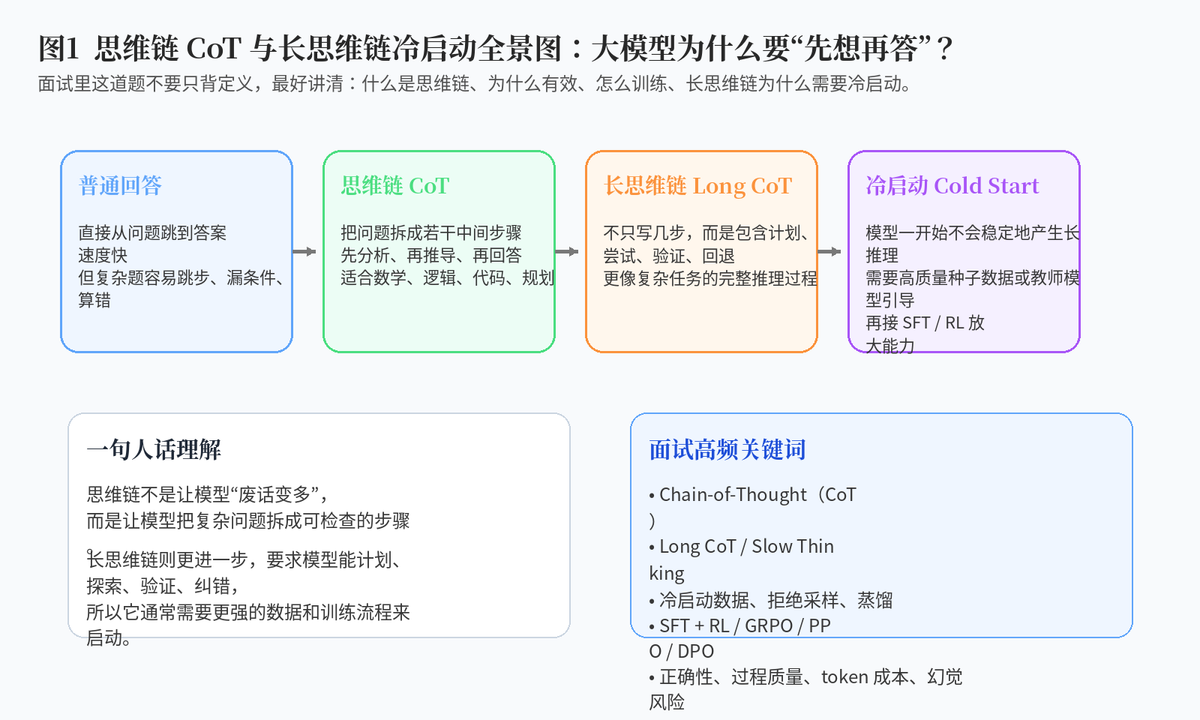
1. 为什么"思维链"会成为大模型面试高频题?
1.1 这道题表面问概念,实际在考推理模型训练主线
在大模型面试里,"什么是思维链"看似是一个基础概念题,但它背后其实连接着一整条推理模型训练路线:提示词如何诱导推理、模型如何学习分步解题、长思维链数据怎么冷启动、SFT 和 RL 如何配合、推理过程如何评估,以及上线时如何平衡准确率、延迟和 token 成本。
因此,回答这道题不能只说"思维链就是一步步推理"。更好的回答方式是:先讲它是什么,再讲它为什么有效,然后讲短思维链和长思维链的区别,最后讲长思维链冷启动怎么做。这样才能体现出对大模型训练和工程落地的理解。
2. 什么是思维链?
2.1 用一句人话解释
思维链,英文叫 Chain-of-Thought,简称 CoT。它指的是模型在给出最终答案之前,先生成一串中间推理步骤。也就是说,模型不是直接从问题跳到答案,而是先把问题拆开,逐步分析,再给出结论。
通俗理解,普通回答像是"直接报答案",思维链回答像是"把解题过程写出来"。它特别适合数学题、逻辑题、代码推理、复杂问答、多约束规划等场景。

2.2 思维链不是"输出越长越好"
很多人会误以为思维链就是让模型说更多话。其实不是。真正有价值的思维链,关键不在"长",而在"步骤有用、逻辑连续、能帮助得到正确答案"。
如果中间步骤只是堆废话,或者看似推理但每一步都无法验证,那就不是高质量 CoT,而只是"像推理的文本"。所以在训练和评估时,既要看最终答案,也要看推理过程是否合理。
3. 思维链为什么有效?
