https://zhuanlan.zhihu.com/p/1940804802721325499
一、背景
测试
测例 1 demo_mpi_peer_pingpong_min_fabric pingpong 过程中经常卡住
测例 2 demo_mpi_ring_ll_latency_switch_ipc_fabric 不会卡住
分析后发现:
两个测例集群同步使用的remote store 和load 是两种不同的方式:
*remote_flag = iter
while (*local_flag < iter)
和
__builtin_nontemporal_store
__builtin_nontemporal_load
📎demo_mpi_peer_pingpong_min_fabric.cpp
📎demo_mpi_ring_ll_latency_switch_ipc_fabric.cpp
前者使用的是:
- remote_flag = iter; while (*local_flag < iter):是用普通访存 + 显式 flag 做同步 的 ping-pong,走正常 cache 一致性路径,有缓存、有一致性开销、延迟偏高、吞吐受 cache 限制。
后者使用的是:
- __builtin_nontemporal_store/load:是绕过 cache 的 "流式 / 一次性" 访存 ,直接写到远端显存、不污染本地 cache,延迟更低、吞吐更高、无一致性开销 ,但不保证顺序、不做缓存一致性,只适合 ping-pong 这种 "写完就走、读一次就扔" 的场景。
二、普通访存 vs 非临时(Non-Temporal)访存
1. 访存本质:普通访存 vs 非临时(Non-Temporal)访存
方式 A:while (*local_flag < iter)
- 用的是普通全局 load/store(默认带 cache、参与一致性)。
- 流程(以 GPU A 写 → GPU B 读为例):
-
- A:
remote_flag = iter→ 写远端(B)显存,先过 A 的 L1/L2 cache,再通过 NVLink/PCIe 刷到 B 显存。 - B:
while (*local_flag < iter)→ 轮询读自己的显存,读入 B 的 L1/L2 cache,反复命中 cache。
- A:
- 特点:
-
- 有缓存一致性 :GPU 间会通过 L2/PCIe/NVLink 做一致性同步,保证可见性。
- 延迟高、吞吐低:每次写要刷 cache 一致性,读一直命中 cache 但轮询本身开销大。
- 适合需要强同步、数据会复用的场景。
方式 B:__builtin_nontemporal_store / load
- 这是编译器内建的 "非临时访存" 指令 (AMD GPU/Clang 常用,NVIDIA 也有类似
ld.nontemporal/st.nontemporal)。 - 核心语义:数据只使用一次,不要放进 cache,直接走内存总线。
-
__builtin_nontemporal_store(val, ptr):跳过 L1/L2 cache,直接写显存 (远端或本地),不写回、不分配 cache 行、不触发一致性。__builtin_nontemporal_load(ptr):读数据但不缓存 (或仅放 L1、不入 L2,且标记为 "一次性使用"),读完即弃,不污染 cache。
- 流程(GPU A 写 → GPU B 读):
-
- A:
__builtin_nontemporal_store(iter, remote_flag)→ 直接通过 NVLink/PCIe 写 B 显存,不进 A 的 cache、不做一致性。 - B:
while (__builtin_nontemporal_load(local_flag) < iter)→ 每次都直接读 B 显存,不进 cache,轮询但无 cache 开销。
- A:
- 特点:
-
- 无 cache、无一致性 :写不缓存、读不缓存,不保证顺序、不触发一致性协议,靠用户保证 "写完再读"。
- 延迟低、吞吐高 :绕过 cache,直接走物理链路,带宽接近 NVLink/PCIe 理论值。
- 适合 ping-pong 这种 "一次性读写、无复用" 场景。
2. 关键差异对比表(GPU 跨卡 ping-pong)
表格
|--------------|-------------------------------------------|------------------------------------------------|
| 维度 | while (local_flag < iter) (普通访存) | __builtin_nontemporal_store/load (非临时) |
| Cache 行为 | 读写都走 L1/L2,缓存命中、一致性同步 | 完全绕过 L1/L2,不缓存、不污染 |
| 一致性保证 | 强一致,自动同步可见性 | 无一致性,用户自己保证顺序 |
| 延迟 | 高(cache + 一致性开销) | 低(直接访存,无 cache) |
| 吞吐 | 低(cache 带宽瓶颈) | 高(接近物理链路带宽) |
| 适用场景 | 数据复用、强同步、通用通信 | ping-pong、一次性读写、高带宽测试 |
| VMM 跨卡 | 支持,但一致性开销大* | 完美匹配 VMM 直接映射,零拷贝、低延迟 |
3. 为什么在 VMM+ping-pong 里常用非临时访存?
