小米 MiMo API 开放平台发布协议变更。在 Agent 类产品的多轮会话中,如果开启思考模式(Thinking Mode)且历史消息包含工具调用(tool_calls),assistant 消息必须完整回传 reasoning_content 字段,否则 API 返回 400 错误。
javascript
HTTP/1.1 400 Bad Request
{
"error": {
"message": "Param Incorrect",
"param": "The reasoning_content in the thinking mode must be passed back to the API.",
"code": "400"
}
}受影响的客户端包括:Trae、Cursor、GitHub Copilot CLI、Roo Code、Codex、Zed、AutoGen 等。
【开发者通知 ·Xiaomi MiMo 思考模式适配说明】
各位开发者好,使用 MiMo 思考模式的 Agent 类产品请注意:
当在 Agent 类产品的多轮会话中开启 MiMo 思考模式,且历史会话中存在工具调用时,后续所有 user 交互轮次中回传的 assistant 如果包含了工具调用,必须完整回传 reasoning_content 字段,否则 API 将返回 400 错误。之所以作此要求,是因为历史 reasoning_content 一旦缺失,模型上下文将不完整,可能表现出指令遵循下降,幻觉增多等现象,影响用户使用体感。
受影响产品:Trae、Cursor、Roo Code、Codex、GitHub Copilot CLI、Zed、AutoGen 等,我们正积极与相关框架方沟通,推进适配调整。
受影响模型:MiMo-V2.5-Pro、MiMo-V2.5、MiMo-V2-Pro、MiMo-V2-Omni、MiMo-V2-Flash
正确回传方式详见官方文档示例代码,如遇问题欢迎群内反馈。
https://platform.xiaomimimo.com/docs/zh-CN/usage-guide/passing-back-reasoning_content
Xiaomi MiMo团队
05月12日
解决方案
本代理作为 Trae 与 MiMo API 之间的中间层:
javascript
Trae → MiMo Reasoning Proxy → MiMo API
↓ 拦截响应,缓存 reasoning_content
↓ 下次请求自动注入回 assistant 消息核心逻辑:
- 拦截响应 :从 MiMo 返回的 assistant 消息中提取
reasoning_content,按content + tool_calls哈希缓存 - 注入请求 :当 Trae 发送后续请求时,为缺少
reasoning_content的 assistant 消息自动注入缓存值 - 降级处理 :如果缓存未命中(如代理启动前的旧对话),自动剥离
tool_calls避免 400
中间件工具包下载
蓝奏云
https://wwbvq.lanzoue.com/b0j1ght6j 密码:123
免部署版使用方法:MiMoProxy免
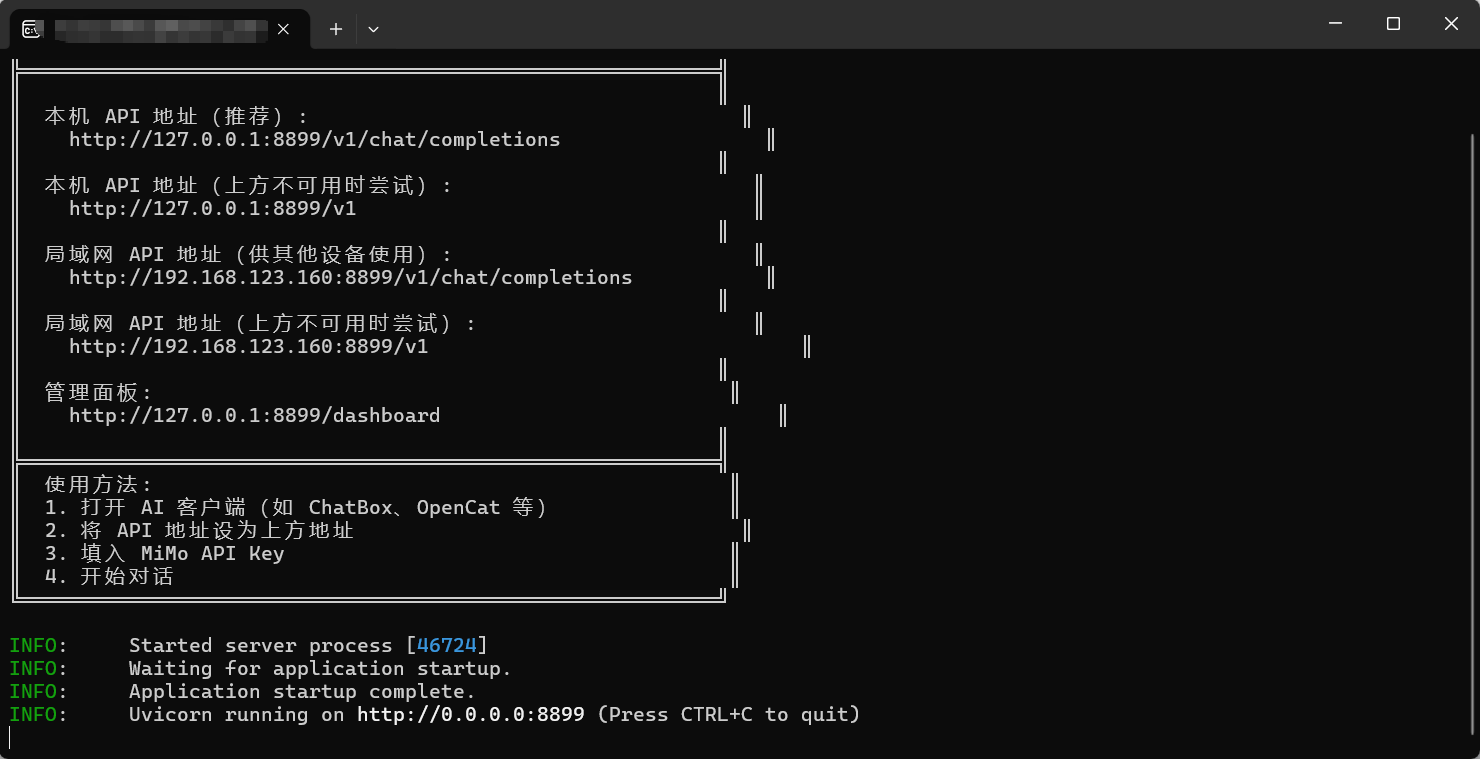
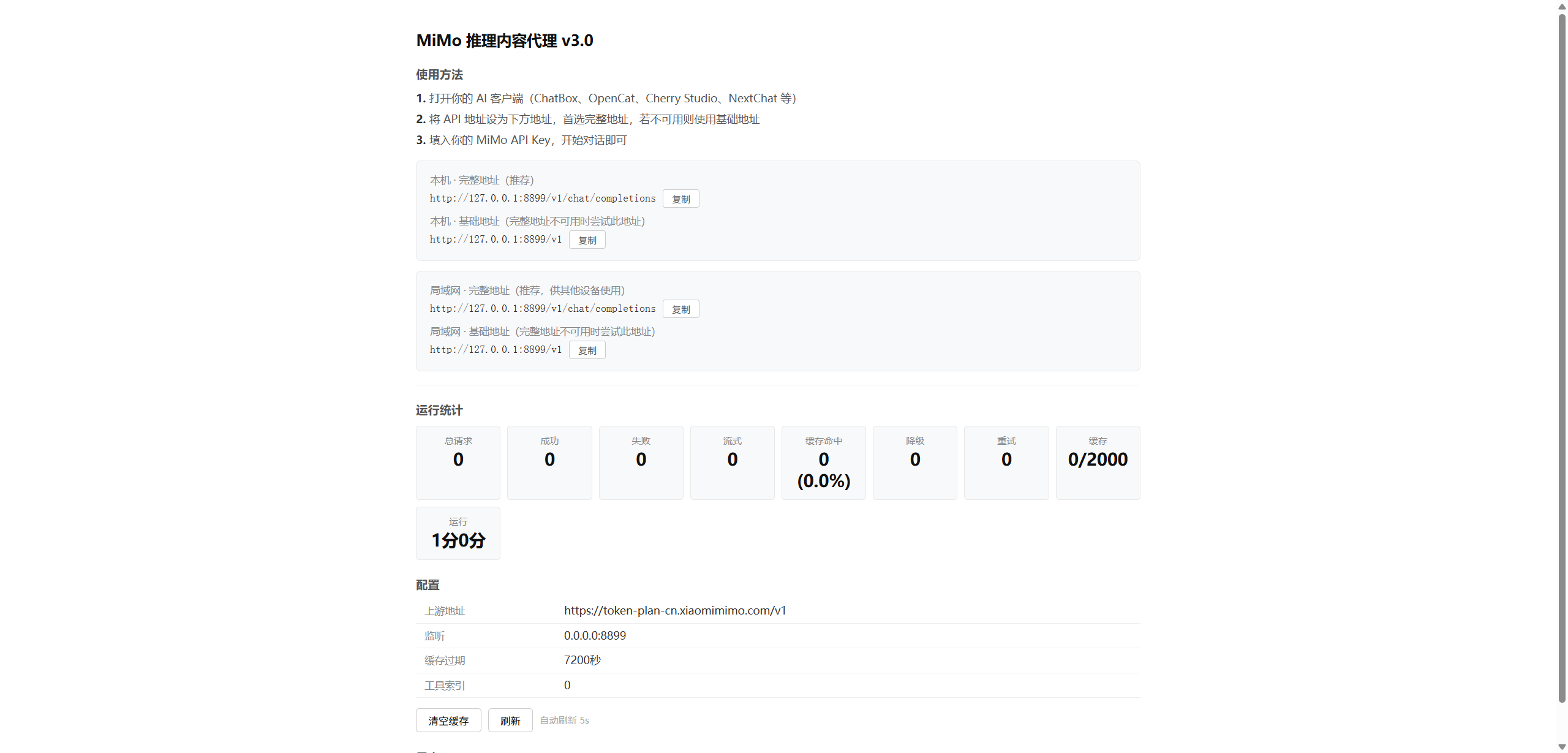
1.下载exe程序后双击运行如下
2.按住Ctrl然后点击管理面板的链接跳转打开管理面板
http://127.0.0.1:8899/dashboard
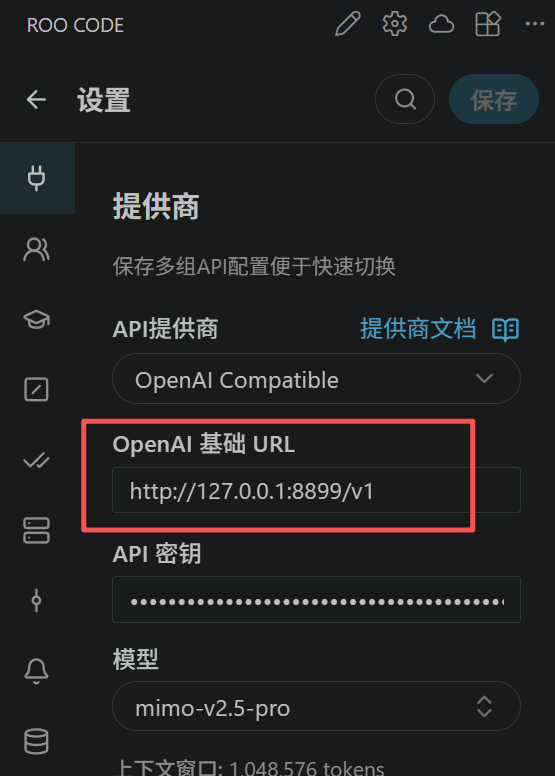
3.复制本地代理地址,替换到相应的客户端上 http://127.0.0.1:8899/v1
4.保存之后即可正常运行。
下面是已知限制
- 缓存基于内存,重启后丢失(新对话会自动重建)
- 降级处理(剥离 tool_calls)会导致模型丢失工具调用的上下文
- 仅支持 OpenAI 兼容的
/v1/chat/completions端点

邀请码
我在用 MiMo 开放平台体验 小米顶尖模型 MiMo V2.5等 ,通过我的邀请码注册为新用户,即得 ¥10 API 体验金。邀请码:HA428C。注册:https://platform.xiaomimimo.com?ref=HA428C (注册后点控制台左下方入口填入,体验金40天有效)
开源代码
python
"""
MiMo Reasoning Content Proxy