3.1 把复杂问题拆成可检查的小步骤
思维链有效的第一层原因,是它把复杂问题拆成更小、更容易处理的步骤。对模型来说,一次性从题目跳到答案,难度很高;但如果先识别条件、再分解目标、再逐步计算,出错概率就会降低。
这和人类做题很像。我们做复杂数学题时,也不是直接写结果,而是先列已知条件,再一步步推导。大模型生成思维链,本质上也是在模仿这种"分步求解"的模式。
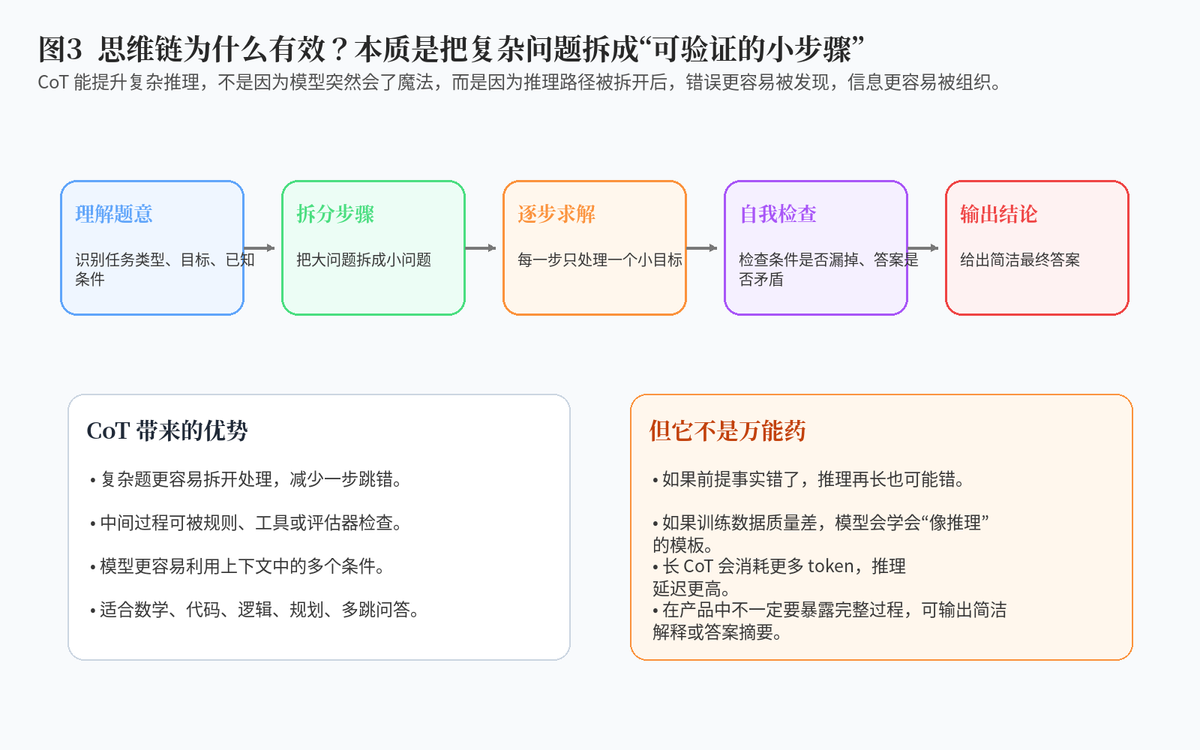
3.2 让错误更容易被发现
直接答案错了,你很难知道模型错在哪里;但如果中间过程展开了,就可以检查它是不是漏条件、算错数、逻辑跳步,还是把问题理解错了。
这对训练也很重要。因为中间过程可以被规则、工具、单元测试、人工评审或模型评估器检查,从而筛选出更好的训练样本。
3.3 但思维链不等于真实思考过程
需要注意的是,模型输出的思维链是一个生成出来的推理文本,不一定等同于模型内部真实机制。它可以帮助模型组织答案,也可以帮助外部系统评估,但不能简单理解成"模型真的像人一样在脑子里思考"。
4. 什么是长思维链?
