Claude Code、Codex 为什么都选了 Grep 而不是 RAG
你可能默认以为,像 Claude Code 这样的 AI 编程工具,背后一定有一套复杂的 RAG 系统:建索引、算向量、做语义检索,然后喂给模型生成答案。
事实是,Claude Code 确实试过 RAG。然后它把 RAG 扔了。
不只是 Claude Code。OpenAI 的 Codex CLI、Cognition 的 Devin、Aider、Sourcegraph Cody,几乎所有主流 AI 编程工具都做出了同一个选择:用 Grep 搜索代码,不用 RAG。这不是巧合,也不是这些团队偷懒。他们在实践中发现,对于代码搜索这个场景,Grep 比向量检索快得多、准得多,还省掉了一整套基础设施。
今天就来聊聊这背后的原因。
RAG 和 Grep 是什么
如果你已经熟悉这两个概念,可以跳过这段。
RAG 全称 Retrieval-Augmented Generation,检索增强生成。简单说就是先建一个"知识库",把文档切成小块,用嵌入模型把每一块转成数学向量,存进向量数据库。用户提问的时候,把问题也转成向量,在数据库里找最相似的几块,然后把这些内容连同问题一起喂给大模型来生成回答。RAG 的核心思路是"语义相似",即使用词不同,只要意思接近就能找到。
Grep 就简单多了。它就是一个文本搜索工具,输入一个关键词或正则表达式,在文件里逐行扫描,把匹配的行找出来。ripgrep 是 Grep 的现代增强版,速度快了十倍以上,还自动跳过 .gitignore 里的目录。Claude Code 内部用的就是 ripgrep。
这两者看起来差距很大,RAG 是"智能"的语义匹配,Grep 是"笨"的关键词匹配。但在代码搜索这个场景里,"笨"的方法反而赢了。
Anthropic 的官方说法
最权威的解释来自 Boris Cherny,Claude Code 的创造者和首席工程师。2025 年 5 月他在 Latent Space 播客上公开讲了这件事。
他说他们确实试过 RAG,也试过其他搜索工具。最终发现 agentic search 才是正确的方式。他用了两个词形容结果:"outperformed everything, by a lot",超过了一切,而且是大幅超越。这让他们自己都很惊讶。
关于为什么不用 RAG,他给了几个具体理由。RAG 需要一个完整的索引步骤,有很多复杂性在里面。代码会不断变化,索引很快就会和实际代码失去同步。而且索引文件存在哪里也是个安全问题,涉及代码隐私。

"我们尝试了 RAG......尝试了几种不同的搜索工具。最终,我们发现 agentic search 才是正确的方式。有两个重要原因......第一,它的表现超过了一切。而且是大幅超越。这很令人惊讶。"
HackerNews 上也有一位 Anthropic 工程师直接确认了这一点。原话是 "Claude Code doesn't use RAG currently. In our testing we found that agentic search out-performed RAG for the kinds of things people use Code for." 意思很明确,测试结果摆在那里,agentic search 就是更好。
"Claude Code 目前不使用 RAG。在我们的测试中,agentic search 在人们使用 Code 的场景中表现优于 RAG。"
更有意思的是 2026 年 3 月的一次意外。Claude Code 大约 51 万行 TypeScript 源码通过 npm source maps 泄露了。社区拿到代码一通分析,确认代码库里完全不存在 RAG 管线、没有向量数据库集成、没有嵌入计算代码。搜索架构就是 Grep、Glob、Read 这几个工具调用的封装。源码不会说谎。
代码搜索和文档搜索是两回事
