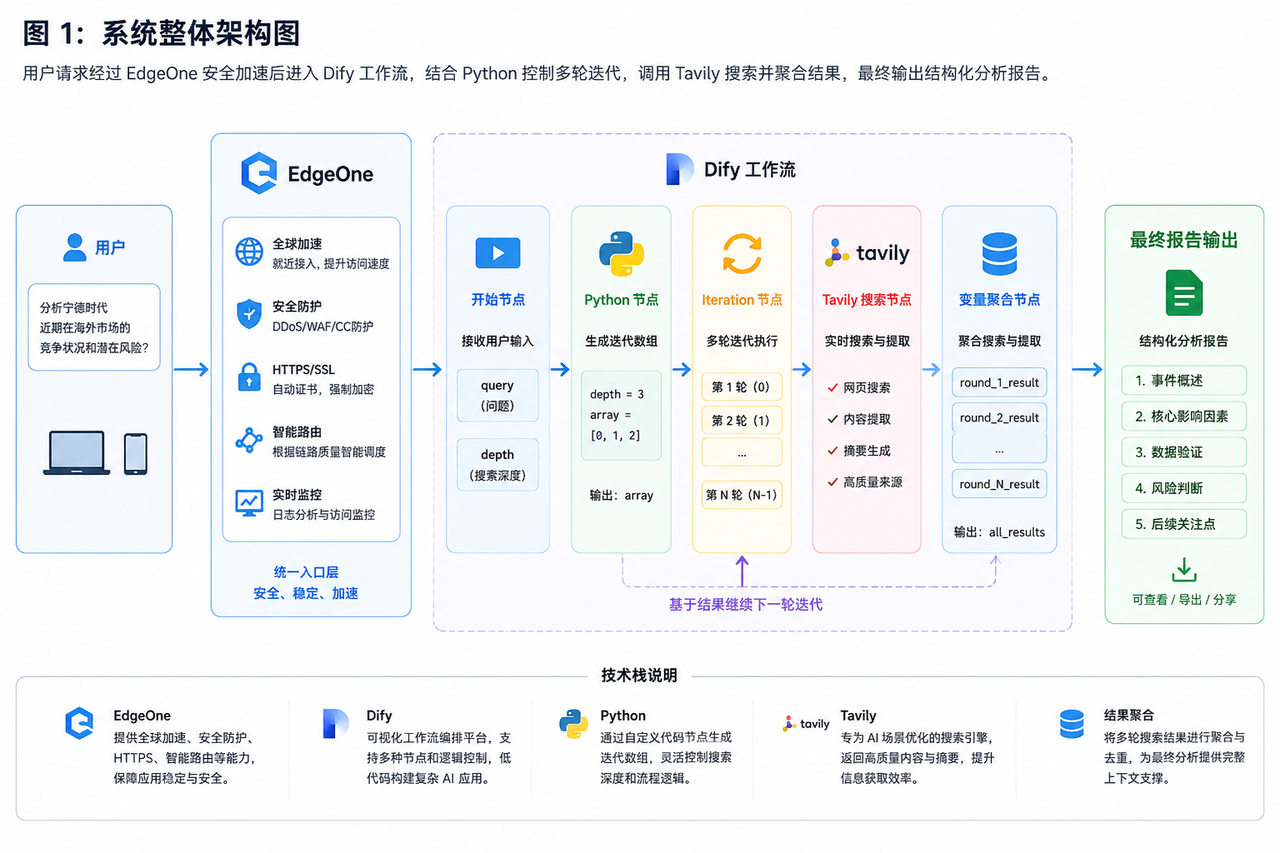
系统架构:像研究员一样工作
我搭建的系统,大概是这样的思路。
用户提出一个问题,系统接收后,不是直接去搜索,而是先理解问题的深度,然后按照设定的轮数,一轮一轮地执行多轮搜索。每轮搜索的结果会持续保存,后续轮次基于已有的信息继续追踪,最终生成一份结构化的研究报告。
整个流程大概是:
听起来有点复杂对吧?但实际上,把它拆开来看,每个环节都挺简单的。
Dify:工作流的调度核心
Dify 是整个系统的调度核心。我把工作流拆成了几个节点:
开始节点负责接收问题与搜索深度;
Python 节点生成迭代数组;
Iteration 节点控制多轮循环;
Tavily 搜索节点获取实时信息;
变量聚合节点保存上下文;
最终整理节点生成研究报告;
最后通过回复节点输出结果。
这种模块化设计的优势在于,逻辑清晰,可维护性高,以后想加新功能也方便。
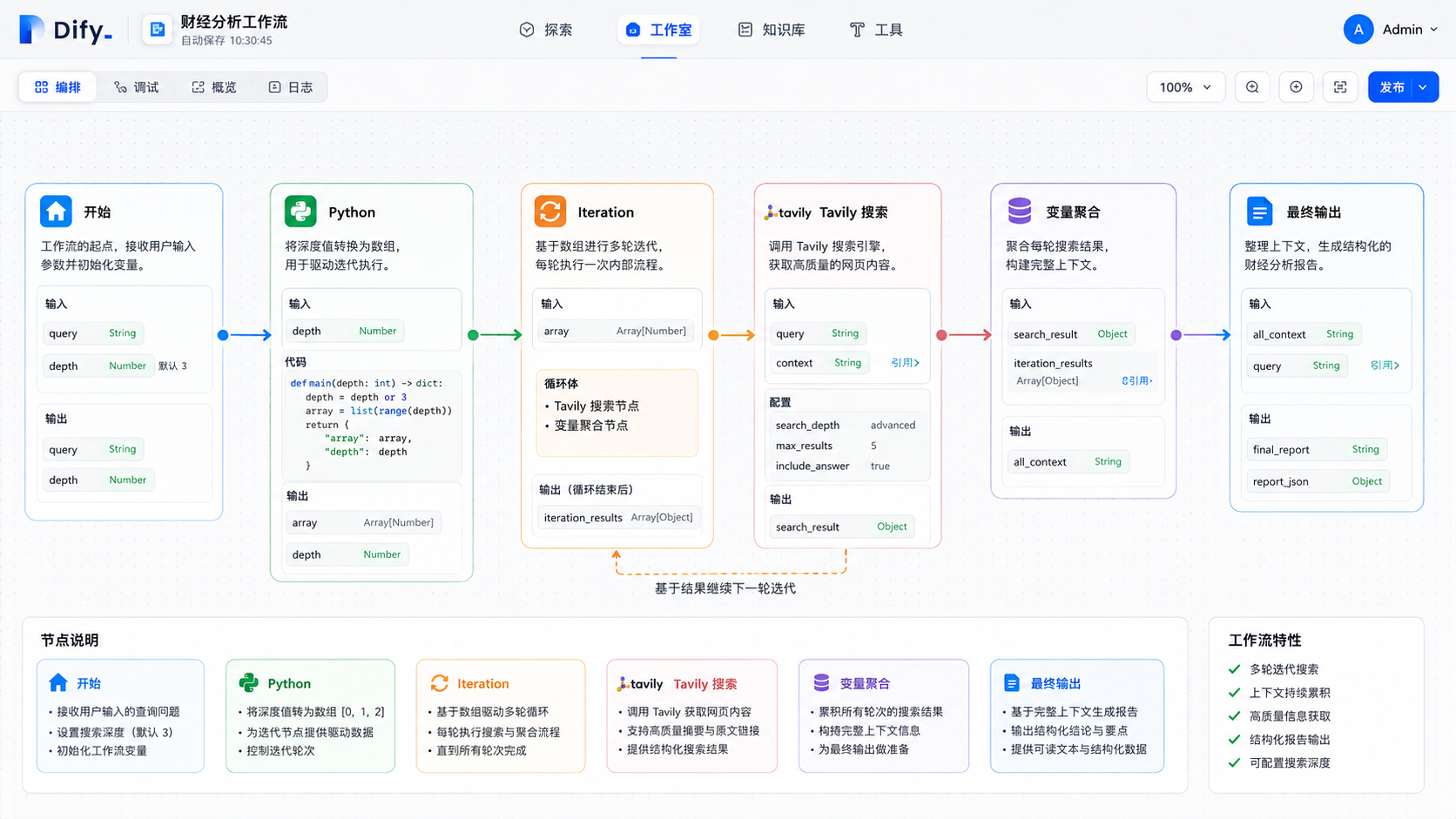
Python 节点:几行代码定胜负
