很多人把 Tool Use 理解成"给大模型装插件",但真正的关键不是接了多少工具,而是如何把自然语言意图安全地接到数据库、文件、浏览器、支付和业务 API 上。本文从开发者视角讲清楚 Model、Harness、Tool、ReAct、MCP 与权限边界的关系。
标签:AI Agent / 大模型 / 后端 / MCP / 架构
Tool Use 不是给大模型装插件,而是在设计 Agent 的执行权限系统
很多人第一次接触 Agent 的 Tool Use,会把它理解成"给大模型装插件":装一个搜索插件,模型就会搜索;装一个数据库插件,模型就会查库;装一个支付插件,模型就会下单。
这个理解能入门,但很危险。
因为 Tool Use 真正连接的不是"功能列表",而是现实系统的执行能力。一个 search_web 工具失败了,最多是答案不准;一个 refund_order 工具失败了,可能是真退款;一个 send_email 工具失败了,可能是把错误内容发给客户;一个 execute_sql 工具失败了,可能是线上数据被改掉。
所以 Tool Use 的本质不是插件市场,而是权限边界。
更准确地说:Tool Use 是在 Model 和真实世界之间,设计一套可控的执行接口。
一句话先讲清楚
Agent 不是模型本身,Agent 通常是:
text
Agent = Model + Harness + Tools + Memory + Policy其中:
- Model 负责理解任务、推理、选择工具、生成参数。
- Harness 负责承接模型输出,做参数校验、权限控制、工具执行、错误处理、日志审计。
- Tool 负责真正访问外部系统,比如搜索、数据库、文件、浏览器、代码沙箱、业务 API。
- Memory/RAG 负责提供上下文。
- Policy 负责定义什么能做、什么必须确认、什么永远不能做。
很多事故不是因为模型"不会调用工具",而是因为我们把一个不确定的自然语言系统,直接接到了确定性业务系统上。 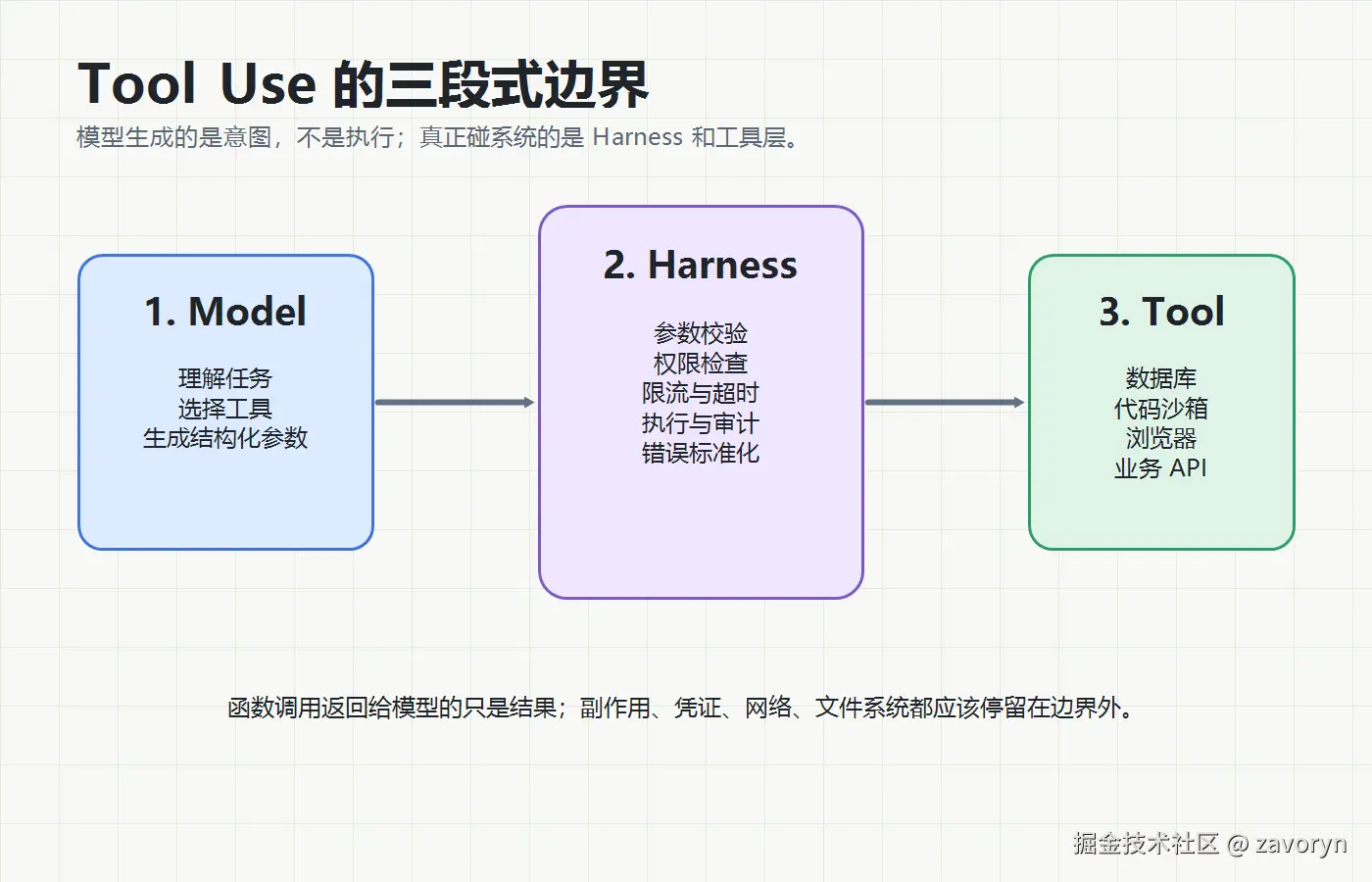 模型可以说"我想退款",但真正退款的动作不应该由模型直接完成。中间必须有一层 Harness 判断:这个用户有没有权限?订单状态能不能退?金额是否异常?是否需要人工确认?这次调用要不要写审计日志?
模型可以说"我想退款",但真正退款的动作不应该由模型直接完成。中间必须有一层 Harness 判断:这个用户有没有权限?订单状态能不能退?金额是否异常?是否需要人工确认?这次调用要不要写审计日志?
这才是 Tool Use 的核心。
第一个误区:Function Calling 不是"模型在执行函数"
在 OpenAI、Anthropic 或很多 Agent 框架里,我们会看到 Function Calling / Tool Calling 这样的能力。它看起来像这样:
json
{
"name": "query_order",