"""
import logging
import os
import socket
import sys
from pathlib import Path
import uvicorn
def check_prerequisites():
"""检查运行前置条件"""
errors = []
# 检查配置文件
config_path = os.getenv("MIMO_CONFIG_FILE", "config.yaml")
if not Path(config_path).exists():
errors.append(f"配置文件不存在: {config_path}")
errors.append("请复制 config.example.yaml 为 config.yaml 并修改配置")
# 检查模板文件
template_dir = os.getenv("MIMO_TEMPLATE_DIR", os.path.join(os.path.dirname(__file__), "..", "templates"))
template_path = Path(template_dir) / "dashboard.html"
if not template_path.exists():
errors.append(f"仪表盘模板不存在: {template_path}")
# 检查依赖
missing_deps = []
for dep in ["httpx", "starlette", "uvicorn", "yaml", "aiofiles"]:
try:
__import__(dep)
except ImportError:
# yaml 的包名是 pyyaml
if dep == "yaml":
try:
__import__("yaml")
except ImportError:
missing_deps.append("pyyaml")
else:
missing_deps.append(dep)
if missing_deps:
errors.append(f"缺少依赖: {', '.join(missing_deps)}")
errors.append("请运行: pip install -r requirements.txt")
return errors
def main():
print("""
╔══════════════════════════════════════════════╗
║ MiMo Reasoning Content Proxy - 开源版 ║
╚══════════════════════════════════════════════╝
""")
# 前置检查
errors = check_prerequisites()
if errors:
print("❌ 启动检查失败:\n")
for e in errors:
print(f" • {e}")
print("\n请按照提示完成配置后重试。")
print("完整部署指南请参考项目文档。")
sys.exit(1)
# 加载配置
from .config import load_config
config = load_config()
# 配置日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(name)s] %(message)s",
datefmt="%H:%M:%S",
)
# 创建应用
from .routes import create_app
app = create_app(config)
# 获取本机 IP
local_ip = "127.0.0.1"
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(("8.8.8.8", 80))
local_ip = s.getsockname()[0]
s.close()
except Exception:
pass
print(f"""
════════════════════════════════════════════════
MiMo Proxy 开源版
════════════════════════════════════════════════
API: http://127.0.0.1:{config.server.port}/v1/chat/completions