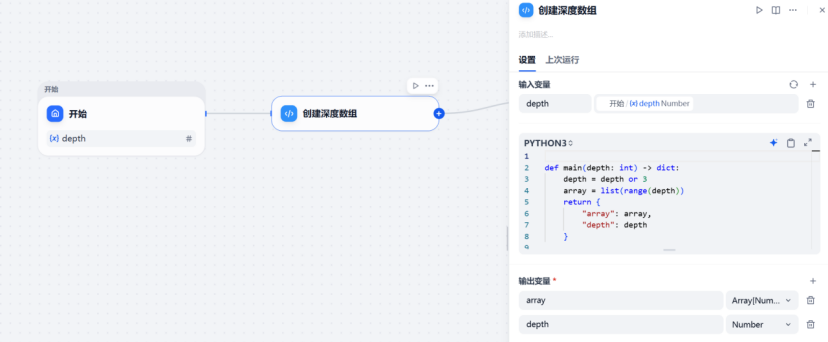
Python 节点这里其实就几行代码的事情。因为 Iteration 节点需要数组作为输入,所以必须先把用户输入的搜索轮数转换成列表。
def main(depth: int) -> dict:
depth = depth or 3
array = list(range(depth))
return {
"array": array,
"depth": depth
}如果用户输入 3,系统会生成 0, 1, 2,工作流就会执行三轮搜索。
这几行代码确实非常简单,但它决定了整个系统是否具备真正的迭代能力。没有这一步,后面的多轮分析就无从谈起。
搜索与聚合:让信息真正有用
Tavily:搜索结果不用再清洗
Tavily 这个工具,我一开始用的时候其实挺怀疑的。
因为在信息密集型场景中,最大的成本不是搜索,而是清洗搜索结果。普通搜索往往包含大量重复转载、标题党内容、低质量论坛讨论、缺乏来源的观点。这些玩意儿搜出来容易,但你真要用的时候,筛选成本比不用搜索还高。
