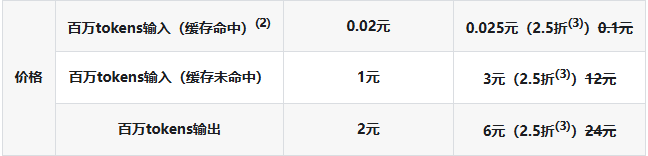
在使用deepseek V4时,我们会发现调用API时的价格描述中分为了缓存命中和未命中两类,那么什么是缓存命中呢?
1. 基本概念
前缀缓存(Prefix Caching / KV Cache Reuse)
大模型推理时,每个token都要计算Key和Value向量,存入KV Cache。当多次请求共享相同的输入前缀(如system prompt、few-shot示例),这些前缀对应的KV Cache可以被复用,不必重复计算。
缓存命中(Cache Hit)
当新请求的前缀与缓存中已有的前缀匹配时,称为"命中",直接加载已有的KV Cache,跳过这部分的计算。未匹配则"未命中"(Cache Miss),需要重新计算。
2. 工作原理
请求A: systemcontext问题A → 计算全部KV Cache
请求B: systemcontext问题B → systemcontext部分命中,只计算问题B
关键细节:
缓存以 1 分钟 TTL 过期,5 分钟内未被访问则失效
前缀必须 从开头完全匹配,中间插入或修改任何 token 都会导致缓存断裂
请求间前缀越长、越稳定,命中率越高
3. 典型应用场景
-
多轮对话:每轮共享之前的对话历史
-
批量推理:相同的system prompt + 不同问题
-
RAG系统:相同检索上下文 + 不同查询
-
Agent循环:同一prompt模板反复调用