1 .insert替换

就是插入相同的东西,你就想插入,你就可以使用后面的语句把前面的替换了。

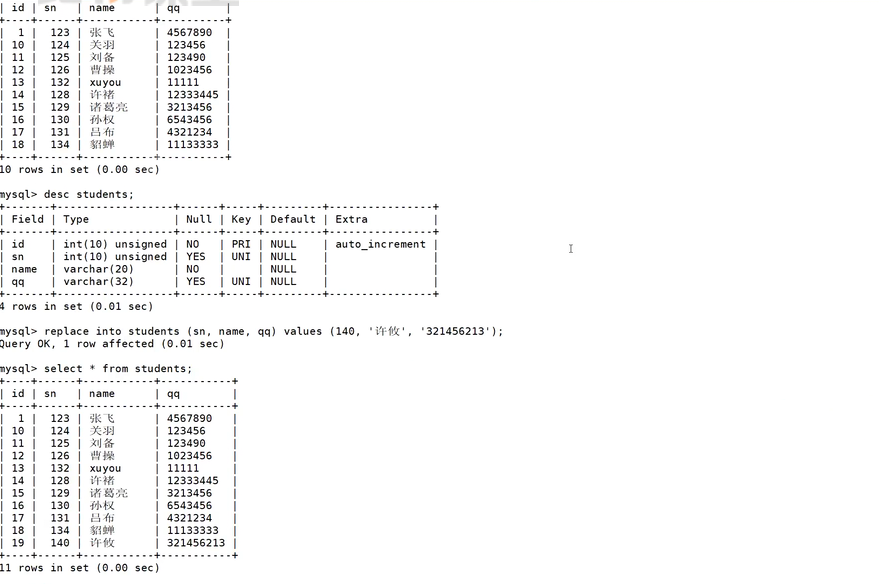
这时候是没有发生冲突,跟插入语句差不多。
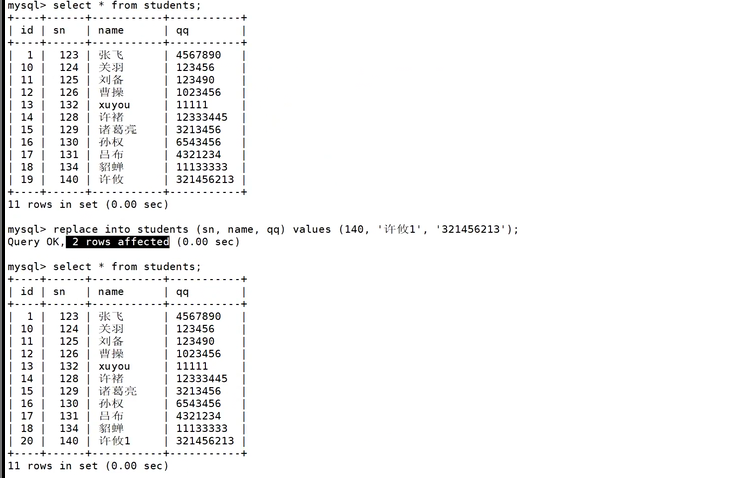
此时出现了2行受到影响,此时说明冲突了。
是先删除原来的,然后再删除。
SELECT
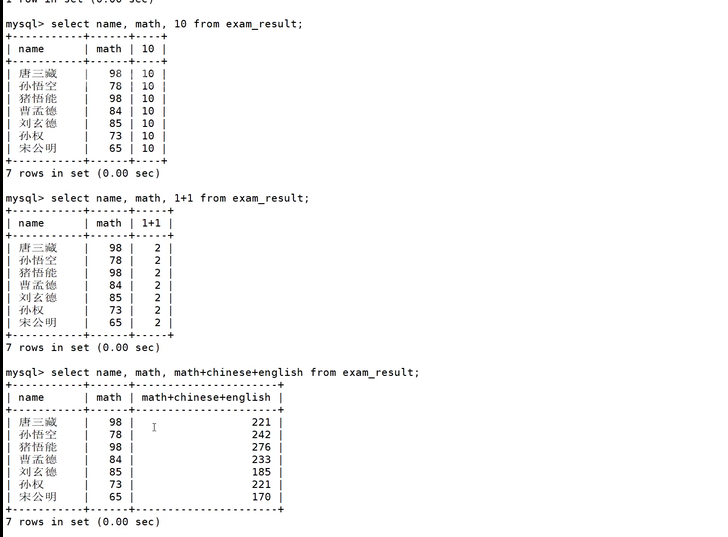
这个就是可以自己加一行,筛选出来。