Tavily 解决的是这个问题。它返回的并不是简单链接,而是经过处理后的核心摘要与来源信息。这意味着系统可以直接使用这些结果,而不必再进行大量手工筛选。
在财经分析中,这一点尤其重要。
变量聚合:让每轮搜索都成为下一步的基础
然后是变量聚合。这个节点做的事情,就是把每轮搜索的结果统一保存。
你想想看,如果每轮搜索彼此独立,那多轮执行就失去了意义。第一轮记录事件背景,第二轮补充数据证据,第三轮交叉验证,最终整理成完整结论。这样系统就能够持续积累上下文,而不是每次都重新开始。
这整个过程,特别像研究员不断完善自己的笔记。第一轮写得很粗,第二轮加了数据,第三轮做了交叉验证,到最后,笔记变成了报告。
最终输出:结构化研究报告
当迭代结束后,系统会对全部信息进行统一整理。输出结构大概是:
事件背景;
核心影响因素;
数据验证;
风险评估;
后续关注点。
这种结构和专业研究报告的逻辑非常接近。用户看到的结果,不再是简单的搜索摘要,而是一篇具有完整分析链条的研究内容。

好,上面说的这些,在本地跑其实已经挺顺畅了。但我真正的目标,并不是做一个只能自己使用的 Demo。
这时候问题就来了:
用户访问速度不稳定;
HTTPS 配置复杂;
接口容易遭到恶意请求;
缺少统一入口;
源站压力过大。
这些问题,并不是 Dify 或搜索工具本身能够解决的。所以我引入了腾讯云 EdgeOne,作为整个系统的入口层。
EdgeOne 部署:让工作流真正上线
第一步:获取 Dify API Key
让工作流真正具备上线能力,需要解决几个关键问题。
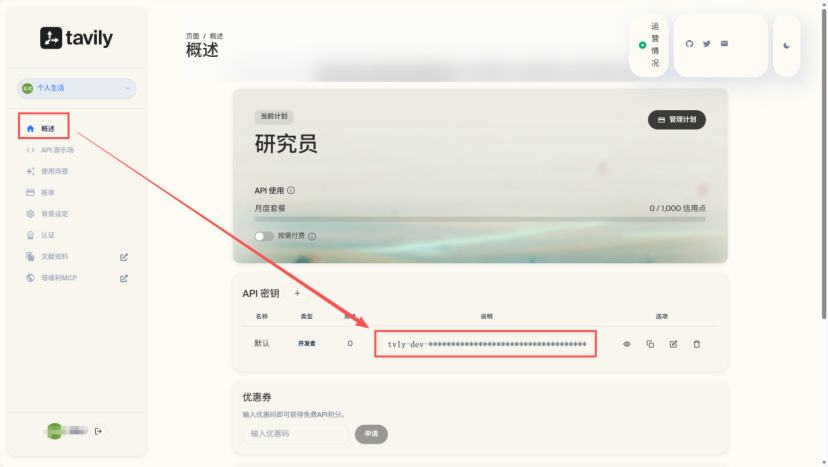
第一步,在 Dify 中获取 API Key。打开对应的应用,进入 API 访问页面,就能看到系统自动生成的访问凭证。需要获取的主要是 API Key 和 API Endpoint,也就是工作流的访问地址。
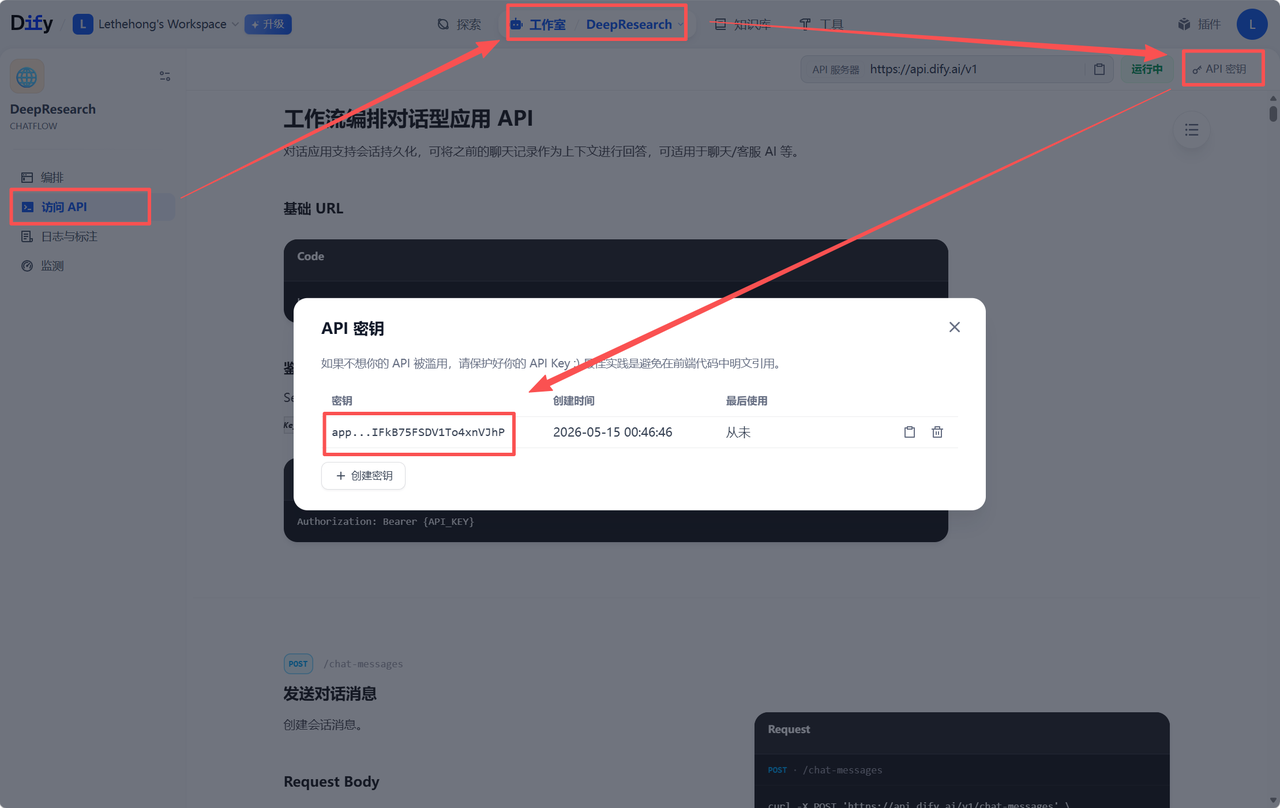
这两项信息相当于连接 Dify 工作流与 EdgeOne 的「桥梁」,后续部署时必须填进去。
第二步:在 EdgeOne 创建 AI 应用
第二步,在 EdgeOne 中创建 AI 应用。登录腾讯云 EdgeOne 控制台,选择 AI 应用部署(不同版本界面名称可能略有差异),新建一个应用实例。
