论文:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
RLHF
https://blog.csdn.net/pipisorry/article/details/134052380?

DPO算法
DPO loss推导过程
目标函数

通过目标函数推导出最优RM模型的形式


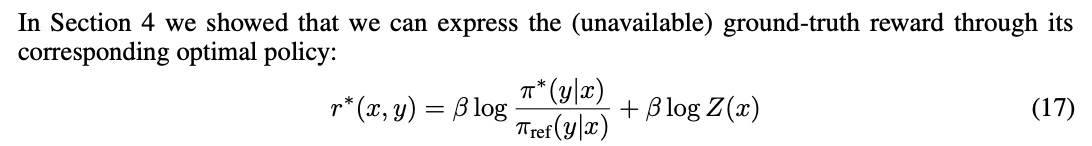
Note: 这里的r(x,y)是无法直接求解的,因为Z中也包含r。但可以说明的是最优的语言模型,实际上都对应着一个隐含的RM,也就是说最优的语言模型自然隐含着一个最优的RM。
将r(x,y)代入BT模型学习偏好目标:
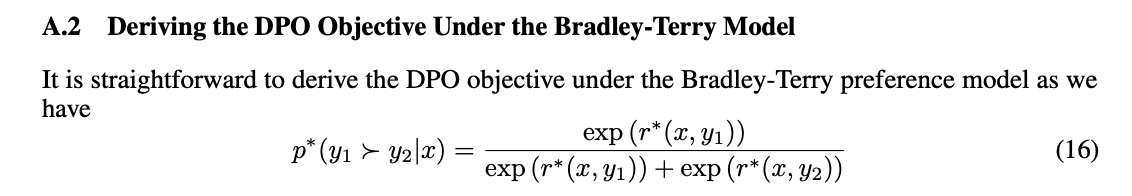
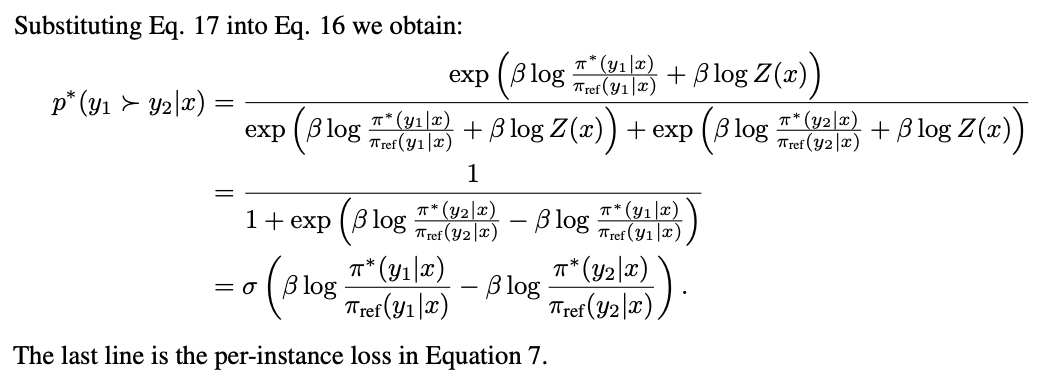
得到最终DPO的loss:
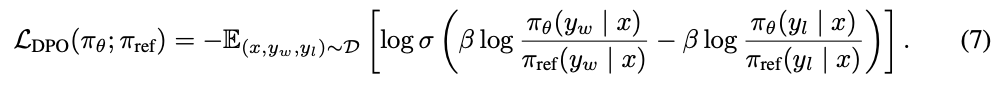
DPO优化求导解析

DPO梯度更新的直观理解:增加被人类偏好数据的生成概率,降低不被人类偏好,同时模隐式reward误差越大,权重也越大。
DPO的训练流程
去除了Reward Model和强化学习部分的训练,DPO算法不需要也不包含critic的V(s)它直接优化πθ。
两步骤进行训练:
1 用收集的人类偏好数据中更受偏好的数据SFT模型;
2 在该SFT模型上,用人类偏好数据,通过DPO训练目标训练模型。
Note: DPO看上去只学习了r和偏好,所以需要训练的第一步更好?
DPO训练语料prompt+1正例+1反例:
{
"prompt": "What is the capital of China?",
"chosen": "The capital of China is Beijing.",
"rejected": "The capital of China is Shanghai."
}DPO算法评价
DPO与SFT
DPO的训练更像 SFT,但从理论基础和目标看仍然属于RL算法。SFT 的目标仅仅是模仿数据分布(最大化似然),并不关心"好"与"差"的相对排序或奖励最大化。DPO 关心的是偏序关系,这是 RL(特别是偏好优化)的核心。
DPO 是披着 SFT 外衣的 RL 算法。 它继承了 RL 的核心目标(最大化偏好/奖励),但通过巧妙的数学变换,将计算化简为了监督学习的损失函数,从而获得了 SFT 的便利性和 RL 的对齐效果。
这也正是 DPO 大受欢迎的原因:用 SFT 的简单性,实现了 RL 的对齐能力。
DPO与RLHF
虽理论上DPO与RLHF等价,但偏好数据有限训练出的Policy并不最优,对应的RM不能准确代表偏好。而训练一个泛化的RM可帮助优化出一个泛化性更强的Policy
DPO与PPO
| 特性 | PPO (传统 RL) | DPO |
|---|---|---|
| 训练方式 | 在线/离线采样 + 重要性采样 | 静态数据集上的分类目标 |
| 需要环境交互 | 是 | 否 |
| 需要价值函数 V(s) | 是 | 否 |
| 损失函数形式 | 策略梯度 + 裁剪 + KL惩罚 | 二分类损失 (如 logistic regression) |
| 核心操作 | (state, action) -> reward |
(chosen, rejected) -> preference |
只看代码,你会觉得 DPO 就是:拿两个文本给模型看,让它更倾向于生成 chosen,而不是 rejected。
DPO与对比学习
DPO不是对比学习,它优化的是获胜回答和失败回答的概率差,不是表征相似度。
对比学习是为了改善表征一致性,不适合用来"继续训练"以改变生成行为,强项在表征学习,不是策略优化。
不同范式的示例
SFT:你拿字帖(示范数据)给一个小孩,让他照着抄。目标是"写得像字帖"。
RL (PPO):你给小孩一个分数(奖励),让他自己试错写很多遍,每次根据分数调整写法。目标是"拿高分"。
DPO:你给小孩两篇作文(一篇好一篇差),让他学会"区分好坏并倾向于写好作文",但不让他真的去考试拿分。他学习的方式是看比较(分类),而不是试错(交互)。
from:https://blog.csdn.net/pipisorry/article/details/161107152