前言
不管你是面试还是日常调优,只要聊到数据库性能,"索引"几乎一定是绕不开的话题。
很多小伙伴知道索引能加速查询,但问到"怎么建索引才能让查询最快"时,往往只能答出"给 where 后面的列加索引"。
其实,索引优化远没有这么简单。
今天这篇文章我就把工作中最常用的10个索引优化技巧总结出来,希望对你会有所帮助。
更多项目实战在我的技术网站:susan.net.cn/project
技巧一:选择高选择性的列作为索引
1.1 问题现象
有些小伙伴习惯性地给所有出现在 WHERE 子句中的列都加上索引,结果发现加了索引反而更慢。
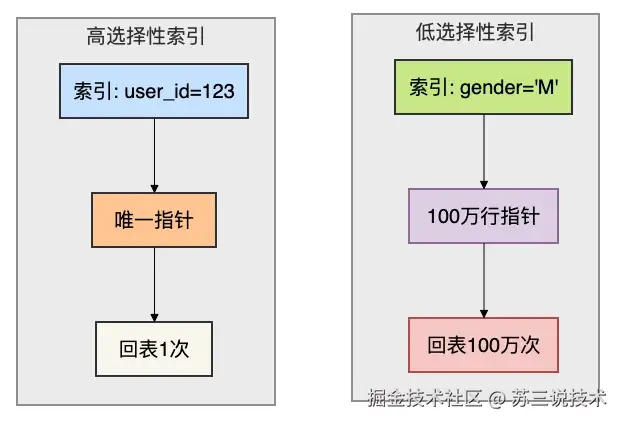
比如给"性别"列加索引,查询男性用户时,依然扫描了大量数据。
1.2 什么是选择性?
选择性 = COUNT(DISTINCT col) / COUNT(*),比值越接近 1,选择性越高。选择性高的列能快速过滤掉大量数据。
sql
-- 查看选择性
SELECT
COUNT(DISTINCT gender) / COUNT(*) AS gender_selectivity,
COUNT(DISTINCT user_id) / COUNT(*) AS user_selectivity
FROM users;- 低选择性:性别(0.5 左右),索引几乎没用。
- 高选择性:用户 ID、订单号(接近 1),索引价值巨大。
1.3 底层原理
InnoDB 的 B+Tree 索引结构,每个叶子节点存储一个键值 + 行指针。
当选择性很低时(比如性别只有男/女),索引树高度虽然低,但每个键值对应海量行,依然需要回表读取大量数据,代价甚至超过全表扫描。
优化器会选择全表扫描。
1.4 正确做法
只在高选择性列上建索引。
若业务必须过滤低选择性字段(如 status),可将其放在联合索引的末尾,作为二次筛选项。
sql
-- 不推荐
ALTER TABLE orders ADD INDEX idx_status (status);
-- 推荐:status 作为联合索引的后续列
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);1.5 适用场景与优缺点
- 优点:高选择性索引能迅速定位少量数据,极大减少 IO。
- 缺点:低选择性索引浪费空间,且写入时需要维护。
- 适用场景:用户 ID、订单号、手机号等唯一或接近唯一的列。
技巧二:联合索引遵循最左前缀法则
2.1 问题现象
创建了 INDEX(a, b, c),却写出 WHERE b = 1 AND c = 2,结果不走索引,查询极慢。
2.2 最左前缀原则
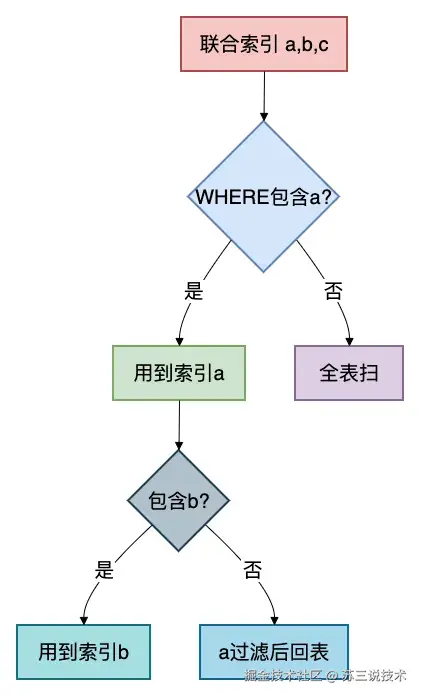
联合索引 (a, b, c) 本质上是一颗按 a 排序,a 相同再按 b 排序,b 相同再按 c 排序的 B+Tree。
查询条件必须包含最左边的列,才能用到索引。
2.3 正确与错误示例
sql
-- 正确:用到索引所有列
SELECT * FROM t WHERE a = 1 AND b = 2 AND c = 3;
-- 正确:用到 a 和 b,c 无法完全匹配,但已过滤大量数据
SELECT * FROM t WHERE a = 1 AND b = 2;
-- 正确:只用 a,依然能用索引
SELECT * FROM t WHERE a = 1;
-- 错误:跳过 a,完全无法使用索引
SELECT * FROM t WHERE b = 2 AND c = 3;
-- 错误:范围查询后的列无法使用索引(后面会讲)
SELECT * FROM t WHERE a = 1 AND b > 2 AND c = 3;
-- c 不会走索引,因为 b 是范围2.4 优化建议
- 把等值查询的列放在最左边 ,范围查询(>、<、between)的列放在右边。
- 尽量保证查询条件覆盖最左前缀,避免跳过前列。
2.5 适用场景
- 多条件组合查询频繁的表。
- 需要排序、分组、过滤的综合业务。
技巧三:尽量使用覆盖索引,避免回表
3.1 什么是回表?