4.1 短 CoT 与 Long CoT 的区别
短思维链通常只是几个明确步骤,比如"先算 A,再算 B,最后得到答案"。而长思维链通常包含更完整的推理过程:先制定计划,再分解子任务,必要时尝试多条路线,过程中自我检查,发现矛盾后回退,最后再输出结论。
所以长思维链不是简单把回答拉长,而是让模型具备更像复杂任务求解的行为:计划、探索、验证、纠错。
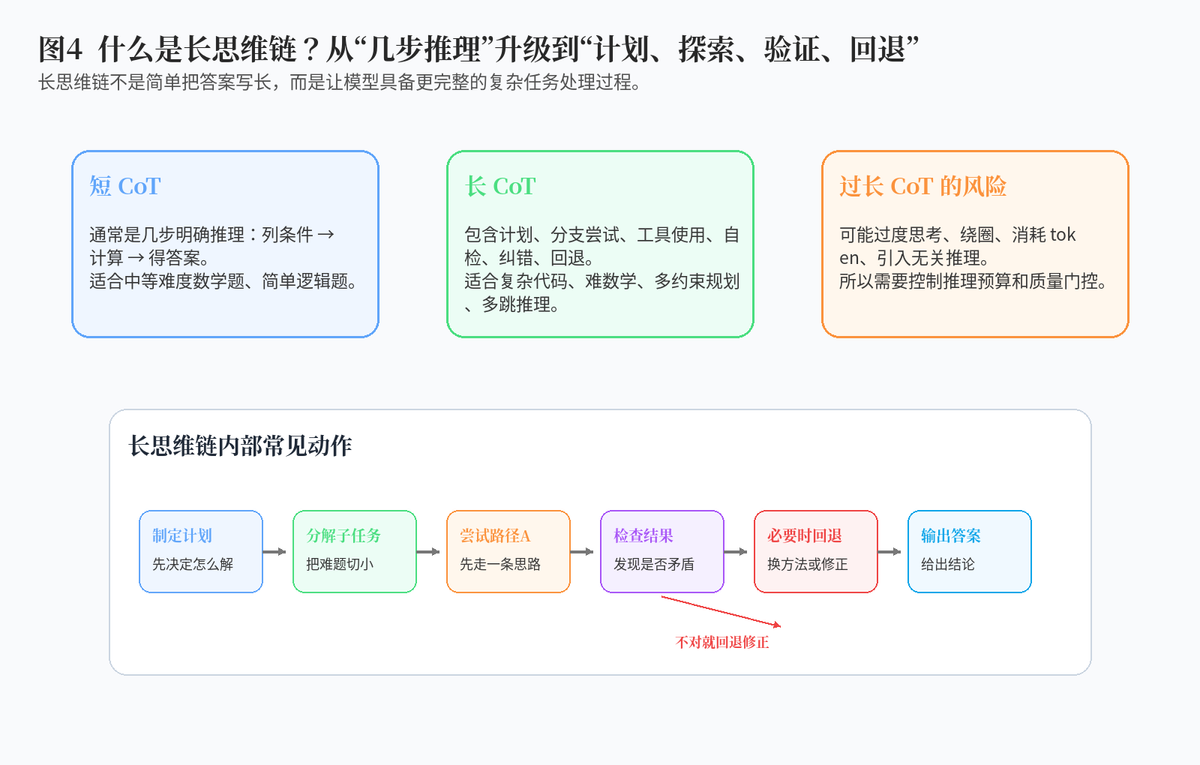
4.2 长思维链适合哪些任务?
长思维链适合那些"一步推不出来"的任务。例如复杂数学推理、竞赛题、代码修复、多文件工程分析、多跳问答、科学推理、策略规划、多约束决策等。
这类任务的共同特点是:条件多、步骤长、容易走错路、需要检查和回退。短 CoT 可能只能覆盖表层步骤,而长 CoT 更适合表达完整求解过程。
4.3 长思维链的成本问题
长思维链不是越长越好。越长意味着 token 成本更高、推理延迟更大、产生无关内容的风险也更高。因此真正上线时,系统往往要做推理预算控制:简单问题直接答,复杂问题才触发长推理。
5. 什么是长思维链冷启动?
