上一篇 SDD 系列收尾时,留了一句话:"如何驾驭 AI 来赋能整个软件开发周期,将是另外一个值得深入探讨的话题。" 到现在有将近一个月没更新!期间除了偷懒,五一跑高速添堵之外,主要的原因是这个问题没怎么想透。SDD 解决了"怎么让 AI 尽可能准确地完成一个开发任务"的问题,但"整个开发周期"呢?这个月一直在薅那稀疏的头发,也一直在实际项目里摸索着。
从今年3月份开始,有一个词开始反复出现 ------ 不管是在顶级博客、行业文章、集团大会还是内部分享汇报里,这个词叫 Harness Engineering。
有意思的是,每个人所说的 Harness Engineering 好像听起来都不太一样。
一、不确定性的来源变了
SDD 系列解决的是一个相对"小"的问题:怎么让 AI 确定性地完成一个任务 ------用 Spec 约束意图,再由 AI 验证 AI 生成的结果。初步的实践数据看起来还行。但一个任务搞定了,整个开发周期呢?测试谁来写?验证谁来做?架构怎样确保?代码腐化谁来管?如何持续改进?这些问题 SDD 没回答,因为它们本来就不在"单任务"的范围内。
回头想想,这些焦虑的本质可能指向同一个问题:软件工程一直在跟不确定性作斗争,但这次不确定性的来源变了。
-
• 软件工程从来都不是"天然确定"的 ------ 需求会变、并发会冲突、网络会抖动、分布式系统会脑裂。软件工程的本质工作,恰恰是用工程化手段(锁、类型系统、测试、CI/CD、一致性协议)把这些不确定性驯服为可预测的确定性结果。说白了就是:同样的输入 + 同样的初始状态 = 必须得到同样的输出。
-
• 而LLM 的本质是概率性输出 ------同一个 prompt 跑两次,结果可能不同。以前的不确定性在"外面"(需求变化、运行时环境、网络故障),你用工具去管它们。但现在不确定性跑到了"生产线本身"上------写代码的那个家伙(AI),它自己就是概率性的。
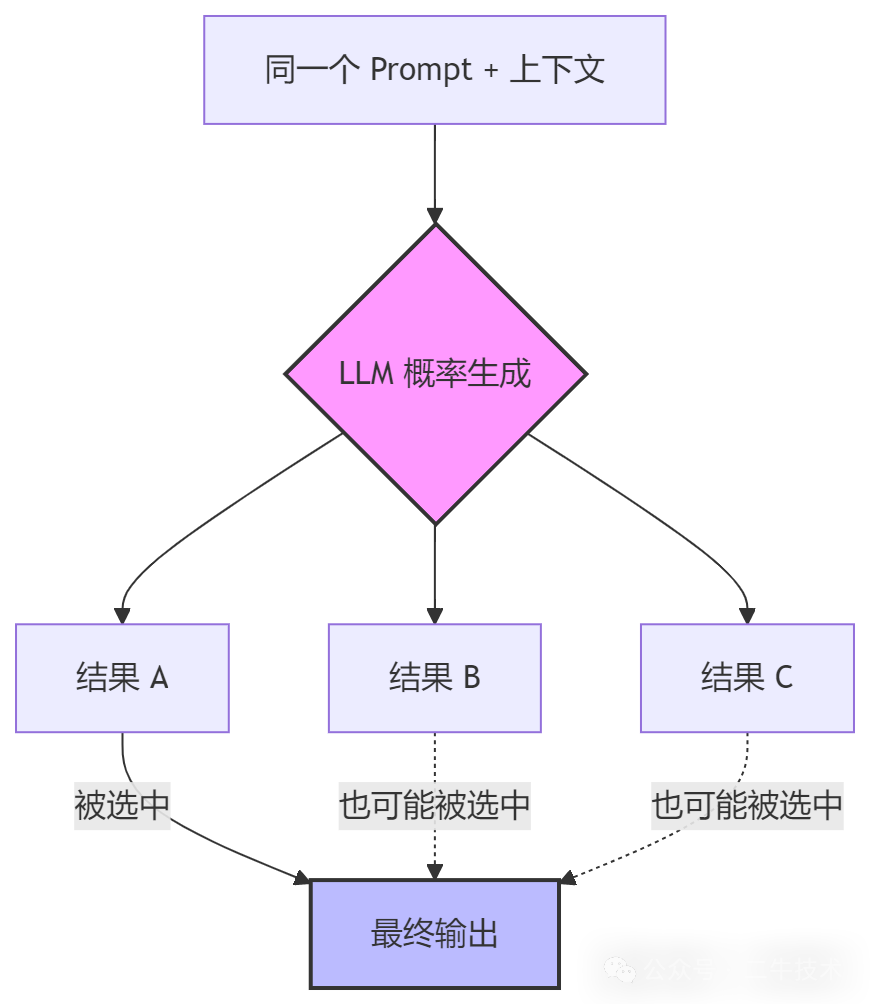
AI 不是不靠谱,而是"靠谱的概率"还不够高。Harness Engineering 就是想把这个概率逼近 100% 的一整套工程实践。