LAN: http://{local_ip}:{config.server.port}/v1/chat/completions
Dash: http://127.0.0.1:{config.server.port}/dashboard
Cache: {config.cache.backend} (max={config.cache.max_size}, ttl={config.cache.ttl_seconds}s)
════════════════════════════════════════════════
""")
uvicorn.run(app, host=config.server.host, port=config.server.port, log_level="info")
if __name__ == "__main__":
main()
python
"""
日志缓冲 & 管理面板模块
"""
import logging
import os
import time
from pathlib import Path
import aiofiles
class LogBuffer(logging.Handler):
"""保留最近 N 条日志供面板展示"""
def __init__(self, capacity: int = 200):
super().__init__()
self.capacity = capacity
self.entries: list[dict] = []
def emit(self, record: logging.LogRecord):
self.entries.append({
"time": time.strftime("%H:%M:%S", time.localtime(record.created)),
"level": record.levelname,
"msg": self.format(record),
})
if len(self.entries) > self.capacity:
self.entries = self.entries[-self.capacity:]
async def load_dashboard_html() -> str:
"""从外部模板文件加载仪表盘 HTML"""
# 查找模板路径:优先环境变量 → 相对路径
template_dir = os.getenv("MIMO_TEMPLATE_DIR", os.path.join(os.path.dirname(__file__), "..", "templates"))
template_path = Path(template_dir) / "dashboard.html"
if not template_path.exists():
raise FileNotFoundError(
f"仪表盘模板文件不存在: {template_path}\n"
f"请确保 templates/dashboard.html 文件存在,或设置 MIMO_TEMPLATE_DIR 环境变量"
)
async with aiofiles.open(template_path, "r", encoding="utf-8") as f:
return await f.read()
class DashboardRenderer:
"""延迟加载并缓存仪表盘 HTML"""
def __init__(self):
self._html: str | None = None
async def render(self, **kwargs) -> str:
if self._html is None:
self._html = await load_dashboard_html()
# 简单模板替换
html = self._html
for key, val in kwargs.items():
html = html.replace(f"{{{{{key}}}}}", str(val))
return html
python
"""
配置加载模块
支持 YAML 配置文件 + 环境变量覆盖
"""
import os
from pathlib import Path
from dataclasses import dataclass, field
import yaml
@dataclass
class RedisConfig:
url: str = "redis://localhost:6379/0"
