文章说明:
- 文章有出现小红薯的地方,本来是为了写小红薯
- 但是风控太严了,用 cookie 登录,直接把我的电脑端、手机端全部下线了,然后之前的设置就保留了,换成今日头条了
- 文章全流程都是自己摸索打通的,包括(飞书、代码快、参数)等
- 文章历史两天完成,主要在调试(坑太多)
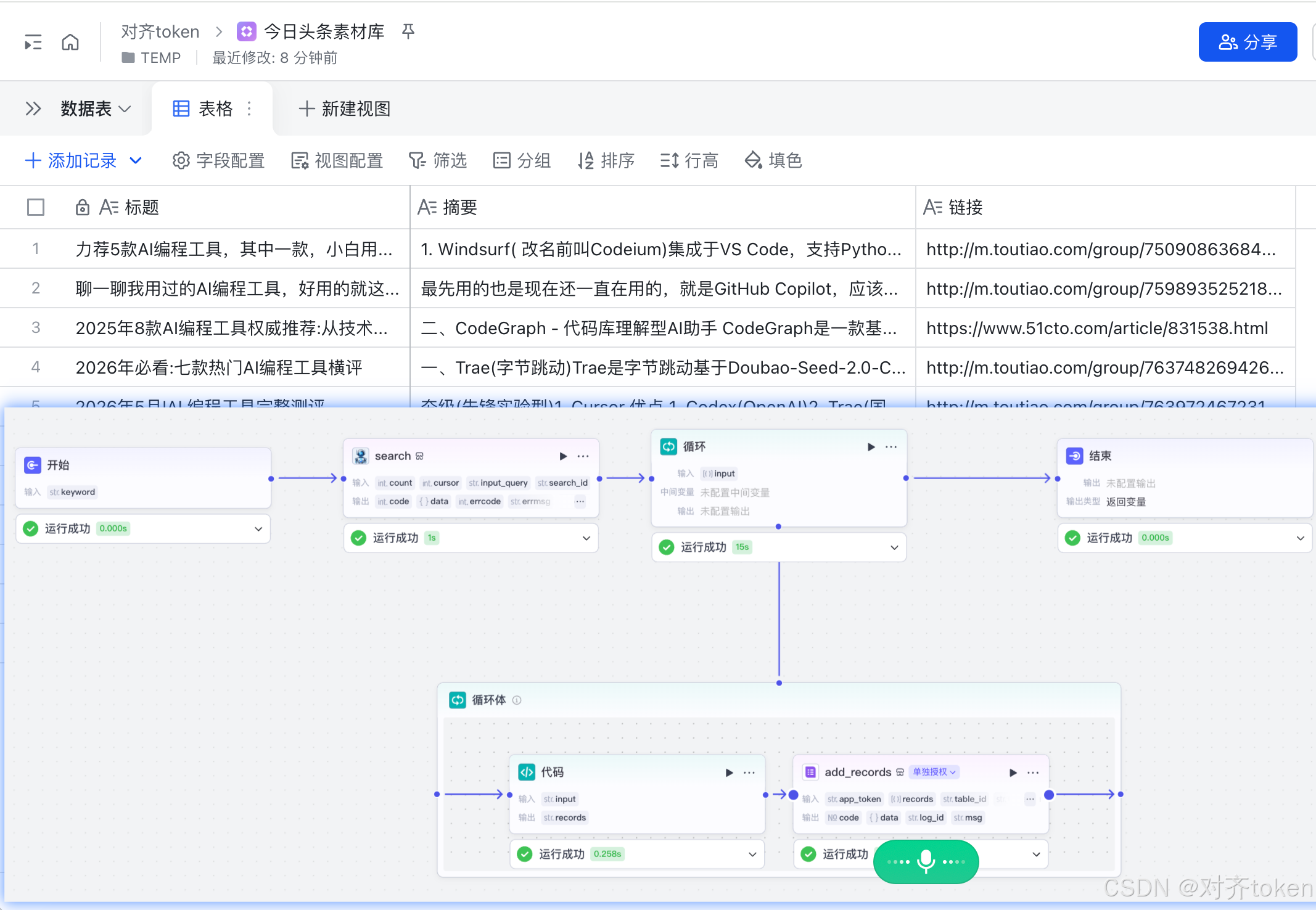
这个工作流的思路是:
- 你输入一个关键词(比如"早八通勤妆"),它能自动在头条帮你搜出N条热门笔记,然后一条条地自动填入你建好的飞书多维表格里。
- 这就好比雇了个24小时不休息的实习助理,专门帮你做素材搜集和整理
整个流程的骨架是这样的:
- 开始(输入关键词)
- 搜索插件(搜笔记列表)
- 循环节点(处理每条笔记) ->(循环体内:获取详情 → 代码拼装格式)
- 飞书写入
- 结束
别被这个骨架吓到,我会把它拆成你能一步步跟着点的小操作。
📌 准备工作:拿到飞书的"钥匙"
1. 创建飞书多维表格,复制链接
这是最终数据的落脚点。表格链接就相当于你家的地址,扣子得靠它才能把数据送到家。
- 🔍 操作解读 :
- 打开飞书,新建一个多维表格,名字就叫"今日头条素材库"。
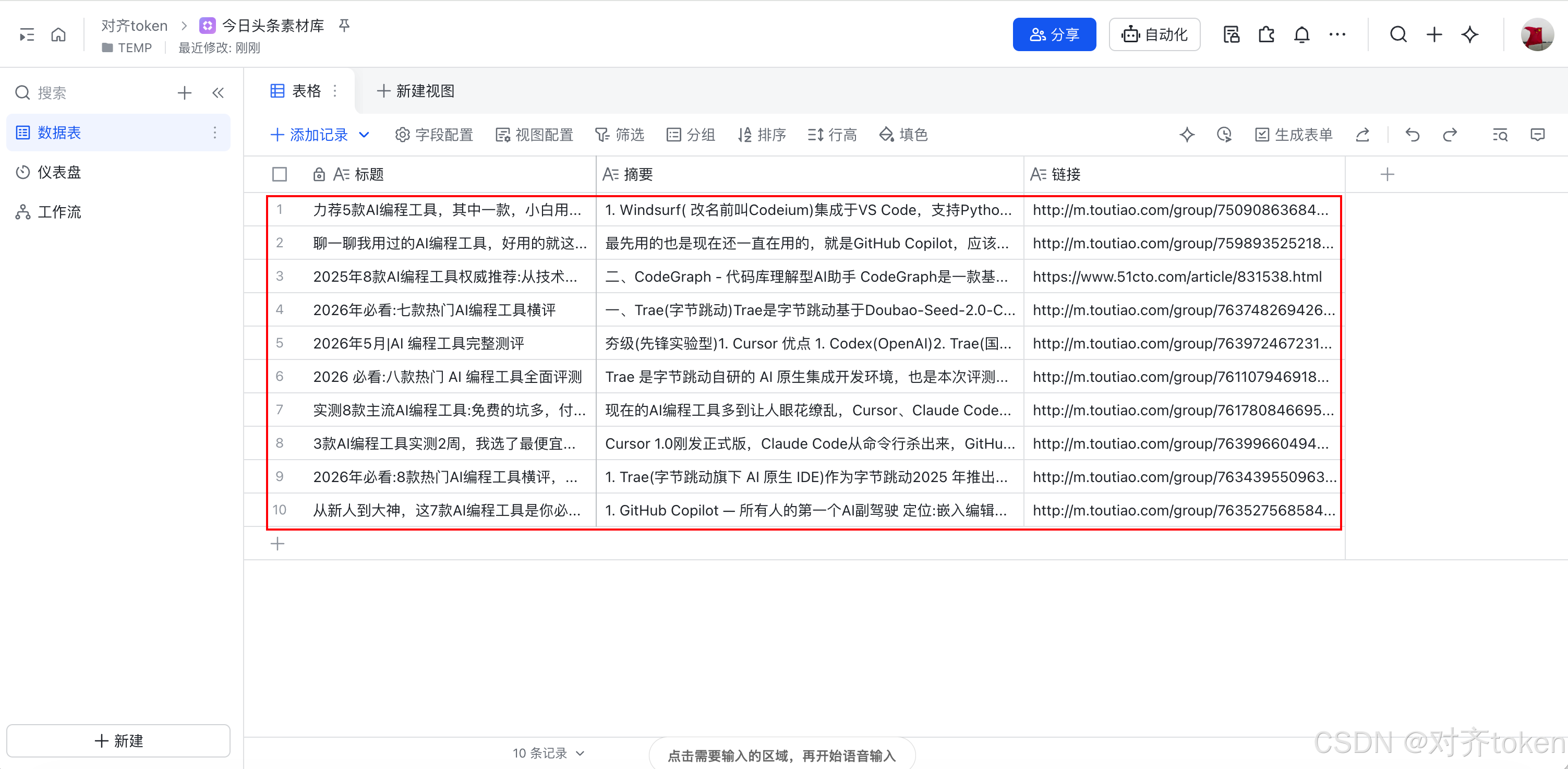
- 设计好字段(也就是表头),可以参考这套配置,按需增减:
- 标题 (文本)
- 链接 (文本
- 摘要 (文本)
- 复制浏览器顶部的表格链接,保存备用,这就是传说中的
app_token。
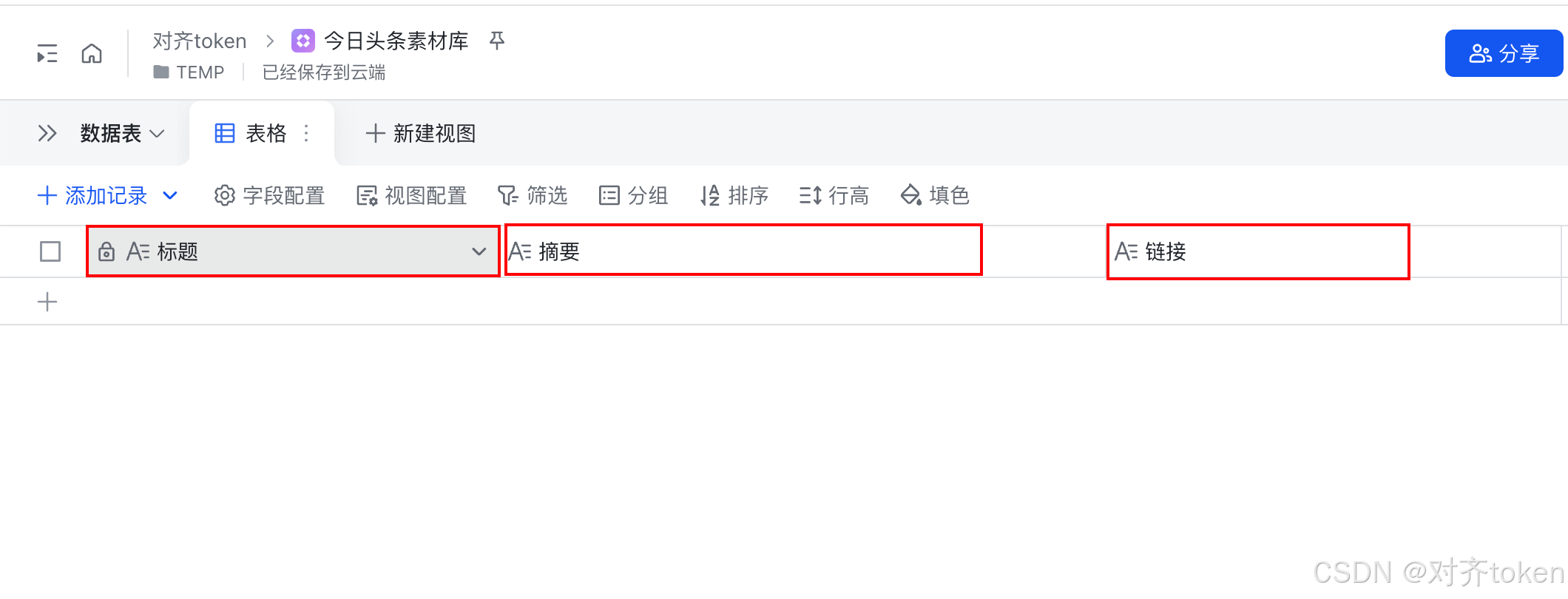
2.⭐获取多维表格的 app_token 和 table_id
刚刚复制的表格链接里,其实包含了两个关键信息:app_token 和 table_id。