这意味着我们手里那套老工具箱------锁、类型系统、CI/CD、一致性协议------并没有失效,但不够用了 。因为它们是为"管住运行时的不确定性"设计的,而现在你要管住的是"生产过程本身的不确定性"。需求的探索、原型的设计、代码的产出、测试的生成执行,这些流程的主体从人变成了 AI------你需要为这个新的不确定性来源,设计新的工程手段。
举个真实的例子:我用 AI agent 来做 Code Review。第一次它找到2-3个需要修改的安全问题。可是我重启一个 chat session,同样让它对同一个改动做 Code Review,这次它没给出安全问题,而是给了一些重构优化的意见。这就是缺少 Harness 的代价:每一次"成功"的 AI 输出,都感觉是在开盲盒。
二、那 Harness 到底是什么?
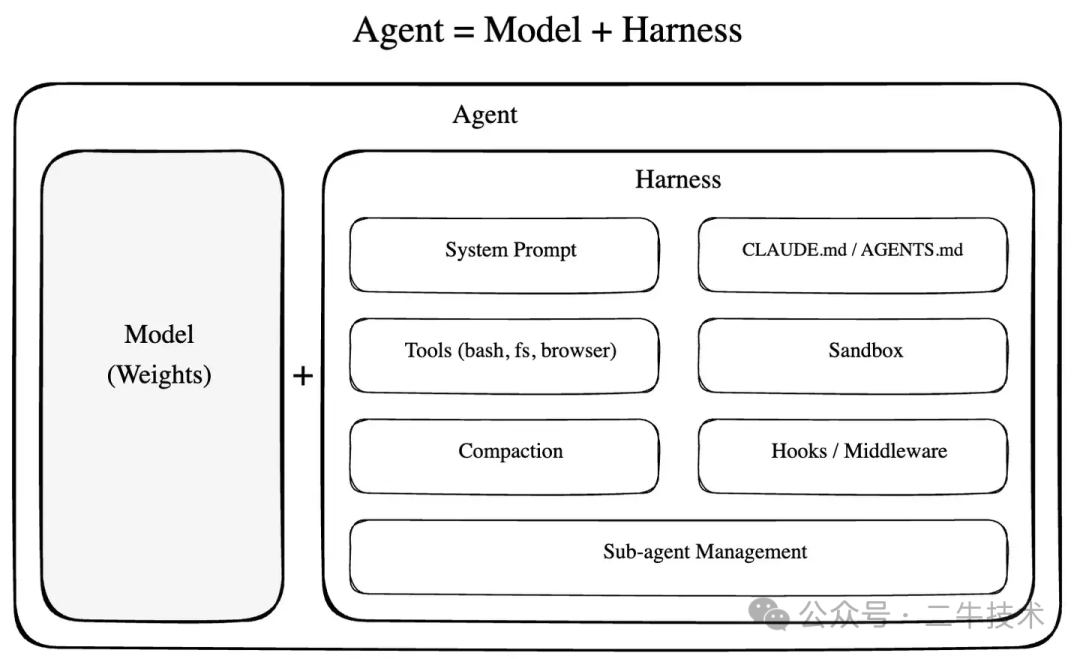
对于 Harness 的定义有很多,个人觉得比较清晰的是 LangChain 提出的这个广义的公式:
Agent = Model + Harness
Model 提供智能(推理、理解、生成),Harness 是 Model 以外的一切------工具、规则、编排、权限、反馈回路。
德国的 AI 码农 Philipp Schmid 在1月份的博客上发表了 《The importance of Agent Harness in 2026》, 他在文中将 Agent Harness 与计算机做了一个类比:
| 计算机 | AI 编程 | 作用 |
|---|---|---|
| CPU | LLM | 提供算力/智力 |
| 内存 | Context Window | 工作记忆、上下文 |
| 操作系统 | Harness | 资源调度、权限管理、错误恢复 |
| 应用程序 | Agent | 面向用户的产品 |
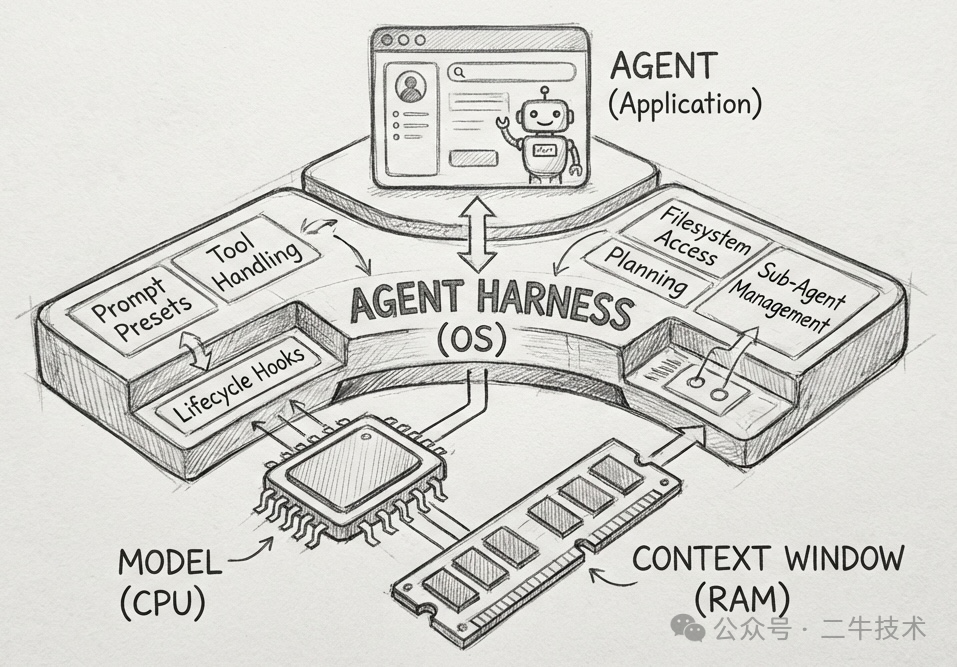