prefix: str = "mimo:rc:"
@dataclass
class CacheConfig:
max_size: int = 2000
ttl_seconds: int = 7200
backend: str = "memory" # "memory" | "redis"
redis: RedisConfig = field(default_factory=RedisConfig)
@dataclass
class ServerConfig:
host: str = "0.0.0.0"
port: int = 8899
@dataclass
class LoggingConfig:
persistent: bool = False
db_path: str = "./logs/mimo_proxy.db"
retain_days: int = 7
@dataclass
class RetryConfig:
max_retries: int = 3
backoff_base: int = 2
@dataclass
class DashboardConfig:
enabled: bool = True
log_buffer_size: int = 200
@dataclass
class AppConfig:
upstream_api_base: str = "https://token-plan-cn.xiaomimimio.com/v1"
server: ServerConfig = field(default_factory=ServerConfig)
cache: CacheConfig = field(default_factory=CacheConfig)
logging: LoggingConfig = field(default_factory=LoggingConfig)
retry: RetryConfig = field(default_factory=RetryConfig)
dashboard: DashboardConfig = field(default_factory=DashboardConfig)
def _deep_merge(base: dict, override: dict) -> dict:
"""递归合并字典,override 优先"""
result = base.copy()
for k, v in override.items():
if k in result and isinstance(result[k], dict) and isinstance(v, dict):
result[k] = _deep_merge(result[k], v)
else:
result[k] = v
return result
def _apply_env_overrides(cfg_dict: dict) -> dict:
"""环境变量覆盖配置"""
env_map = {
"MIMO_API_BASE": "upstream_api_base",
"MIMO_LISTEN_HOST": "server.host",
"MIMO_LISTEN_PORT": ("server.port", int),
"MIMO_CACHE_MAX_SIZE": ("cache.max_size", int),
"MIMO_CACHE_TTL": ("cache.ttl_seconds", int),
"MIMO_CACHE_BACKEND": "cache.backend",
"MIMO_REDIS_URL": "cache.redis.url",
"MIMO_LOG_PERSISTENT": ("logging.persistent", lambda x: x.lower() in ("true", "1", "yes")),
"MIMO_LOG_DB_PATH": "logging.db_path",
}
for env_key, path in env_map.items():
val = os.getenv(env_key)
if val is None:
continue
converter = None
if isinstance(path, tuple):
path, converter = path
if converter:
val = converter(val)
keys = path.split(".")
