最近发现一个挺有意思的事。越来越多的人开始用视频转笔记类的工具,把B站视频或者播客丢进去,几分钟就能拿到一份带小标题、有时间戳的图文讲义。
我挺好奇这背后到底是怎么做到的。拆了一下技术链路,发现比想象中复杂不少。
第一环:语音识别(ASR)
最基础的一步,把音频信号转成文字。
现在主流的方案基本都是端到端深度学习。OpenAI开源的Whisper是用得比较多的一个,工业界还常用Conformer架构。核心思路差不多,先用声学模型提取音频的频谱特征,再通过解码器转成文字序列。
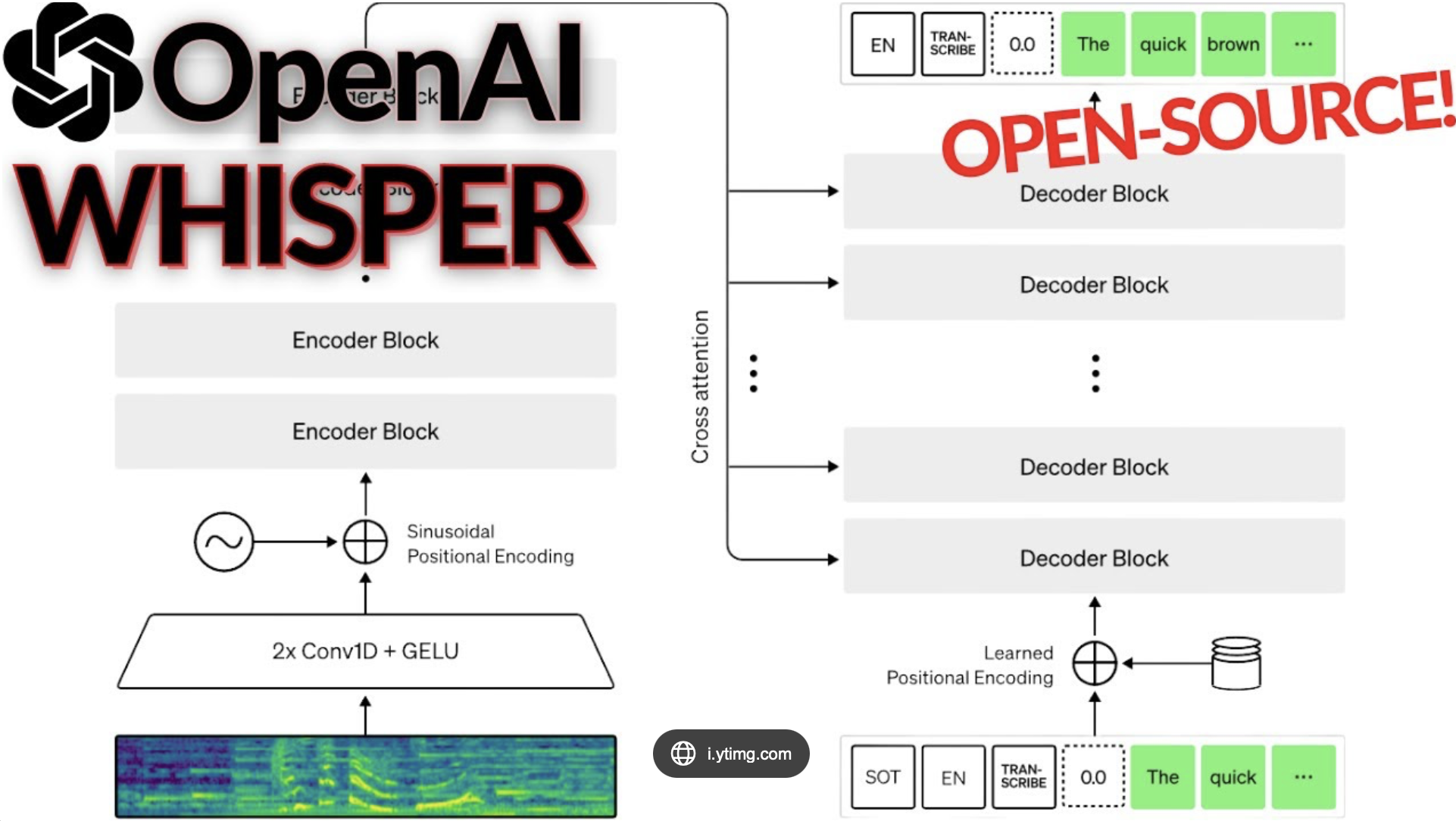
普通话场景下准确率都能做到90%以上。真正拉开差距的是专业术语和方言------金融、医学这些垂直领域的识别,需要在训练数据和模型微调上下功夫。

第二环:说话人分离
访谈类视频、播客、会议录音,通常有好几个人在说话。如果不去区分谁在讲,转出来的文字就是一坨......