要理解为什么 Grep 在代码搜索里赢了,得先理解代码和自然语言的本质区别。
当你用 AI 编程工具的时候,你问的问题通常是"AuthService 这个类在哪里定义","哪些文件调用了 processPayment 这个函数","这个变量在哪里被修改了"。这些问题不是语义问题,是精确匹配问题。"AuthService 在哪里定义"的答案不是"跟认证概念语义最接近的文件",而是"字面上包含 class AuthService 这几个字符的文件"。
向量嵌入为模糊匹配而优化,它擅长的是"即使用词不同也能找到意思相近的内容"。但代码导航几乎不需要模糊匹配,你需要的是精确性。grep "class AuthService" 就能直接定位,而向量搜索可能把 AuthService、LoginService、SessionManager 都混在一起返回。
还有一个 RAG 解决不好的问题:代码的依赖关系。
理解一段代码往往需要追踪一条跨越多个文件的调用链。一个支付功能可能从 controller 出发,经过 service 层,到 repository 层,最后到 database migration。RAG 的相似度搜索可能检索到 controller 那一层,但几乎不可能沿着调用链一路找到底层的 migration。继承关系也一样,PaymentProcessor 继承 BaseProcessor 实现 ITransactionHandler,理解它需要三个文件同时出现。RAG 没有机制把这三个文件关联在一起。
分块也是个头疼的问题。2025 年一项 NAACL 同行评审研究发现,分块策略对 RAG 性能的影响等于甚至大于嵌入模型的选择。代码分块尤其棘手:函数和它所属的类一旦分开,继承信息就丢了;方法和调用它的代码分开,使用模式就看不到了;import 语句和使用它的代码分开,依赖关系就断了。研究数据很说明问题,尊重代码结构的自适应分块能达到 87% 的准确率,而固定大小分块只有 13%。
索引新鲜度也是问题。开发者每编辑一次文件,那个文件的嵌入就过时了。要保持向量索引实时更新,就得持续重新嵌入,又贵又容易出延迟。而文件系统读取永远是实时的,你改了什么,下一次查询就能看到。
Agentic Search
说到这里你可能会想,光靠 Grep 也太原始了吧。
确实,Claude Code 用的不只是 Grep。它用的是一种叫做 Agentic Search 的方式。区别在于,搜索过程本身包含了推理。
举个例子。你想知道"认证 token 是怎么验证的"。
如果是语义搜索,会把"auth token validation"这个查询转成向量,返回 10 个最相似的代码块。也许正确的文件在里面,但也可能返回一堆测试夹具、废弃的处理器和 README 里关于认证的部分。
如果是纯 Grep,会匹配 validateToken 这个关键词,返回每一个出现的位置:函数定义、15 个调用点、4 个测试 mock 和一条 changelog 记录。信息倒是全的,但噪音太多。
如果是 Agentic Search,它会先 Grep validateToken,在 auth/middleware.ts 里找到函数定义,读一下这个文件,发现它调用了 lib/crypto 里的 decodeJWT,然后跟着这个 import 追过去,找到真正的验证逻辑。最终返回两个精确的文件位置。
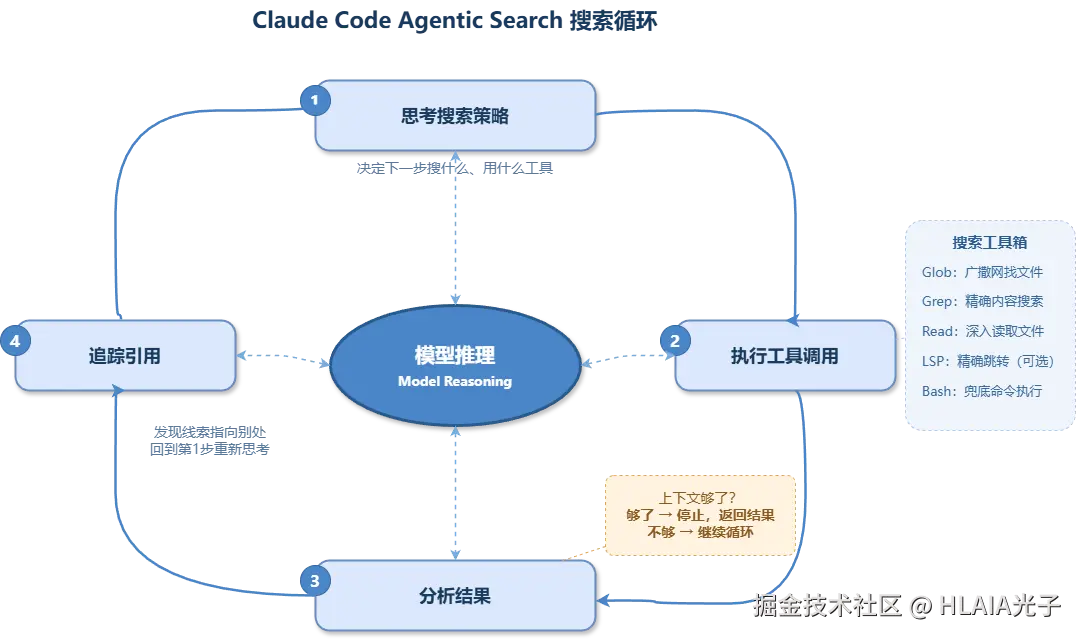
核心区别就在于这个"跟着追过去"的动作。模型不只是匹配模式,它会对代码可能在哪里形成假设,用工具调用验证这些假设,跨文件追踪因果链。搜索变成了一个循环:搜一下,读结果,想一想,再搜。典型情况下三四轮就能定位到目标。
而且模型可以同时发出好几个 Grep 调用,不同的模式、不同的目录、不同的文件类型一起搜。8 个并行 Grep 的延迟大约和 1 个差不多,但探索了 8 倍的代码库。
