文章目录
- 前言
- 一、磁盘
-
- 1.1、简单认识磁盘
- 1.2、磁盘的物理结构
- 1.3、磁盘的存储结构
- 1.4、磁盘的逻辑结构
- [1.5、LBA & CHS地址](#1.5、LBA & CHS地址)
- 二、引入文件系统
- 三、🌟Ext2文件系统🌟
-
- 3.1、宏观认识
- [3.2、块组Block Group的内部组成](#3.2、块组Block Group的内部组成)
-
- [3.2.1、inode Table && Data Blocks](#3.2.1、inode Table && Data Blocks)
- [3.2.2、inode Bitmap && Block Bitmap](#3.2.2、inode Bitmap && Block Bitmap)
- 3.2.3、GDT
- [3.2.4、Super Block](#3.2.4、Super Block)
- 3.3、目录与文件名
- 3.4、路径解析&路径缓存🌟
- 3.5、存储大文件问题
- 3.6、挂载分区
- 三、软硬链接
前言
在基础IO(有需要了解的读者可以点击此链接)部分,我们已经深刻了解了LinuxOS下的内存级文件系统。今天,本文将继续探讨LinuxOS的文件系统------Ext系列文件系统 ,即磁盘级文件系统,并将其与内存级文件系统的知识相关联,形成一张紧密的Linux文件系统体系。
一、磁盘
1.1、简单认识磁盘
要深刻理解磁盘级文件系统,那么首先就必须要对磁盘有着一定的理解。

磁盘(disk) ,也可称为机械磁盘 ,是指利用磁 记录技术存储数据的存储器 。
它是计算机中唯一的机械设备,它的特点用四个字即可概括:量大便宜 。"量大"指的是存储容量大
目前,我们接触磁盘的机会相对来说已经比较少了,作为大学生,基本上用的都是笔记本电脑,而笔记本电脑中所使用的都是SSD(固态硬盘),与磁盘不同,存储原理与运作原理也大不相同。如果是自己组装过电脑,或者了解过机房的人可能对磁盘会比较熟悉。
1.2、磁盘的物理结构

磁盘内部主要由主轴、磁片、磁头等组成。
磁片是一个非常光滑的镜面,肉眼看上去有点像平时用到的光盘,它相当于一张纸我们存储的数据就保存在上面;
而磁头就相当于笔,用于写入数据;
主轴就相当于一个马达,在磁盘内部高速旋转,磁头臂则带动着磁头来回摇摆,两者相互配合,进而用来准确寻找对应写入的位置。
注意:磁头臂上的磁头是共进退 的。这一点极其重要
1.3、磁盘的存储结构
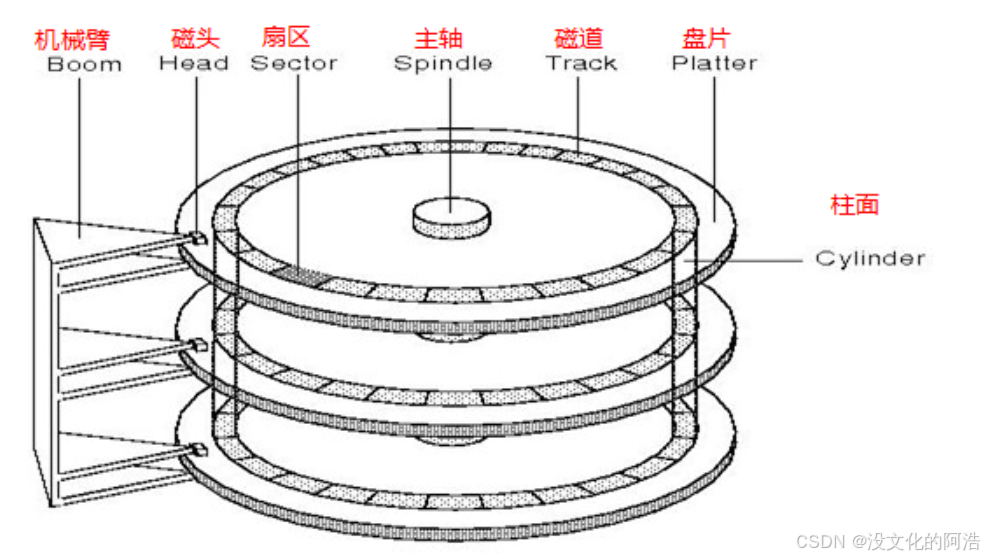
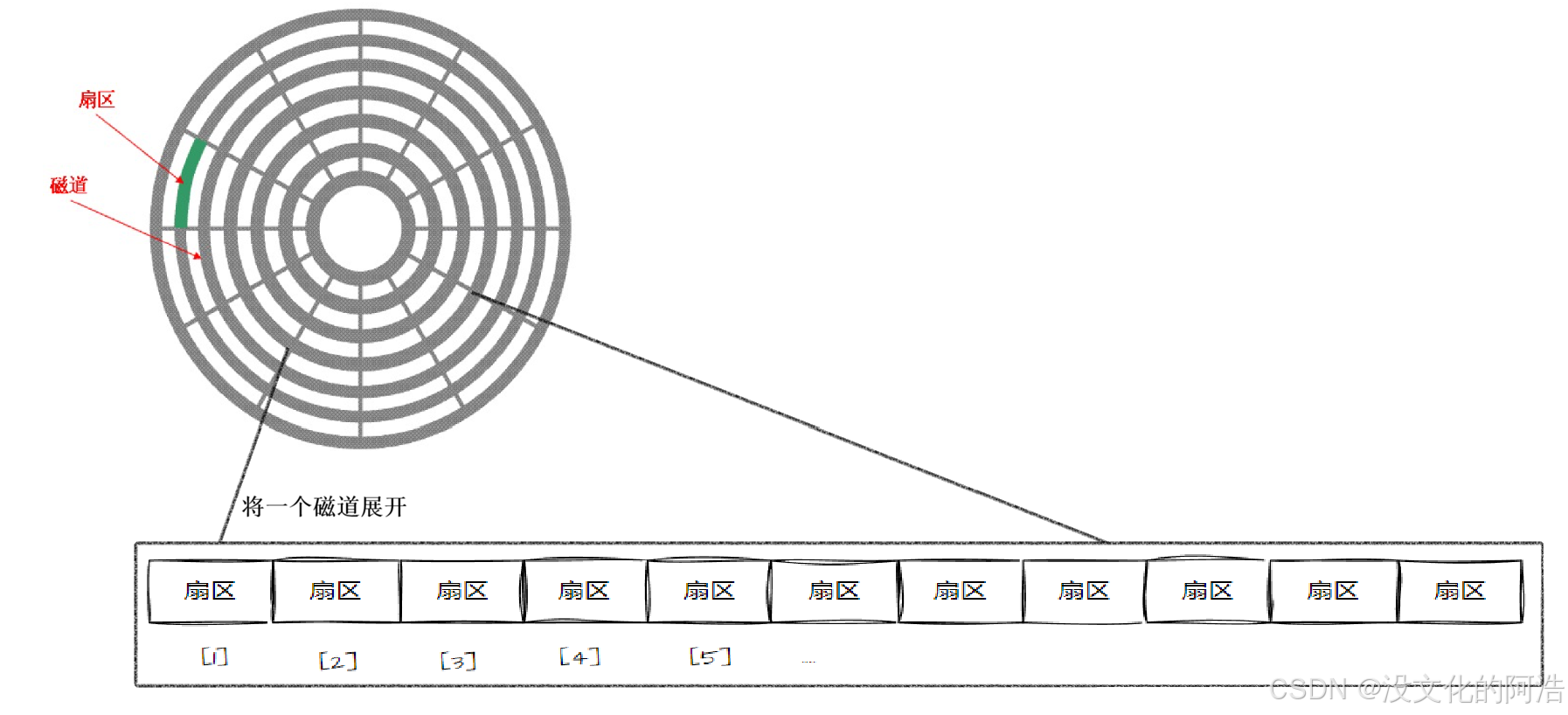
整个盘面在存储结构上还可以更加精细地划分为一块一块的扇区 ,扇区是磁盘存储数据的基本单位 ,即从磁盘读出和写入信息的最小单位,一块扇区占有512Byte 。
而一块盘面上,对应一圈的扇区所组成的圆环又称作磁道 。每个盘面上,与主轴相对距离相同的磁道又共同组成柱面 ,可以认为 磁盘整体是由柱面组成的。注意,一个盘片可能会有两个盘面, 而每一个盘面对应一个磁头
因此,我们可以大致得出一个磁盘存储容量的计算公式: 磁盘容量 = 磁头数(盘面数)* 柱面数(每面磁道数)* 每道的扇区数 * 扇区所占的字节数
知道了扇区,柱面等概念,此时我们就可以回答一下问题:
问题:我们应该如何向一块扇区写入数据呢🧐??
- 如果要向某一块扇区写入数据,那么首先必须要做的就是找到那块对应的扇区!!
- 磁盘在进行访问的时候,首先确定的是我们要访问哪一块柱面(cylinder),那么,我们如何确定柱面呢??
- 我们先前提过所有磁头通过磁头臂实现共进退 ,这一行为本质就是在寻找对应的柱面!!