技术路线一般是先用声纹特征(x-vector、ECAPA-TDNN这些)对每个时间片段做聚类,判断「这一段是谁说的」,然后给每句话打上说话人标签。

坦率地讲,这一步在多人激烈讨论的场景下还是会有错。安静的访谈好说,七八个人同时发言的圆桌会议,现在的技术还没法做到100%准确。
第三环:文本分段与结构化
拿到带说话人标签的逐字稿之后,下一步是理解内容的语义结构。
这里用到的是NLP里的文本分割和主题建模。算法会分析相邻句子之间的语义相似度,找到「话题转换点」,然后在这些位置切分段落。
更进一步的做法是用大语言模型来做段落标题生成。给模型一段原文,让它概括出一个小标题,这样最终的笔记就有了H2/H3的层级结构。
我自己摸索下来,这一步是整条链路里最关键的。转出文字谁都能做,但把几万字的逐字稿变成一篇有逻辑、可阅读的结构化笔记,这才是真正的难点。
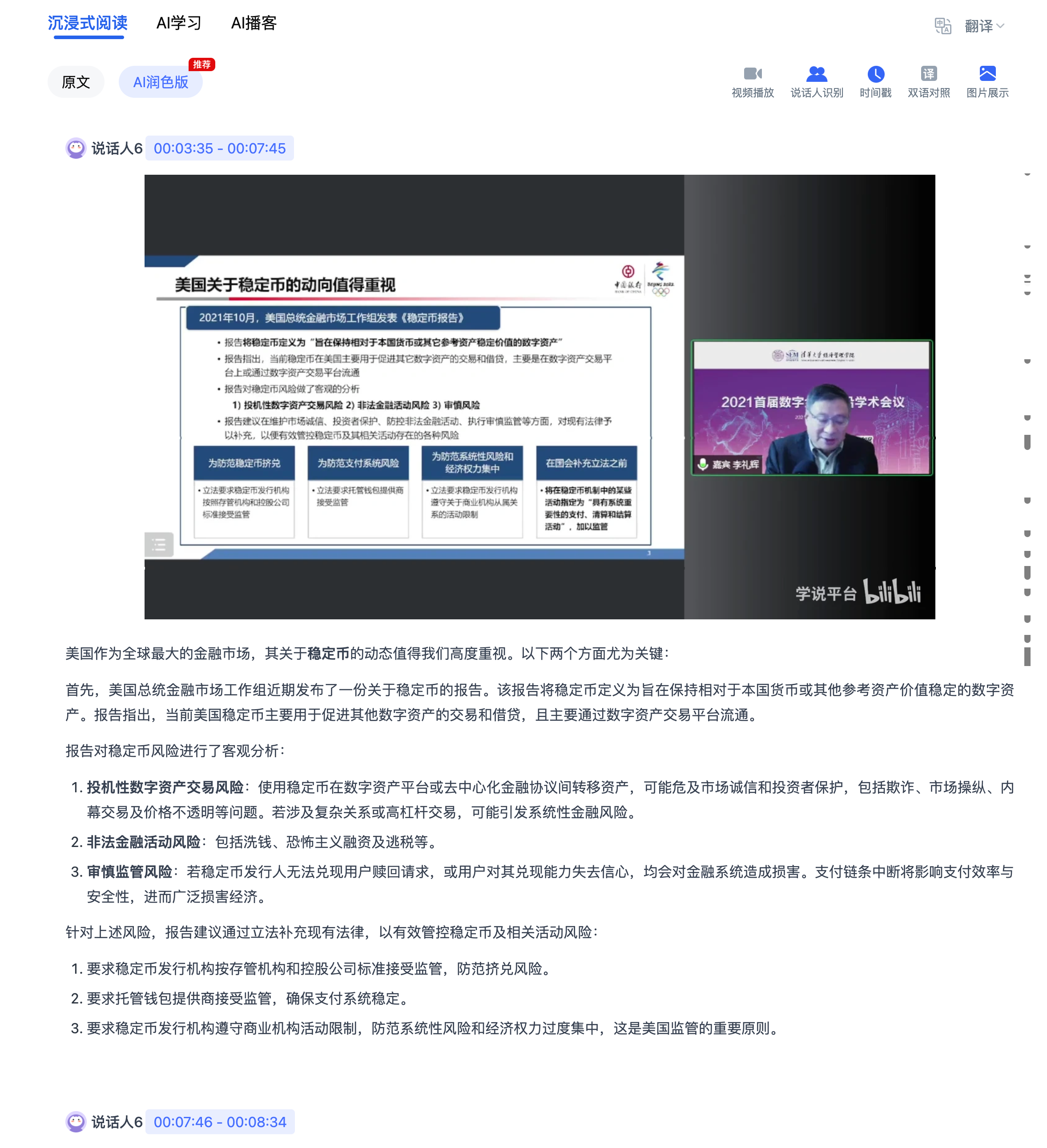
