一、RAG
Retrieval Augmented Generation,检索增强生成。20年提出
如何让大语言模型使用外部知识 进行生成。 通常,预训练模型(pre-trained models)的知识是存储在参数中的,因此模型无法了解训练集之外的知识(例如搜索数据、行业知识)。之前的做法是通过在预训练模型上进行****微调(fine-tuning)****来更新模型的知识。
1. RAG的背景与核心思想
-
解决的问题:解决大语言模型(LLM)无法获取外部知识、容易产生"幻觉"、以及更新知识成本高的问题。
-
核心思路 :在LLM生成回答前,先从外部知识库中检索 相关信息,然后将检索结果与用户问题一同增强 到提示词中,引导模型基于这些资料生成更准确、更有时效性的答案。
-
与微调的对比 :文章对比了RAG与模型微调的优劣,指出RAG在知识实时更新、可解释性、减少幻觉 方面有优势,而微调在深度定制、响应速度上表现更好。
2. RAG的技术流程:索引、检索与生成
-
索引:这是离线处理阶段,包含四个关键步骤:
-
数据加载:将PDF、网页等不同格式的源数据解析为纯文本。
-
文本分块:由于模型输入长度限制和语义聚焦需求,需将长文本切分成小段。文章详细介绍了固定大小、句子分割、递归分割等多种方法,并强调需根据业务调整。
-
文本嵌入:调用嵌入模型将文本块转化为能表达语义的多维向量。
-
创建索引:将文本向量存入Chroma、FAISS等专业向量数据库中。
-
-
检索 :目标是根据用户的查询,快速检索到与之最相关的知识,并将其融入提示
(Prompt)中。将用户问题用同样的模型向量化,然后在向量数据库中通过相似度计算,找出最相关的前K个文本块。 -
生成:将检索到的文本块作为上下文,和用户问题一起填入预设的提示模板,交给LLM生成最终答案。
3. RAG系统的评估体系
-
核心指标 :围绕用户问题、检索上下文、LLM答案 这个三元组,提出了上下文相关性、答案忠实度、答案相关性等6个关键评估指标。
-
评估方法 :除了人工评估,文章重点介绍了如何使用 LangSmith 平台进行自动化评估、监控与迭代优化。
4. RAG系统的优化策略
这是进阶内容,介绍了多种提升RAG效果的技术:
-
Query优化 :如 RAG Fusion (多查询融合)和 HyDE(假设性文档嵌入),让检索更精准。
-
高级检索优化 :包括句子窗口检索 (扩展上下文)、分层索引检索 (先搜摘要再搜细节)、混合检索(关键词+语义搜索)等。
-
语义路由:根据用户意图,自动将问题路由到不同的数据源(如文档库、数据库、API)。
-
重排序:在初步检索后,使用更精细的重排序模型,对结果进行再排序,确保最相关的片段排在前面。
二、LangChain
LangChain是一个专门为利用语言模型创建应用程序而设计的全面框架。它的主要目标是帮助开发人员轻松构建基于语言模型的应用。
LangChain 的核心价值在于------它提供了一个模块化、可插拔的集成框架,将RAG(检索增强生成)流程中的各个关键环节标准化 并串联起来,形成一个完整、高效的生产流水线。
三、自监督学习SSL
自监督学习 (Self-Supervised Learning, SSL) 是近年来人工智能领域最具革命性的训练范式之一。它的核心思想可以概括为一句话:"让数据自己做自己的标签" (Predicting the data from the data)。
传统深度学习高度依赖人工标注的数据(监督学习),但这不仅成本高昂,且获取困难。
自监督学习通过巧妙地设计"前置任务" (Pretext Task),利用无标签数据本身的结构信息来生成伪标签,从而在大规模无标注数据上训练模型,学习到通用且强大的特征表示。
自监督学习主要分为两大流派:对比学习 (Contrastive Learning) 和 掩码/生成式学习 (Masked/Generative Modeling)。下面我们将结合实例和 PyTorch 代码详细讲解。
(一) 对比学习 (Contrastive Learning)
对比学习在计算机视觉 (CV) 领域取得了巨大成功,代表作包括 SimCLR、MoCo 等。
1. 核心思想与实例 假设我们有一张"狗"的照片。
-
正样本对 (Positive Pair): 我们对这张照片进行两种不同的数据增强(例如:一张随机裁剪并调整颜色,另一张水平翻转并转为灰度图)。虽然看起来不同,但它们本质上都是同一只狗。
-
负样本对 (Negative Pair): 我们从数据集中随机拿一张"猫"的照片。
-
训练目标: 让模型将两个"狗"的特征表示在空间中拉近 (最大化相似度),将"狗"和"猫"的特征表示推远(最小化相似度)。
2. 核心公式 (InfoNCE Loss) 对比学习通常使用 InfoNCE (Normalized Temperature-scaled Cross Entropy) 损失函数。给定一个正样本对 (zi,zj),其损失计算如下:
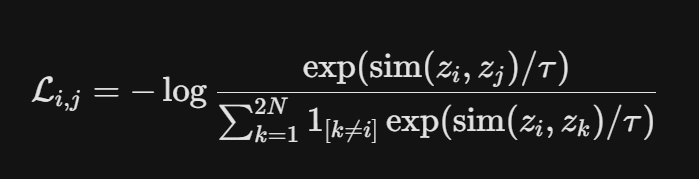
其中,sim(u,v) 是余弦相似度,τ 是温度超参数,N 是 Batch Size,2N 代表包含了每个样本的两个增强版本。
3. 代码实例 (PyTorch 实现简化的 SimCLR 损失)
python
import torch
import torch.nn.functional as F
def contrastive_loss(z_i, z_j, temperature=0.5):
"""
计算基于 Batch 的对比学习损失 (InfoNCE)
z_i: 图像增强视角 1 的特征向量 (Batch_size, Feature_dim)
z_j: 图像增强视角 2 的特征向量 (Batch_size, Feature_dim)
"""
batch_size = z_i.shape[0]
# 1. 组合所有的特征 (2N, Feature_dim)
z = torch.cat((z_i, z_j), dim=0)
# 2. 计算相似度矩阵 (2N, 2N)
# F.normalize 使得点乘等价于余弦相似度
sim_matrix = F.cosine_similarity(z.unsqueeze(1), z.unsqueeze(0), dim=2)
sim_matrix = sim_matrix / temperature
# 3. 构造标签和掩码
# 正样本对的索引:i 与 i+batch_size 互为正样本
labels = torch.cat([torch.arange(batch_size) for _ in range(2)], dim=0)