没有操作系统的 CPU 什么也干不了------它能计算,但不知道该算什么、结果放哪、出错了怎么办。没有 Harness 的 LLM 也是一样:它能生成代码,但不知道该遵循什么规范、怎么验证自己的输出、哪些文件不该碰。
所以 Harness Engineering 不是"更高级的 Prompt Engineering",Prompt 只是 Harness 的一小块。它也不是"多接几个 MCP 工具",工具只是 Harness 的另一小块。
Harness Engineering 是一整套让 AI 的不确定性被系统工程方式"管起来"的实践。
三、一张图,让工具各就各位
如果你跟我一样,觉得"Harness 是 Model 以外的一切"这个定义还是太泛了,那 Thoughtworks 的 Birgitta Böckeler 在 Martin Fowler 网站上发的 《Harness engineering for coding agent users》 给了一个非常好用的坐标系。她把 harness 的组成拆成两个维度:
第一个维度:控制的时机
-
• Guides(前馈/Feedforward) ------在 AI 动手之前就缩小它的错误空间。比如 AGENTS 文件、Instructions、MCP 工具、架构文档、设计实现限制。本质是"让它尽量别犯错"。
-
• Sensors(反馈/Feedback) ------在 AI 产出之后验证结果并触发自我修正。比如 Linter、单元测试、end-to-end 测试、AI Code Review、运行日志。本质是"犯了错马上抓住",甚至要记下来,避免相同的问题再次出现,完成一个闭环。
第二个维度:执行的方式
-
• Computational(确定性工具)------ CPU 跑的,快、便宜、结果可靠。Type checker、structural test、coverage report。跑一千次结果一样。
-
• Inferential(推理性工具)------ GPU 跑的,慢、贵、结果有概率性。LLM-as-judge、AI code review、语义分析。有判断力,有创造力,但不保证每次一致。