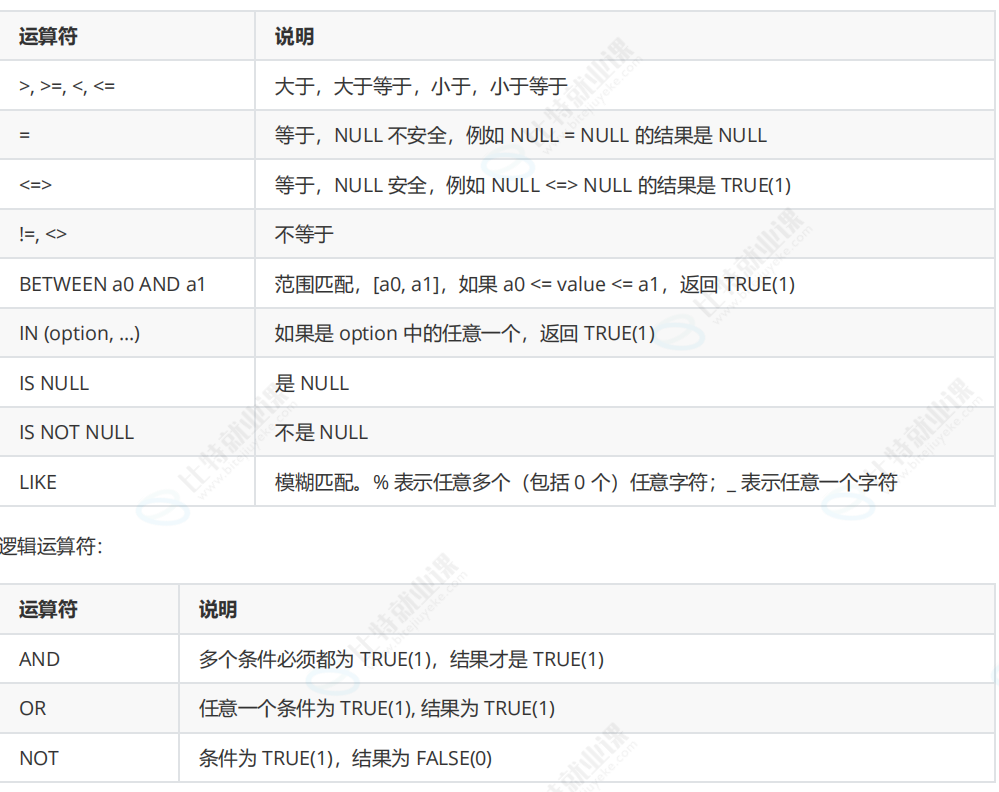

模糊查询,%表示后面是多个字符,_代表的是就是一个字符。

为什么报错??
首先需要知道sql的执行顺序,先执行from,然后where,最后才是select,所以先执行where,此时where不知道你把这个列重命名了,因为并没有执行你,所以只能是下面这样子写。