InnoDB 的二级索引叶子节点存储的是主键值。
当你通过二级索引找到主键后,还需要回聚簇索引查找完整行,这个过程叫"回表"。
回表是随机 IO,极其昂贵。
3.2 覆盖索引
如果索引中已经包含了查询需要的所有列,MySQL 就不需要回表,直接从索引中获取数据,称为"覆盖索引"。
sql
-- 低效:需要回表读取 name 和 age
SELECT name, age FROM user WHERE id_card = 'xxx';
-- 仅有 idx_id_card,需回表
-- 高效:覆盖索引
ALTER TABLE user ADD INDEX idx_id_card_name_age (id_card, name, age);
SELECT name, age FROM user WHERE id_card = 'xxx';
-- 索引已包含所需列,直接返回,不回表3.3 优缺点
- 优点:大幅减少随机 IO,查询速度可提升数倍甚至数十倍。
- 缺点:索引占用空间增大,写入维护成本增加。
- 适用场景:高频查询的固定字段组合(如用户个人信息、订单简要列表)。
技巧四:避免在索引列上使用函数或表达式
4.1 问题现象
sql
-- 不走索引
SELECT * FROM orders WHERE DATE(create_time) = '2026-01-01';原因:对索引列 create_time 使用了 DATE() 函数,MySQL 无法直接使用索引。
4.2 正确写法
sql
-- 正确:使用范围查询
SELECT * FROM orders
WHERE create_time >= '2026-01-01 00:00:00'
AND create_time < '2026-01-02 00:00:00';4.3 其他常见错误
sql
-- 错误: 隐式类型转换(phone 是 VARCHAR)
SELECT * FROM user WHERE phone = 13800000000;
-- ✅ 正确:加引号
SELECT * FROM user WHERE phone = '13800000000';
-- 错误: 使用运算
SELECT * FROM product WHERE price * 0.8 > 100;
-- ✅ 正确:移运算到右侧
SELECT * FROM product WHERE price > 100 / 0.8;4.4 底层原理
B+Tree 索引按照列原始值排序存储,对列做任何函数运算都会破坏排序规则,使索引无法按范围快速定位。
4.5 适用场景
任何需要过滤、排序的查询,都应保证索引列本身不被函数包裹。
技巧五:利用索引下推减少回表
5.1 什么是索引下推(ICP)?