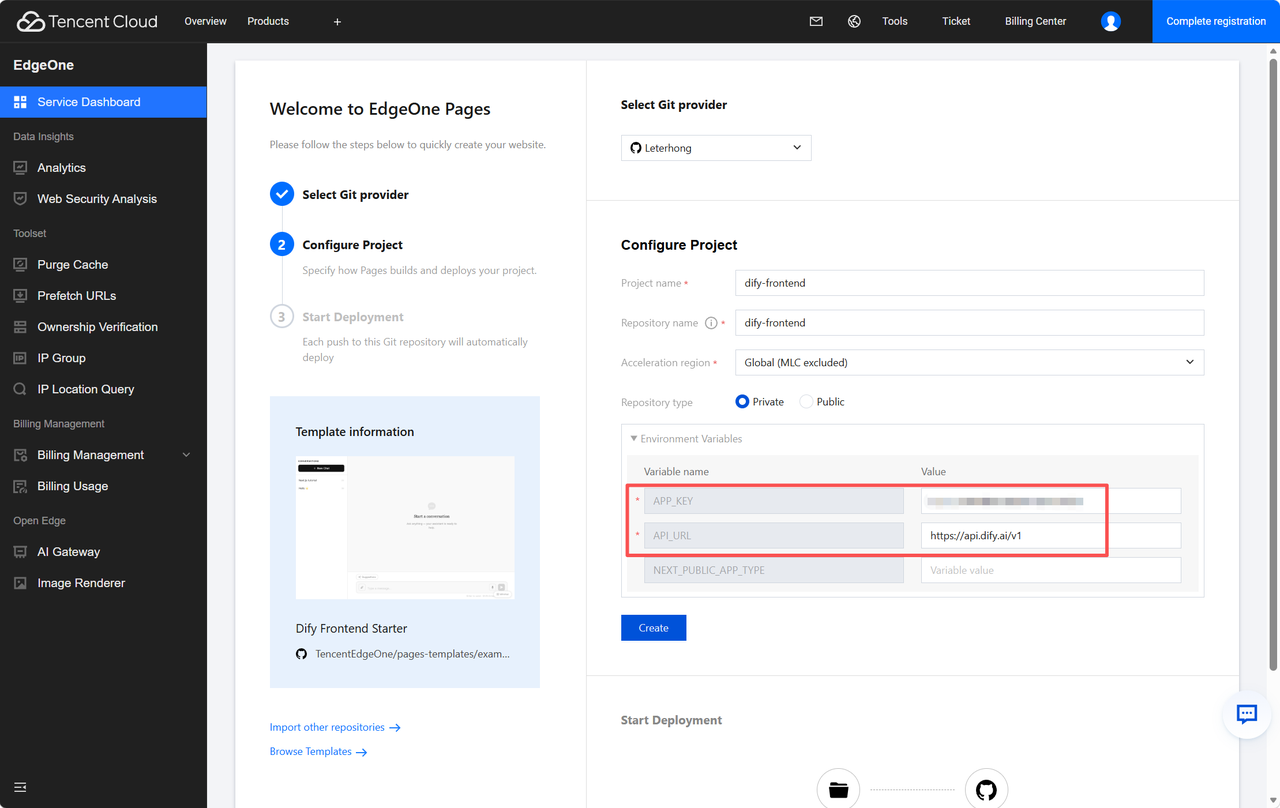
创建过程中需要填写 Dify 的 API 地址和密钥。填完之后点击部署,剩下的事情 EdgeOne 会自动搞定。
第三步:等待自动部署完成
第三步,等待自动部署完成。点击部署后,EdgeOne 会自动完成这些操作:
创建公网访问入口;
配置 HTTPS 证书;
启用全球边缘加速;
开启 Web 应用防火墙(WAF);
配置 DDoS 与 CC 防护;
建立到 Dify 的安全回源。
整个过程通常只需要几十秒到几分钟。部署完成后,控制台状态会显示为「已部署(Running)」,同时系统会生成一个可直接访问的在线地址。
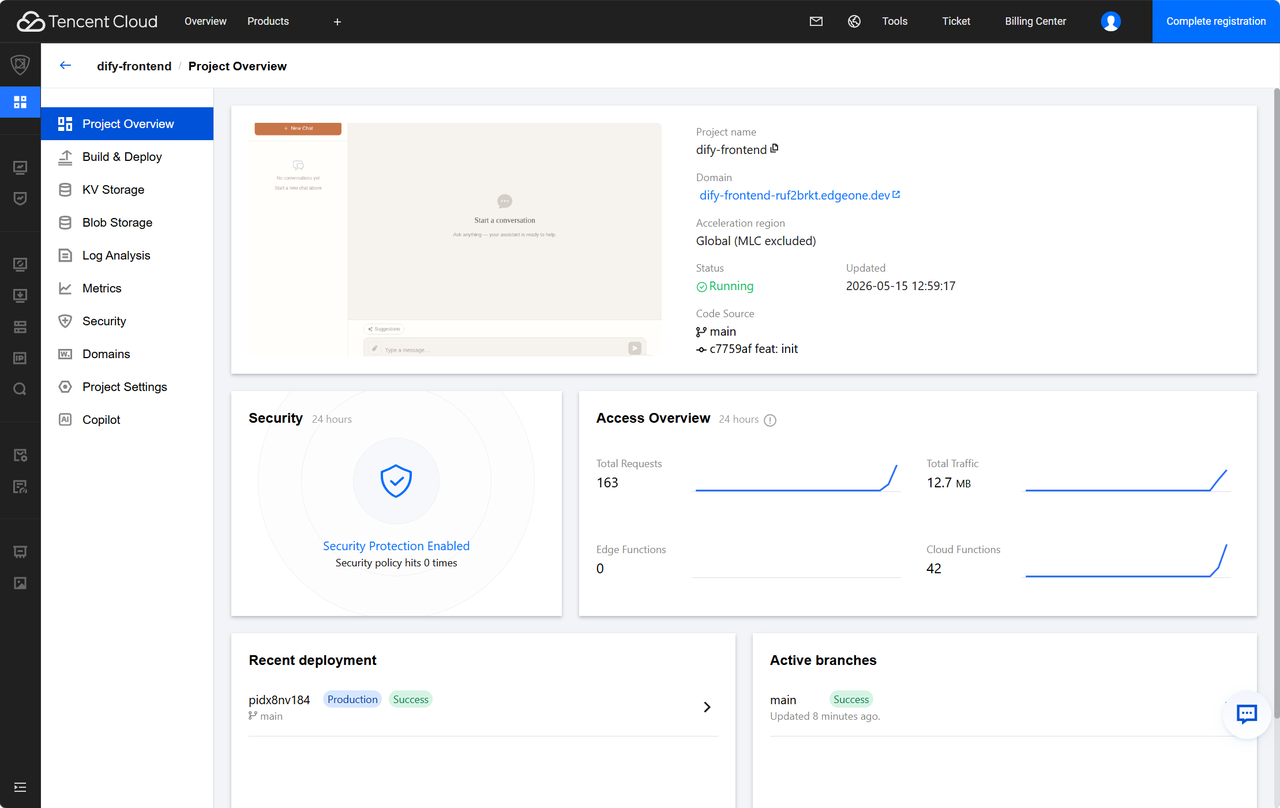
部署成功后,用户就可以通过这个地址直接访问智能财经分析系统了。访问后能看到完整的交互界面,输入问题就能触发 Dify 工作流,自动完成多轮搜索、信息聚合、风险分析和报告生成。