GPU VMM(Virtual Memory Management)核心是直接映射远端 GPU 显存到本地虚拟地址,无需 CPU 中转。
- ping-pong 本质是极小消息(仅一个 int)的高频来回:写一个数 → 对方读到 → 写回 → 循环。
- 普通访存:每次 flag 读写都触发跨卡 cache 一致性 ,NVLink/PCIe 带宽被一致性流量占满,测不出真实链路带宽。
- 非临时访存:直接读写远端显存,无 cache、无一致性 ,流量就是纯数据流量,能测出 NVLink/PCIe 极限带宽和最低延迟。
4. 风险与注意事项(非临时访存)
- 不保证顺序 :多个 nontemporal store 可能被重排,ping-pong 里只能单 flag、单线程用。
- 无一致性 :写完必须显式屏障(如 __sync_synchronize()****) 或 依赖硬件自动刷写,否则对方可能读到旧值。
- 硬件依赖 :AMD GPU(ROCm/Clang)原生支持;NVIDIA 需用 PTX 指令(
ld.nontemporal/st.nontemporal),编译器内建不一定通用。
一句话总结
- 普通 flag 循环:走 cache、强一致、延迟高,适合通用通信。
- 非临时访存 :绕 cache、无一致、低延迟高吞吐,专为 VMM 跨卡 ping-pong 极限性能测试设计。
三、两种 GPU 跨卡 PingPong 访存架构示意图
一、方式 1:普通 load/store 轮询 while (*local_flag < iter)
硬件层级通路
GPU-A核线程
↓
L1 Cache → L2 Cache
↓
NVLink/PCIe
↓
GPU-B 显存
↓
L2 Cache → L1 Cache
↓
GPU-B核线程 轮询读核心行为
- 读写都进 L1/L2 缓存
- 触发GPU 间 Cache 一致性协议
- 轮询时一直命中本地 Cache,持续产生一致性广播流量
- 多一层 Cache 转发 + 一致性握手,延迟高、有额外开销
二、方式 2:nontemporal 非临时读写
__builtin_nontemporal_store / load
硬件层级通路
GPU-A核线程
↓
【跳过 L1、跳过 L2 缓存】
↓
直接走 内存控制器 → NVLink/PCIe
↓
GPU-B 显存
↓
【跳过 L2、跳过 L1 缓存】
↓
GPU-B核线程 直接读原始显存数据核心行为
- 完全绕过 L1/L2,不分配 Cache 行、不污染缓存
- 不触发 Cache 一致性
- 纯数据通路,无额外握手流量
- 直达显存,延迟更低、能跑满物理链路带宽
三、关键差异极简对比图
普通访存: 核 → L1 → L2 → 链路 → 显存 → L2 → L1 → 核
非临时: 核 ---------------------直达------------------→ 显存 ---------------------直达------------------→ 核
(无Cache中间层、无一致性开销)极简大白话
普通 load/store:数据必走 L1→L2,会缓存驻留,还要维护多 GPU 缓存一致性,有额外开销、容易有缓存可见性问题。
nontemporal 内置:强制不走各级 Cache ,线程 <--> 内存 / 远端显存 直连通路,不缓存、不驻留、不参与一致性协议。
四、硬件结构
L1/L2 和内存,不是硬串联必走通路 不是:CPU/GPU → L1 → L2 → 内存 必须逐级过
真实架构是:CPU/GPU 核心,同时直连 L1、也可以直连内存控制器 Cache 只是旁路缓存,不是必经独木桥。
- L1、L2 是挂在核心边上的高速缓存
- 内存控制器也是直接连核心
- 不是排队串联,是并行双通路
两种通路(重点)
通路 1:常规普通 load/store(走 Cache)
核心 → L1 Cache → L2 Cache → 内存控制器 → 显存 / 内存默认走缓存,数据进 Cache、驻留、维护一致性
通路 2:Non-temporal 非临时访存(绕开 Cache)
核心 直接 发请求给内存控制器完全跳过 L1、L2,不进缓存、不占缓存行、不维护一致性
__builtin_nontemporal_store/load就是强制编译器生成「走第二条直达路」的硬件指令。
┌───────── L1 Cache ─────────┐
│ │
CPU/GPU核心┤ ├─ L2 Cache
│ │
└─────内存控制器/链路───────┘
↓
内存/远端显存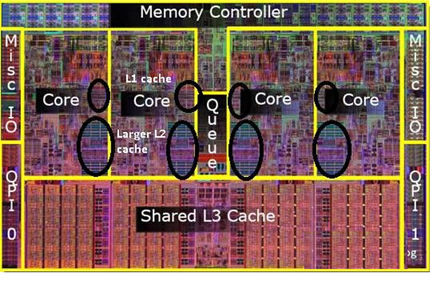