5.1 冷启动到底"冷"在哪里?
长思维链冷启动,指的是基础模型一开始不一定能稳定地产生高质量长推理。它可能写得很短,或者虽然写得很长但逻辑混乱;也可能过程看起来像推理,最终答案却错。
因此,在进入大规模强化学习之前,通常需要先准备一批高质量长思维链样本,让模型先学会"长推理应该长什么样":如何分解、如何检查、如何回退、如何收敛到答案。
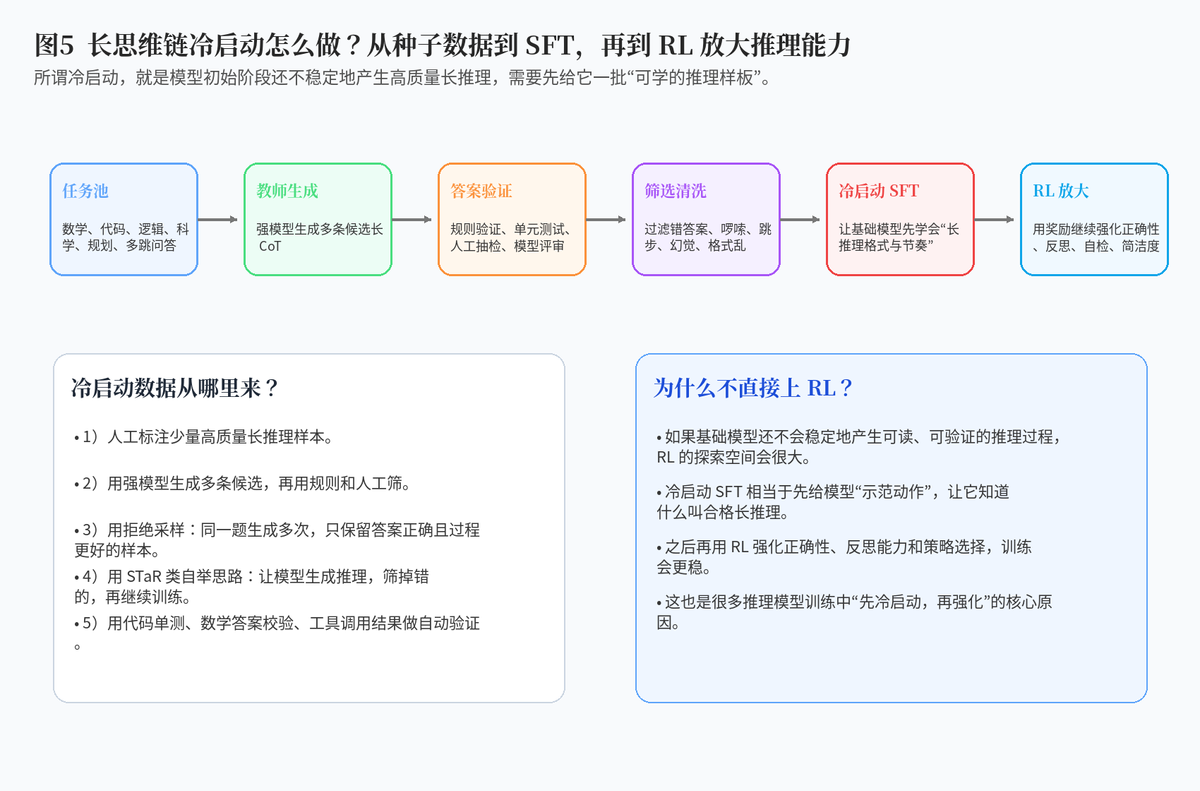
5.2 为什么不直接上强化学习?
如果模型连基本的长推理格式都不会,直接让它通过强化学习探索,搜索空间会非常大,训练也容易不稳定。冷启动数据就像给模型先做示范,让它知道什么叫合格的长推理。
之后再用 RL 去强化正确性、反思、自检和策略选择,训练会更加稳定。简单说,冷启动负责"先教会动作",强化学习负责"把动作练得更好"。
6. 长思维链冷启动数据怎么构建?