Anthropic 的研究还发现一个有意思的数据:当无关内容在上下文里积累时,模型性能会下降 30% 以上。这也是为什么 Agentic Search 要配合子代理隔离使用。搜索在独立的上下文窗口里跑,死胡同直接丢弃,只把相关的文件范围返回给主代理。不是子代理更聪明,而是主代理的上下文保持干净。
Claude Code 的搜索工具箱
Claude Code 给模型配备了五个核心工具。
Grep 基于ripgrep,搜索文件内容中的模式。Glob 做快速文件模式匹配,比如找出 src 目录下所有 TypeScript 文件。Read 读取指定文件的内容。Bash 可以执行任意 shell 命令,不过需要用户许可。还有 LSP,2025 年 12 月加入的可选语言服务器增强。
模型的搜索过程完全自主驱动。它先广泛搜索,用 Glob 找到相关文件类型。然后 Grep 特定的函数名、导入语句、模式。看到有希望的文件就读一下内容。读完发现引用了别的东西,就继续 Grep 跟踪下去。直到收集到足够的上下文,搜索结束。整个循环如下图所示。
为什么选 ripgrep 而不是传统的 grep?原因很实际。ripgrep 默认递归搜索、自动遵守 .gitignore、支持智能大小写匹配、文件类型过滤更简洁。在 Linux 内核基准测试里,ripgrep 耗时约 0.06 秒,grep 约 0.67 秒,差了十倍。而且在 Agent 工作流里,每个搜索结果都会变成文本送进模型的上下文窗口,无关结果会消耗 token、污染上下文、分散模型注意力。ripgrep 自动跳过 node_modules 这些目录,模型只看到真正相关的代码。
LSP 被定位为可选的精度增强层,不是搜索骨干。Grep 用来形成假设,LSP 用来验证假设和做精确操作。Claude Code 的设计理念是,能在 shell 里执行并产生文本输出的工具,比需要持久连接的有状态协议更原生。
不是 Claude Code 一家这么干
前面说了,几乎所有主流 AI 编程工具都独立做出了相同的选择,这不是商量好的。
OpenAI 的 Codex CLI 核心提示里直接指定用 ripgrep,不用任何向量检索。Devin 背后的 Cognition 团队甚至专门用强化学习训练了一个 SWE-grep 模型来优化 Grep 搜索策略。Aider 用 tree-sitter 做 AST 分析,结合 PageRank 算法构建代码地图,也是纯结构化方案。Sourcegraph Cody 用三元组索引加 LSP,走的是代码搜索引擎的路线。
不过还是有用RAG的,Cursor 是唯一一个确实用了 RAG 的主流工具,它有一个 5 步 RAG 管线做语义搜索的补充层。但即使在 Cursor 内部,ripgrep 仍然是 Agent 搜索的主要工具。当 ripgrep 在大型 monorepo 里变慢时,Cursor 的优化路径不是转向向量搜索,而是为正则搜索本身构建了一个本地 n-gram 索引。这很说明问题,他们需要的还是精确匹配,只是需要它更快。
这种行业趋同不是偶然的。各团队独立测试后都得出了相同结论,在代码搜索这个场景里,Grep 加上模型推理的组合,就是比 RAG 好。
大上下文窗口改变了一切
还有一个重要的背景因素。2022 到 2023 年的时候,模型上下文窗口只有 4k 到 32k token,RAG 几乎是必需品,你不可能把整个代码库塞进去。但到了 2025 到 2026 年,前沿模型提供了 多至100 万的 token,情况完全不同了。
写这篇博客的时候,gpt 5.6还没有正式发布,有传言,gpt 5.6的上下文窗口长达1.5M
瓶颈发生了转移。2023 年的瓶颈是检索,模型的读取器小、慢、贵,所以必须精心挑选喂给它什么。2026 年的瓶颈变成了对混乱上下文的推理,读取器大、快、便宜了。所以策略也变了:让检索器"笨但高召回",让模型自己做重活。ripgrep 负责把可能相关的内容都捞出来,模型负责从中筛选和理解。