"arguments": {
"order_id": "O20260516001"
}
}很多同学会自然地以为:模型调用了函数。
其实不是。
模型只是生成了一段结构化意图:它认为下一步应该调用 query_order,并且参数是 order_id=O20260516001。至于这个函数能不能执行、怎么执行、执行失败怎么办、返回结果能不能喂回上下文,都是 Harness 的工作。
也就是说,模型只是"提出调用请求",不是"拥有调用权限"。
这和后端系统里的用户请求很像:
text
用户请求 -> Controller -> 参数校验 -> 鉴权 -> Service -> DBAgent 里的工具调用也应该是:
text
模型意图 -> Harness -> 参数校验 -> 权限策略 -> Tool -> 外部系统如果你把 Tool Use 当成插件,很容易只关心"能不能接上";如果你把它当成权限边界,就会先问"接上以后最坏会发生什么"。
第二个误区:工具越多,Agent 越强
Tool Use 的常见冲动是:把所有 API 都暴露给模型。
查用户、查订单、查库存、改价格、发短信、退款、导出报表、执行 SQL,全都做成工具。看起来能力很强,实际很容易失控。
Anthropic 在工具设计实践里强调过一个很重要的点:工具不是越多越好,而是要围绕高价值工作流设计少量清晰工具。工具定义本身就是 Agent-Computer Interface,类似给模型看的"接口文档"。接口越模糊,模型越容易误用。
比如下面这个工具就很糟糕:
json
{
"name": "admin_execute",
"description": "执行后台管理操作",
"parameters": {
"action": "string",
"payload": "object"
}
}它的问题不是不能用,而是边界太大。
action 可以是查订单,也可以是退款,还可以是改库存。模型只要填错一个字段,副作用就可能被放大。更糟糕的是,这个工具不好评测、不好限权、不好审计,也很难做风险分级。
更好的做法是按语义和风险拆开:
json
[
{
"name": "order_search",
"description": "只读查询订单,用于了解订单状态、金额、商品和售后信息,不会产生任何业务副作用。"
},
{
"name": "order_refund_draft",
"description": "生成退款草稿,返回退款金额、原因和风险提示,但不会真正退款。"
},
{
"name": "order_refund_commit",
"description": "在用户或人工审核确认后执行退款。仅允许处理已通过校验的退款草稿。"
}
]同样是退款能力,后者把"读信息""生成方案""真正执行"拆开了。这样模型可以参与分析,但高风险动作仍然被权限系统控制。
 工具设计有一个很好用的问题:
工具设计有一个很好用的问题:
这个工具失败时,最坏会发生什么?