6.1 先构建任务池
第一步是构建任务池。任务要覆盖数学、代码、逻辑、科学、多跳问答、规划等类型,并且要区分难度层级。只用简单题,会让模型学不到长推理;只用超难题,又可能让训练早期过于不稳定。
6.2 再生成多条候选推理
第二步是让强模型、教师模型或当前模型本身生成多条候选推理。对同一道题生成多次,是为了获得不同推理路径。这样后续才能筛选出既正确又清晰的样本。
6.3 最关键的是验证和筛选
第三步是验证答案是否正确。数学题可以用标准答案校验,代码题可以用单元测试,选择题可以直接匹配答案,事实题可以用检索结果或人工审核。
答案正确只是第一关,过程也要筛。需要过滤掉跳步、乱编、废话过多、自相矛盾、格式混乱、靠猜得对的样本。最终留下来的,才适合进入冷启动 SFT 数据集。
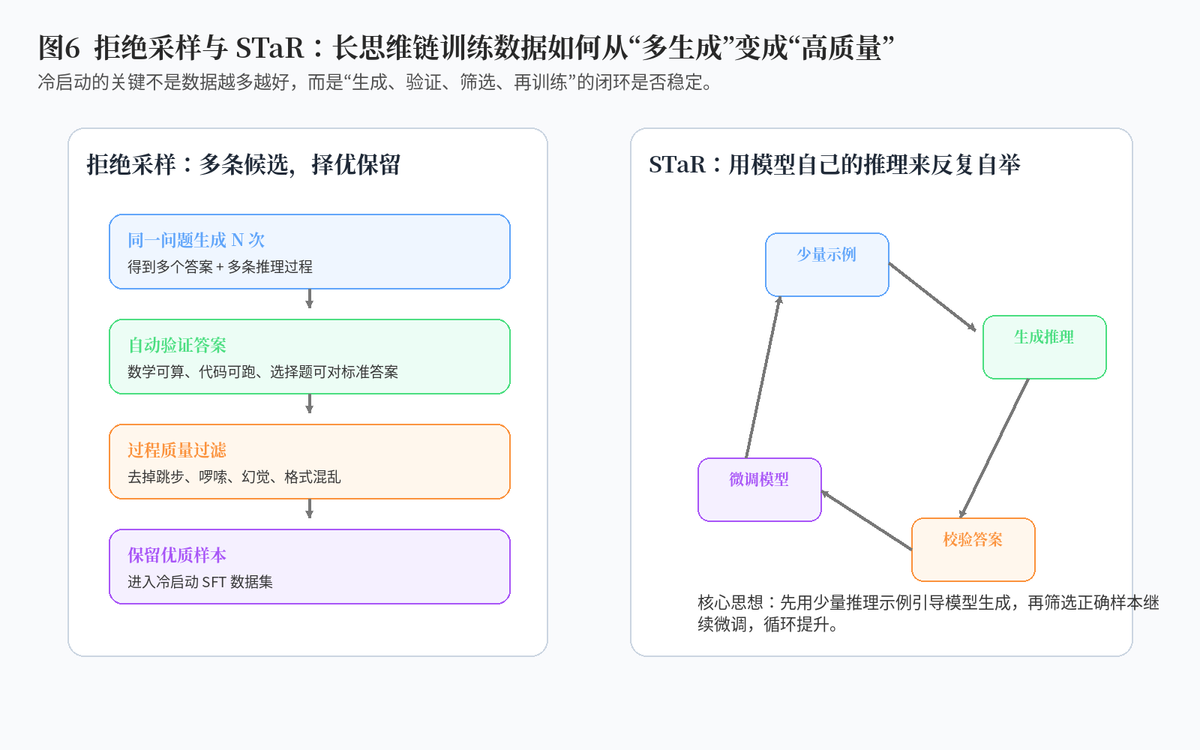
7. 拒绝采样和 STaR 在这里有什么用?