app_token 相当于整个多维表格文件的身份证,而 table_id 则是文件里某一张具体子表的身份证。
一个多维表格可以有多个子表,所以两者缺一不可。
-
🔍 操作解读:
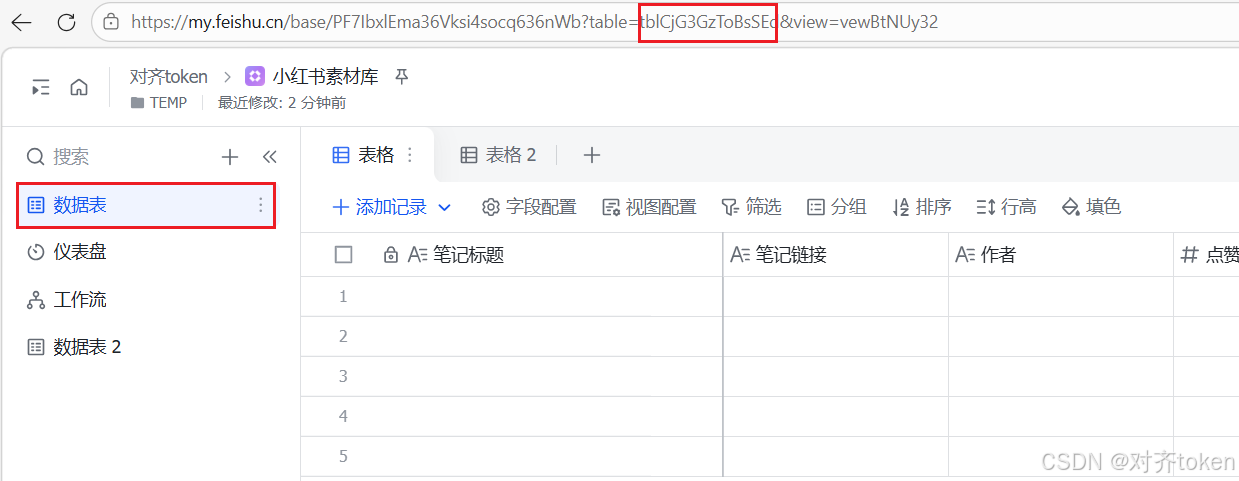
- 在浏览器打开你的多维表格,查看地址栏的 URL。
- URL 的结构大致是:
https://xxx.feishu.cn/base/XXXXX?table=YYYYY。
Plainhttps://my.feishu.cn/wiki/LR79wrhXhinpLekY4aEcWepdnRw?table=tblCjG3GzToBsSEd&view=vewBtNUy32- 获取
app_token****(Base ID) :base/后面到?之前的那串字符(示例中的XXXXX),就是app_token。把它复制并单独记下来。
PlainLR79wrhXhinpLekY4aEcWepdnRw获取
table_id****(Table ID) :?table=后面的那串字符(示例中的YYYYY),就是table_id。同样复制并单独记下来。PlaintblCjG3GzToBsSEd- 检查 :如果你的表格有多个子表,切换到不同子表时,URL 中
table=后面的这串 ID 会变化 。请务必确保当前打开的是你想写入数据的那张子表,再复制table_id。
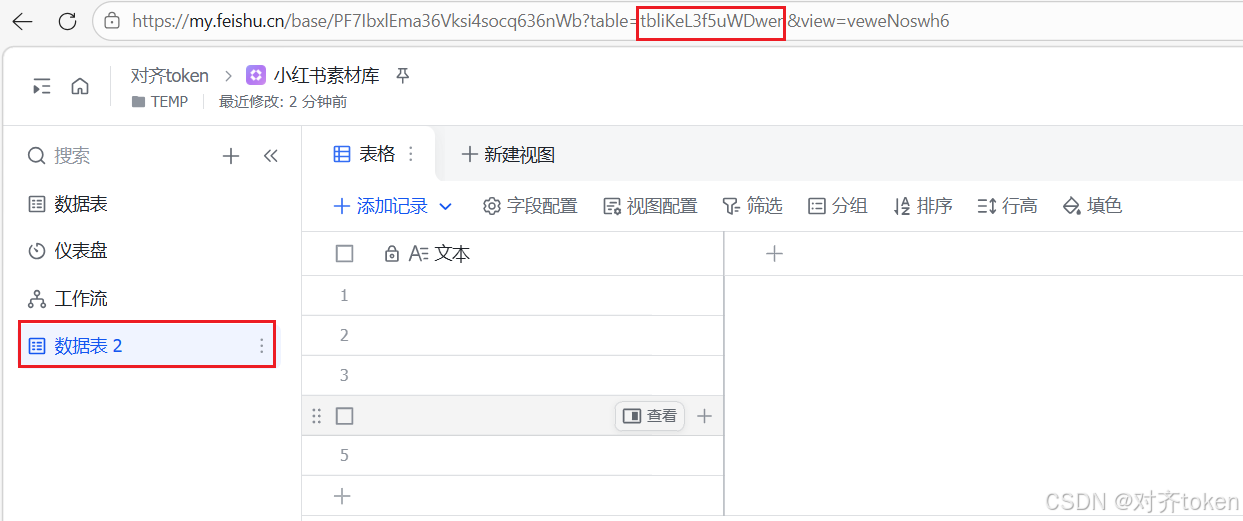
📦 记忆技巧:
app_token帮你找到"文件"table_id帮你找到"文件里的那张表"。
3. ⭐ 创建并授权飞书应用(个人版关键步骤)
之前只讲了要飞书多维表格的链接,但这还不够。
要让扣子有权限往你的多维表格里写数据,需要去 飞书开放平台 创建一个应用来授权。