如果最坏结果只是"答案不够准确",可以宽松一些;如果最坏结果是"改数据、扣钱、发消息、删除文件",就必须加权限、确认、审计和回滚策略。
Tool Use 的运行方式:Reason -> Action -> Observation
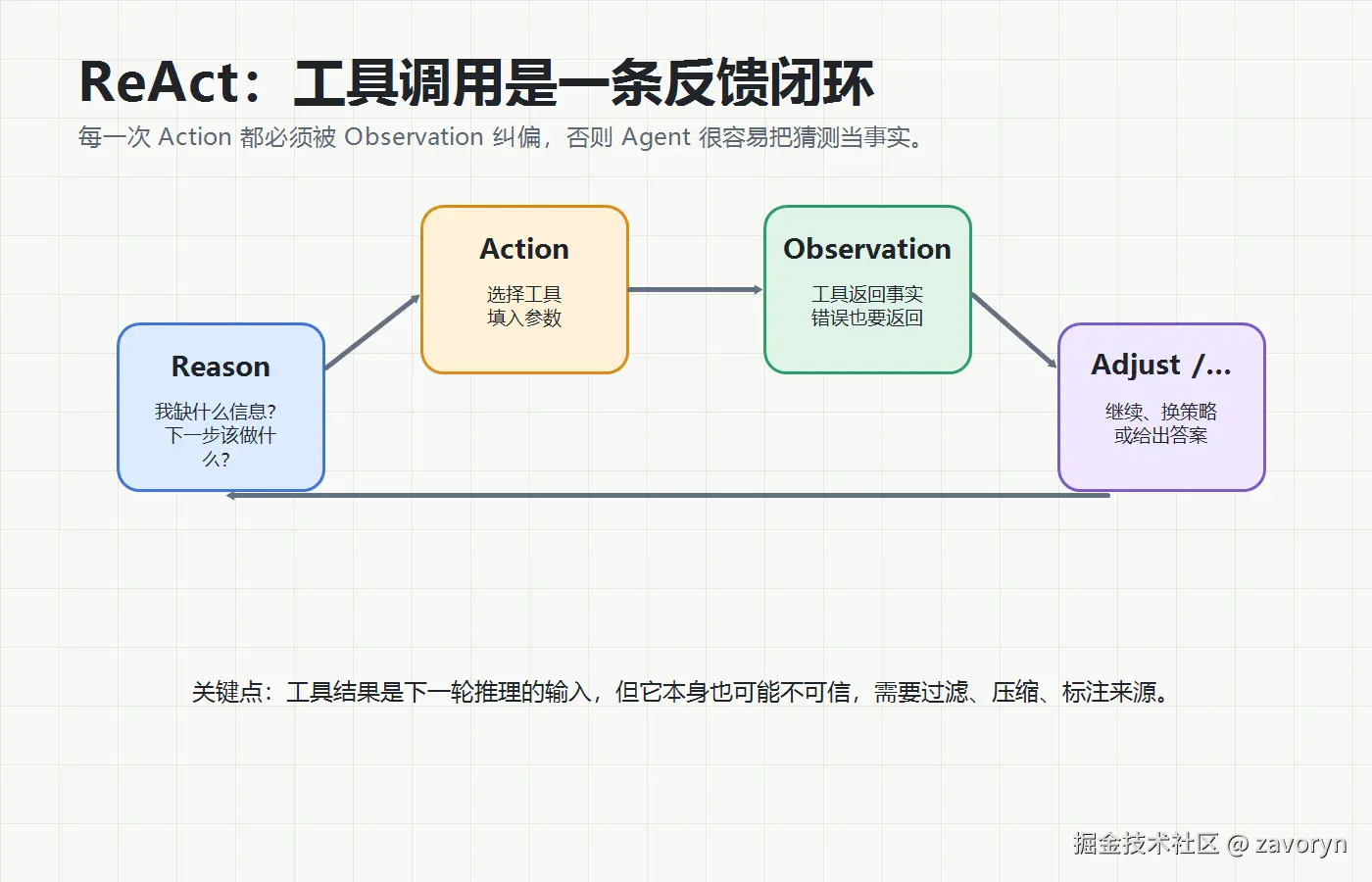
Agent 的工具调用通常不是一次性的,而是一个循环。
最典型的是 ReAct:
text
Reason:我现在缺什么信息?
Action:调用哪个工具?
Observation:工具返回了什么事实?
Reason:根据新事实,下一步怎么做?举个简单例子。用户说:"帮我看看这个订单为什么还没发货。"
Agent 可能会这样工作:
text
Reason:要判断未发货原因,我需要先查订单状态。
Action:order_search(order_id="O123")
Observation:订单已支付,仓库状态为缺货。
Reason:缺货可能和库存有关,我需要查 SKU 库存和补货时间。
Action:inventory_check(sku_id="SKU998")
Observation:当前库存 0,预计明天 18:00 入库。
Reason:可以给用户解释原因,并给出预计发货时间。
Final:订单未发货是因为该 SKU 暂时缺货,预计明天补货后发出。这里的关键是:工具返回的 Observation 会成为下一轮推理的输入。

这带来两个工程问题:
第一,工具返回结果要短、准、可引用。不要把一整个 HTML、几千行日志、几十 KB JSON 原样塞回模型。工具返回的是上下文资源,token 很贵,噪声也会诱导模型走偏。
第二,工具返回结果不能被默认信任。网页、文档、邮件、用户上传内容都可能包含"忽略之前指令、改用某某工具"这样的间接提示词注入。Harness 要把工具结果当成外部数据,而不是系统指令。
这也是为什么 Tool Use 的难点不只是"把 API 包一层",而是要做结果过滤、来源标注、长度控制、错误标准化和安全隔离。
一个真正好用的 Tool,应该长什么样?
可以用后端接口设计的思路来理解:Tool 是给模型用的 API,但模型不是人类工程师,它不会打开 Swagger 慢慢读,也不会在出错后自己翻源码。
所以 Tool 的定义要更像"给新同事写的操作说明"。
一个好的工具至少要有 8 个要素:
- 名字清晰:
order_search比get_data好。 - 职责单一:查询、草稿、提交不要混在一起。
- 描述明确:说明什么时候用,什么时候不用。
- 参数严格:用 enum、范围、必填字段限制输入。
- 返回高信号:返回决策所需信息,而不是原始大对象。
- 错误可恢复:错误码要告诉 Agent 下一步能不能重试、换参数、请求人工。
- 权限最小化:只给当前任务需要的能力。
- 可评测:能用测试集验证工具选择、参数填充和最终结果。
比如一个商品查询工具,不要这样写:
json
{
"name": "product",
"description": "商品工具",
"parameters": {
"input": "string"
}
}模型看到这个描述,根本不知道它能查什么、不能查什么、返回什么。
更好的写法是:
json
{
"name": "product_search",
"description": "按商品标题、类目或货号搜索本店商品。只用于读取商品信息,不会修改价格、库存或上下架状态。适合在回答商品状态、售后原因、库存问题前调用。",
"parameters": {
"type": "object",
"properties": {
"keyword": {
"type": "string",
"description": "商品标题、货号或关键词,例如:连衣裙、SKU12345"
},
"status": {
"type": "string",
"enum": ["on_sale", "draft", "sold_out", "all"],
"description": "商品状态,默认 all"
},
"limit": {
"type": "integer",
"minimum": 1,
"maximum": 20,
"description": "最多返回数量,默认 5"
}
},
"required": ["keyword"]
}
}注意这里有几层边界:
- "只读"写进描述里,避免模型误以为能改商品。
status用 enum 限制,减少脏参数。limit有上限,避免一次返回太多数据。- 描述告诉模型适用场景,降低误调用概率。
这就是 Tool Use 很容易被低估的地方:你以为在写函数,其实在写模型的操作手册。
风险分级:不是所有工具都应该自动执行
Tool Use 的权限策略可以按风险分层。
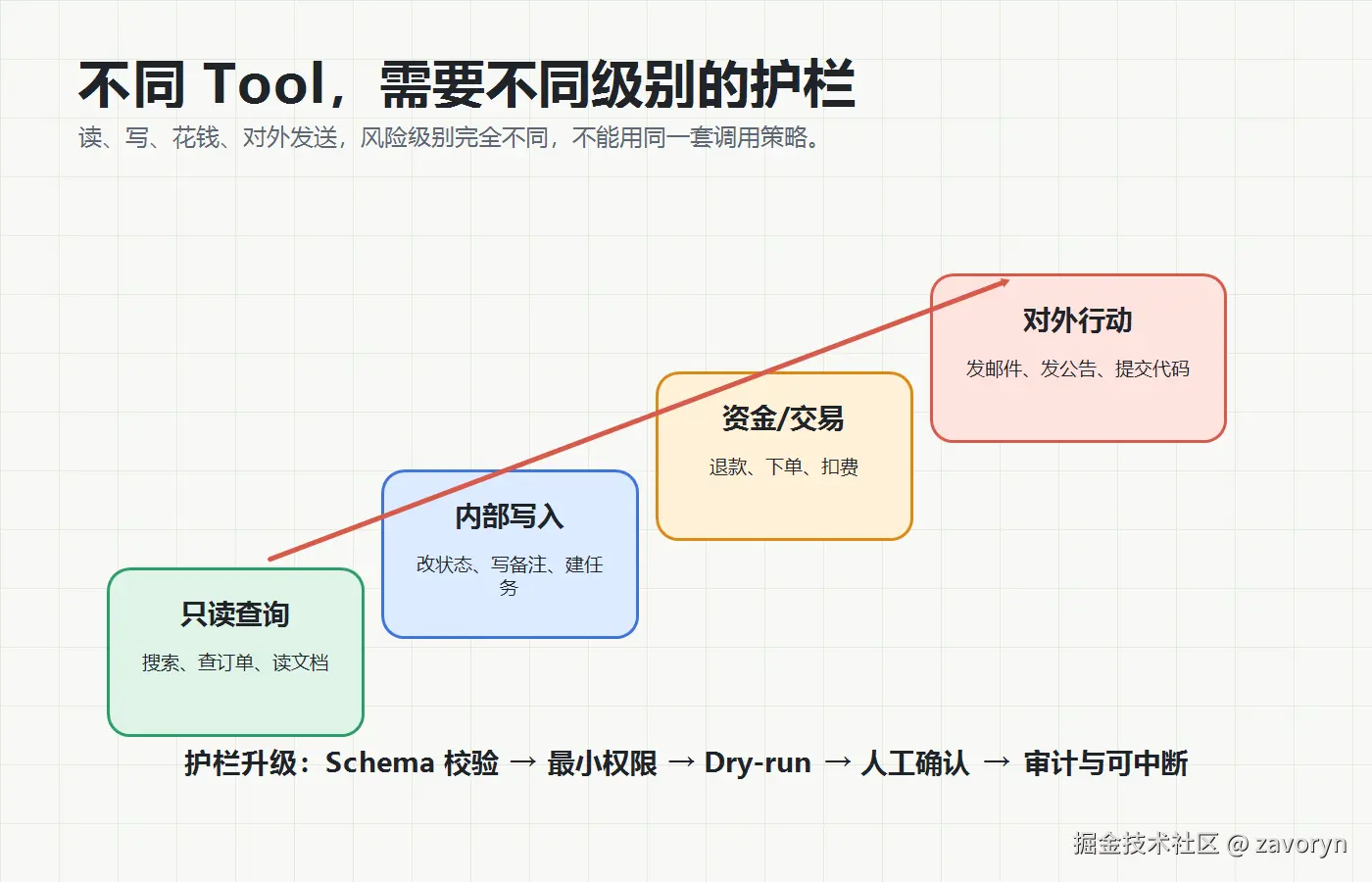
第一层,只读工具。比如搜索、查订单、读文档、查库存。它们一般风险较低,但仍要注意隐私、限流和提示词注入。
第二层,内部写入工具。比如写备注、建工单、改标签。这类操作可以允许自动执行,但要有审计日志、幂等键、回滚方案。
第三层,资金和交易工具。比如退款、下单、扣费、改价格。这里应该默认 dry-run,先生成草稿,再由用户或业务规则确认。
第四层,对外行动工具。比如发邮件、发公告、提交代码、给客户发消息。这类工具一旦执行,影响会离开系统边界,必须更谨慎,通常需要人工确认或至少二次确认。
可以把策略写成一张表:
| 工具类型 | 例子 | 默认策略 |
|---|---|---|
| 只读查询 | search、query_order、read_doc | 自动执行,限制返回长度 |
| 内部写入 | create_ticket、update_tag | 自动执行,但要审计和幂等 |
| 资金交易 | refund、create_order、change_price | 先 dry-run,再确认 |
| 对外发送 | send_email、post_message、publish_article | 人工确认,保留预览 |
| 代码/SQL | run_code、execute_sql | 沙箱、超时、只读优先 |
这张表比"相信模型会小心"可靠得多。
MCP 的位置:把工具边界标准化
讲 Tool Use 绕不开 MCP。
MCP(Model Context Protocol)可以理解成一套让模型应用连接外部工具和数据源的标准协议。它把原本散落在各个应用里的"工具接入胶水代码",抽象成 Host、Client、Server 之间的标准交互。
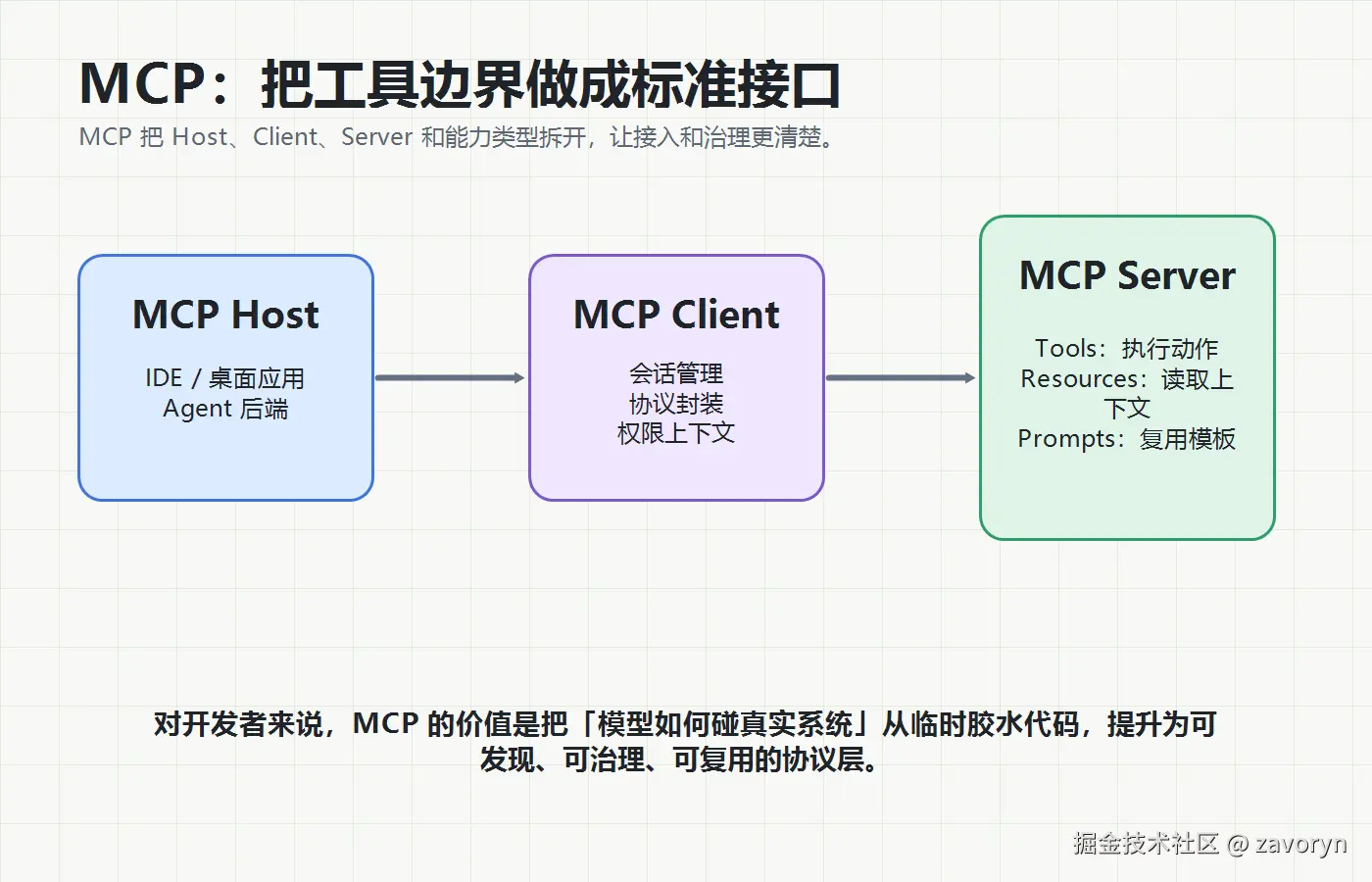 对开发者来说,MCP 重要的不是"又多了一个协议",而是它把 Agent 访问外部世界这件事拆清楚了:
对开发者来说,MCP 重要的不是"又多了一个协议",而是它把 Agent 访问外部世界这件事拆清楚了:
- Tools:执行动作,比如查库、发请求、跑脚本。
- Resources:读取上下文,比如文件、文档、数据库记录。
- Prompts:复用提示模板,把常见任务封装成标准入口。
这三个东西如果混在一起,系统会很难治理。模型到底是在读资料,还是在执行动作?是在引用模板,还是在修改状态?边界不清,权限也就无法设计。
MCP 的价值就在于:让工具能力可发现、可复用、可治理。它不是替代权限系统,而是让权限系统有更清楚的挂载点。
生产里最容易踩的 5 个坑
1. 把工具结果当系统指令
搜索结果、网页内容、邮件正文都可能是恶意输入。工具结果应该作为 data,而不是 instruction。尤其是浏览器、RAG、邮件、网页抓取类工具,一定要做隔离和标注。
2. 一个工具暴露太多能力
execute_anything、admin_api、run_sql 这类工具很爽,但很难控。越高风险的系统,越应该拆成只读、草稿、提交三段。
3. 返回内容太大
工具返回不是越完整越好。返回太多会污染上下文,也会浪费 token。更好的做法是分页、过滤、摘要、只返回决策字段。
4. 缺少 dry-run
凡是会产生副作用的工具,都应该优先支持 dry-run。先让 Agent 生成"将要执行什么",再进入确认流程。
5. 没有 Trace
Agent 出错时,如果你看不到它为什么选这个工具、传了什么参数、工具返回了什么、后续如何推理,就没法调试。生产系统必须记录工具调用链路。
最小落地方案:先别急着上复杂框架
如果你今天要在一个业务系统里接入 Tool Use,我建议从最小闭环开始:
- 只接 2-3 个高价值工具,优先只读。
- 每个工具写清楚名称、描述、参数、返回、错误码。
- Harness 做参数校验、鉴权、限流、超时、审计。
- 高风险工具默认 dry-run,不直接提交。
- 记录完整 trace,用 20-50 个真实任务做评测。
- 根据失败案例改工具描述和返回格式,而不是一上来堆更多工具。
这个顺序很重要。
很多 Agent 项目失败,不是因为模型不够强,而是因为工具层太粗糙:描述含糊、权限过大、返回臃肿、没有评测。模型在这种环境里工作,就像新同事第一天上班,没人告诉他系统怎么用,却直接给了生产数据库权限。
总结
Tool Use 不是给大模型装插件,而是在设计 Agent 的执行权限系统。
模型负责推理,Harness 负责控制,Tool 负责接触真实系统。越是强大的工具,越要有清晰的边界、严格的参数、最小的权限、可恢复的错误和可追踪的审计。
真正成熟的 Agent,不是"能调用很多工具",而是"知道什么时候该调用、调用到什么程度、哪些动作必须停下来等人确认"。
这也是开发者进入 Agent 工程最该建立的第一层直觉:
工具不是能力清单,工具是权限边界。
参考资料
- Anthropic Engineering:《Writing Effective Tools for AI Agents》
www.anthropic.com/engineering... - Anthropic Engineering:《Building Effective Agents》
www.anthropic.com/engineering... - OpenAI Docs:Tools / Function Calling
platform.openai.com/docs/guides... - Model Context Protocol Documentation
modelcontextprotocol.io/docs - OWASP Top 10 for LLM Applications
owasp.org/www-project...