7.1 拒绝采样:多生成,严筛选
拒绝采样的思想非常直观:同一道题让模型生成多次,然后只留下答案正确、过程质量高的样本。它的价值在于,不要求模型每一次都完美,只要在多次尝试中能产生好样本,就可以把好样本挑出来训练。
比如代码题可以用单元测试筛,数学题可以用标准答案筛,多跳问答可以用证据覆盖率和事实一致性筛。这样可以把"模型偶尔做对"转化成"训练数据稳定变好"。
7.2 STaR:让模型用自己的推理进行自举
STaR 的思路是:先用少量推理示例引导模型生成推理,再筛选出能得到正确答案的推理样本,用这些样本继续微调模型,然后重复这个过程。
它的核心价值是降低对大规模人工推理标注的依赖,让模型通过"生成---筛选---训练---再生成"的循环逐步提升。
8. 思维链训练和 SFT、RL、RLHF 是什么关系?
8.1 SFT 负责"学格式、学节奏、学基本能力"
冷启动阶段常用 SFT,也就是监督微调。它的目的不是让模型一下子变成最强推理模型,而是先让模型学会高质量推理样本的格式、步骤和节奏。
比如模型要知道:复杂题先拆条件,再制定计划,必要时验证答案,最后给出简洁结论。这些行为可以通过高质量样本示范出来。
8.2 RL 负责"强化正确性和探索能力"
SFT 之后,还可以通过强化学习继续提升推理能力。奖励可以来自规则、答案验证、代码单测、数学结果校验,也可以来自奖励模型。
在推理任务里,RL 的价值在于鼓励模型探索更有效的推理策略,例如自我检查、回退、换路径、减少无用步骤。
8.3 RLHF 不一定等于推理训练的全部
RLHF 更强调利用人类偏好对模型行为做对齐,例如更有帮助、更安全、更符合表达偏好。而推理模型训练还可能使用规则奖励、可验证任务奖励、代码测试奖励等。二者可以结合,但不能简单划等号。
9. 思维链训练如何评估?
9.1 不能只看答案,也不能只看过程
评估思维链训练,第一层必须看最终答案是否正确。因为推理过程写得再漂亮,答案错了也没有意义。数学题看正确率,代码题看单测通过率,问答题看 EM、F1 或人工评审。
但只看答案也不够。因为模型可能碰巧猜对,或者过程完全不可信。所以第二层还要看过程质量:是否跳步、是否自洽、是否有无关推理、是否能覆盖关键条件。