这是整个流程的关键,一步都不能省。
🔍 操作解读:
- 进入飞书开放平台 :在浏览器中打开
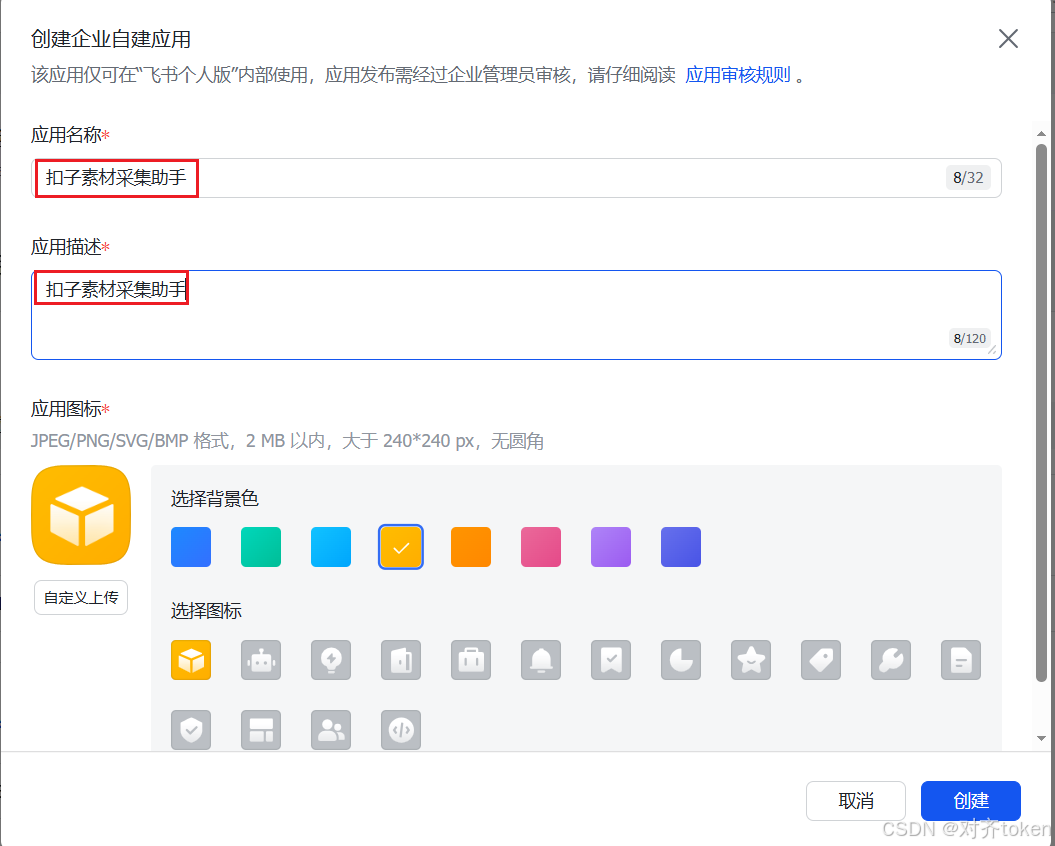
https://open.feishu.cn/,使用你的个人飞书账号登录。 - 创建企业自建应用 :进入"开发者后台 ",点击"创建企业自建应用"。填写应用名称(如"扣子素材采集助手")、描述和图标,然后点击"创建"。
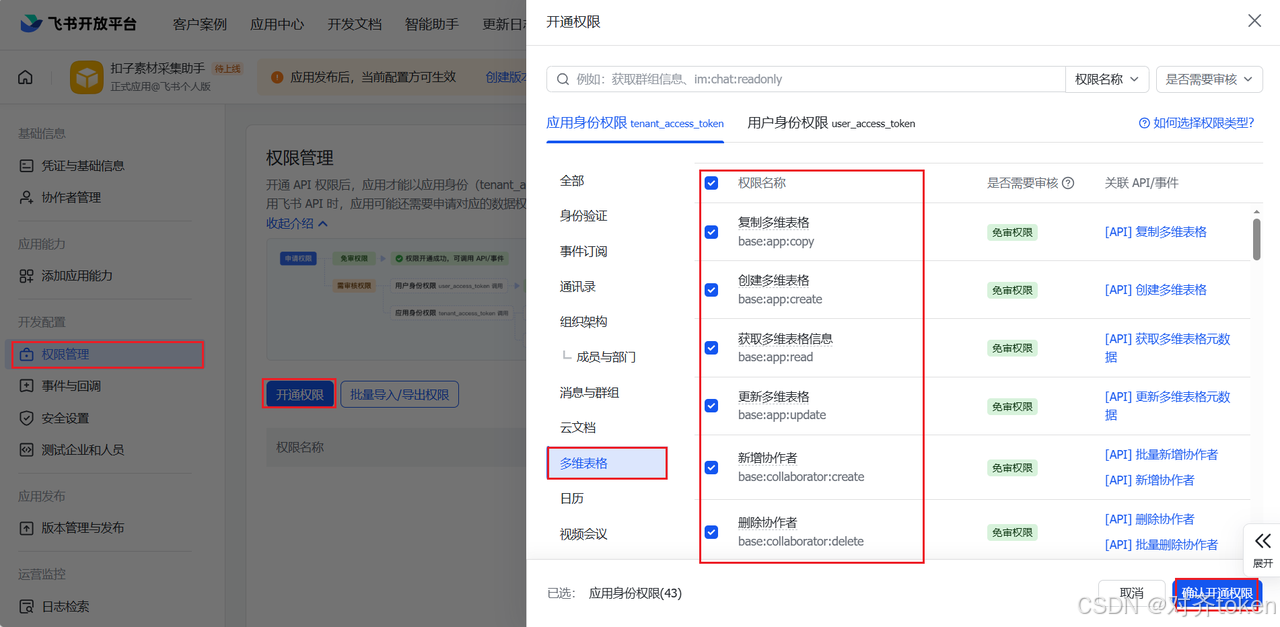
- ⭐ 开通多维表格权限 :
- 在应用详情页的左侧导航栏,点击"权限管理"。
- 在"权限管 理"页面,点击"开通权限"。
- 在搜索框输入"多维表格"
- 勾选"查看、评论、编辑和管理多维表格"及其所有子权限
- 确保"应用身份权限 "和"用户身份权限"下的选项都勾选上
- 然后点击"确认开通权限"。
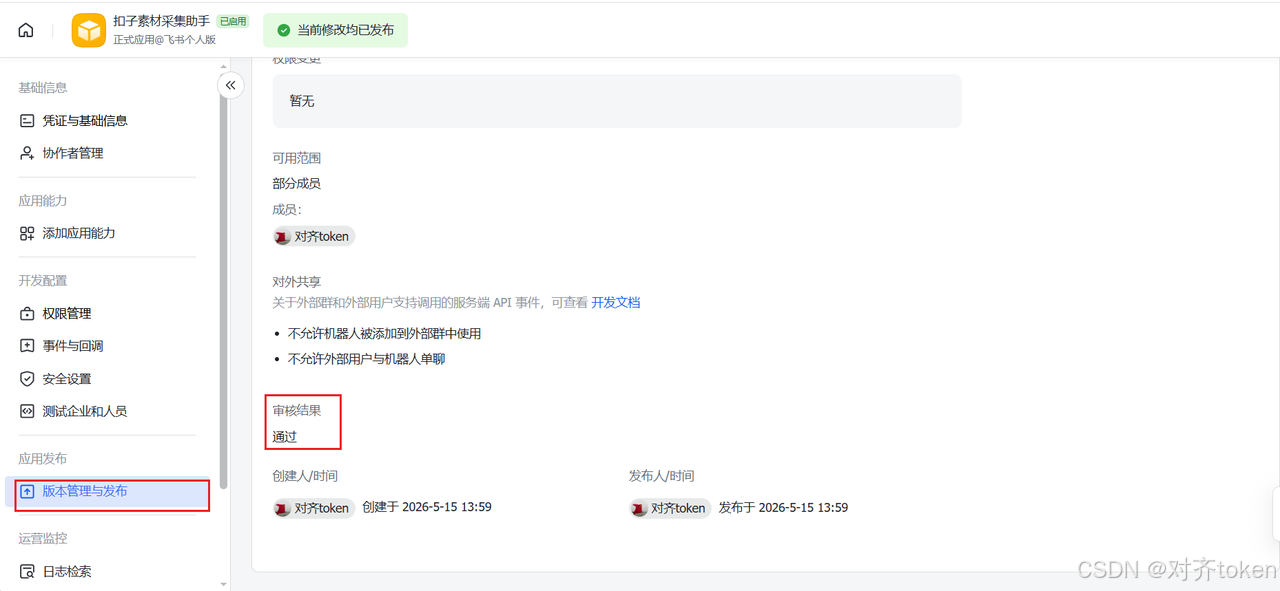
- ⭐ 发布应用并关联多维表格:
- 发布应用 :在应用详情页顶部,点击"创建版本 ",输入版本号(如
v1.0)和更新说明,点击"保存"。接着,在右上角点击"申请线上发布 "。首次发布通常会自动通过审核,无需人工审批。
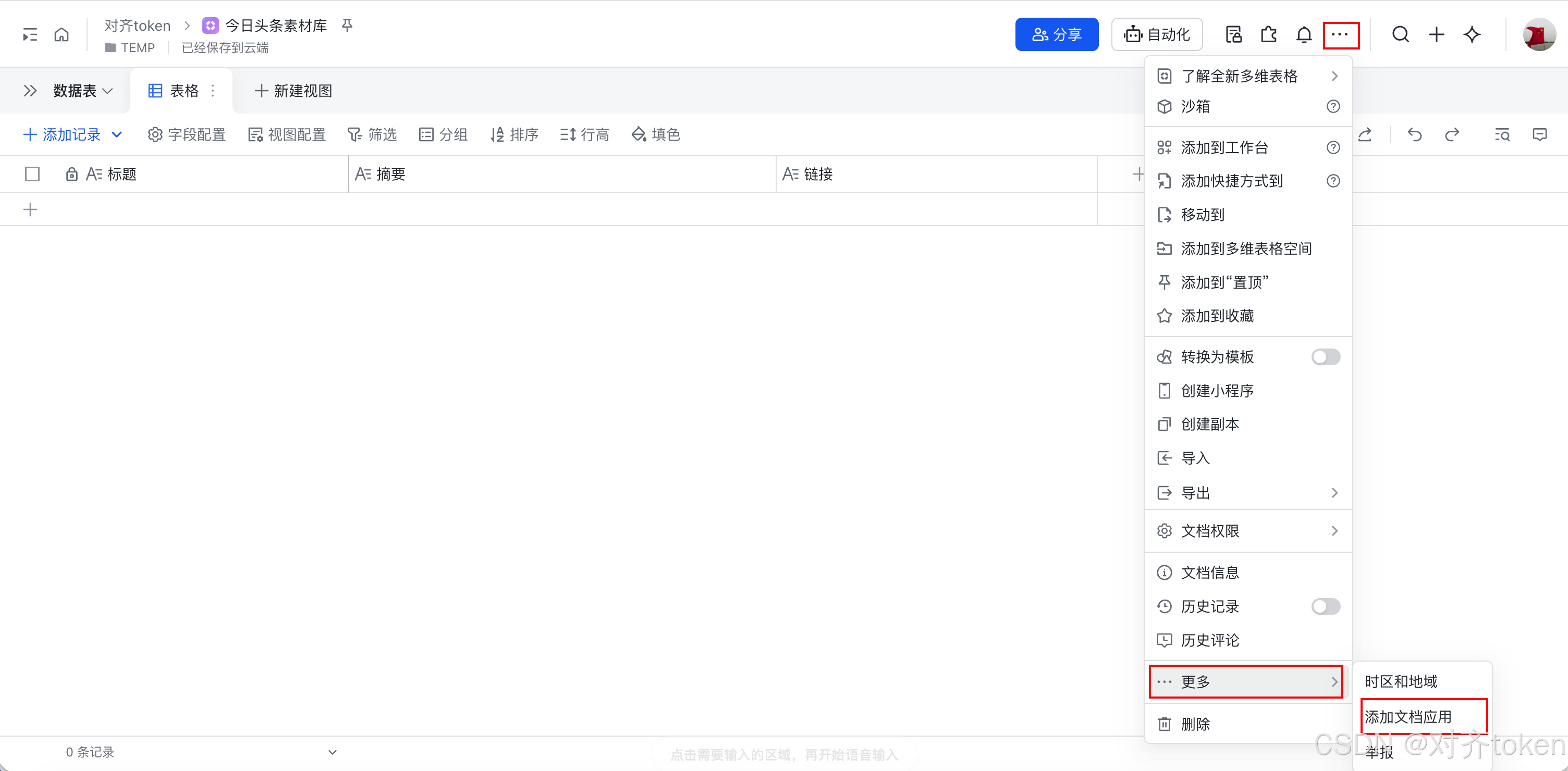
- 关联多维表格 :回到你的飞书多维表格页面,点击右上角的"... "菜单,选择"更多 " -> "添加文档应用 "。在弹出的窗口中,搜索你刚刚创建的应用名称("扣子素材采集助手 "),点击"添加"。这一步是告诉飞书,这个应用可以操作这个表格。
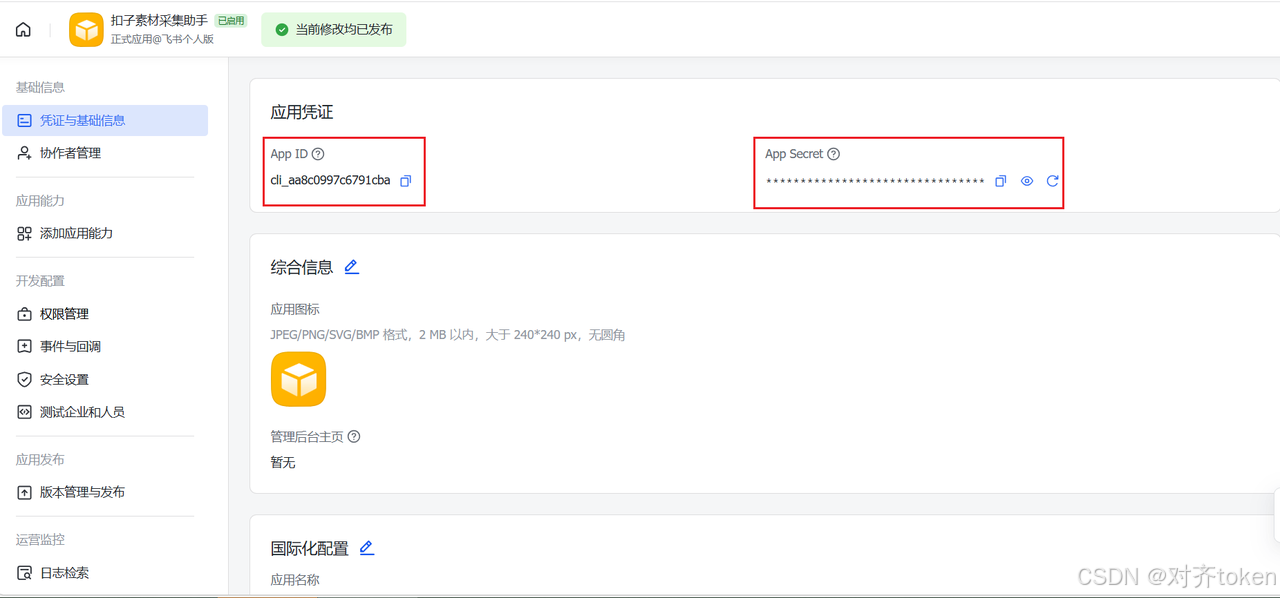
- 获取并保存 App ID 和 App Secret :在应用详情页的"凭证与基础信息 "页面,复制