- 通过磁头找到对应的柱面后,我们就需要确定所找的扇区在柱面内的哪一个磁道上,这个操作很简单,只需要通过每个面对应的 磁头(header) 就可以轻松解决。
- 最后,在通过盘面的高速旋转就可以定位到指向扇区(sector)。
以上操作,就称之为CHS地址定位,用于硬件上的寻址操作。
1.4、磁盘的逻辑结构
磁盘本质上虽然是硬质的,但是可以抽象地认为磁盘整体是由柱面组成的 ,因此逻辑上我们可以把磁盘想象成为卷在⼀起的柱面,那么磁盘的逻辑存储结构我们也可以类似于:
这样的一个磁道就可以理解为一个一维数组 ,而与之对应的柱面展开,就类似一个二维数组 ,再以柱面为单位,将整个磁盘展开后,即三维数组 ,因此,磁盘的逻辑结构本质上是一个三维数组 。
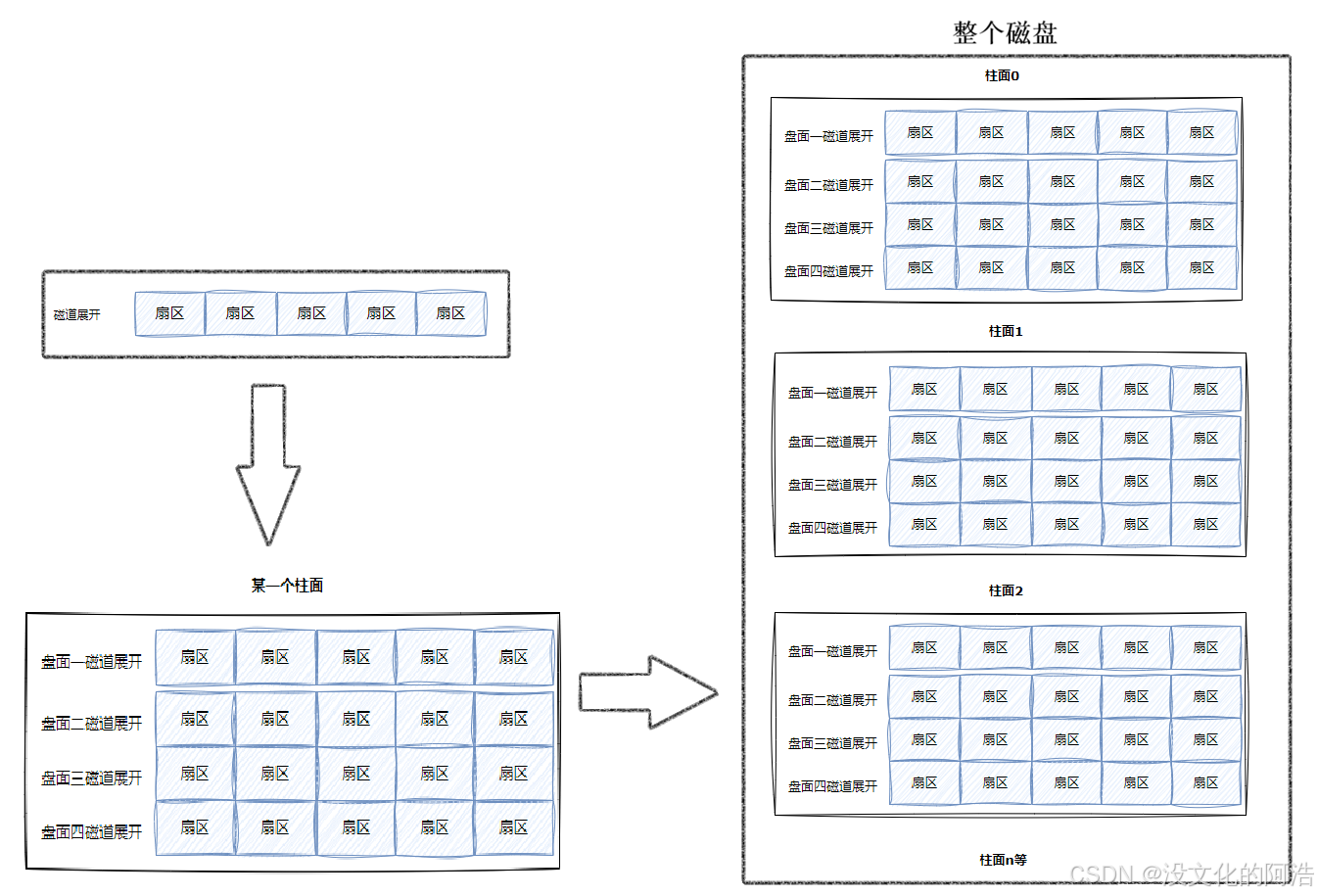
有了这样一个理解后,我们反过来再看CHS地址定位,本质上不就是通过三个数组下标来进行定位操作的吗😲。
我们在学习C/C++的过程中,我们了解,二维数组的本质就是一个存储着一维数组的一维数组。三维数组同理,因此我们又可以将磁盘在逻辑上抽象为一维数组 。

所以,每一个扇区都有一个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。那么我们如何得到这个LBA地址呢?CHS转换成为LBA地址 。CHS如何转换成为LBA地址,谁来做??磁盘自己来做!CHS与LBA地址之间的转换,只需要通过简单的乘除运算即可。
在操作系统的角度来看,我们必须使用LBA地址,为什么呢??
操作系统下具有大量的文件,为了能够迅速的在磁盘上找到对应文件,操作系统有必要记录这些文件在磁盘上的所处位置。如果操作系统使用CHS地址,此时就需要存储三个整型变量,而使用LBA地址,仅仅只要保存一个整型变量,这可以极大地减少操作系统所占空间大小 。因此,操作系统只需要使用
LBA就可以了!
1.5、LBA & CHS地址
接下来,我们就来讲解LBA地址与CHS地址的相互转换。
💧CHS转成LBA :
1️⃣磁头数 *每磁道扇区数 = 单个柱面的扇区总数
2️⃣LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1
扇区号通常是从1开始的,而在LBA中,地址是从0开始的,因此需要-1。柱面和磁道都是从0开始编号的 。
总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
💧LBA转成CHS :
1️⃣柱面号C = LBA // (磁头数 * 每磁道扇区数)【就是单个柱面的扇区总数】
2️⃣磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
3️⃣扇区号S = (LBA % 每磁道扇区数) + 1
//: 表示除取整
所以,从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。
因此,从现在开始,磁盘就是一个元素为扇区的一维数组,数组的下标就是每⼀个扇区的LBA地址。OS使用
磁盘,就可以用一个数字访问磁盘扇区了。
二、引入文件系统
硬盘这个概念讲了这么多,主要就是为了引出扇区的概念!!其他的在操作系统的角度来看,其实并没有那么重要。
2.1、引入"块"概念
如今这个磁盘大小动辄以几百GB为容量的时代,不敢想象会存在着多少个扇区,如果操作系统在读取磁盘数据时以扇区为单位,必然要将它们管理起来,这绝对会产生巨大的开销,并且效率低下,因此,我们很容易就能够联想到,操作系统一定不会直接使用扇区来访问磁盘!!
那么,操作系统将如何来访问磁盘呢🤔??
其实硬盘**(硬盘是磁盘的一种)是典型的 "块"设备 。操作系统读取硬盘数据的时候,其实是不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块(block)**。
硬盘的每个分区是被划分为一个个的"块"。⼀个"块"的大小是由格式化 的时候确定的,并且不可
以更改,最常见的是4KB ,即连续八个扇区组成一个 "块"。"块"是文件存取的最小单位。
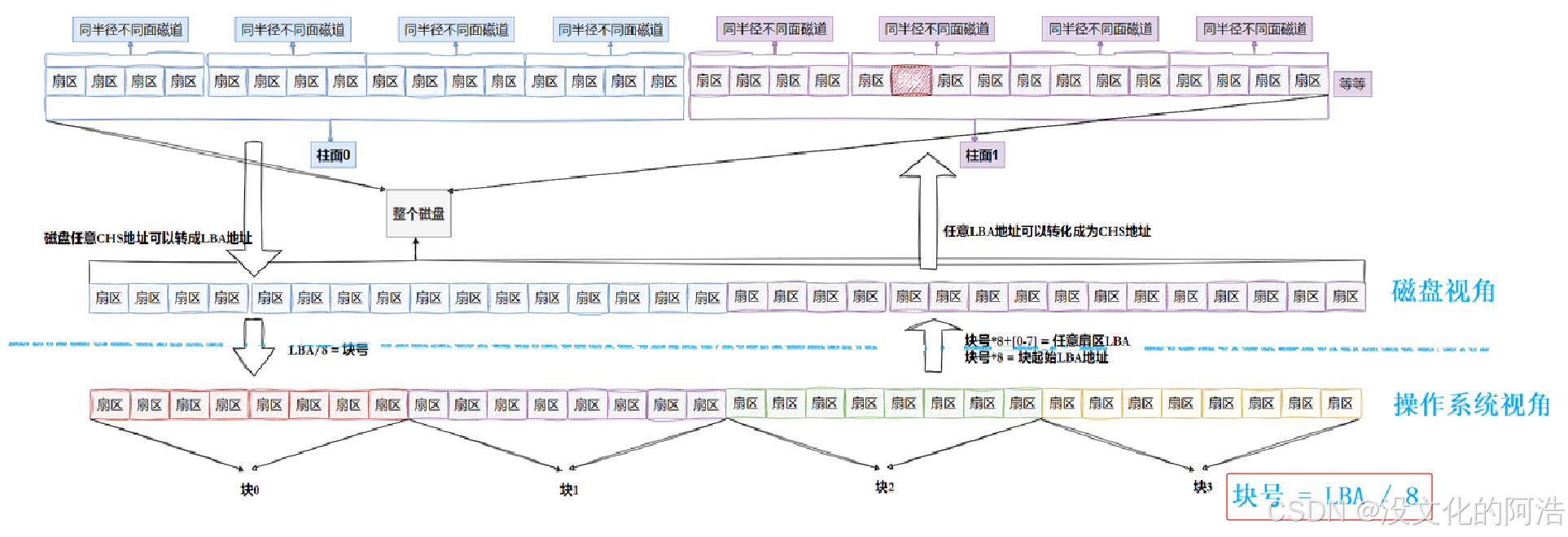
引入块的概念,除了提高操作系统对硬盘的访问效率,还进行了软硬件解耦的功能 。
在操作系统的角度,只需要关心"块";而在磁盘角度,面对的则是"扇区"。两者通过简单的基本运算相互联系。
2.2、"分区"概念
一块磁盘的容量太大,常常以几百GB为主,极其不便于管理😇!!
那么我们应该如何解决这个问题呢??
其实磁盘是可以被分成多个分区 的。
以Windows观点来看,你可能会有一块磁盘并且将它分区成C,D,E盘。那么,这个C,D,E就是分区。分区从实质上说就是对硬盘的一种格式化 。

但是Linux的设备都是以文件形式存在,那是怎么分区的呢??