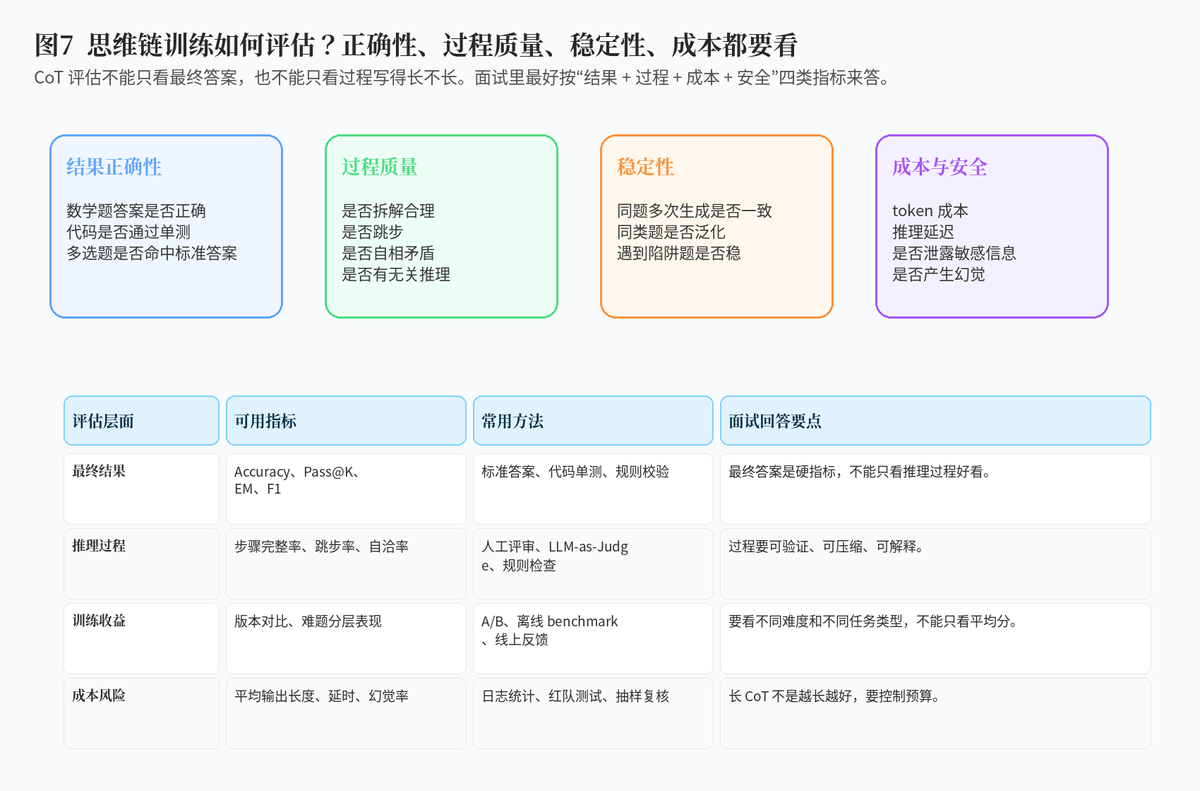
9.2 还要看成本和稳定性
长 CoT 会带来更高 token 成本和更高延迟,因此评估时还要统计平均输出长度、平均响应时间、复杂题触发比例、单次推理成本等。
另外,同一道题多次生成是否稳定,同类题是否泛化,也很关键。如果模型只有在训练分布里表现好,换个问法就崩,那说明推理能力还不够扎实。
10. 长思维链训练常见问题与优化方向
10.1 常见问题一:学会了"装作推理"
如果训练数据里有很多表面很长、但逻辑并不严谨的样本,模型就可能学会"看起来在推理",而不是真正提升解题能力。解决办法是提高数据筛选强度,把最终答案验证和过程质量审核结合起来。
10.2 常见问题二:过度思考
长思维链训练多了,模型可能在简单题上也写很长,造成延迟高、成本高。解决办法是训练或推理时加入难度判断和推理预算控制:简单题短答,复杂题才长推理。
10.3 常见问题三:长推理引入幻觉
推理越长,模型越可能在中间引入未经验证的假设。解决办法是让模型在关键步骤调用工具、检索事实、引用证据,或者在最终输出前做事实一致性检查。
11. 面试高频追问,建议这样回答
11.1 什么是思维链?
答:思维链就是模型在给出最终答案之前,先生成中间推理步骤,把复杂问题拆成多个小步骤来解决。它适合数学、逻辑、代码、多跳问答等复杂任务。
11.2 长思维链冷启动是什么?
答:长思维链冷启动是指在模型还不能稳定产生高质量长推理时,先用一批高质量长 CoT 样本进行 SFT,让模型学会长推理的格式、节奏和自检方式,再通过 RL 进一步强化正确性和推理策略。
11.3 冷启动数据怎么构建?
答:先构建覆盖数学、代码、逻辑、规划等任务的题库;再用强模型或教师模型生成多条候选推理;然后用标准答案、规则、单测、人工或模型评审做验证;最后过滤掉错答案、跳步、啰嗦和幻觉样本,只保留高质量数据做 SFT。
11.4 拒绝采样有什么用?
答:拒绝采样就是同一道题生成多次,只保留答案正确且过程质量更好的样本。它能把模型偶尔生成的好推理筛出来,变成高质量训练数据。
11.5 长 CoT 有什么风险?
