这篇论文《Anisotropic Modality Align》(各向异性模态对齐)是一篇深入探讨多模态大语言模型(MLLM)底层表征空间的理论与方法相结合的优秀研究。它打破了以往对"模态鸿沟(Modality Gap)"的粗略认知,从严格的几何视角对其进行了重新定义,并据此提出了一种极其有效且无需配对数据的对齐算法(AnisoAlign),最终实现了仅用纯文本数据就能训练出媲美甚至超越真实图文预训练模型的MLLM。
以下是对这篇论文的详细解读:
一、 核心背景与问题动机
1. 背景:
像CLIP这样的多模态对比学习模型,虽然能把图像和文本映射到同一个空间里,但即使经过大规模预训练,图像和文本的表征之间依然存在系统性的几何偏差,这就是著名的"模态鸿沟(Modality Gap)"。
2. 动机(终极目标):
如果我们能完美消除这个鸿沟,把文本特征"伪装"成完美的图像特征,我们就可以摆脱对极其稀缺且昂贵的高质量图文对(Paired Data)的依赖,仅用海量的纯文本数据来训练多模态大模型(MLLM)。
3. 现有方法的痛点:
以前的方法(如C3、ReAlign)通常把这个鸿沟简单看作是"中心点的偏移"或者用随机噪声去弥补。论文提出质疑:模态鸿沟到底是一种什么形态的几何差异?如果一味地去迎合目标模态(图像)的分布,会不会把源模态(文本)本身的语义结构给破坏掉?
在多模态对齐和消除"模态鸿沟(Modality Gap)"的研究领域,C 3 C^3 C3 和 ReAlign 是用来解决特征不对齐问题的无需训练(Training-free)的基线方法。
它们的核心目的和本论文一样:不使用真实的图像,仅通过数学或统计手段,把文本的特征向量"修改"成看起来像图像的特征向量。
以下是对这两种方法的通俗解释:
1. C 3 C^3 C3 方法 (Connect-Collapse-Corrupt)
C 3 C^3 C3 是一种非常简单直接的启发式方法。它的名字来源于它操作的三个步骤:
- Connect(连接): 它假设像 CLIP 这样的对比学习模型已经把图像和文本拉到了同一个大致的空间里(有了连接的基础)。
- Collapse(坍缩/消除偏移): 它认为模态鸿沟主要就是"中心点对不齐"。所以它直接计算出文本的总体中心点和图像的总体中心点,然后把文本特征整体平移,强行对齐到图像的中心。
- Corrupt(破坏/注入噪声): 这是它最简单粗暴的一步。平移之后,为了弥补剩下的分布差异,并增加一点鲁棒性,它直接给文本特征加上一层随机的高斯噪声,最后再把向量归一化。
❌ 为什么这篇论文(AnisoAlign)认为 C 3 C^3 C3 不好?
本论文的诊断发现,模态之间的差异并不是向四面八方均匀散开的(各向同性),而是集中在几个特定方向上(各向异性)。 C 3 C^3 C3 简单粗暴地加入"随机噪声",虽然让分布变宽了,但严重破坏了文本原本的语义结构(比如把原本相似的词语特征给随机冲散了),导致它在需要精细语义区分的任务上表现不佳。
2. ReAlign 方法 (Modality Gap-driven Subspace Alignment)
相比于加随机噪声的 C 3 C^3 C3,ReAlign 要聪明得多,它是一种基于统计学特征的对齐方法,试图在全局分布上做文章。它也包含三个步骤:
- Anchor Alignment(锚点对齐): 和 C 3 C^3 C3 的第一步一样,也是先消除"一阶平均数偏差",把文本的中心平移到图像的中心。
- Trace Alignment(迹/方差对齐): 平移之后,文本和图像的方差(也就是特征散布的范围)大小可能不一样。ReAlign 会计算全局的迹(Trace,代表总能量/总方差),然后等比例地缩放文本特征的残差 ,让文本特征的整体方差大小和图像特征一样。最重要的是,这一步它保留了文本原有的协方差结构(没有像 C 3 C^3 C3 那样加随机噪声破坏它)。
- Centroid Alignment(重心再对齐): 因为特征通常要映射到单位球面上(归一化),映射后中心又会跑偏,所以最后再做一次微调纠正。
❌ 为什么这篇论文(AnisoAlign)认为 ReAlign 还不够好?