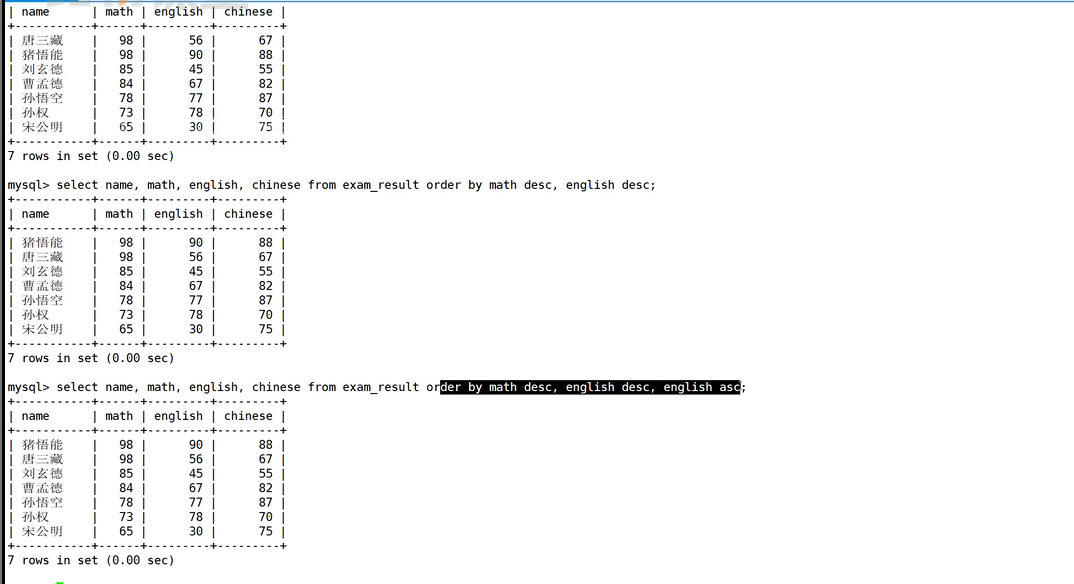
这三个成绩升序降序的前提是前面的成绩需要相等才会排后面的,如果前面的直接大于或者小于了,此时不管后面了。


因为是先把数据通过where筛选出来,然后再进行排序的,这里没有这个where,所以就是全部数据,此时select拿到全部数据,然后再排序显示出来。所以这里是可以使用别名的。
limit

主要三种用法,第三种和第二种差不多一样,off'set后面表示从哪个位置开始筛选,这个limit后面表示筛选几个。
第一个就是回显前三条数据的意思,第二个是从第三个数据开始下标为2,到第六个数据,下标是5,最后一个是从第一个数据开始,就是前五个数据。
这个limit执行是在这个order by之后。
update