把这两个维度组合起来,就得到一个 2×2 矩阵:
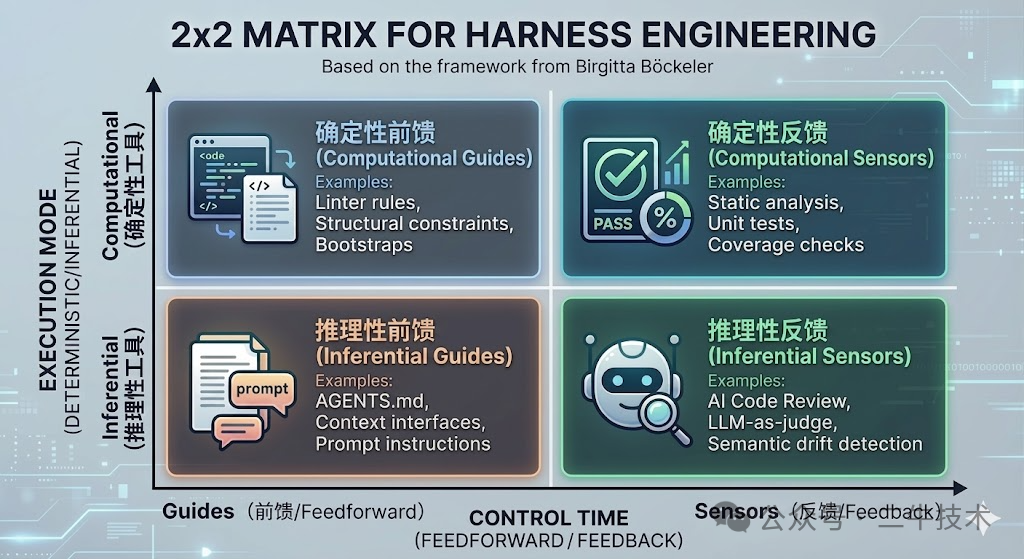
这张图的价值在于:我们日常做的每一件事------写 instruction、配 linter、跑测试、做 code review------基本都能在这四个格子里找到自己的位置。当我们发现某个象限是空的,那有可能就是我们的 Harness 还有缺口的地方。
四、为什么每个人讲的 Harness 都不太一样?
有了以上的定义和坐标系 之后,再回头看开头那个现象------"人人都在讲 Harness Engineering,但听起来像在讲不同的东西"------好像就没那么困惑了:因为大家站在矩阵的不同象限里说话。
-
• CEO/CTO 关心的是"AI 产能能否规模化、如何进行组织的转型"------他们在讲 Guides 的战略层面:Harness 模板化、组织结构的转型升级。
-
• BA/PM 焦虑的是"AI 能不能把业务需求写对"------他们在讲 Inferential Guides:business context、原型设计、验收标准、业务规则结构化
-
• 开发/架构师 在意的是"怎么让 AI 少犯低级错误,别改烂架构"------他们在讲如何利用确定性和不确定性的工具来提供前馈和反馈:linter、CI、project context、AI Code Review
-
• QA 纠结的是"AI 生成的测试到底能不能信"------他们在讲 Behaviour Sensors:端到端验证、行为漂移检测
-
• AI 工具厂商 包装的是"我们内置了 planning + subagents + context management"------他们在讲产品化的 Harness 组件
当把大家的视角放到同一张 2×2 矩阵上,大家就能相互 GET 到对方想表达的意思了。
Harness Engineering 不是某一个角色的专属领域,它是一整个控制系统------每个角色负责其中一个环节。
这里还有一个问题值得思考:如果 AI 在干活,那人干什么?