App ID和App Secret并妥善保存。这两个是应用的"账号 "和"密码",后续配置会用到。
⚠️ 避坑提醒:应用发布后,最好等待几分钟再操作,权限同步需要一点时间。
1️⃣ 第一步:创建工作流并设置"开始"节点
- 🖱️ 操作解读 :
- 登录扣子平台(coze.cn ),左侧菜单点 "资源库" → "工作流" → "创建工作流",名字就叫"今日头条批量采集"。
- 在画布上找到"开始"节点,点击它,在右侧面板设置输入变量。
- 🧩 参数配置 :我们需要定义以下变量,方便后续调用:
keyword:String,输入搜索关键词。count:Number ,搜索数量,建议先填5测试(我就用默认的了)。
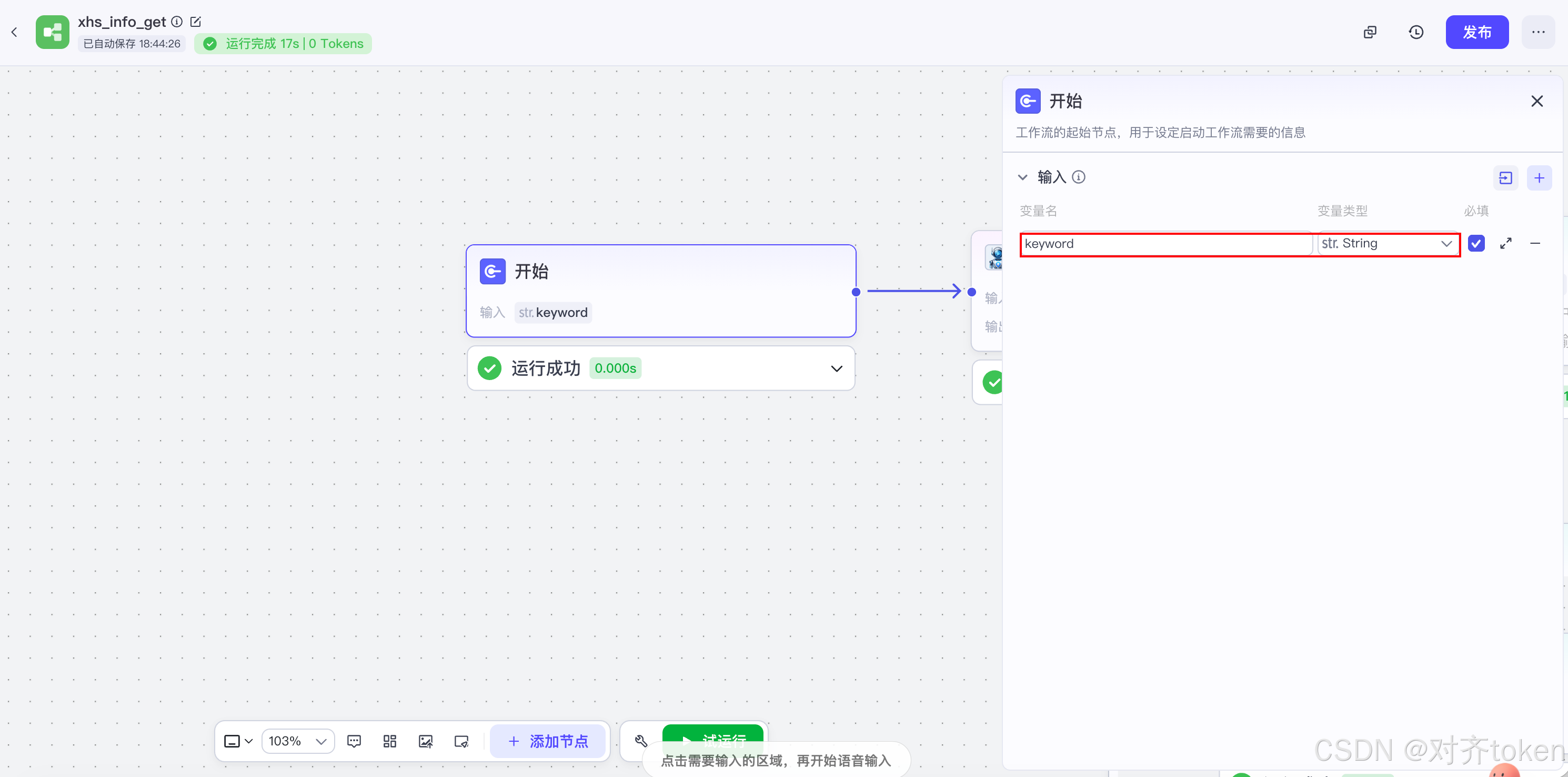
🧠 设计意图 :开始节点决定了工作流接收什么"原料"。这里定义
keyword和count两个参数,供后续搜索插件使用。
2️⃣ 第二步:添加"头条搜索"插件
- 🔍 操作解读 :
- 在左侧节点列表找到 "插件" ,点开,搜索 "头条搜索"。
- 找到官方出品的"头条搜索"插件,选择
search工具,点击添加。 - 将"开始"节点底部的连线点,拖到"搜索"插件节点顶部的连接点上,让数据能流过去。
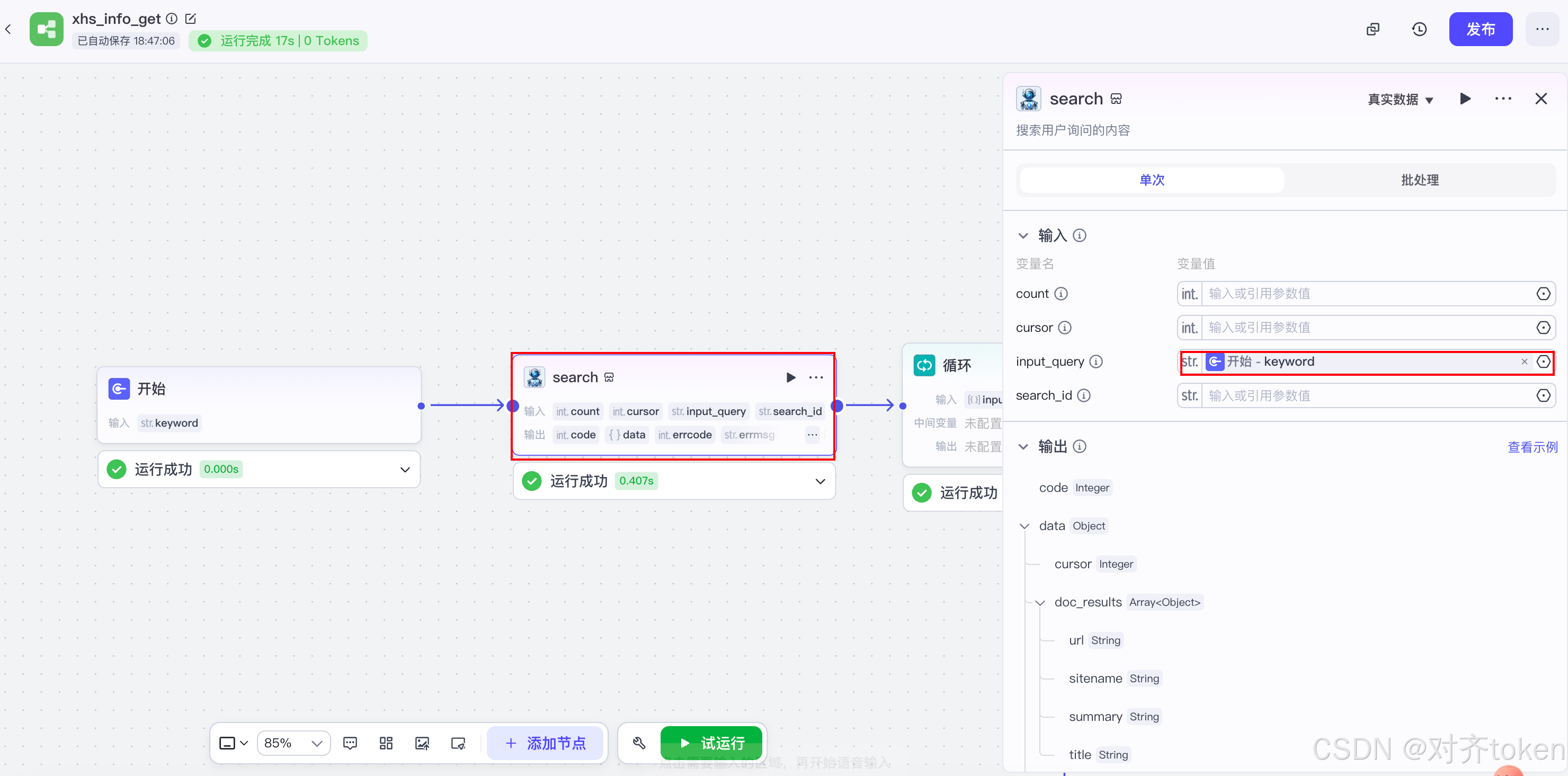
- 点开搜索插件配置面板,找到
input_query字段,点击输入框,通过"添加变量 "→"节点引用 "→选择开始节点 的keyword。
- ⚠️ 踩坑预警 :
- 官方搜索插件相对稳定,但若返回数据为空,先检查
input_query是否引用正确。 - 输入参数除了
input_query之外,其他可以留空。
- 官方搜索插件相对稳定,但若返回数据为空,先检查