整个调用过程对用户完全透明。用户看到的是一个稳定、安全且响应迅速的在线应用,而不是底层复杂的工作流编排系统。
总结
说真的,完成这个项目之后,我最大的体会是:
工作流 决定了应用「能做什么」;而基础设施决定了应用「能否真正被使用」。
Dify 让我能够快速构建复杂逻辑;Tavily 帮我解决信息获取问题;Python 提供了灵活的控制能力;EdgeOne 则让这一切具备了稳定交付的可能。
四者结合之后,这套系统才真正成为一个完整的产品。
从一次简单的搜索,到多轮自动分析;
从本地 Demo,到可公开访问的在线系统;
从功能验证,到稳定交付。
这次实践让我更加确信,AI 应用的落地,拼的从来不只是模型能力,而是整体工程能力。
如果说 Dify 让我们以极低门槛构建复杂工作流,那么 EdgeOne 则让这些工作流真正拥有面向用户的能力。
对于希望把 AI 应用投入真实场景的开发者来说,Dify 与 EdgeOne 的组合,确实是一条非常值得尝试的实践路径。
以上就是我这段时间的一些摸索,可能有些想法还不成熟,如果你有更好的思路,欢迎交流。
感谢你看完这篇文章,如果觉得不错,随手点个赞、在看、转发三连吧。