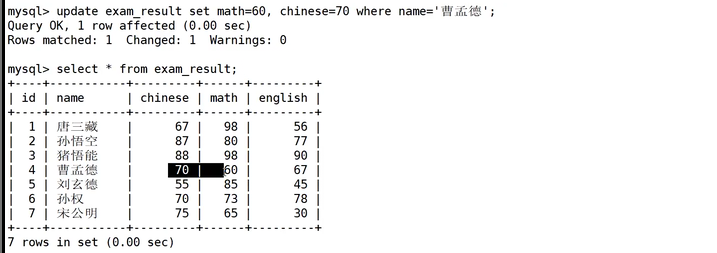

我们的这个操作是把后三名的数学成绩加30分。
我们上面如果不加where条件的话,此时就直接把这一列全部改变了。
Delete

这里也是如果不加where的话,此时就直接把全部删除了。
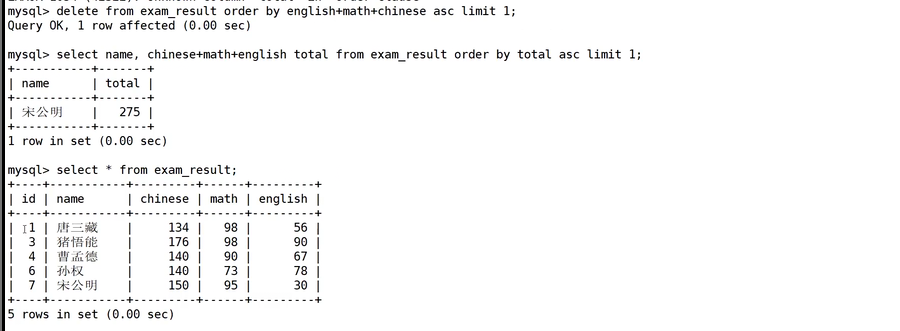
配合order by使用,这个个语句的作用就是删除最后一名的成绩。
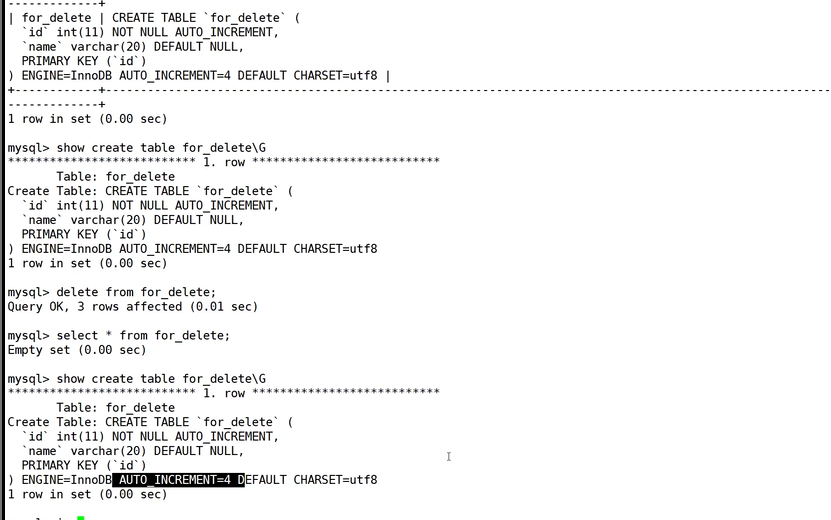
再看一个需要注意的点,我们此时创建一个表,表中存在自增字段,我们也插入了内容,此时你的自增计数器的结果是4,表示我们下次插入就是4,但是此时你把表中的内容全部删除,此时这个计数器的结果还是不变的。下次插入自增字段的结果是4.
截断表
注意:这个操作慎用
-
只能对整表操作,不能像 DELETE 一样针对部分数据操作;
-
实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
-
会重置 AUTO_INCREMENT 选项
看一下下面的例子。

此时你截断这个表,这个表中将无数据,此时你再次插入的话,这个自增计数还是从1开始的。
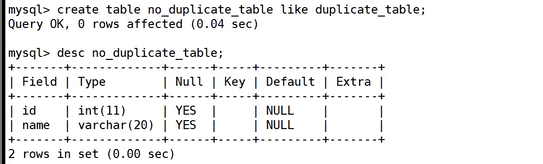
这个语句就能创建相同的表结构。
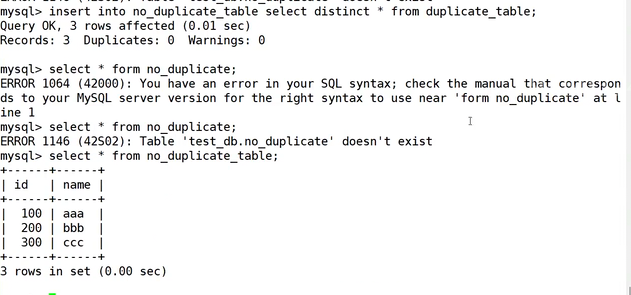
通过这两个语句的结合,我们此时就把这个进行了去重的操作,此时我们只需要通过语句修改表明即可。

再通过这个操作,我们就把表明修改了,把原来的数据保存了起来。
为什么要使用rename呢??不适用mv呢??
因为rename一次可以修改多个文件名,这个mv一次只能改一个文件名。
还有就是从原子性角度来看原子性:整个改名操作要么一次性全部成功,要么完全失败,不会出现中间脏状态。
Linux 内核 rename(oldpath, newpath) 系统调用特性:
- 全程加文件系统锁
- 不拆分 "删旧名、建新名" 两步
- 中间不会被进程调度打断
- 断电、崩溃只会两种结果:
- 改名完全成功
- 改名完全没发生 绝对不会出现:旧文件没删、新文件已存在 的错乱中间态。
你如果使用循环mv修改,此时不是原子性的,有的可能修改正确,有的可能会由于某种原因出现错误,可能有正确的有错误的,你也不知道,或者使用cp+rm的方式,这个也不是原子的,也会出现有的正确有的错误的现象,但是使用rename不会出现这个问题,要么全对,要么全错。
聚合函数
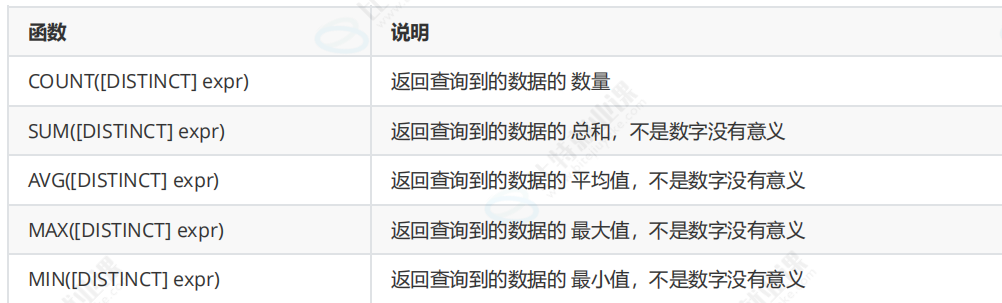