3️⃣ 第三步:添加"循环"节点,逐个处理每条新闻
这是批量操作的灵魂,能让机器自动完成重复的提取工作。
- 🔍 操作解读 :
- 添加节点,搜索 "循环" ,将它连接在"头条搜索"插件的后面。
- 点击"循环 "节点,在右侧配置:
- 循环数据 :点击输入框,通过"添加变量"→"节点引用"→选择
头条搜索/search节点的输出字段。在引用时逐层展开,选择data下的doc_results列表(格式为Array<Object>)。 - 循环次数:可以留空,系统会自动根据列表长度来循环。
- 循环数据 :点击输入框,通过"添加变量"→"节点引用"→选择
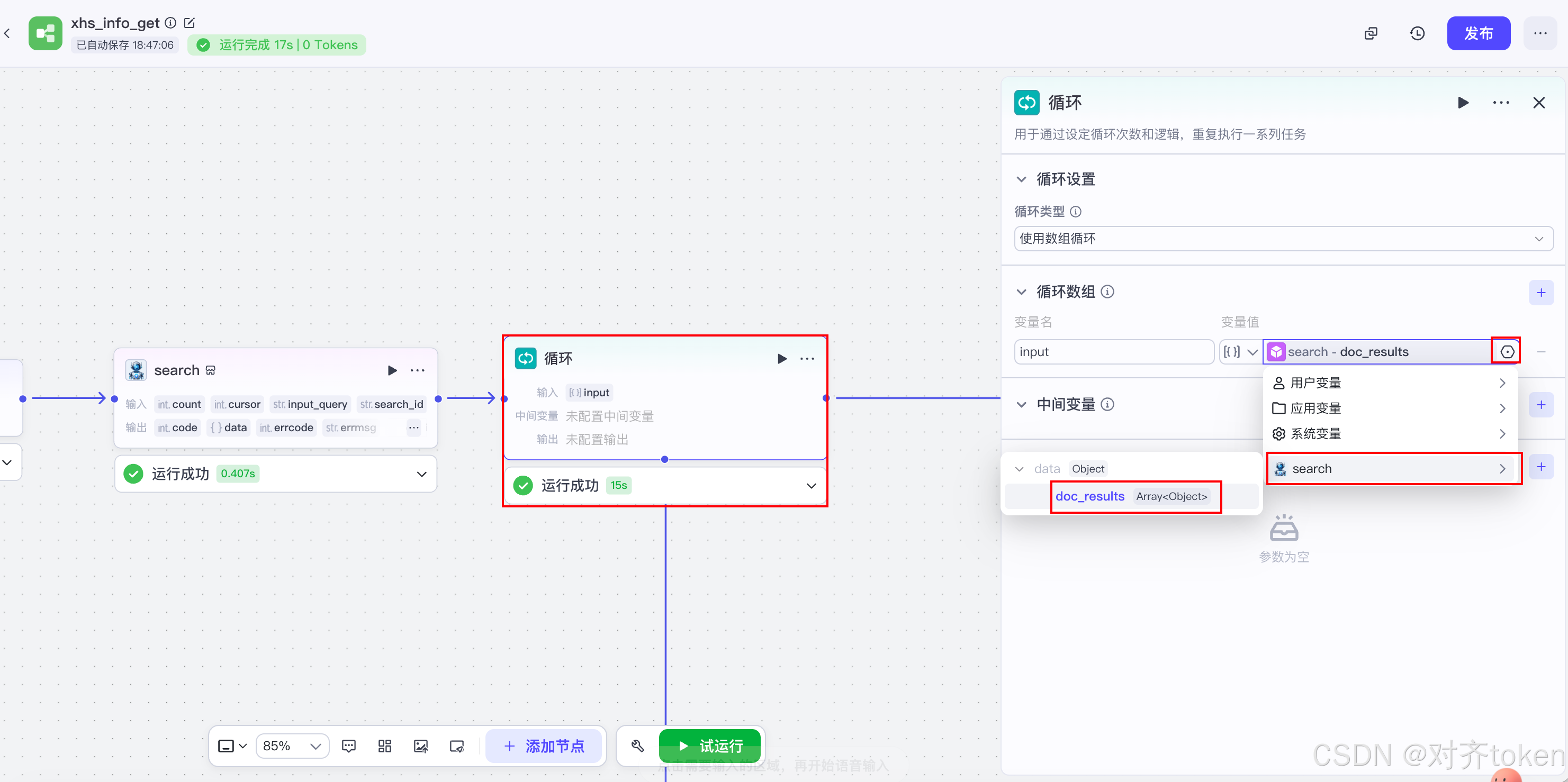
- 💡 核心思路 :插件返回的是一个新闻列表,循环节点能让下面的步骤(大模型提炼、代码拼装等)对列表里的每一条新闻都执行一次,这样就实现了批量处理。
4️⃣ 第四步:添加"代码"节点,拼装飞书格式
这是解决"飞书不收"问题的关键,必须把数据格式做得分毫不差。
-
🔍 操作解读 :
-
在大模型节点后,添加一个 "代码" 节点。
-
语言选 Python 。点击代码节点,先别急着写代码,先点开 "输入"参数 :
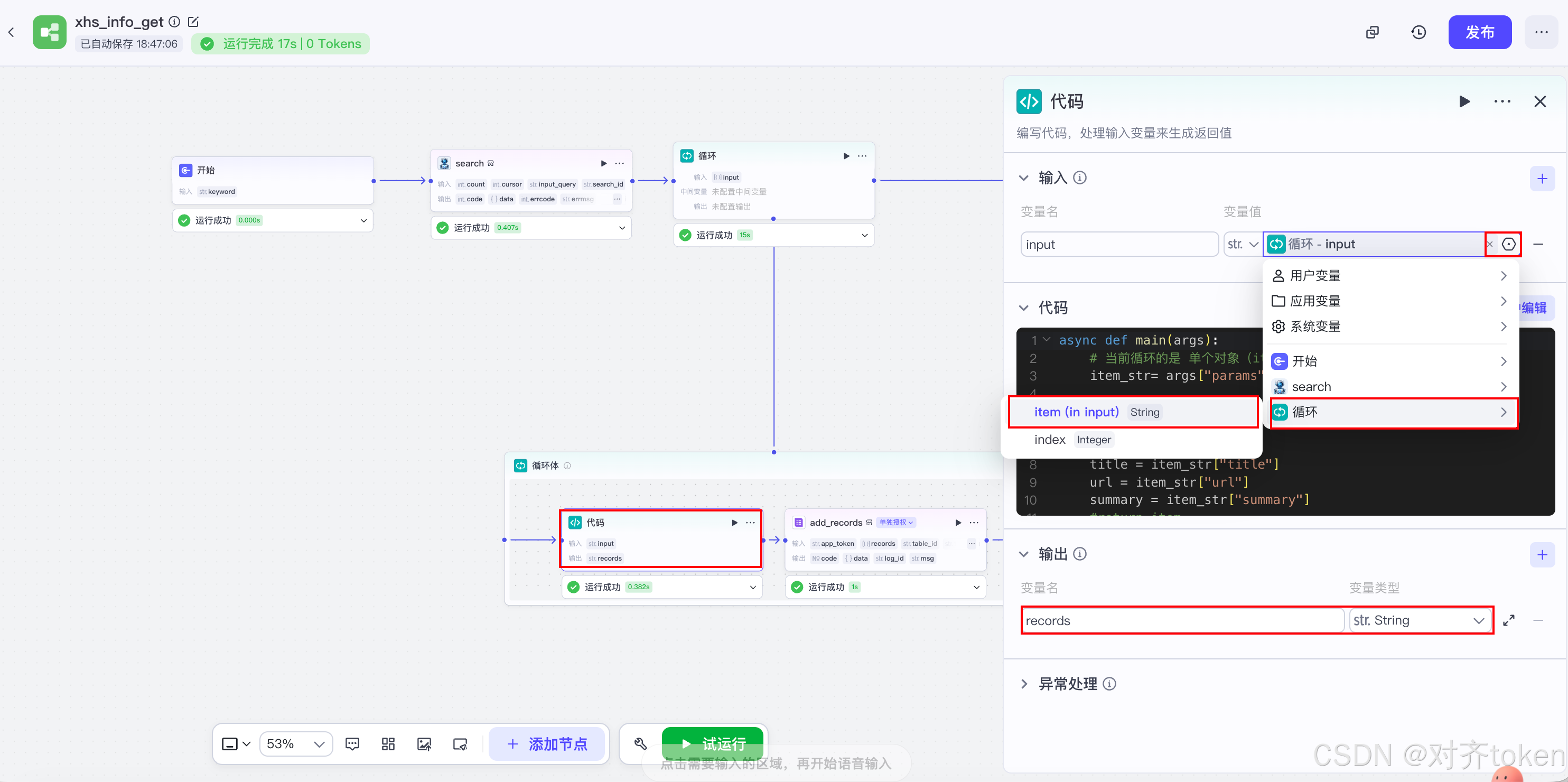
-
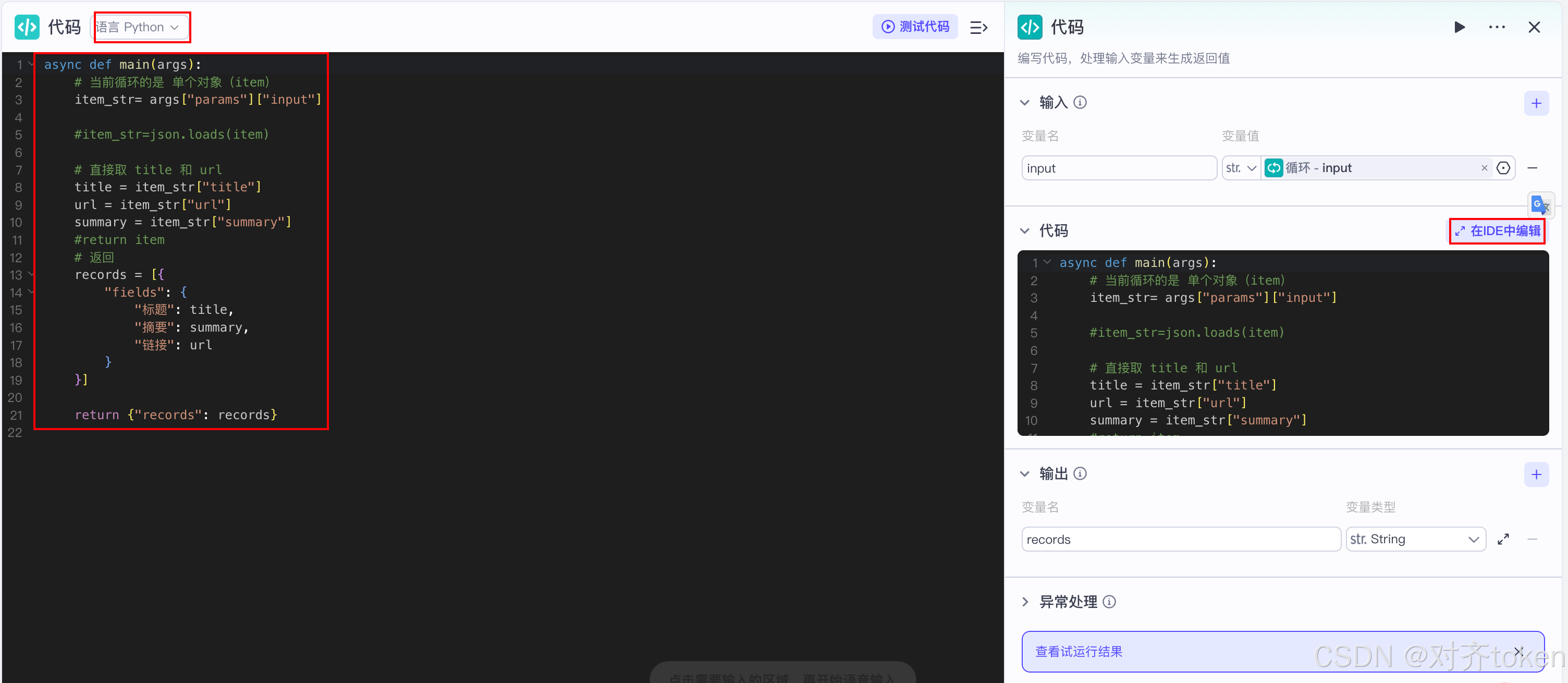
代码编辑区,粘贴以下代码(注意把字段名改成和你的飞书表格列名一模一样):
Pythonasync def main(args): # 当前循环的是 单个对象(item) item_str= args["params"]["input"] # 直接取 title 和 url title = item_str["title"] url = item_str["url"] summary = item_str["summary"] #return item # 返回 records = [{ "fields": { "标题": title, "摘要": summary, "链接": url } }] return {"records": records} -
-
📦 代码解读 :
- 飞书的
add_records插件只认Array<Object>格式,也就是[{ "fields": {"列名": "值"} }]这样的结构。 - 代码节点的作用,就是把上游散乱的字段,严格按照这个格式封装好。
- fields里的key必须和你的飞书表格列名一模一样,一个字都不能差,包括空格、大小写,否则飞书那边会报错。
- 飞书的
5️⃣ 第六步:添加"飞书多维表格写入"插件
这是最后一步,把处理好的数据送入飞书表格。
- 🔍 操作解读 :
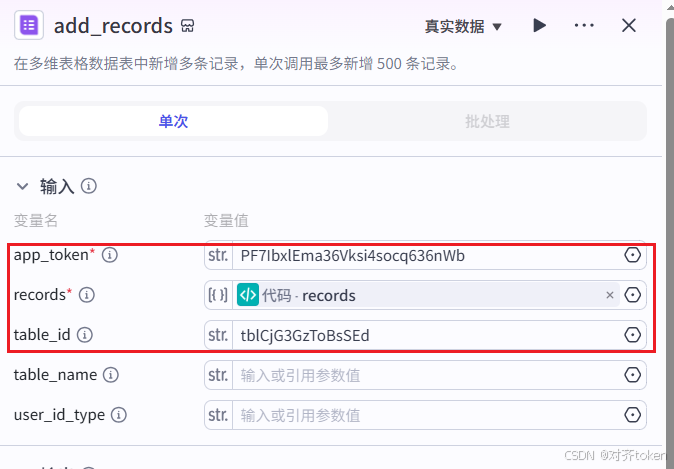
- 在代码节点后,添加插件,搜索 "飞书" ,找到官方的 "飞书多维表格" ,选
add_records功能。 - 配置参数:
app_token:粘贴在准备工作中获取的app_token(即base/后面的那串字符)。table_id:粘贴在准备工作中获取的table_id(即?table=后面的那串字符)。records:点击"添加变量"→"节点引用"→选择 代码节点 →records。
- 在代码节点后,添加插件,搜索 "飞书" ,找到官方的 "飞书多维表格" ,选
- ⭐ 首次使用需授权:点击"飞书多维表格"插件节点上的"去授权"按钮。在弹窗中选择"单独授权",使用已创建好应用并关联了表格的飞书账号登录并授权。
🔧 测试技巧 :授权时如果遇到"获取授权码为空 "或失败 ,建议多刷新重试几次。一般2-3次就能成功。如果插件里没看到