ReAlign 确实比 C 3 C^3 C3 进步很大,因为它保留了源模态(文本)的语义结构。但是,本论文指出:ReAlign 做的仅仅是"全局"的统计匹配。
它只是把文本的方差"等比例放大或缩小"来凑图像的方差,却没有纠正那些具体阻碍两个模态融合的"特定主导方向"(各向异性残差方向)。这就好比一件衣服整体缩放了尺寸,但袖子和领子的比例依然不对。此外,ReAlign 是全局操作,缺乏针对每个样本实例的具体微调。
🌟 总结与对比:为什么本论文(AnisoAlign)能赢?
为了让你更直观地理解,我们可以把"把文本伪装成图像"比作"把一群中国人化妆成欧洲人":
- C 3 C^3 C3 的做法: 让所有人整体往欧洲人的聚居地走一步(平移中心),然后往每个人脸上随机泼不同颜色的颜料(加随机噪声)。结果:虽然站在一起了,但长相全毁了(语义破坏)。
- ReAlign 的做法: 让所有人走到欧洲人的聚居地,然后发现中国人普遍偏瘦,于是把所有人的体型按同一个全局比例放大(Trace对方差整体缩放)。结果:保留了原本的样貌特征,但依然没有变成欧洲人的骨相。
- AnisoAlign(本论文)的做法: 走到聚居地后,它发现差异并不在全身,而是集中在"鼻梁高度"和"眼窝深度"等少数几个特定的方向(各向异性残差) 。于是它提取了欧洲人的面部规律(阶段一:学习图像先验相位),然后在极其严格的微调范围内,针对性地修改这几个特定部位(阶段二:有界的残差修正)。结果:既完美保留了你是谁(保语义),又极其自然地融入了欧洲人的人群(兼容目标分布)。
二、 核心发现:重新诊断"模态鸿沟"
作者通过一系列几何诊断,得出了关于模态鸿沟的颠覆性结论:
- 发现1:图文模态已经具备"兼容的主导几何结构"。
图像和文本并不是在空间里各玩各的。它们的协方差特征值分布(长尾衰减)非常相似,且它们的主成分子空间重合度极高(远超随机基线)。这意味着:CLIP预训练已经为图文建立了一个共享的核心语义骨架。 - 发现2:鸿沟不仅仅是"中心偏移"。
如果只是中心没对齐,把文本的中心平移到图像中心,鸿沟就该消失。但实验发现,平移后依然存在巨大的误差(残差)。 - 发现3:残差不是随机噪声,而是"各向异性(Anisotropic)"的。
剩下的误差不是均匀向四面八方发散的(各向同性),而是高度集中在少数几个主导方向上。
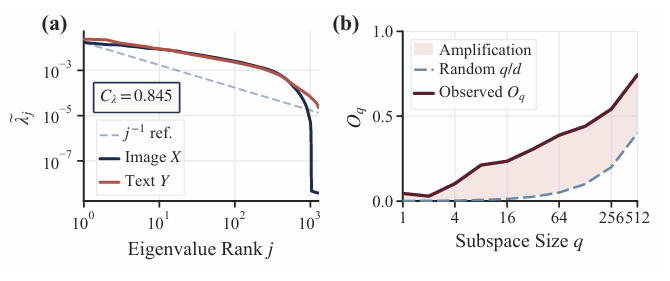
- 图1:图像与文本模态共享兼容的主导几何结构。a.两种模态的归一化协方差谱呈现相似的长尾衰减特性。b.它们的主子空间重叠度始终高于随机基线。
🌟 推导出对齐的终极原则(Anisotropic Modality Alignment):
有效的对齐绝不能只是简单地把文本拉向图像的分布,而是必须做到两点:
- 保语义: 维持源模态(文本)内部已有的语义几何结构不变。
- 修方向: 针对性地修正那些阻碍融合的"少数各向异性残差方向"。
三、 提出的方法:AnisoAlign 框架
基于上述原则,作者提出了一个极其精巧的纯文本(非配对)对齐算法。它分为两大阶段:
准备工作:固定子空间分解 & 极坐标解耦 (Sec 4.1 & 4.2)
- 分解: 把整个表征空间拆分为"主导子空间 U U U"和"正交残差空间 V V V"。
- 极坐标化: 在主导空间 U U U 内,将特征两两分组,转换为极坐标(半径 ρ \rho ρ 和 相位/角度 θ \theta θ) 。
- 为什么用极坐标? 因为角度(相位)能极好地刻画方向的变化(各向异性),而半径代表能量。这比直接在欧式空间里加减坐标要符合几何本质得多。
阶段一:目标模态(图像)的周期性先验预训练 (Sec 4.3)
- 这一步完全不需要文本,只看图像。