这个就是统计我们数学成绩存在多少行,如果是count(*)表示总共多少行。

不同的数学成绩有多少个。
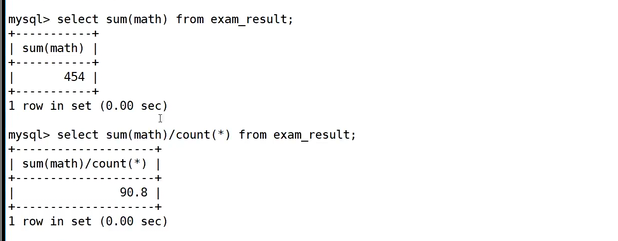
一个是数学总分,一个是平均分。
- COUNT(*)
统计:表中所有总行数,不管空值 NULL
-
忽略行是否为空
-
只要这一行存在,就算 1 行
-
最快、最常用
-
不会过滤 NULL
- COUNT (列名)
统计:该字段不为 NULL 的数据行数
-
自动过滤掉字段值是 NULL 的行
-
空字符串
''不算 NULL,会被统计 -
只数有值的
例子:count(name)只要 name 是 null,这一行直接不计入总数
- COUNT(1)
效果 = COUNT (*)
-
1 就是常量占位符
-
不读取字段,直接数行数
-
不计 NULL 行
-
性能和
count(*)几乎一致


group by

我们这个语句的作用就是查询每个部门的最高工资和平均工资的。

也可以把部门加上,此时就更加清晰。


这里我们是按照不同部门的不同岗位分的组,此时也能看到,我们此时需要关注的就是这个job的,虽然你的部门信息是一样的但也是不影响的,因为这个工作是不一样的,要把它们看成一个整体。
先记得就是这个聚合函数和你分组使用的字段才能在select出现。

这个只需要知道这个having就行就是给分组后的数据进行添加筛选条件的。
怎么理解这个having和where呢??
简单来说就是一个是先对表进行筛选然后再分组,having是对分组后的数据进行筛选的。
select * from 表明 where sal > 3000;此时你查询工资大于3000的,它能得到一个表信息,此时你查询出来的结果你可以看成一张新表,这是没问题的,然后select deptno ,job , max(sal) from 表明 where sal > 3000 group by deptno , job having sal < 4000;就拿这个例子理解,首先你先执行的是先看到这个表,然后where筛选出来的结果,此时你就拿到了这个工资大于3000的部门中的信息,此时这个是个新表就是工资全是大于3000的,此时你是对这个表分组,分完组之后你还是会获得一个分组之后的新表如下图所示的:
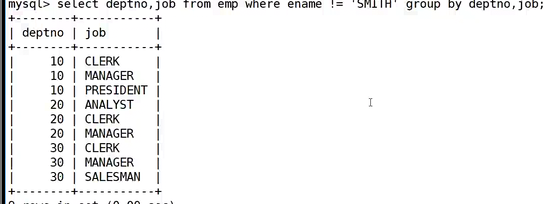
此时这个还是个新表,你的having是对这个表进行条件筛选的,作用的点不一样。

就是这个顺序。