Anthropic 官方的说法是 "Just-in-time context, not pre-inference RAG",即时上下文而非推理前 RAG。维护轻量级标识符,在运行时通过工具动态加载数据,而不是提前建好索引等着查。
这也是 Boris Cherny 提到的"Bitter Lesson"哲学:一切都是模型。随着模型变得更好,它会吸纳一切其他东西。与其花精力构建复杂的检索工程,不如押注模型能力的提升。
成本差距不是一星半点
从工程角度看,差距更直观。
经典 RAG 管线要经历这些步骤:文档分块、嵌入计算、存入向量数据库、查询向量化、相似度搜索、检索分块、拼装生成。涉及 4 到 5 个服务组件,每个都可能出问题。
Grep 加长上下文就四步:查询、ripgrep 搜索、结果加载到上下文、生成。不需要新增任何基础设施。
延迟上的差距也很明显。ripgrep 典型延迟 10 到 50 毫秒,完整 RAG 管线通常 500 毫秒以上。Agentic Search 因为多轮搜索,延迟在 2 到 8 秒左右,但换来的是精确得多的高质量结果。
工程成本更不用说了。搭建一套 RAG 管线保守估计 40 到 80 小时工作量。同样的钱,在 Sonnet 4.6 加 prompt caching 下,可以跑三万次以上 200k token 的查询,够用几个月。
维护方面,RAG 管线要处理嵌入 API 成本、监控告警、schema 变更、文档更新队列、嵌入失败重试。而 ripgrep 这边,文件改了,下一次查询自动看到新的内容,没有维护负担。
RAG 的运用场景
说了这么多 Grep 的好处,也得公平地说,RAG 在某些场景下仍然是更好的选择。
当语料量级达到 500GB 以上的原始文本时,ripgrep 也扛不住。当用户用的词和文档里的词差距很大的时候,比如用户说"wifi 断了",文档里写的是"物理层连接丢失",向量嵌入能捕捉这种语义关联,词法搜索做不到。跨模态检索,比如以图搜图、以音频搜音频,嵌入是必需的。极低延迟场景,要求 100 毫秒内给出答案的,RAG 的预索引优势就体现出来了。还有合规审计,需要证明特定查询确实参考了特定文档的,RAG 的可追溯性更有用。跨代码、文档、Jira、Slack 等异构数据源搜索时,结构化解析会失效,向量方法反而更灵活。
所以不是"RAG 已死",而是在代码搜索这个特定场景里,它不是最优解。
写在最后
研究完这些材料,我最大的感受是:AI 编程工具的选择背后,反映的是一种工程哲学的取舍。
RAG 看起来更"先进",有向量数据库、有嵌入模型、有语义理解,整个技术栈听起来就很酷。但先进不等于适合。代码搜索的核心需求是精确匹配和结构追踪,这两件事恰好是 RAG 最不擅长的。而 Grep 看起来"原始",但它做的事情和代码搜索的需求完美对齐:找到包含特定文本的行,不猜、不模糊、不遗漏。
真正让这个"原始"方案跑起来的,是模型能力的飞跃。两年前模型上下文窗口小、推理能力弱,必须靠精心设计的检索管线来"喂"数据。现在模型够大了,给它一堆 Grep 结果,它自己能理解、筛选、追踪。所以瓶颈从"怎么检索"变成了"怎么让模型更好地推理"。
Boris Cherny 说的 "Everything is the model" 这句话我觉得是整个决策的核心。与其花时间构建复杂的检索工程,不如相信模型会越来越强。这个赌注目前看起来是对的。
Claude Code 不用 RAG,不是因为它做不到,而是因为测试结果告诉他们不需要。Agentic Search 在代码搜索上全面超过了 RAG,而且零索引开销、零基础设施、零维护负担。Codex、Devin、Aider 等工具独立验证了同一个结论。
这不是 RAG 的失败,而是技术选型的胜利。选择适合场景的工具,而不是选择看起来最先进的工具。
如果你觉得这篇文章有帮助,点赞关注,点点赞~