app_token或table_id输入框,可以先手动输入参数名,再点击"去授权"。
6️⃣ 第七步:连接、测试与发布
- 🖱️ 连接 :
- 在循环体内,将代码节点底部连到"飞书写入"插件顶部。
- 点击左上角返回主画布,检查所有连线是否正确:
开始 → 头条搜索 → 循环 → 结束。
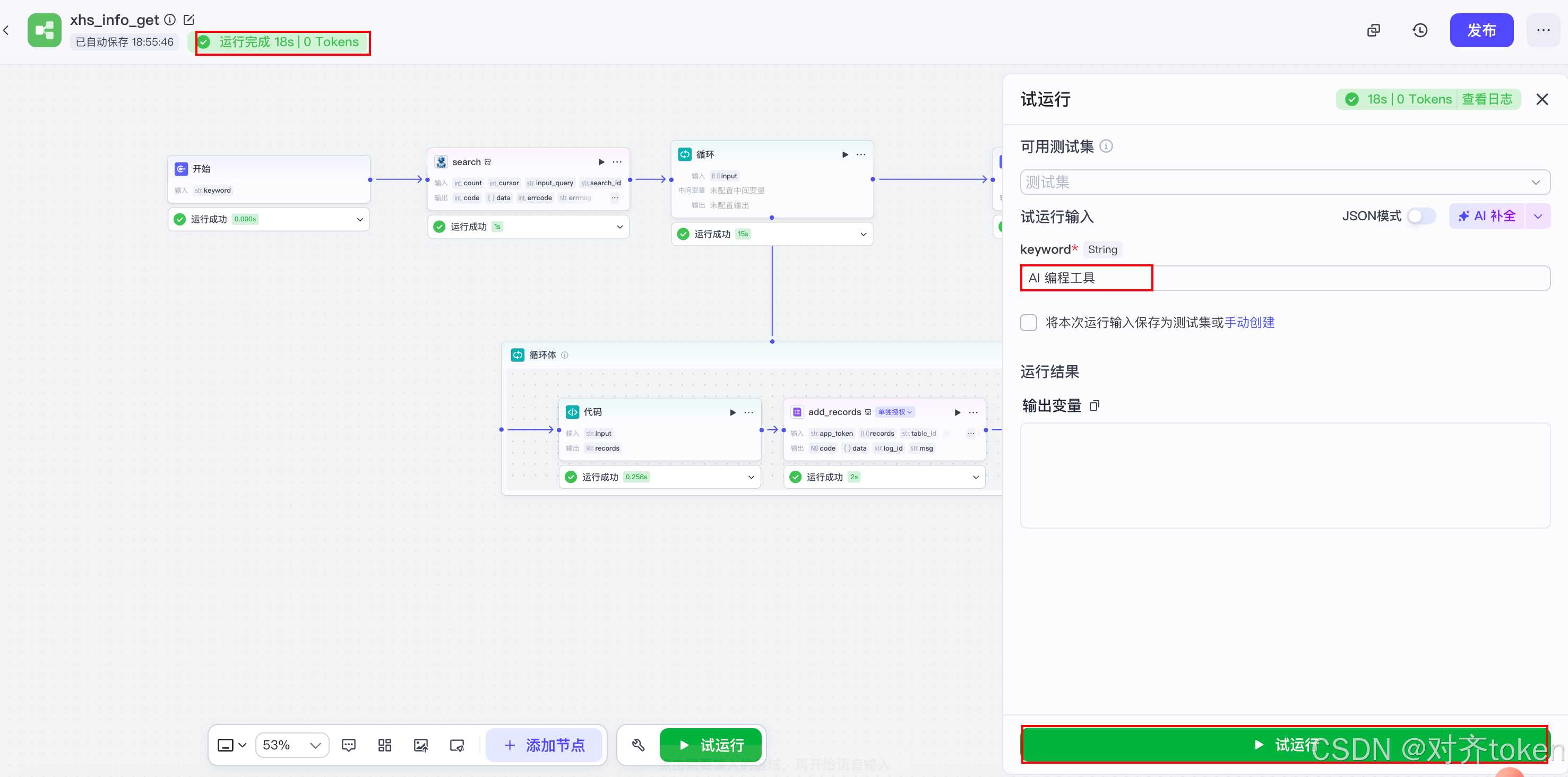
- 🧪 测试调优 :
- 点击画布右上角的 "试运行"。
- 输入一个关键词,比如"AI工具",采集数量先填 3。
- 点击运行,观察节点变绿,最后看飞书多维表格里是不是多出了3行数据。
- 如果写入失败:
- 检查1 :代码节点里的
fields里的 key 和飞书表格列名是否一模一样。 - 检查2 :
app_token和table_id是否分别粘贴正确,没有搞混。 - 检查3:飞书应用权限是否已开通并发布,表格是否已关联该应用。
- 检查1 :代码节点里的
- 🚀 发布:测试通过后,点"发布",再回到智能体或API中调用即可。
⚠️ 常见踩坑与排错
| 现象 | 原因 | 解决 |
|---|---|---|
| 搜索插件返回空数据 | input_query 未正确引用开始节点的 keyword | 检查插件配置面板,确认引用路径为 开始节点 → keyword |
| 飞书写入报错"格式错误"或"fields cannot be extracted" | 代码输出的 fields 里的 key 和飞书表格列名不一致 | 回代码节点核对每个 key,包括空格、标点全角半角 |
| 循环中途中断 | 某条新闻的字段为空(如 title 为 null) | 在代码节点加保护:title = args.title or "" |