第四环:关键信息提取
有了分段之后,还可以进一步做精华速览和思维导图。
精华速览用的是摘要模型(BART、PEGASUS)或者直接用LLM,从全文中筛选最有价值的几个要点,浓缩成一份速览。

思维导图的实现比较有意思。把文章的层级结构转成树状节点,再渲染成可视化图表。好的实现会让每个节点都能跳转到原文对应的位置------这需要在生成节点的时候保留原文的时间戳或段落索引。
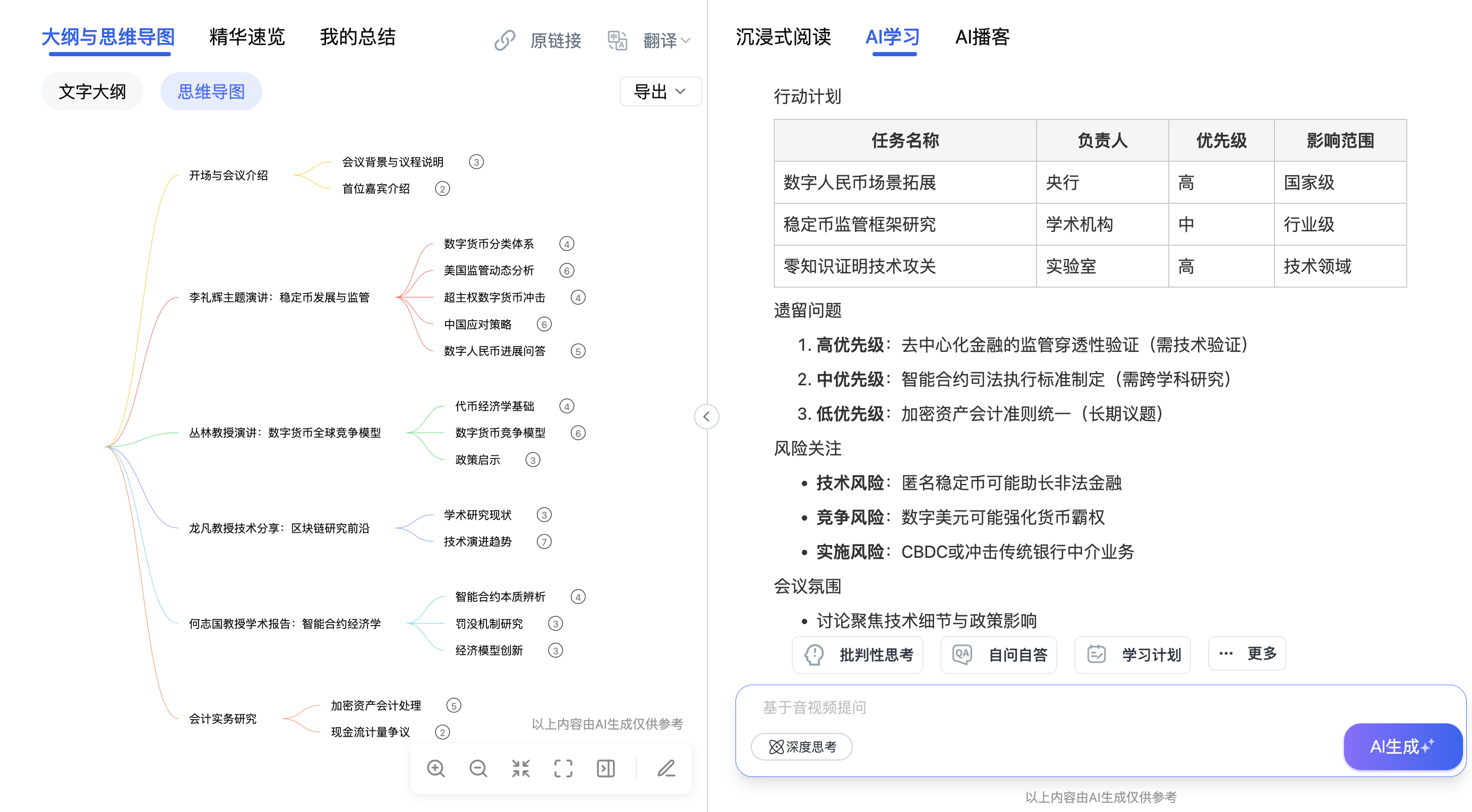
第五环:多模态处理
如果是视频而不只是音频,还有一层,关键帧提取。
先做场景切换检测(Shot Boundary Detection),识别出画面明显变化的时间点,然后在这些位置截取关键帧。更高级的做法是用多模态模型(CLIP)理解画面内容,判断哪些帧包含有价值的视觉信息------比如PPT、数据图表、产品界面------只保留这些。
这步做好了,你看到的笔记里就会自动带PPT截图,不用自己倒回去视频里截图。

小结
整个链路拆下来大概是这样:
Copy
音频信号 → ASR语音识别 → 说话人分离 → 文本分段 → 结构化(标题+层级)→ 信息提取(要点/速览/思维导图)→ 关键帧(如果是视频)每一步背后都是一套独立的技术体系。把它们串起来变成一个流畅的产品体验,工程量其实不小。
像我平时用的Ai好记就是基于这套思路做的。
它把上面这些步骤都整合在了一个流程里,B站、抖音、小宇宙这些平台的链接直接粘进去就处理。支持在线链接直粘、本地上传、阿里云盘百度网盘直连、本地录制四种输入方式,不用自己一个个步骤去拼。
如果你对其中某一步特别感兴趣,后面可以单独展开讲。
FAQ
Q:语音识别准确率受什么影响最大?
A:口音、背景噪音、专业术语密度。安静环境下普通话转写基本没问题,嘈杂环境或者方言场景差距就出来了。
Q:说话人分离能区分多少人?
A:目前主流方案在2-4人的场景下表现比较好,超过6人准确率会明显下降