答:主要风险包括 token 成本高、延迟高、过度思考、过程幻觉、表面推理和输出冗余。因此上线时要做推理预算控制、质量门控和事实校验。
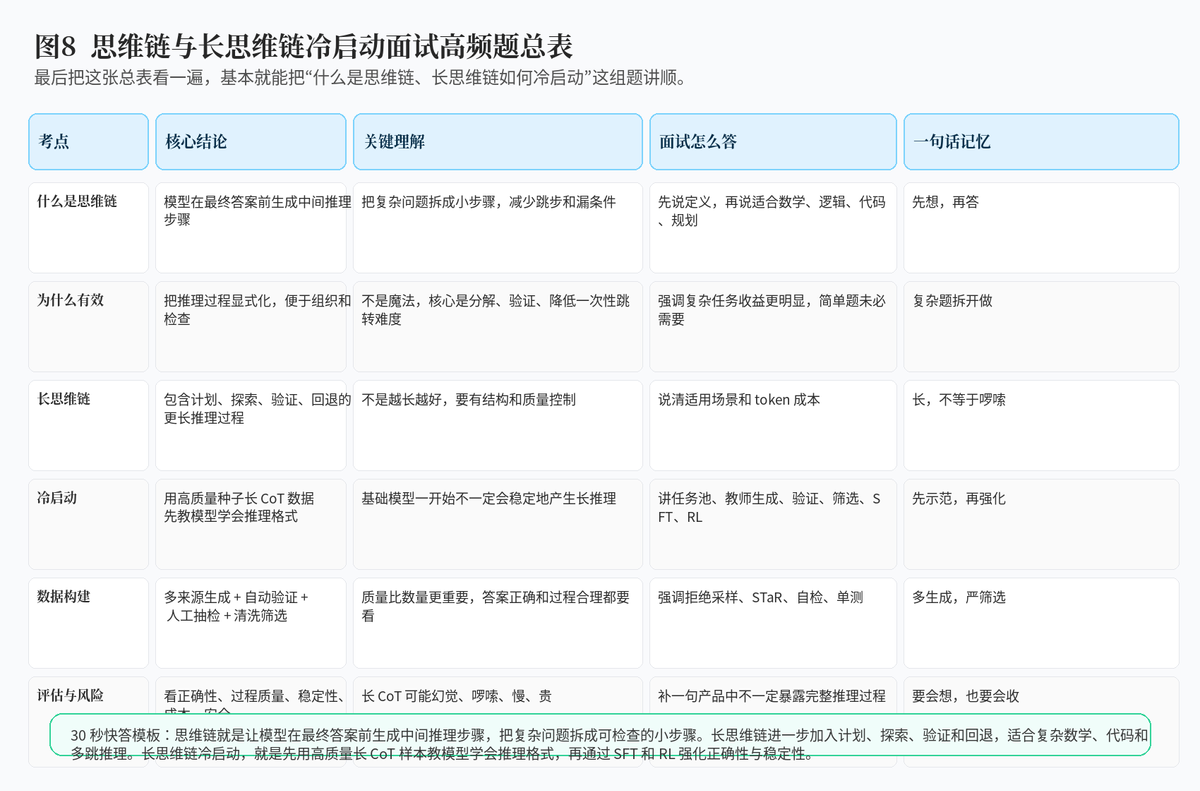
12. 总结:高质量回答的关键,是讲清"定义---作用---训练---评估---风险"
如果把这组问题浓缩成一句话,那就是:思维链是让模型先生成中间推理步骤再回答,长思维链则进一步加入计划、探索、验证和回退;而长思维链冷启动,就是先用高质量长推理样本教会模型基本推理格式,再通过 SFT 和 RL 放大推理能力。
面试里真正能拉开差距的,不是背出 CoT 三个字母,而是能把"为什么有效、数据怎么来、如何筛选、怎么训练、怎么评估、有什么风险"这一整条链路讲顺。只要这条线讲清楚,这道题就不只是基础题,而是能展示推理模型训练理解深度的加分题。
附:30 秒面试快答模板
"思维链就是让模型在最终回答前先生成中间推理步骤,把复杂问题拆成多个可检查的小步骤。它适合数学、逻辑、代码和多跳问答等复杂任务。长思维链更进一步,会包含计划、探索、验证和回退。长思维链冷启动,是因为基础模型一开始不一定会稳定地产生高质量长推理,所以需要先构建高质量长 CoT 样本,通过教师模型生成、拒绝采样、答案验证和过程过滤来得到训练数据,再用 SFT 让模型学会推理格式,后续再用 RL 强化正确性和自检能力。评估时不仅看最终答案,还要看过程质量、稳定性、token 成本和幻觉风险。"