d = cfg_dict
for k in keys[:-1]:
d = d.setdefault(k, {})
d[keys[-1]] = val
return cfg_dict
def load_config(config_path: str | None = None) -> AppConfig:
"""加载配置:YAML 文件 + 环境变量覆盖"""
cfg_dict = {}
if config_path is None:
config_path = os.getenv("MIMO_CONFIG_FILE", "config.yaml")
path = Path(config_path)
if path.exists():
with open(path, "r", encoding="utf-8") as f:
cfg_dict = yaml.safe_load(f) or {}
else:
print(f"[WARN] 配置文件不存在: {config_path}")
print(f"[WARN] 将使用默认配置 + 环境变量")
print(f"[HINT] 请复制 config.example.yaml 为 config.yaml 并修改")
cfg_dict = _apply_env_overrides(cfg_dict)
# 手动构建 dataclass(不支持递归 from_dict)
server_cfg = ServerConfig(**cfg_dict.get("server", {}))
redis_cfg = RedisConfig(**cfg_dict.get("cache", {}).get("redis", {}))
cache_raw = cfg_dict.get("cache", {})
cache_raw.pop("redis", None)
cache_cfg = CacheConfig(**cache_raw, redis=redis_cfg)
logging_cfg = LoggingConfig(**cfg_dict.get("logging", {}))
retry_cfg = RetryConfig(**cfg_dict.get("retry", {}))
dashboard_cfg = DashboardConfig(**cfg_dict.get("dashboard", {}))
return AppConfig(
upstream_api_base=cfg_dict.get("upstream_api_base", AppConfig.upstream_api_base),
server=server_cfg,
cache=cache_cfg,
logging=logging_cfg,
retry=retry_cfg,
dashboard=dashboard_cfg,
)
python
"""
缓存模块
支持内存缓存 (LRU+TTL) 和 Redis 缓存
"""
import hashlib
import json
import logging
import time
from collections import OrderedDict
from typing import Optional
log = logging.getLogger("mimo-proxy")
class MemoryCache:
"""LRU + TTL 内存缓存,支持 tool_call_id 索引"""
def __init__(self, max_size: int = 2000, ttl: int = 7200):
self._data: OrderedDict[str, tuple[str, float]] = OrderedDict()
self._tc_index: dict[str, str] = {}
self.max_size = max_size
self.ttl = ttl
@property
def size(self) -> int:
return len(self._data)
@staticmethod
def msg_hash(msg: dict) -> str:
content = msg.get("content") or ""
tc = json.dumps(msg.get("tool_calls") or [], sort_keys=True, ensure_ascii=False)
return hashlib.sha256(f"{content}||{tc}".encode()).hexdigest()[:16]
@staticmethod
def tc_ids(msg: dict) -> list[str]:
return [t["id"] for t in msg.get("tool_calls") or [] if t.get("id")]
async def get(self, key: str) -> Optional[str]:
if key in self._data:
val, ts = self._data[key]
if time.time() - ts < self.ttl:
self._data.move_to_end(key)
return val
del self._data[key]
return None
async def set(self, key: str, value: str, tool_call_ids: list[str] | None = None):
if key in self._data:
del self._data[key]
self._data[key] = (value, time.time())
while len(self._data) > self.max_size:
self._data.popitem(last=False)
if tool_call_ids:
for tid in tool_call_ids:
self._tc_index[tid] = value
async def lookup(self, msg: dict) -> Optional[str]:
h = self.msg_hash(msg)
cached = await self.get(h)
if cached:
return cached
for tid in self.tc_ids(msg):
if tid in self._tc_index:
return self._tc_index[tid]
return None
async def clear(self):
self._data.clear()
self._tc_index.clear()
def info(self) -> dict:
return {"size": self.size, "max": self.max_size, "ttl": self.ttl, "tc_index": len(self._tc_index), "backend": "memory"}
class RedisCache:
"""Redis 缓存后端"""
def __init__(self, redis_url: str = "redis://localhost:6379/0", prefix: str = "mimo:rc:",
ttl: int = 7200, max_size: int = 2000):
self._redis = None
self._redis_url = redis_url
self._prefix = prefix
self.ttl = ttl
self.max_size = max_size
self._tc_index_prefix = prefix + "tcidx:"
async def _ensure_connection(self):
if self._redis is None:
try:
import redis.asyncio as aioredis
self._redis = aioredis.from_url(self._redis_url, decode_responses=True)
await self._redis.ping()
log.info("Redis 连接成功: %s", self._redis_url)
except ImportError:
raise RuntimeError("Redis 后端需要安装 redis 包: pip install redis")
except Exception as e:
self._redis = None
raise ConnectionError(f"Redis 连接失败: {e}")
@staticmethod
def msg_hash(msg: dict) -> str:
content = msg.get("content") or ""
tc = json.dumps(msg.get("tool_calls") or [], sort_keys=True, ensure_ascii=False)
return hashlib.sha256(f"{content}||{tc}".encode()).hexdigest()[:16]
@staticmethod
def tc_ids(msg: dict) -> list[str]:
return [t["id"] for t in msg.get("tool_calls") or [] if t.get("id")]
async def get(self, key: str) -> Optional[str]:
await self._ensure_connection()
return await self._redis.get(f"{self._prefix}{key}")
async def set(self, key: str, value: str, tool_call_ids: list[str] | None = None):
await self._ensure_connection()
pipe = self._redis.pipeline()
pipe.setex(f"{self._prefix}{key}", self.ttl, value)
if tool_call_ids:
for tid in tool_call_ids:
pipe.setex(f"{self._tc_index_prefix}{tid}", self.ttl, value)
await pipe.execute()
async def lookup(self, msg: dict) -> Optional[str]:
h = self.msg_hash(msg)
cached = await self.get(h)
if cached:
return cached
for tid in self.tc_ids(msg):
val = await self._redis.get(f"{self._tc_index_prefix}{tid}")
if val:
return val
return None
async def clear(self):
await self._ensure_connection()
async for key in self._redis.scan_iter(f"{self._prefix}*"):
await self._redis.delete(key)
async for key in self._redis.scan_iter(f"{self._tc_index_prefix}*"):
await self._redis.delete(key)
def info(self) -> dict:
return {"size": "?", "max": self.max_size, "ttl": self.ttl, "tc_index": "?", "backend": "redis"}
def create_cache(backend: str = "memory", **kwargs):
if backend == "redis":
return RedisCache(**kwargs)
return MemoryCache(**kwargs)
python
"""
核心代理逻辑模块
注入 reasoning_content、流式代理、非流式代理
"""
import asyncio
import json
import logging
import httpx
from .cache import MemoryCache, RedisCache
from .stats import Stats
from .config import RetryConfig
log = logging.getLogger("mimo-proxy")
def inject_reasoning(messages: list[dict], cache: MemoryCache | RedisCache, stats: Stats) -> tuple[int, int]:
"""注入缓存的 reasoning_content,无缓存则降级剥离 tool_calls"""
injected = degraded = 0
for i, msg in enumerate(messages):
if msg.get("role") != "assistant" or not msg.get("tool_calls") or msg.get("reasoning_content"):
continue
# 同步查找(内存缓存)/ 异步需要特殊处理
# 这里为了兼容,使用同步接口
cached = None
if isinstance(cache, MemoryCache):
h = cache.msg_hash(msg)
cached_val = cache._data.get(h)
if cached_val:
import time
val, ts = cached_val
if time.time() - ts < cache.ttl:
cached = val
else:
del cache._data[h]
if not cached:
for tid in cache.tc_ids(msg):
if tid in cache._tc_index:
cached = cache._tc_index[tid]
break
if cached:
msg["reasoning_content"] = cached
injected += 1
stats.cache_hits += 1
log.info("Injected reasoning msg[%d] (%d chars)", i, len(cached))
else:
ids = MemoryCache.tc_ids(msg)
stats.cache_misses += 1
log.warning("No cache msg[%d] ids=%s → degrading", i, ids)
content = msg.get("content") or ""
summary = " ".join(
f"[Called {tc.get('function', {}).get('name', '?')}]"
for tc in msg.get("tool_calls") or []
)
msg["content"] = f"{content} {summary}".strip()
del msg["tool_calls"]
degraded += 1
stats.degraded += 1
return injected, degraded
def save_reasoning(msg: dict, cache: MemoryCache | RedisCache):
"""缓存 assistant 消息中的 reasoning_content"""
rc = msg.get("reasoning_content")
if rc and msg.get("tool_calls"):
h = cache.msg_hash(msg)
tc_ids = cache.tc_ids(msg)
if isinstance(cache, MemoryCache):
import time as _time
if h in cache._data:
del cache._data[h]
cache._data[h] = (rc, _time.time())
while len(cache._data) > cache.max_size:
cache._data.popitem(last=False)
for tid in tc_ids:
cache._tc_index[tid] = rc
log.info("Cached reasoning (%d chars)", len(rc))
def _sse(data: str) -> bytes:
return f"data: {data}\n\n".encode()
async def stream_proxy(
upstream: str,
headers: dict,
body: dict,
client: httpx.AsyncClient,
cache: MemoryCache | RedisCache,
stats: Stats,
retry_config: RetryConfig,
):
"""流式转发,同时累积 reasoning_content 用于缓存"""
acc_content = ""
acc_reasoning = ""
acc_tc: list[dict] = []
for attempt in range(retry_config.max_retries):
try:
async with client.stream("POST", upstream, headers=headers, json=body) as resp:
if resp.status_code != 200:
err = (await resp.aread()).decode("utf-8", errors="replace")
log.warning("Stream %d (attempt %d): %s", resp.status_code, attempt + 1, err[:200])
if resp.status_code < 500:
yield _sse(err)
return
if attempt < retry_config.max_retries - 1:
await asyncio.sleep(retry_config.backoff_base * (attempt + 1))
continue
yield _sse(json.dumps({"error": {"message": err[:200], "code": "502"}}))
return
buf = ""
async for chunk in resp.aiter_bytes():
buf += chunk.decode("utf-8", errors="replace")
while "\n" in buf:
line, buf = buf.split("\n", 1)
line = line.rstrip("\r")
if line.startswith("data: "):
payload = line[6:].strip()
if payload == "[DONE]":
if acc_reasoning and (acc_content or acc_tc):
synthetic = {
"role": "assistant",
"content": acc_content,
"tool_calls": acc_tc,
"reasoning_content": acc_reasoning,
}
save_reasoning(synthetic, cache)
yield _sse("[DONE]")
continue
try:
chunk_data = json.loads(payload)
delta = chunk_data.get("choices", [{}])[0].get("delta", {})
if v := delta.get("reasoning_content"):
acc_reasoning += v
if v := delta.get("content"):
acc_content += v
for tc in delta.get("tool_calls") or []:
idx = tc.get("index", 0)
while len(acc_tc) <= idx:
acc_tc.append({
"id": "", "type": "function",
"function": {"name": "", "arguments": ""}
})
if tc.get("id"):
acc_tc[idx]["id"] = tc["id"]
fn = tc.get("function", {})
if fn.get("name"):
acc_tc[idx]["function"]["name"] += fn["name"]
if fn.get("arguments"):
acc_tc[idx]["function"]["arguments"] += fn["arguments"]
except (json.JSONDecodeError, IndexError, KeyError):
pass
yield _sse(payload)
elif line.strip() == "":
yield b"\n"
elif line.startswith(":"):
yield (line + "\n\n").encode()
else:
yield (line + "\n").encode()
return
except httpx.TimeoutException as e:
log.warning("Stream timeout (attempt %d): %s", attempt + 1, e)
stats.retries += 1
if attempt < retry_config.max_retries - 1:
await asyncio.sleep(retry_config.backoff_base * (attempt + 1))
except Exception as e:
log.error("Stream error: %s", e, exc_info=True)
yield _sse(json.dumps({"error": str(e)}))
return
yield _sse(json.dumps({"error": {"message": "Stream failed after retries", "code": "502"}}))
python
"""
路由定义模块
"""
import asyncio
import json
import logging
from contextlib import asynccontextmanager
import httpx
from starlette.applications import Starlette
from starlette.requests import Request
from starlette.responses import HTMLResponse, JSONResponse, StreamingResponse
from starlette.routing import Route
from .cache import MemoryCache, RedisCache, create_cache
from .config import AppConfig
from .dashboard import LogBuffer, DashboardRenderer
from .proxy import inject_reasoning, save_reasoning, stream_proxy
from .stats import Stats
log = logging.getLogger("mimo-proxy")
class AppContext:
"""应用上下文,持有所有共享状态"""
def __init__(self, config: AppConfig):
self.config = config
self.stats = Stats()
self.cache: MemoryCache | RedisCache = create_cache(
backend=config.cache.backend,
max_size=config.cache.max_size,
ttl=config.cache.ttl_seconds,
redis_url=config.cache.redis.url,
prefix=config.cache.redis.prefix,
)
self.log_buffer = LogBuffer(capacity=config.dashboard.log_buffer_size)
self.dashboard_renderer = DashboardRenderer()
self.client: httpx.AsyncClient | None = None
def get_client(self) -> httpx.AsyncClient:
if self.client is None or self.client.is_closed:
self.client = httpx.AsyncClient(
timeout=httpx.Timeout(300, connect=30),
follow_redirects=True,
)
return self.client
def create_routes(ctx: AppContext) -> list[Route]:
"""根据配置创建路由列表"""
async def chat_completions(request: Request):
ctx.stats.requests += 1
try:
body = await request.json()
except Exception:
ctx.stats.failed += 1
return JSONResponse({"error": "Invalid JSON"}, status_code=400)
messages = body.get("messages", [])
inj, deg = inject_reasoning(messages, ctx.cache, ctx.stats)
if inj or deg:
log.info("Inject=%d Degrade=%d", inj, deg)
headers = {}
if auth := request.headers.get("authorization"):
headers["authorization"] = auth
upstream = f"{ctx.config.upstream_api_base}/chat/completions"
is_stream = body.get("stream", False)
if is_stream:
ctx.stats.stream += 1
ctx.stats.success += 1
return StreamingResponse(
stream_proxy(upstream, headers, body, ctx.get_client(), ctx.cache, ctx.stats, ctx.config.retry),
media_type="text/event-stream",
headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"},
)
# 非流式:带重试
resp = None
for attempt in range(ctx.config.retry.max_retries):
try:
resp = await ctx.get_client().post(upstream, headers=headers, json=body)
if resp.status_code >= 500 and attempt < ctx.config.retry.max_retries - 1:
ctx.stats.retries += 1
log.warning("Upstream %d (attempt %d)", resp.status_code, attempt + 1)
await asyncio.sleep(ctx.config.retry.backoff_base * (attempt + 1))