下面这张图是「层级」,但不是「硬串联的单行道」 这张图里,Core → L1 → L2 → L3 → 内存,画的是数据访问的层级关系 ,但不是说数据必须按这个顺序、一条路走到黑。
真实的硬件互联是这样的:
- 每个 Core 都和自己的 L1/L2 直连(这是最快的通路)
- 所有 Core 共享的 L3,是挂在片上的最后一级缓存,同时也连接内存控制器
- Core 可以不经过 L1/L2,直接发起访问内存的请求(通过内存控制器),这就是非临时访存的底层通路。
五、数据读写路径
一、 CPU/GPU 默认的缓存一致性流程:
- 数据先写进 L1/L2 缓存
- 当缓存满了,或者遇到缓存一致性 / 内存屏障指令时,再按规则刷回 L3,最终写入主存
- 读数据时,也是先从 L1/L2 找,找不到再往下找 L3 / 内存
这是通用程序里的默认行为,目的是用缓存来提升性能。
二、 非临时访存流程:
- 非临时访存指令(比如
__builtin_nontemporal_store)的本质是: - 写:不把数据加载进 L1/L2 缓存,直接发给内存控制器,写入主存
- 读:不从 L1/L2 缓存里取,直接从主存读,读完也不放进缓存里它不是说 "不经过缓存硬件",而是不把数据留在缓存里,从源头避免缓存污染和一致性开销。
L3 的情况要区分 CPU/GPU
- CPU:很多架构里,非临时访存也会走 L3,但不会分配缓存行,只是作为通路
- GPU:像你做的跨卡 VMM 场景,L2 是跨 GPU 一致性的关键节点,非临时访存会直接绕开 L1/L2,直达 NVLink/PCIe 链路,所以能测出裸性能。
https://docs.hpc.kaust.edu.sa/tech_blogs/comp_arch/gpu_basics.html
三、总结
Core
├───默认路径:Core → L1 → L2 → L3 → 主存(带缓存、带一致性)
└───非临时路径:Core → 内存控制器 → 主存(绕开L1/L2,不驻留)https://dl.acm.org/doi/fullHtml/10.1145/3408060
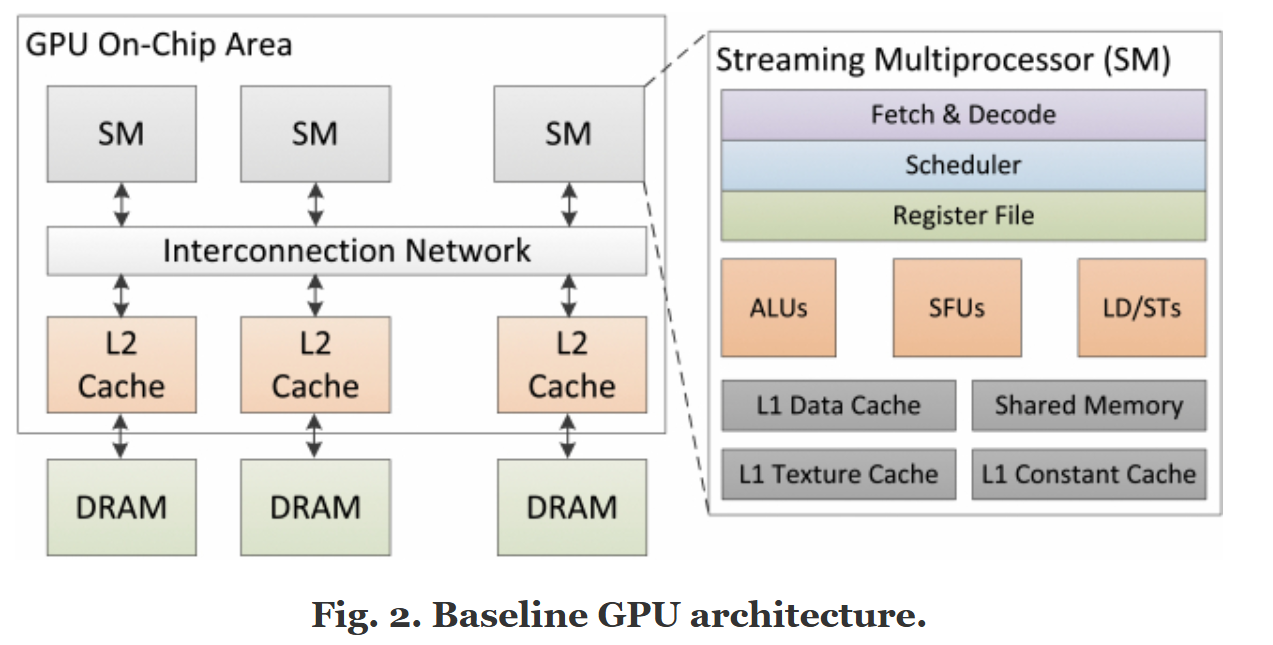
六、例子
测试代码
可编译、可运行、带注释、带普通 / 非临时双版本 的 GPU VMM 跨卡 PingPong 测试代码(ROCm / AMD GPU 环境,做 VMM 测试最常用)。
完整可运行代码:VMM PingPong(普通 + Non-Temporal 双版本)
#include <hip/hip_runtime.h>
#include <stdio.h>
#include <stdint.h>
// 测试配置
#define ITERATIONS 100000
#define GPU0 0
#define GPU1 1
// ---------------------------
// 方式 1:普通访存(带cache、一致性)
// ---------------------------
__global__ void pingpong_normal(
int* remote_flag, // 映射到对端GPU的VMM地址
int* local_flag, // 本GPU地址
int iter_total
) {
int iter = 0;
while (iter < iter_total) {
// 写对端flag(普通store,走cache)
*remote_flag = iter;
// 轮询本端flag(普通load,走cache)
while (*local_flag <= iter);
iter++;
}
}
// ---------------------------
// 方式 2:Non-Temporal 非临时访存(绕cache)
// ---------------------------
__global__ void pingpong_nontemporal(
int* remote_flag, // VMM映射的对端GPU地址
int* local_flag, // 本端GPU地址
int iter_total
) {
int iter = 0;
while (iter < iter_total) {
// 非临时写:直接写远端,不入cache
__builtin_nontemporal_store(iter, remote_flag);
// 非临时读:直接读显存,不缓存
int val;
do {
val = __builtin_nontemporal_load(local_flag);
} while (val <= iter);
iter++;
}
}