MySQL 5.6 引入索引条件下推(Index Condition Pushdown),允许在索引遍历过程中,先对索引中包含的列进行条件过滤,减少不必要的回表。
5.2 举例说明
sql
-- 联合索引 (name, age)
SELECT * FROM user WHERE name LIKE '张%' AND age = 25;- 无 ICP :先通过
name LIKE '张%'找到所有主键,再回表过滤age = 25。 - 有 ICP :在索引层同时判断
age = 25,只对符合两个条件的记录回表。
5.3 开启方式
ICP 默认开启,可通过 SHOW VARIABLES LIKE 'optimizer_switch' 查看。
sql
SET optimizer_switch='index_condition_pushdown=on';5.4 适用场景
- 联合索引,且 where 条件中有索引列的非前缀匹配(如
LIKE '张%')。 - 索引列有范围查询,且后面还有等值条件。
技巧六:避免使用 OR,改用 UNION 或 IN
6.1 问题现象
sql
SELECT * FROM user WHERE status = 1 OR status = 2;如果 status 选择性很低,OR 可能导致索引失效,优化器选择全表扫描。
6.2 优化方案
- 使用 IN :
WHERE status IN (1,2),通常能走索引。 - 使用 UNION:强制走索引再合并。
sql
SELECT * FROM user WHERE status = 1
UNION
SELECT * FROM user WHERE status = 2;注意:UNION 会去重,若确定无重复可用 UNION ALL,性能更好。
6.3 原理
OR 会将条件拆分成多个独立查询再合并,但优化器可能低估成本。
IN 是被优化器特别处理的等值集合,通常能利用索引。
技巧七:使用前缀索引节省空间
7.1 问题背景
对于长字符串列(如 VARCHAR(255)),整个列建索引会占用大量空间,且影响写入性能。
7.2 前缀索引
只索引列的前 N 个字符。例如邮箱前 10 个字符几乎唯一。
sql
ALTER TABLE user ADD INDEX idx_email_prefix (email(10));7.3 选择合适长度
sql
-- 计算不同前缀长度的选择性
SELECT
COUNT(DISTINCT LEFT(email, 5))/COUNT(*) AS sel5,
COUNT(DISTINCT LEFT(email, 10))/COUNT(*) AS sel10,
COUNT(DISTINCT email)/COUNT(*) AS total
FROM user;选择选择性接近 1 的最小长度。
7.4 注意
前缀索引不能用于 ORDER BY 和 GROUP BY,也无法成为覆盖索引。
技巧八:定期监控并删除未使用的索引
8.1 冗余索引举例
INDEX(a)和INDEX(a,b),前者完全多余。INDEX(a)和INDEX(b,a),对于查询WHERE a = 1两者都可用,但可保留其一。
8.2 查找未使用的索引(需开启 performance_schema)
sql
SELECT * FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE object_schema = 'your_db' AND index_name IS NOT NULL
ORDER BY count_read, count_write;COUNT_READ 长期为 0 的索引可以考虑删除。
8.3 查找冗余索引
sql
SELECT * FROM sys.schema_redundant_indexes WHERE table_schema = 'your_db';技巧九:深分页查询优化(延迟关联)
9.1 问题
LIMIT 100000, 10 需要扫描 100010 行,然后丢弃前 100000 行,效率极低。
9.2 优化方案
延迟关联:先利用覆盖索引查出主键,再回表取完整行。
sql
-- 慢
SELECT * FROM orders ORDER BY id LIMIT 100000, 10;
-- 快
SELECT * FROM orders t1
JOIN (SELECT id FROM orders ORDER BY id LIMIT 100000, 10) t2
ON t1.id = t2.id;游标分页:适合数据只增不减的场景,记住上一页最后一条 ID。
sql
SELECT * FROM orders WHERE id > last_id ORDER BY id LIMIT 10;技巧十:定期分析表,更新统计信息
10.1 为什么需要?
优化器根据统计信息选择索引。若统计信息陈旧,可能选错索引。
10.2 手动更新
sql
ANALYZE TABLE orders;OPTIMIZE TABLE 可重建表、整理碎片,适合大批量删除后执行。
sql
OPTIMIZE TABLE orders;10.3 自动化
MySQL 8.0 默认开启持久化统计信息,且会在表数据变化超过 10% 时自动更新。
但仍建议在批量导入/删除后手动执行。
更多项目实战在我的技术网站:susan.net.cn/project
总结
| 技巧 | 核心要点 | 优点 | 缺点/注意 |
|---|---|---|---|
| 高选择性列 | 唯一值占比高 | 过滤快 | 状态字段慎用 |
| 最左前缀 | 联合索引从左匹配 | 命中率高 | 顺序错误失效 |
| 覆盖索引 | 索引包含查询列 | 免回表 | 占用更多空间 |
| 避免函数 | 不对索引列做运算 | 索引可用 | 写法需调整 |
| 索引下推 | 索引层先过滤 | 减少回表 | 依赖版本 |
| OR改IN/UNION | 避免OR | 可能走索引 | 看具体优化器 |
| 前缀索引 | 只索引前缀 | 节省空间 | 不能排序/覆盖 |
| 清理冗余 | 删除重复/无用索引 | 提升写入 | 定期巡检 |
| 深分页优化 | 延迟关联 | 减少扫描 | 复杂度增加 |
| 更新统计信息 | 让优化器准确 | 选对索引 | 大表避免高峰期 |
最后送大家一句话:**索引是把双刃剑,用得好是屠龙刀,用不好就是自残剑。
** 建索引之前,先用 EXPLAIN 看执行计划;
建完之后,定期通过监控系统清理无效索引。
你的数据库会感谢你的。
你在实际工作中还遇到过哪些索引相关的"坑"?欢迎评论区分享你的经历。
如果觉得有帮助,别忘了点赞、分享,让更多小伙伴看到~