continue
break
except httpx.TimeoutException:
ctx.stats.retries += 1
if attempt < ctx.config.retry.max_retries - 1:
await asyncio.sleep(ctx.config.retry.backoff_base * (attempt + 1))
continue
ctx.stats.failed += 1
return JSONResponse({"error": "Timeout after retries"}, status_code=504)
except Exception as e:
ctx.stats.failed += 1
return JSONResponse({"error": str(e)}, status_code=500)
if resp is None:
ctx.stats.failed += 1
return JSONResponse({"error": "No response"}, status_code=502)
if resp.status_code >= 400:
ctx.stats.failed += 1
return JSONResponse({"error": resp.text[:300]}, status_code=resp.status_code)
data = resp.json()
for ch in data.get("choices", []):
msg = ch.get("message", {})
if not msg.get("content") and not msg.get("tool_calls") and msg.get("reasoning_content"):
msg["content"] = msg["reasoning_content"]
save_reasoning(msg, ctx.cache)
ctx.stats.success += 1
return JSONResponse(data)
async def list_models(request: Request):
headers = {}
if auth := request.headers.get("authorization"):
headers["authorization"] = auth
try:
resp = await ctx.get_client().get(f"{ctx.config.upstream_api_base}/models", headers=headers)
return JSONResponse(resp.json(), status_code=resp.status_code)
except Exception as e:
return JSONResponse({"error": str(e)}, status_code=502)
async def api_stats(request: Request):
return JSONResponse({
"stats": ctx.stats.to_dict(),
"cache": ctx.cache.info(),
"upstream": ctx.config.upstream_api_base,
})
async def api_logs(request: Request):
n = min(int(request.query_params.get("count", "50")), 200)
return JSONResponse({"logs": ctx.log_buffer.entries[-n:]})
async def api_cache_clear(request: Request):
await ctx.cache.clear()
log.info("Cache cleared")
return JSONResponse({"ok": True})
async def dashboard(request: Request):
try:
html = await ctx.dashboard_renderer.render(
HOST=ctx.config.server.host,
PORT=ctx.config.server.port,
)
return HTMLResponse(html)
except FileNotFoundError as e:
return HTMLResponse(f"<h1>模板加载失败</h1><pre>{e}</pre>", status_code=500)
async def root(request: Request):
return JSONResponse({
"status": "running",
"service": "MiMo Reasoning Content Proxy (OSS)",
"cache_size": ctx.cache.info().get("size", "?"),
"upstream": ctx.config.upstream_api_base,
"uptime": ctx.stats.uptime,
"dashboard": f"http://127.0.0.1:{ctx.config.server.port}/dashboard",
})
routes = [
Route("/", root),
Route("/health", lambda r: JSONResponse({"ok": True})),
Route("/v1/chat/completions", chat_completions, methods=["POST"]),
Route("/chat/completions", chat_completions, methods=["POST"]),
Route("/v1/models", list_models),
Route("/models", list_models),
]
if ctx.config.dashboard.enabled:
routes += [
Route("/dashboard", dashboard),
Route("/api/stats", api_stats),
Route("/api/logs", api_logs),
Route("/api/cache/clear", api_cache_clear, methods=["POST"]),
]
return routes
def create_app(config: AppConfig) -> Starlette:
"""创建 Starlette 应用"""
ctx = AppContext(config)
# 设置日志
ctx.log_buffer.setFormatter(logging.Formatter("%(message)s"))
log.addHandler(ctx.log_buffer)
routes = create_routes(ctx)
@asynccontextmanager
async def lifespan(app):
ctx.client = httpx.AsyncClient(
timeout=httpx.Timeout(300, connect=30),
follow_redirects=True,
)
yield
if ctx.client:
await ctx.client.aclose()
return Starlette(routes=routes, lifespan=lifespan)
python
"""
统计数据模块
"""
import time
from dataclasses import dataclass, field
@dataclass
class Stats:
start_time: float = field(default_factory=time.time)
requests: int = 0
success: int = 0
failed: int = 0
stream: int = 0
cache_hits: int = 0
cache_misses: int = 0
degraded: int = 0
retries: int = 0
@property
def uptime(self) -> str:
s = int(time.time() - self.start_time)
for unit, div in [("天", 86400), ("时", 3600), ("分", 60)]:
if s >= div:
return f"{s // div}{unit}{s % div // 60}分"
return f"{s}秒"
def to_dict(self) -> dict:
hit_total = max(self.cache_hits + self.cache_misses, 1)
return {
"uptime": self.uptime,
"requests": self.requests,
"success": self.success,
"failed": self.failed,
"stream": self.stream,
"cache_hits": self.cache_hits,
"hit_rate": f"{self.cache_hits / hit_total * 100:.1f}%",
"degraded": self.degraded,
"retries": self.retries,
}