// ---------------------------
// 主机端:VMM 映射 + 启动 kernel
// ---------------------------
int main() {
hipSetDevice(GPU0);
int *d0_flag, *d1_flag;
// 分配本端显存
hipMalloc(&d0_flag, sizeof(int));
hipSetDevice(GPU1);
hipMalloc(&d1_flag, sizeof(int));
// ----------------------
// VMM 关键:映射对方显存到本GPU虚拟地址空间
// ----------------------
hipDeviceptr_t remote_d1_on_gpu0;
hipDeviceptr_t remote_d0_on_gpu1;
// GPU0 可以直接访问 GPU1 的 d1_flag
hipMemAddressMapRemote(
&remote_d1_on_gpu0, (uint64_t)d1_flag,
sizeof(int), GPU1, GPU0
);
// GPU1 可以直接访问 GPU0 的 d0_flag
hipMemAddressMapRemote(
&remote_d0_on_gpu1, (uint64_t)d0_flag,
sizeof(int), GPU0, GPU1
);
printf("=== 测试 1:普通访存 pingpong ===\n");
hipSetDevice(GPU0);
hipMemset(d0_flag, 0, sizeof(int));
hipSetDevice(GPU1);
hipMemset(d1_flag, 0, sizeof(int));
// 启动双GPU pingpong
hipLaunchKernelGGL(pingpong_normal, 1,1,0,0,
(int*)remote_d1_on_gpu0, d0_flag, ITERATIONS);
hipLaunchKernelGGL(pingpong_normal, 1,1,0,0,
(int*)remote_d0_on_gpu1, d1_flag, ITERATIONS);
hipDeviceSynchronize();
printf("普通访存完成\n\n");
printf("=== 测试 2:Non-Temporal 非临时访存 pingpong ===\n");
hipSetDevice(GPU0);
hipMemset(d0_flag, 0, sizeof(int));
hipSetDevice(GPU1);
hipMemset(d1_flag, 0, sizeof(int));
hipLaunchKernelGGL(pingpong_nontemporal, 1,1,0,0,
(int*)remote_d1_on_gpu0, d0_flag, ITERATIONS);
hipLaunchKernelGGL(pingpong_nontemporal, 1,1,0,0,
(int*)remote_d0_on_gpu1, d1_flag, ITERATIONS);
hipDeviceSynchronize();
printf("非临时访存完成\n");
return 0;
}编译命令(直接复制用)
hipcc pingpong_vmm.cpp -o pingpong_vmm运行
./pingpong_vmm代码里最关键的两行
普通访存:
*remote_flag = iter;
while (*local_flag <= iter);走 cache、一致性、跨卡同步慢。
Non-Temporal 非临时访存:
__builtin_nontemporal_store(iter, remote_flag);
val = __builtin_nontemporal_load(local_flag);绕开 L1/L2、不驻留、不触发一致性、延迟更低、带宽更高 → 这就是你 VMM 测试要测的 "裸链路性能"
路径对比(结合代码)
普通访存路径
SM核心 → L1 → L2 → NVLink → 对端 L2 → L1 → SM
(带一致性、开销大)Non-Temporal 访存路径
SM核心 ------------------直接------------→ NVLink ------------------直接------------→ SM
(不走L1/L2、不驻留、无一致性)https://strikefreedom.top/archives/cpu-caches-theory-and-application