柱面是分区的最小单位,我们可以利用柱面号码的方式来进行分区,其本质就是设置每个区的起始柱面和结束柱面号码。 此时我们可以将硬盘上的柱面(分区)进行平铺,将其想象成一个大的平面,如下图:

2.3、"分组"概念
但是一个分区还是太大了,就比如windows上的D盘,好几百GB,要直接管理起来,也是还是相当困难。
那么,既然还是太大,我们就继续沿用上文中分区的思想,继续将每一个分区进行划分:将每一个分区进行分组 。就是一种"分治思想"
进而达到以下的结构:
三、🌟Ext2文件系统🌟
3.1、宏观认识
以上所有的准备工作都已经做完,接下来,我们将正式讲解文件系统 了。
我们想要在硬盘上储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。在Linux系统中,最常见的是ext2系列的文件系统。其早期版本为ext2,后来又发展出ext3和ext4。
ext3和ext4虽然对ext2进行了增强,但是其核心设计并没有发生变化,我们仍是以较老的 ext2 作为演示对象。
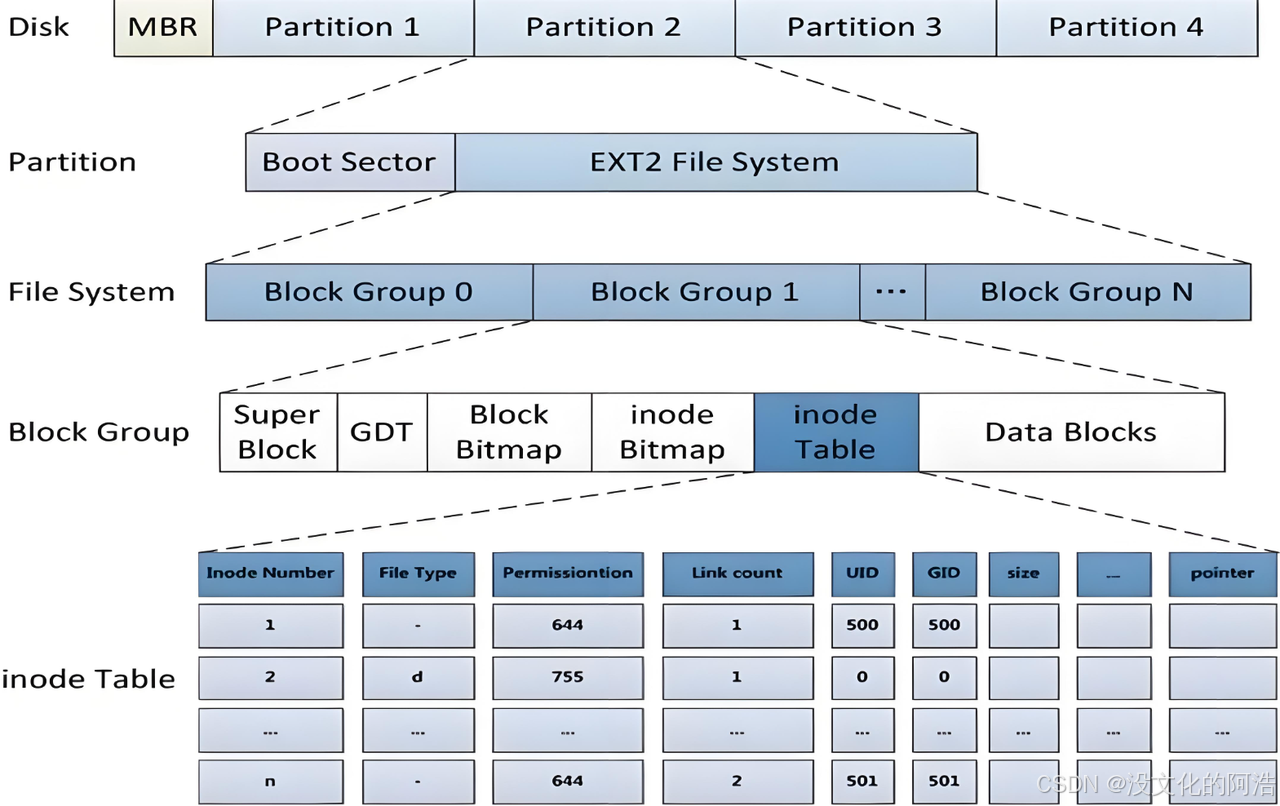
ext2文件系统将整个分区划分成若干个同样大小的块组 (Block Group),如下图所示:
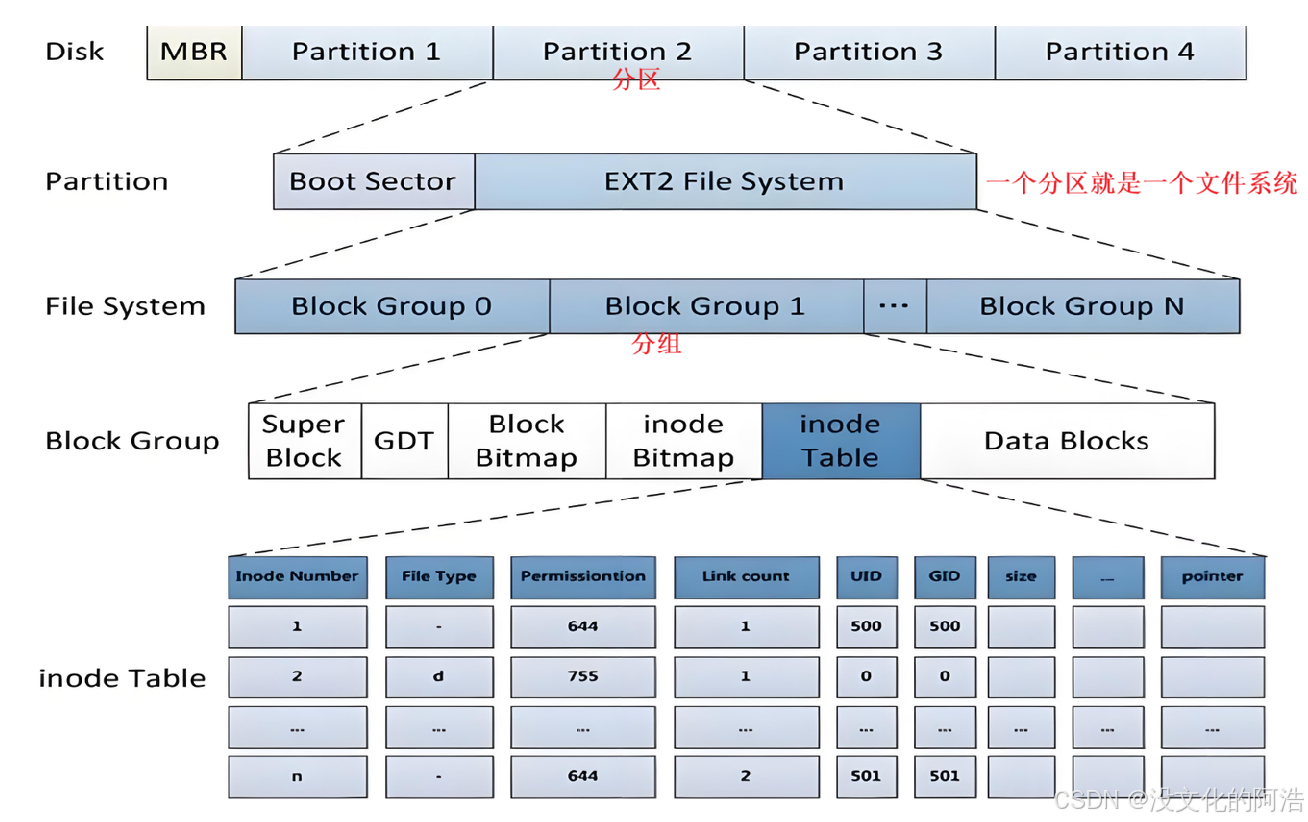
只要能管理一个分区就能管理所有分区,也就能管理所有磁盘文件。
3.2、块组Block Group的内部组成
只要能够管理好一个分组,就能够管理好一个分区,因此我们将以分组为切入点详细探讨文件系统的架构。
Linux下一切皆文件,那么我们的分组自然是用于存放与管理我们的文件。因此,一个分组里头应该包含两部分:文件数据以及管理文件数据的信息。
其中,inode Table和Data Blocks是用于存放文件数据的;inode Bitmap 、 Block Bitmap、GDT以及Super Block则是存放管理文件数据的相关信息。
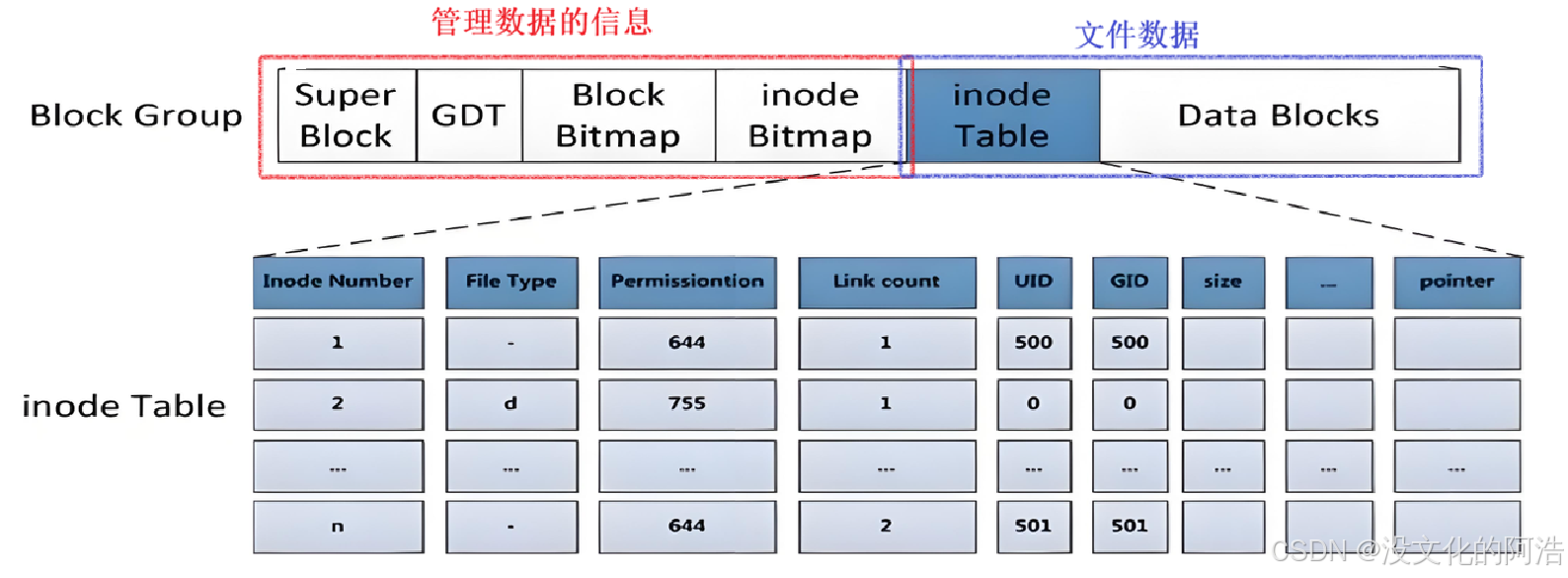
对于一个分区,即文件系统,来说,分组后应该先向每组写入管理信息,再导入对于的文件数据。
就好比某个商场的开张,都是优先让工作人员进入商场管理对应的地方,再开业让顾客进入商场。
此外,分组后,向每组写入管理信息的过程,就叫做写入文件系统 ,俗称格式化。写入全新的文件系统的过程,原文件清空
3.2.1、inode Table && Data Blocks
先输出一个结论:在LinuxOS中,文件内容和文件属性是分开存储的!