Thoughtworks 的 Kief Morris 提出了一个很好的区分:人的角色正在从 in-the-loop (亲自干活)变成 on-the-loop(设计控制系统)。以前你是写代码的人,现在你是设计"让 AI 正确写代码"的人。你不再检查每一行输出,而是设计一套控制系统,让问题在你看到之前就被拦截。
这就是 Harness Engineering 的本质工作:不是替 AI 干活,而是设计"让 AI 干对活"的系统。
五、Harness 不是一劳永逸的
写到这里,我想补充一个容易被忽略的点。
大多数人听到"Harness"的第一反应是:搭好了就可以一直用。把 instruction 写好、把 agent / skill 设计好、把 CI 跑起来 ------ 然后坐等 AI 干活。
但实际情况恰恰相反。AI 的能力在快速演进,AI Coding Agent 的能力也在进化。 3个月前你需要用 linter 规则拦住的编译错误,今天的模型可能已经不会犯了。半年前你需要在 prompt 里写三段话解释的架构约定,今天的 agent 可能从代码结构里就能推断出来。
这意味着 Harness 不是一成不变的 ------ 旧的 Harness 要不断拆除,新的 Harness 要不断前移。
我把这个过程理解为"持续向左 harness":
-
• 当模型能力提升,某些 Sensors(事后检查)变得多余 ------ 因为 AI 已经不会犯那类错了
-
• 当 agent 框架进化,某些 Guides(事前指导)可以简化 ------ 因为 agent 自己能获取上下文了
-
• 但新的风险和新的能力边界会出现,你需要在更前面 、更高层设置新的控制
就像操作系统一样 ------ 早期 操作系统 要管内存分配的每一个字节,后来有了虚拟内存、有了垃圾回收,这些底层 harness 被拆掉了。但 操作系统 并没有消失,它在更高层面(容器编排、安全沙箱、权限管理)继续发挥作用。
Harness Engineering 不是"搭一次就不动"的基建项目,而是一个随 AI 能力同步演进的持续实践。Harness 一直都在,只是 Harness 的位置在不断左移。
写在最后
回到开头那个矛盾:软件工程需要确定性的输出,而AI 天生不确定。Harness Engineering 不是要消灭这个矛盾------概率性输出是目前 LLM 的本质特征,消灭不了------而是用工程化的手段把不确定性围起来、管起来、逼退到可接受的范围。
有了这个框架之后,接下来希望能把几个关键方面逐一展开:
-
- Context Engineering ------ 让 AI "看见"你的项目,系统地管理 AI 在项目中能获取到的所有上下文。
-
- AI 驱动的测试 ------ 谁来验证 AI 的输出?探索能否让 AI 生成的测试验证 AI 生成的代码。
-
- 反馈闭环 ------ 让 Harness 越跑越聪明。不是配好了就不动,而是每一次 AI 的使用都在改进整个系统。
首发于微信公众号 二牛技术
参考源清单
-
- Birgitta Böckeler (Thoughtworks) ------ Harness Engineering for Coding Agent Users, 2026.04
-
- Birgitta Böckeler ------ Context Engineering for Coding Agents, 2026.02
-
- LangChain ------ The Anatomy of an Agent Harness, 2026.03
-
- Kief Morris (Thoughtworks) ------ Humans and Agents in Software Engineering Loops, 2026.03
-
- OpenAI ------ Harness Engineering: Leveraging Codex, 2026.02