- 在这个极坐标空间里,图像的"相位(角度)"是有特定的统计规律和依赖关系的。作者通过一个得分网络(Score Network)学习了图像相位的"物理场(Drift Field)"。
- 目的: 获得一个"先验指南针",它知道真正图像特征的角度分布应该长什么样。
阶段二:先验引导的、有界限的残差微调 (Sec 4.4)
- 开始把文本变成图像。
- 全局初始化: 先做粗调,把文本中心平移,并通过CDF(累积分布函数)把文本的半径分布拉齐到图像。
- 残差修正(核心创新): 引入一个网络来预测文本特征需要修正的偏移量( Δ θ , Δ ρ , Δ v \Delta\theta, \Delta\rho, \Delta v Δθ,Δρ,Δv)。
- 约束1(迎合图像): 修正后的角度,必须符合阶段一学习到的"图像先验指南针"(Prior-Matching Loss)。
- 约束2(保全文本语义): 最关键的一步,所有的修正量都被严格限制在极小范围内(使用了 tanh \tanh tanh 函数)。附录A.7给出了严密的数学证明:只要修正量是有界的,无论怎么变,文本词与词之间的点乘相似度(语义)就不会被破坏。
四、 实验结果与惊人结论
实验在"特征级"和"MLLM真实训练级"都取得了压倒性的成功。
1. 特征几何诊断层面:
- AnisoAlign 几乎完美消除了中心误差,残差的各向异性程度最低。
- 同时(图7),它极其稳定地保留了文本原本的实例一致性、相对几何关系和局部邻居结构(秒杀C3和ReAlign)。
2. MLLM 训练层面(见表1, 表2):
- 在完全不使用真实图片(Fully Text-Only)的设置下,仅用经过AnisoAlign转换的文本去训练多模态大模型,在各种感知、推理、防幻觉榜单上均取得最高平均分(47.49),打败了之前所有的纯文本对齐方法。
3. 最具颠覆性的结论(见表3):扩大纯文本数据规模,能超越真实图文数据!
- 作者做了个终极测试:用100万真实图文对(W/. Image) 得分 52.72。
- 用100万经过AnisoAlign转换的纯文本数据(AnisoAlign-1M)得分 51.60,已经非常逼近。
- 当用200万纯文本数据(AnisoAlign-2M)时,得分达到了 52.75,直接超越了使用100万真实图片的效果!
- 意义: 文本数据获取极度廉价且无限,只要有 AnisoAlign 这个"完美翻译官",大模型训练就可以用海量廉价文本替代昂贵的图片。
在传统的 MLLM 训练中,流程是:
bash
真实图片 -> 视觉编码器 (如 CLIP-ViT) -> 视觉特征向量 -> 投影层(MLP) -> 大语言模型 (LLM)在"纯文本训练"中,我们用文本特征替换掉视觉特征。流程变成了:
bash
描述性文本 -> 文本编码器 (如 CLIP-Text) -> 文本特征向量 -> 【对齐算法(如 AnisoAlign)】 ->
伪视觉特征向量 -> 投影层(MLP) -> 大语言模型 (LLM)训练结束后,模型部署。现在,真正的考验来了------用户上传了一张真正的照片(真狗在草地上玩球),再进行推理。
五、 总结
这篇论文的惊艳之处在于其"先验理顺,后做工程"的研究品味:
- 深刻的洞察: 把"模态鸿沟"这个模糊的经验现象,用数学语言严格证明为一种"低有效维度的各向异性结构残差"。
- 优雅的设计: 放弃了暴力对抗生成或全空间映射,采用了极具物理直觉的"极坐标解耦 + 角度场先验 + 有界微调"设计。
- 重大的应用价值: 证明了只要几何对齐做得足够好,大模型的视觉能力完全可以通过大规模纯文本数据"无中生有"地催生出来,为未来低成本训练多模态巨无霸模型指出了一条极具潜力的明路。