| 插件授权失败 | 应用权限未生效或发布未完成 | ① 检查是否已创建版本并发布;② 等待几分钟再试;③ 确认"权限管理"中已开通多维表格权限 |
| 写入时提示找不到表格 | app_token 或 table_id 填错,或表格未关联应用 | 重新检查 URL 中的两串字符是否正确复制;确认表格已添加文档应用 |
最浪费时间的是代码块,一度三次放弃,始终不能正确解析,最后一步一调试才通过的,主要原因:
- item_str= args"params""input" :params 这货是固定的,input 是你参数名
- "fields": {}:这货必须叫 fields
- 这种时候不适合单步调试,必须完整的调试,看报错日志
💡 留给读者思考:方案三,实现完全自动化
到这里,你已经跑通了整个流程。
那么,如何让它更上一层楼,实现完全自动化呢?这就是留给你的"方案三"思考题。
它的雏形其实已经在你手上了。
在扣子平台里,你可以给任何智能体或工作流添加"定时触发器"------设置在每天早上8:00自动执行,固定好关键词,到点就能自动把最新的爆款笔记送入你的飞书表格。
这个方案的挑战不在于"能不能做",而在于"怎么做才稳"。你需要思考:
- 触发器的稳定性 :如何确保设置好的定时任务不"掉链子"?是检查工作流日志,还是增设异常告警?
- Cookie的动态更新:Cookie是有有效期的,不能一劳永逸。能否设计一个机制,让它能在失效前自动更新,或者通过其他API(如官方开放平台)来规避这个问题?
- 关键词的自动轮换 :如果我想监控"AI工具 "、"内容创作 "、"小红书运营"等多个关键词,是创建多个定时任务,还是能在工作流里自动循环处理关键词列表?
当你把这些问题都想清楚并动手去验证,你就不再是跟着教程做的"小白 ",而是能独立设计自动化方案的"创作者"了。