在每一个分组中,都存在着inode Table(inode表)和Data Blocks(数据块表)。其中inode表用于存放文件属性,数据块用于存放文件数据。
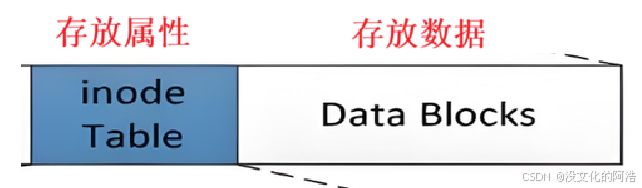
首先,有这样一个问题:文件属性是数据吗🤔??
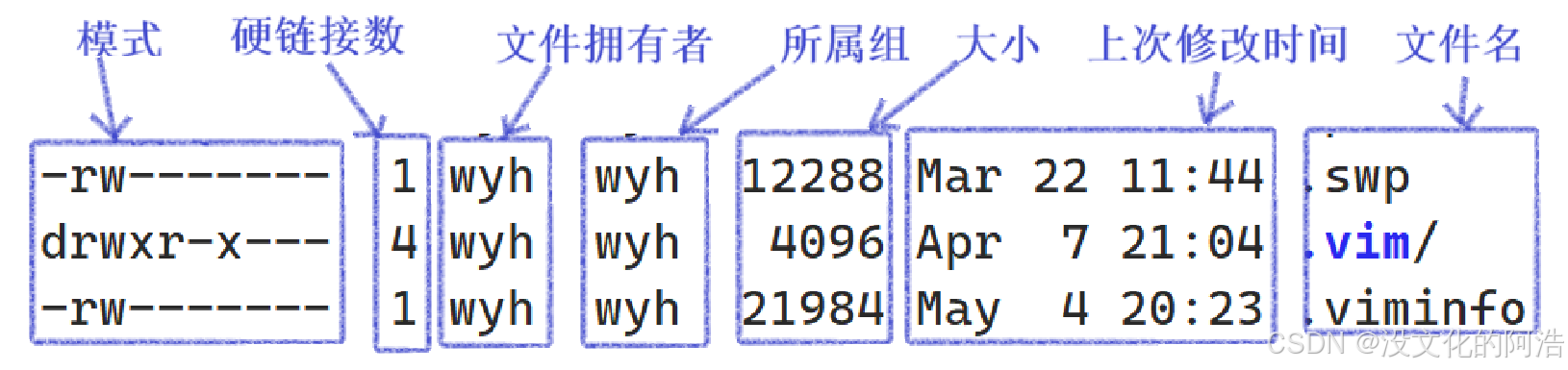
面对这个直击灵魂的问题,我们应该毫不犹豫地说出 "是!!😲" ,从磁盘的角度来看,无论什么本质上都是一种数据。文件属性也叫做元数据
LinuxOS下有这么多文件,每个文件都具有自己的数据,因此,操作系统必然要对这些文件属性进行管理------先描述,再组织!! LinuxOS中,便用struct inode{}来标识文件的属性,其中存有inode编号用于唯一标识。
注意: LinuxOS中,文件名不属于inode的属性!! 每个文件都有一个inode编号来唯一标识。
为了更加深刻地认识inode编号,我们来认识一个新的指令:ls -li,查看文件的更多信息。
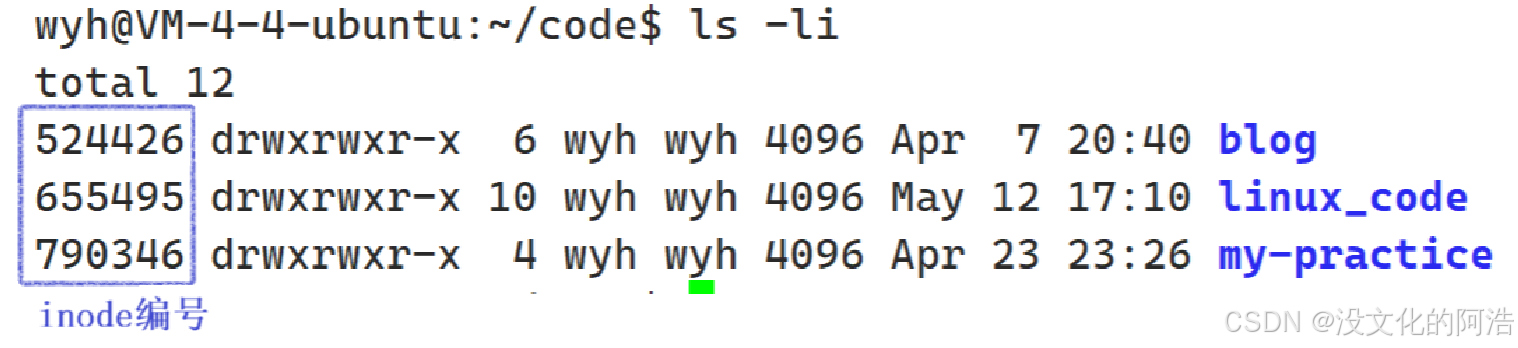
这个数字就是我们的inode编号。目录也是文件哦
一个struct inode{}的大小一般为128Byte,一个数据块恰好可以保存32个struct inode{}。
我们先前说过,inode Table中存放文件属性,那不恰好就是用于存储struct inode{}嘛🤪。于是便有了下图的结构:
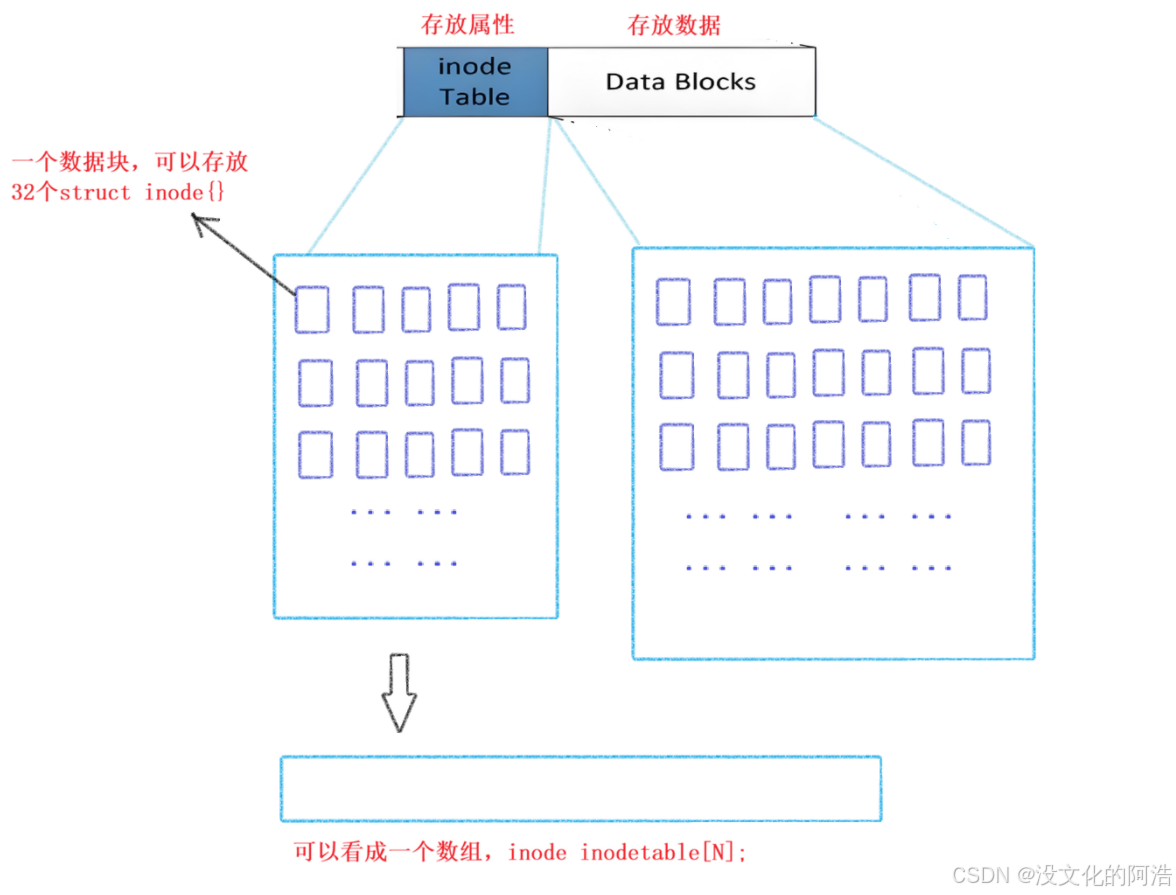
我们的数据块本质上就是八个扇区,我们之前说过,磁盘的逻辑结构本质上是一个一维数组 ,每一个元素都对应这一个扇区,那么我们是否能够将inode Table抽象成一个一维数组呢🤔??当然可以,这样对于struct inode{}的管理,就变成了对一维数组的管理🥹。
看到这里,相信大家一定充斥着一些疑惑,后续内容将逐个解答。
首先,来看这样两个问题:
问题1️⃣:为什么struct inode{}的大小为固定值🤔??
- 我们先前讲过,操作系统会将
inode Table看成一个一维数组进行管理,如果inode结构体的大小不定,就会极大增加工作量来缩影每个inode结构体;而当inode结构体大小固定时,就能够通过简单的数学运算进行快速缩影 ,能够迅速查找到某一个inode结构体属于inode Table的第几个,提高管理效率。 - 为了满足
struct inode{}大小固定,设计者将文件属性的可变内容,最终都转化为整数类型 。
这也解释了"为什么文件名不在inode结构体中",string是可变的,因此我们选择采用编号进行唯一映射。 - 我们来简单看一下struct inode{}的源码💻:
c
/*
* Structure of an inode on the disk
*/
struct ext2_inode
{
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union
{
struct
{
__le32 l_i_reserved1;
} linux1;
struct
{
__le32 h_i_translator;
} hurd1;
struct
{
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS]; /* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union
{
struct
{
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct
{
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct
{
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
// 备注:EXT2_N_BLOCKS = 15问题2️⃣:inode如何与DataBlacks中的内容关联起来的呢🤔??
- 这是一个极其关键的问题!!
- 事实上,每一个数据块也都拥有唯一的编号。
struct inode{}中存有i_block[]数组,其中存放着对于文件内容的数据块的编号!!- 这样,在一个分组中,想要找到一个文件,首先根据文件的inode编号找到对应的inode{},再在inode{}中查找i_block\[\],就能够映射出这个文件对应的数据块。
但是,如果文件太大了,一个分组内的DataBlocks不够存放呢,我们应该如何找到对应的文件呢??这个问题将在后文 "存放大文件问题" 部分给出答案。
3.2.2、inode Bitmap && Block Bitmap
此时,如果有一个新的文件被写入磁盘,那么肯定是要放在空的数据块中,可是我们怎么知道哪一个数据块没有被使用过呢??难道需要一个一个地查看吗??
LinuxOS的设计师们肯定不会使用如此低效的方法。
那么,我们应该如何知道哪一个数据块没有被使用呢🤔??
一个数据块无非就两个状态------被使用或未被使用,对于这种具有二态性 的概念,我们很容易就能够联想到位图 思想。
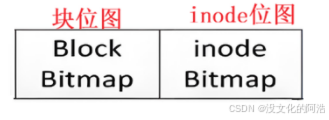
在ext2文件系统中,每个分组都设立了Block Bitmap(块位图),Block Bitmap中记录着DataBlocks中哪个数据块已经被占用,哪个数据块没有被占用。被占用了则用1标识,反之则用0标识。
Block Bitmap中存放的其实也是数据块,只不过这些数据块存放的对于DataBlocks的管理信息。一个数据块4KB,即32768bit,这也就是说一个块就能够管理三万多个DataBlocks中的数据块,因此Block Bitmap并不需要占有太大的空间。
同理,管理inode Table也是运用了同样的位图 思想,操作系统为每个分组都提供了inode Bitmap(inode 位图),它的原理与Block Bitmap几乎一模一样,每个bit表示一个inode是否空闲可用。
既然,一个数据块是否被占用是通过位图来判断的,那么,如果我们想要删除一个文件需要真正的将文件从对应的数据块中彻底清除吗🤔??
我认为,完全不需要,既然仅仅通过位图就能够决定一个数据块的性质,那么我们只需要将这个文件对应的在inode Bitmap和Block Bitmap中对应的比特位由1置0即可。这样只修改位图来删除文件的操作,极大地提高了效率。
那么,这样的操作是否会影响我们后续新建文件呢🤔??
并不会有任何影响,如果我们要新建文件,则先对inode Bitmap的空闲位由0置1,再申请一个struct inode{}存入对应的数据块中,如果该位置留有上个被删除的文件的struct inode{}也不影响,只需要用新的覆盖即可;同理,对于文件内容数据, 对inode Bitmap的空闲位由0置1,再在DataBlocks中申请对应的数据块。
到此,我们能够发现,新建文件的操作相对于删除文件的操作要略显复杂。这也很符合我们日常现象,我们日常在电脑中安装某个大型软件时,比如说游戏,往往要耗费很长时间,但是删除它却非常地快。
3.2.3、GDT
截至目前,我们已经对一个分组的结构已经有了基本认识,这些位图与存放数据块的结构,无论如何,本质上也还是存储于磁盘上的数据,它们一定是磁盘上的一块连续的空间,那么就一定存在这个么一样东西将这一大块存储空间划分为不同的功能区。
在讲解进程地址空间划分时,我们介绍过task_struct中的mm_struct用来划分进程地址空间的不同区域,而mm_struct中,本质就是使用不同的unsign long类型的变量来划分各个区域的界限。
以此类推,文件系统中的每一个分组也一定存在着类似于mm_struct功能的部分,而它就是我们接下来要讲的GDT(Group Descriptor Table/块组描述符表)。
GDT用于描述块组属性信息,整个分区 分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
c
// 磁盘级blockgroup的数据结构
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap */
__le32 bg_inode_table; /* Inodes table block*/
//以上三个变量,用于记录BlockBitmap、inodeBitmap和inode Table的起始位置
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
//以上两个变量,用于记录空缺的块数
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
}其中,bg_free_blocks_count和bg_free_inodes_count分别用于记录空闲的数据块和inode。这也能够提高操作系统对文件增删查改操作的效率。
3.2.4、Super Block
既然,在每一个分组内,我们需要对存储空间进行划分以及存放对应信息,那么在整个文件系统中,我们是否也需要采取对应的措施加强对每个分组的管理呢??
当然是需要的。
Super Block(超级块)用于存放文件系统本身的结构信息,描述整个分区的文件系统 信息。
注意不要与GDT混淆,GDT保存的是一个分组的信息
记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,⼀个block和inode的大小,最近⼀次挂载的时间,最近一次写入数据的时间,最近⼀次检验磁盘的时间等其他文件系统的相关信息。
如果Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
因此,一个分区只能有一个Super Block吗🤔??
理论上是可以的,但是我们绝对不会这么做,因为风险太大了!! 如果某一天,我们的磁盘部分扇区出现物理问题,为了它还能够正常工作,就必须对Super Block进行多次备份,这些Super block区域的数据保持一致,以此提高磁盘的安全性。
那么,是否需要每个组都保存一份Super Block吗🤔??
其实那倒也不必,在保障磁盘信息安全的前提下,适当的进行备份即可。超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有),即一个分区会有多份Super Block。
3.3、目录与文件名
在上一部分,我们反复强调了一件事,那就是inode编号唯一标识文件 ,这件事其实会非常使我们困惑,学习了这么久的Linux操作,我们似乎从来都没有使用过inode,我们一直使用的是文件名,可文件名又不在struct inode{}之中,那么我们是如何唯一标识文件来进行增删查改操作的呢🤔??
要回答这个问题,首先要对目录 有一个清晰的认知!!
Linux下一切皆文件,目录也是文件。因此,目录也需要占用一个inode!!目录的属性自不用说,我们见多了,那目录的内容呢??我们似乎从来没讲过也从来没见过目录的内容,这里不多废话,直接输出结论:目录保存的是当前目录下的文件的文件名与inode编号的映射表。实质上就是hash<string, int>
有了这个大前提,很多问题都能够迎刃而解了。
结论🫐:
- 在磁盘和文件系统的角度,存储目录和普通文件没有任何问题!!一切皆文件的另一角度
- 目录的读写权限的设计。具体可以前往【Linux系统】权限的概念查看。
- 同一个目录下不能够有同名文件。!避免造成映射混乱
因此,虽然我们对于文件进行增删查改操作时没有使用inode标号唯一标识,但是,我们用户通过文件名来间接地获取inode编号进行文件操作。
3.4、路径解析&路径缓存🌟
有这样一个问题:如果我当前想访问当前目录下文件,首先要做的是什么??当然是打开当前对应的目录!然后在当前目录所对应的数据块中查找对应的映射关系。
可是,目录也是一个文件呀!!如果要访问当前目录,那么就必须获得它的inode,要获得inode,就必须查看当前目录的上一级目录的映射表... ...以此类推,这不就是一个递归的过程嘛😳!!

到达根目录后,再往上就没有目录了,因此我们递归的终点就是根目录/ 。根目录在内核中可以算是说被特殊处理过,它是直接的、固定的、可以让我们直接访问到的 ,在电脑开机的时候,操作系统就知道了根目录。
因此,当我们要访问任何文件的时候,Linux内核都需要为我们像上述一样从根目录 开始进行路径解析工作。所以访问文件的时候一定一定要提供路径!!
我们日常也许会有大量地访问文件的操作,难道每一次访问都要解析到根目录下吗🤔??
这样做效率简直太低,大部分时间都在做重复的工作,并且,每一次解析都需要访问磁盘,频繁的硬件与软件IO必然导致效率降低。因此,为了避免这个问题,LinuxOS会对用户访问过的路径进行路径缓存的!!
一个用户也许一短时间内访问了特别多的文件,那么操作系统是否要管理我们所访问过的路径节点呢??
答案是必然的!!依旧先描述,再组织!
在Linux内核中,存在着struct dentry{},用于维护树形路径结构的结构体。
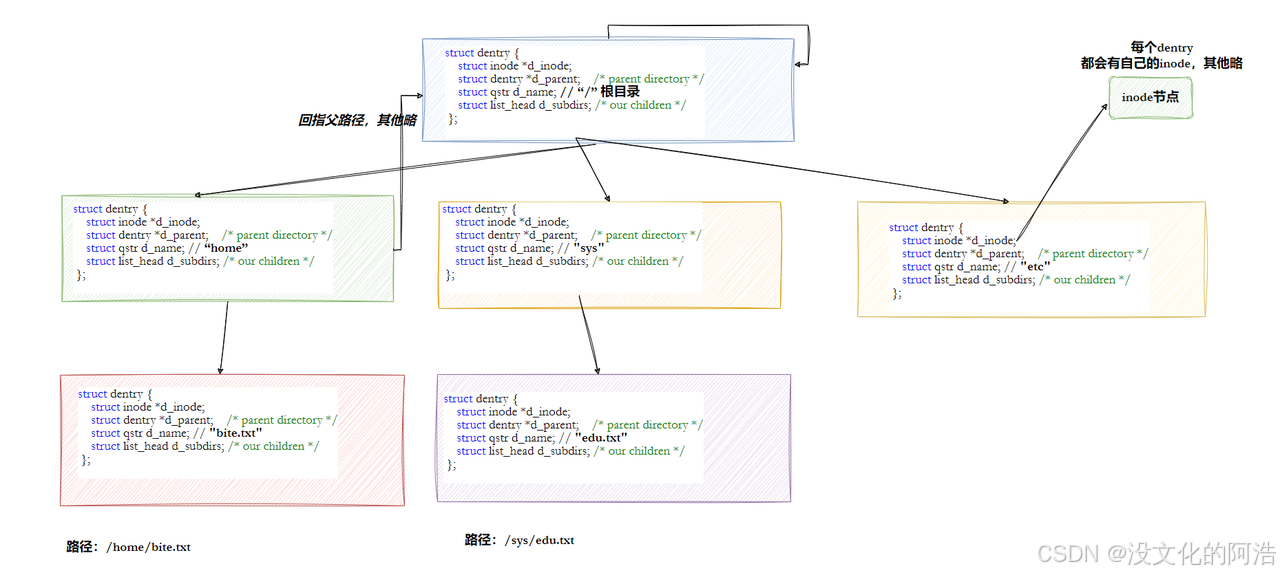
至此,我们可以来回答四个问题:
问题1️⃣:这颗多叉树会动态变化吗🤔??
- 当然,在我们访问一个新的文件(之前没访问的)时,操作系统便会在我们的多叉树中对应位置插入新的节点。同时,整个树形节点也同时会隶属于
LRU(Least Recently Used,最近最少使用)结构中,即当一个节点很少被使用的时候,就会被删除。
问题2️⃣:普通文件也具有struct dentry{}吗🤔??
- 每一个被访问的文件都需要有
struct dentry{},包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。普通文件作为叶子节点于这个树型结构中。
问题3️⃣:为什么,用find搜索的时候,第一次会比较卡顿,但是第二次就变得流畅了呢🤔??
struct dentry{}这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,首先都在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。- 当我们使用
find指令第一次查找一个文件时,也许那个文件并不在树形结构中,此时操作系统就不得不在磁盘中进行查找,因此显得比较卡顿;当我们第二次查找时,该文件所处路径已经被路径缓存了,因此很快就能够得到响应。
问题4️⃣:相对路径如何理解🤔??
- 如果当前路径
.已经存在于树形结构中,则直接以当前路径为参照点,进行查找。 - 如果当前路径
.不存在于树形结构中,操作系统则会从当前进程的PCB中获取当前路径,再从根目录开始对当前路径进行路径缓存。 - 如何从进程PCB中获取当前路径,我们在【Linux系统】进程的基本概念与操作已经讲解过。
- 进程的PCB中会保存当前文件的所处路径,即当前路径
cwd,可以通过ls指令进行查看。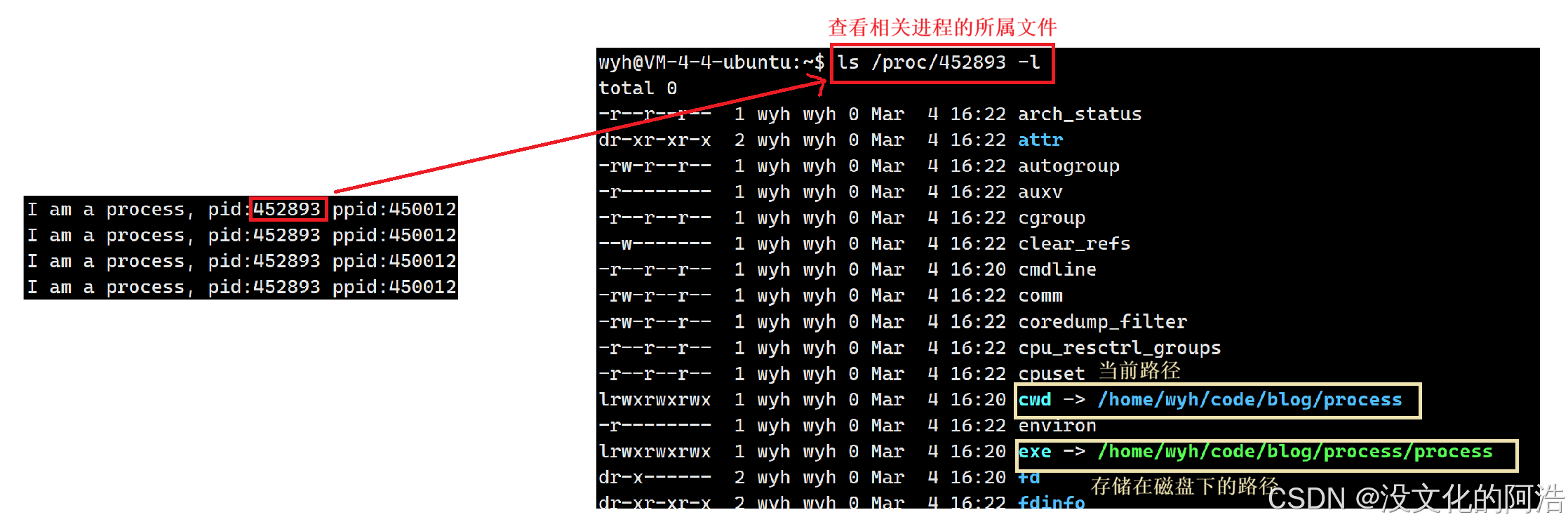
总结一个结论:访问任何文件,Linux内核都是先做路径解析和路径缓存操作的!!
既然要做路径解析和路径缓存,那么总得有人来提供路径给操作系统吧,这个操作谁来做🤔??
- 系统与用户共同构建Linux路径结构。
- 你访问文件,都是使用指令或者工具访问,本质还是进程 访问,而我们先前讲过:进程有
cwd!,我们以指令"cat ./test.c"为例,当内核进行路径解析的时候,解析到当前路径.时,会自然使用对应进程中的cwd,此时就属于系统提供路径。 - 你在程序编写时,利用open打开文件,需要提供了路径,在此则属于用户提供了路径
可是最开始的路径从哪里来呢🤔??
我们先前说过,根目录是操作系统开机自然就知道的,LinuxOS的设计师在设计文件系统的时候,就已经为我们设计好了,简单来说,这是人为规定的协议:内核挂载第一个文件系统时,就把那个目录节点称为根。
为什么要有根目录呢🤔??
根目录是文件系统层次结构的唯一起点。操作系统启动后,需要找到一个**"锚点"**来定位所有文件------没有根,每个文件都得用绝对物理地址(如磁盘第几扇区),那将极难管理。
事实上,我们新建的任何文件都是在用户或者系统指定的目录下新建的,根目录、家目录以及根目录下的缺省目录不就是系统指定的目录 嘛!!当我们在在指定目录下新建文件时,路径的概念不就天然形成了嘛!!
3.5、存储大文件问题
在正式讲解大文件问题前,我们首先得先了解一些前备知识💧:
结论1️⃣ :inode编号与块号并非是组内有效,而是在整个分区有效且唯一。这也就说明了,一个文件不能够跨分区存储。
由于是组内有效,我们便可以对inode编号和数据块号做简单的数学运算,从而快速找到他们所在的分组。
结论2️⃣ :在一个分区内部,即一个文件系统内部,inode与块数都是提前设定好的。
既然是提前设定好的,那么我们如何保障inode的数量与数据块的数量恰好呢🧐??
事实上,我们无法保证😔,磁盘无法做到100%的利用率,inode与数据块之间的比例只能够依靠经验判断。
那是否会存在 "inode table还未用完,Data Blocks就已经用完了" 的情况呢??答案是肯定的。
有了以上的预备知识,接下来,我们可以正式讲解存储大文件问题🔥 。
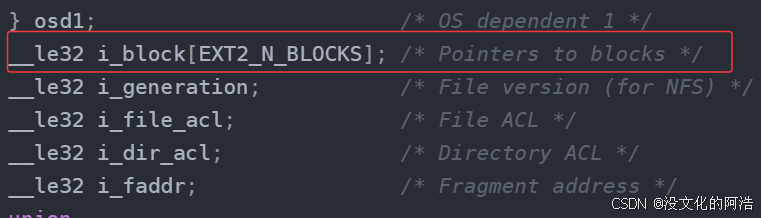
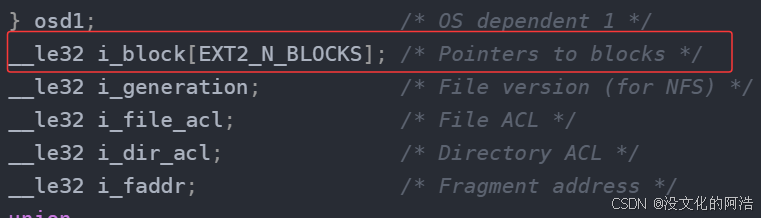
前文我们说过,每一个struct inode{}中都具有一个数组i_block[]用来关联DataBlocks中的数据块,那么,我现在告诉你,i_block[]中用于初始化数组大小的宏EXT2_N_BLOCKS其实等于15!!这就意味着,这个inode只能够关联15个数据块,即最大只能够存储60KB的内容🤯。
显然,这违背了我们的生活常识,我们手机中的照片、聊天记录都不止这么点大🙄。
我们知道每个数据块都具有自己的块号,那么这些块号算不算数据呢??当然算啦,那么既然是数据是不是就可以存储在数据块中!!也就是说,我们用一个数据块存储其他数据块的块号,这不就相当于我们的二级指针嘛😳。按照这个原理,我们便可以设计出以下的数据结构:
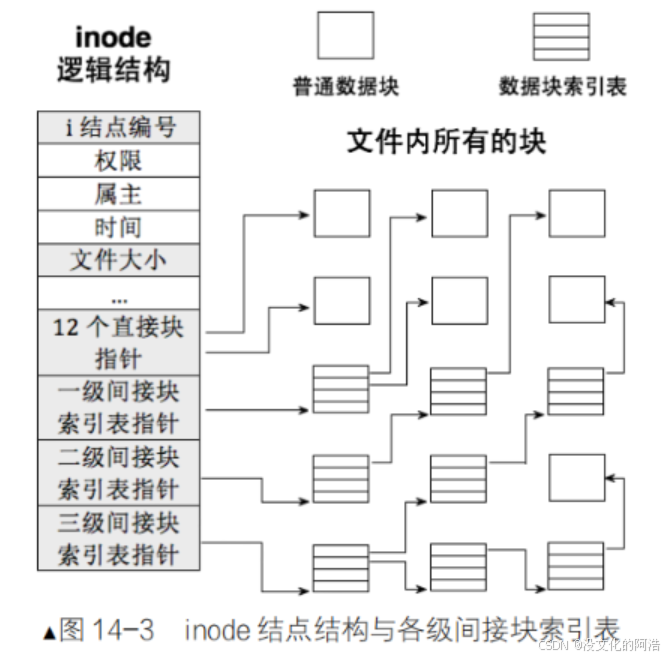
i_bock[]的前12个元素用于存放数据块的块号,第13个元素称为一级间接块索引表 ,指向一个数据块,该数据块中存放其他存储数据的数据块的地址;第14个元素称为二级间接块索引表 ,指向一个数据块,该数据块中存放其他一级间接索引表的地址;第15个元素称为三级间接块索引表,指向一个数据块,该数据块中存放其他二级间接索引表的地址。
如果一个分组不够存储一个大文件,那么我们可以存储到其他分组中。因为我们先前提过:块号是区内唯一的!
综上,我们得出一个结论:块内,不仅仅存储文件自己的数据,还可以存放自己文件所使用的块号。
3.6、挂载分区
我们知道,一块磁盘被分为许多个分区,那么我们如何知道文件处于哪一个分区呢🤔??
如果要使用磁盘,首先需要对磁盘进行分区,再进行分区格式化,分区格式化后,这个文件系统能被直接使用了吗??目前还不可以,我们需要将分区挂载到指定的目录下,然后这个分区才能够被使用!
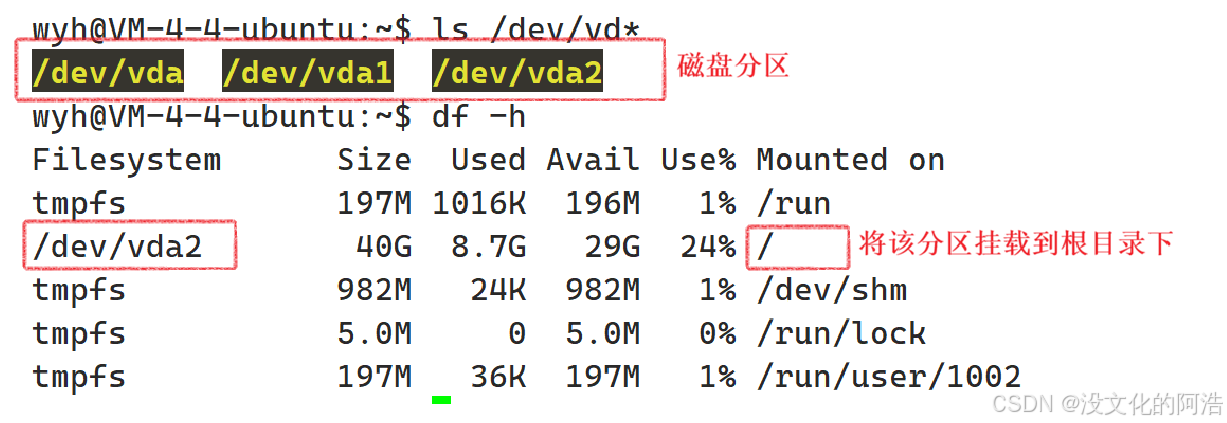
要访问文件,是必须要有路径的。通过路径我们可以查到指定目录下被挂载的分区,这样就知道文件存放于哪一个分区里了。
三、软硬链接
3.1、硬链接
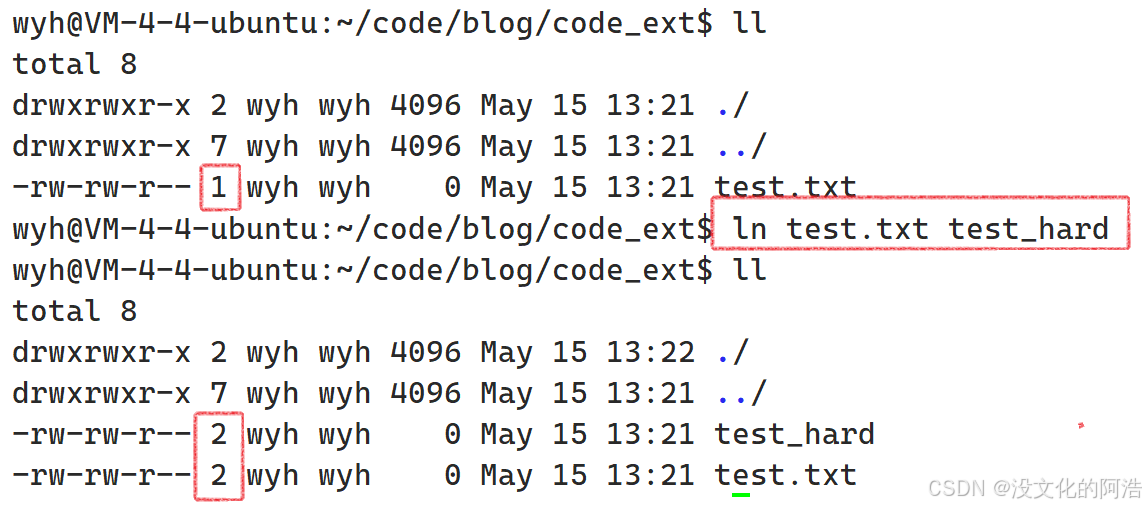
我们看到,真正找到磁盘上文件的并不是通过文件名,而是通过inode编号。事实上在LinuxOS中,可以让多个文件名对应于同一个inode编号。即通过硬链接构建出这样的效果。
指令:ln [filename1] [filename2]👉建立硬链接,将filename2链接到filename1
我们已经简单见过硬链接了,那么它存在的意义是什么呢??
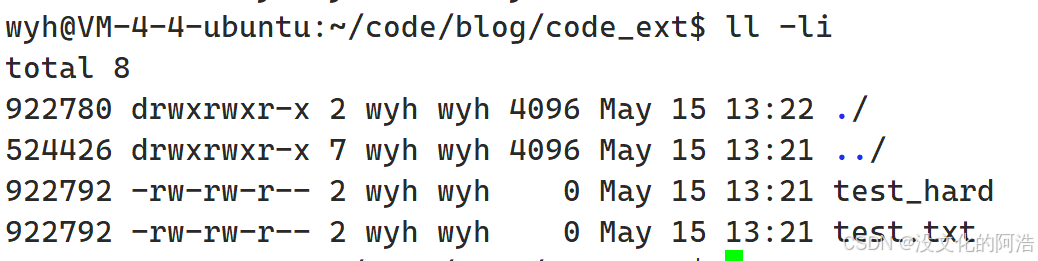
可以看到,这两个文件的inode编号一模一样,这说明这两个文件本质上就是同一个文件,即硬链接和目标文件本质上是同一个文件。
建立硬链接的本质就是在当前目录下新建一个新的字符串 和目标文件的映射关系 。在目录文件中,文件名本质上就是一个字符串!!
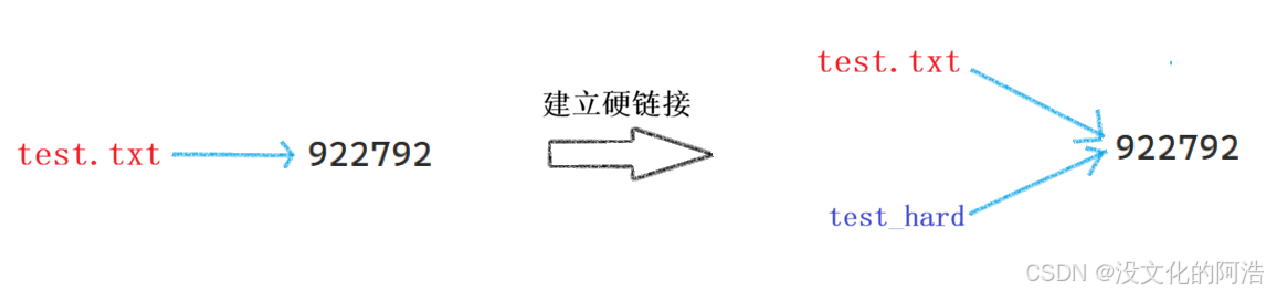
硬链接后,对应文件的硬链接数 就会++,硬链接数就是指 "指向同一个inode的文件名的数量"。下图就是struct inode{}中表示硬链接数的变量

这样的话,删除一个文件的过程则变为:
- 先删除文件名和inode的映射关系。即硬链接数--。
- 如果删除后,对应文件的inode的硬链接数由1变0,该文件对应的
inode Bitmap上的位置由1置0,表示文件删除。
由此,我们也可以看出,硬链接可以被用来实现一个轻量化的备份方案。
接下来补充回答这样两个细节:
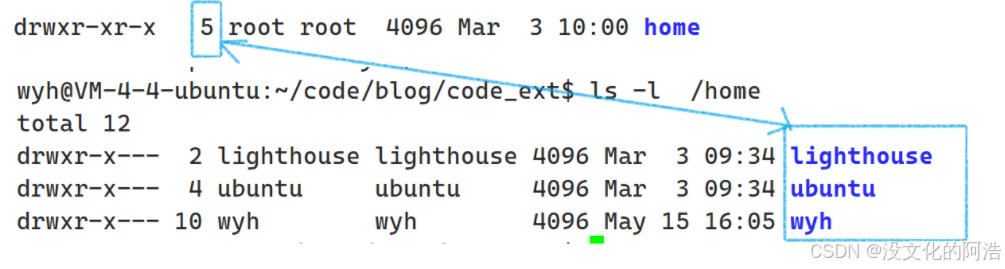
细节1️⃣:为什么创建一个目录时,目录的硬链接数初始值就是2呢🤔??
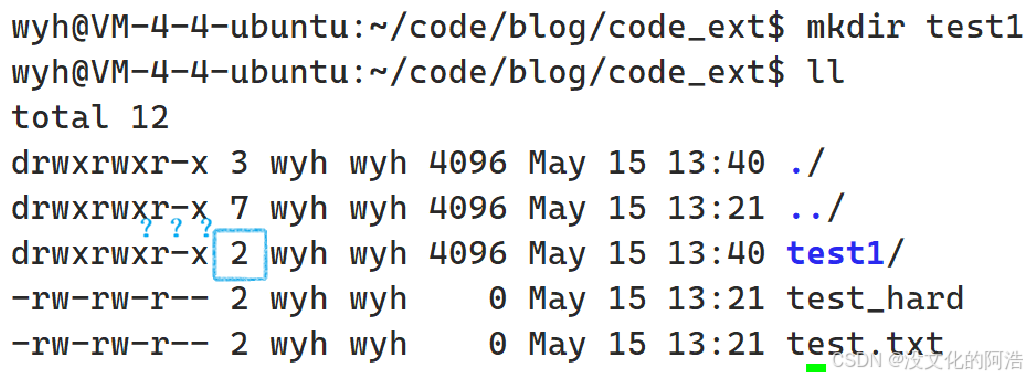
打开对应的目录,我们可以发现,初始创建的目录都会包含以下两个文件..(上级路径)和.(当前路径),而.本质上就是一个硬链接 ,用于指向当前目录的!!此外,..的初始值为3,也是一样的道理!!
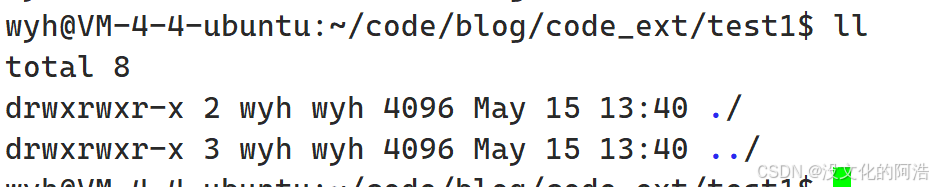
因此,如果给你一个目录的硬链接数,你能够判断当前目录下一共有多少个目录吗🤔??注意,是"目录"
当然可以,除去目录自身,以及目录下的.,即硬链接数 - 2,就是当前目录下的存在的目录的总数!!
细节2️⃣:用户不能给目录建立硬链接!!

这样做是为了防止用户造成环形路径 。
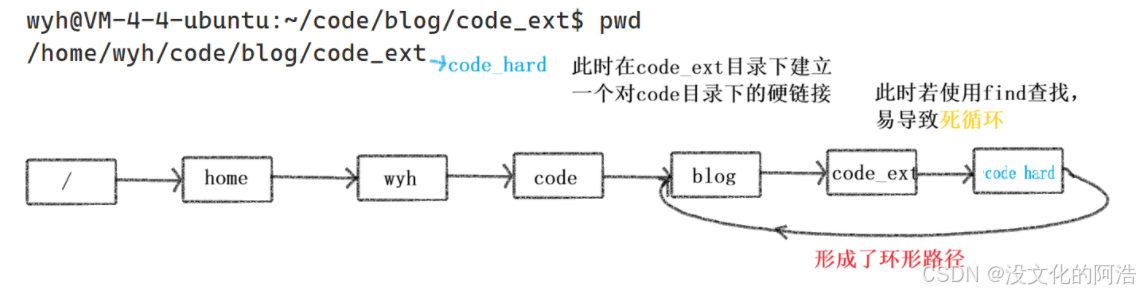
那么,有人有疑问:.和..不就是给目录建立的硬链接吗🤔??
确实,不过这两个硬链接是系统 建立的,不是用户!!而且系统必须这么干,用来表示绝对路径和相对路径。
那么,操作系统是如何来解决环形路径问题的呢??
事实上,操作系统对这两个硬链接做了特殊处理 ,当进行文件查找的时候,操作系统遇到.和..会自动忽略这两个目录。
3.2、软链接
先了解指令:ln -s [filename1] [filename2] 👉建立软链接,将filename2链接到filename1
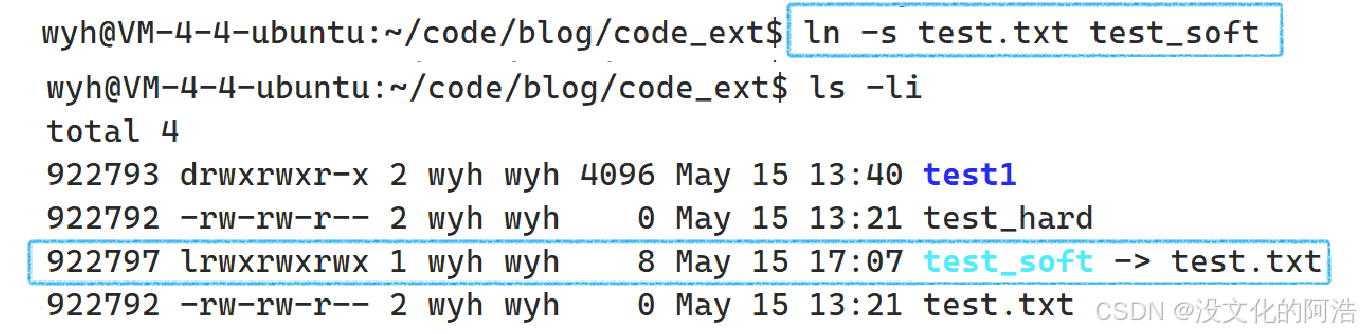
注意看!!与硬链接不同的是,软链接后的文件是一个独立的文件,也就是说它拥有自己的inode!! 此外,软链接能够链接目录,这也是它与硬链接的不同之处。
那么,软链接又有什么作用呢??
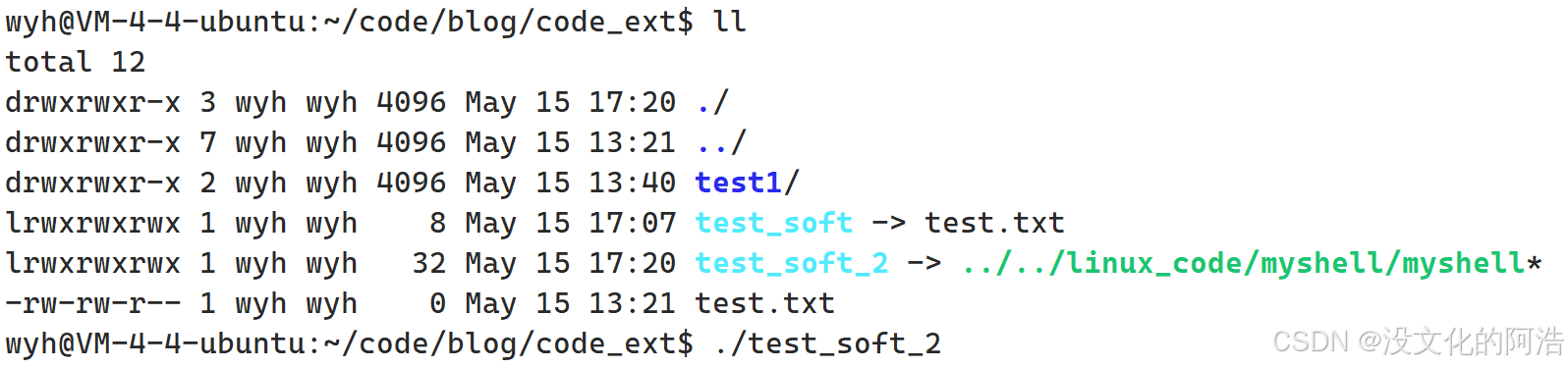
我们可以将软链接看成windows下的快捷方式 。软连接文件中保存的是指向的文件的目标路径,路径也是字符串,也就是数据,自然能够被保存。
当一个文件的路径太长,我们就可以利用软链接,在任意目录下对该文件进行软链接,这样就能够轻松打开它了🥹。例如:
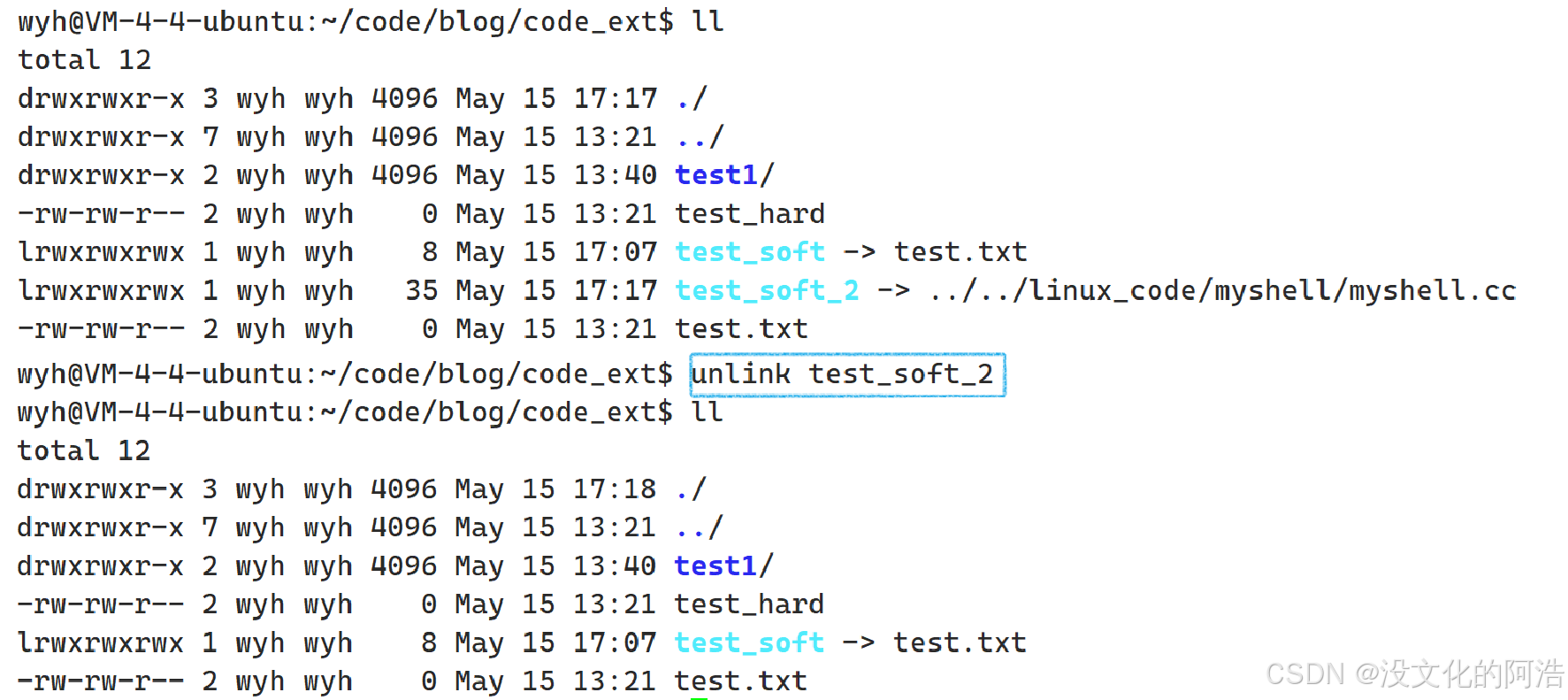
当我们要删除软连接时,除了常规的rm命令,我们也可以采用unlink命令。当然,这个命令对于硬链接也同样适用
最后,我们用一个表格简单总结以下软硬链接:
| 链接方式 | 用途 | 差异 |
|---|---|---|
| 硬链接 | 轻量级文件备份 | 硬链接只是文件名和目标inode的映射关系 |
| 软链接 | 快捷方式 | 软链接是独立文件 |
完🌅🌅🌅