labels = (labels.unsqueeze(0) == labels.unsqueeze(1)).float() # (2N, 2N)的对角块矩阵
# 排除自己和自己计算相似度 (对角线设为负无穷)
mask = torch.eye(labels.shape[0], dtype=torch.bool)
labels = labels[~mask].view(labels.shape[0], -1)
sim_matrix = sim_matrix[~mask].view(sim_matrix.shape[0], -1)
# 4. 提取正样本的相似度
positives = sim_matrix[labels.bool()].view(labels.shape[0], -1)
# 5. 计算 Cross Entropy Loss
# 将正样本放在第0列,其余都是负样本
logits = torch.cat([positives, sim_matrix[~labels.bool()].view(sim_matrix.shape[0], -1)], dim=1)
# 目标分类标签是0,因为我们把正样本放在了第0列
target = torch.zeros(logits.shape[0], dtype=torch.long)
loss = F.cross_entropy(logits, target)
return loss
# 测试代码
batch_size, feature_dim = 64, 128
z_1 = torch.randn(batch_size, feature_dim) # 模拟网络输出
z_2 = torch.randn(batch_size, feature_dim) # 模拟网络输出
loss = contrastive_loss(z_1, z_2)
print(f"Contrastive Loss: {loss.item():.4f}")(二) 掩码/生成式学习 (Masked Modeling)
这种方法在自然语言处理 (NLP) 和视觉领域 (如 MAE) 占据绝对统治地位。它通常也被称为去噪自编码 (Denoising Autoencoding)。
1. 核心思想与实例
-
NLP 中的 BERT (Masked Language Modeling): 给定一句话 "我喜欢学习人工智能"。我们故意遮挡掉几个词,变成 "我喜欢 MASK 人工智能"。模型的前置任务就是根据上下文,预测出 MASK 位置的词是"学习"。
-
CV 中的 MAE (Masked Autoencoder): 将一张图片切分成多个小图块 (Patches),随机丢弃掉 75% 的图块。模型(通常是 Vision Transformer)只需根据剩下的 25% 图块,重新画出缺失的部分。
通过这种"完形填空"的游戏,模型被迫理解了语言的语法和逻辑,或者图像的结构和语义。
2. 代码实例 (PyTorch 模拟简易的文本掩码逻辑)
python
import torch
def create_masked_language_model_data(tokens, vocab_size, mask_token_id, mask_prob=0.15):
"""
模拟 BERT 的 Masked Language Modeling 数据生成
tokens: 原始 token ID 序列 (Batch_size, Seq_length)
"""
labels = tokens.clone()
# 生成一个随机矩阵,用于决定哪些 token 被 mask
rand = torch.rand(tokens.shape)
# 掩码概率通常设为 15%
mask_arr = (rand < mask_prob)
# (可选逻辑:BERT 论文中被选中的 15% 里,80% 变 [MASK],10% 随机词,10% 保持不变。此处为了简化直接替换为 MASK)
masked_tokens = tokens.clone()
masked_tokens[mask_arr] = mask_token_id
# 不需要预测的位置,标签设为 -100 (PyTorch CrossEntropyLoss 默认忽略 -100)
labels[~mask_arr] = -100
return masked_tokens, labels
# 测试代码
batch_size, seq_len, vocab_size = 2, 10, 1000
mask_id = 999 # 假设 999 是 [MASK] token
# 模拟两句话的 token IDs
original_tokens = torch.randint(0, vocab_size, (batch_size, seq_len))
print("Original Tokens:\n", original_tokens)
masked_inputs, target_labels = create_masked_language_model_data(original_tokens, vocab_size, mask_id)
print("\nMasked Inputs (999 means masked):\n", masked_inputs)
print("\nTarget Labels (-100 means ignore in loss):\n", target_labels)
# 在训练循环中,你会这样计算 Loss:
# outputs = model(masked_inputs) # 输出维度 (Batch_size, Seq_length, Vocab_size)
# loss = F.cross_entropy(outputs.view(-1, vocab_size), target_labels.view(-1))(三) 自监督学习的训练范式
自监督学习通常不直接解决你的最终业务问题,它的标准工作流分为两步:
-
Pre-training (预训练): 使用海量无标注数据,利用上述的自监督前置任务(对比或掩码)训练出一个基础模型 (Foundation Model)。这一步模型学习到了通用的特征表示(例如:懂得了基本的中文语法,或者懂得了图像的基本轮廓)。
-
Fine-tuning (微调) / Linear Probing (线性探测): 在基础模型之上加一个简单的分类头/回归头。使用少量的有标注数据(监督学习)对模型进行微调,以适应特定的下游任务(如情感分析、图像分类)。
总结: 自监督学习的本质是挖掘数据自身的监督信号。无论是通过数据增强制造的"对比约束",还是通过掩码制造的"重构约束",目的都是迫使神经网络在不依赖人类标签的情况下,理解这个世界的内在规律。
四、
参考: