
MCP 深度解析:从源码理解模型上下文协议的设计、争议与未来
AI Coding 系列第 11 篇 · 外部集成
这篇文章讲到最后只有一句话:MCP 不是"AI 的 USB 接口",它是一个把外部工具包装成 Claude 统一工具池成员的 JSON-RPC 协议。 你在后面几节遇到的每个"为什么 MCP 这样做"、"为什么社区对它又爱又恨",答案都不在 Anthropic 的市场材料里------在 services/mcp/client.ts 的 connect() 逻辑和 tools/MCPTool/MCPTool.ts 的 buildTool() 包装器里。带着这句话往下读,这篇一万多字的源码分析会变成它的验证过程。
如果你刚接触 MCP,2026 年的言论环境足够让你困惑:官方说"能用 CLI 就直接用",安全圈说协议有设计级漏洞,Perplexity 因为 token 消耗放弃 MCP,企业团队却说 MCP 是多 Agent 治理的必选项。每种声音都有道理,但拼在一起像吵架------新手很容易得出一个错误的结论:"这东西是不是快死了,我学它干嘛?"
不要焦虑。这些矛盾不是 MCP 快死了的信号,是它从"新玩具"变成"基础设施"的过程中必然经历的应力测试。 每一种批评背后都有具体的技术原因------token 为什么吃得多?漏洞出在协议哪一层?官方为什么说不一定要用?------这些问题的答案不在那些文章的标题里,在 MCP 的源码里。
这篇文章从源码层面拆解 MCP 的运行机制,让你穿透噪音,看到它到底是什么、怎么运作、什么时候该用、什么时候不该用。读完你会有一个确定的判断框架------不是"MCP 好"或"MCP 坏",而是"我的场景下用 MCP 划不划算"。
结构是先建立技术地基,再基于地基做判断。 前四节讲 MCP 怎么传、怎么跑、怎么配------你理解这些之后,第五节的安全争议和社区风暴就不再是"又一个安全漏洞新闻",而是"这个设计选择必然导致的后果"。最后三节(决策框架、失败模式、实战案例)是你在项目里做选择时可以翻阅的参考手册。
一、先建立正确的心智模型
很多人把 MCP 理解成"AI 应用的 USB 协议"------这是 Anthropic 官方的比喻。它打动人心,但不准确。
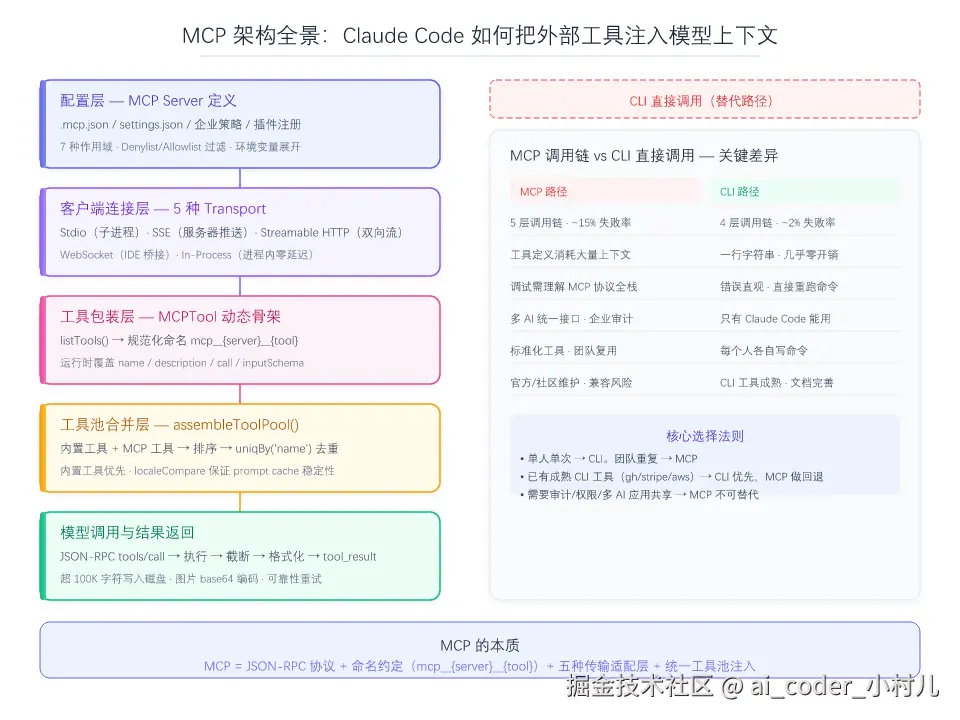
更准确的说法是:MCP 是一个基于 JSON-RPC 2.0 的客户端-服务器协议,Claude Code 作为客户端通过五种传输通道之一连接到 MCP Server,获取该 Server 提供的工具(Tools)、资源(Resources)、提示(Prompts),然后将这些工具以 mcp__{server}__{tool} 的命名格式注入到 Claude 的统一工具池中。
看一眼 client.ts 最核心的依赖导入就能验证这个模型:
📂 展开源码:MCP 客户端导入------协议的本质
typescript
// src/services/mcp/client.ts
import { Client } from '@modelcontextprotocol/sdk/client/index.js'
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js'
import {
SSEClientTransport,
} from '@modelcontextprotocol/sdk/client/sse.js'
import {
StreamableHTTPClientTransport,
} from '@modelcontextprotocol/sdk/client/streamableHttp.js'
import {
CallToolResultSchema,
ListToolsResultSchema,
ListPromptsResultSchema,
ListResourcesResultSchema,
} from '@modelcontextprotocol/sdk/types.js'关键细节:
- 所有 MCP 通信的"语言"都是 JSON-RPC------
CallToolResultSchema、ListToolsResultSchema这些 Zod Schema 定义了 MCP Server 和 Client 之间消息的格式契约。 - 四种 ClientTransport 各解决一类通信场景:子进程管道(stdio)、HTTP 流(StreamableHTTP)、服务器推送(SSE)、IDE 桥接(WebSocket)。再加上第五种 In-Process Transport(见第二节),一共五种。
- MCP Client 的职责是"翻译"------把 JSON-RPC 消息翻译成 Claude API 兼容的 tool 定义格式,再把工具调用结果翻译回模型能消费的文本块。
MCP 不是魔法,是一层薄薄的适配。它解决的问题是:"每个外部系统都有自己的 API 格式,Claude Code 能不能用统一的语言和它们对话?"------答案就是 JSON-RPC 加命名约定。
这层薄适配有一个核心张力贯穿全文:标准化的收益随复用次数增长,而中间层的成本随调用链长度增长。 MCP 的所有争议------从"该不该用"到"安全不安全"------根源都在这个张力上。前四节把这个架构拆开,你自然会看到张力从哪里来。
二、五种传输方式:从源码看各有什么取舍
MCP 协议本身只定义了 JSON-RPC 消息格式,不管消息怎么传输。Claude Code 支持五种传输方式,选择逻辑在 types.ts 的 Zod Schema 里就可以看出来。理解传输层是理解 MCP 安全争议的前提------2026 年 4 月的 OX Security 漏洞(第五节详述)就出在 Stdio 的设计上。
Stdio------最经典,也最有争议
typescript
// src/services/mcp/types.ts
export const McpStdioServerConfigSchema = lazySchema(() =>
z.object({
type: z.literal('stdio').optional(), // 可省略,向后兼容
command: z.string().min(1), // 启动命令
args: z.array(z.string()).default([]),
env: z.record(z.string(), z.string()).optional(),
}),
)Stdio 启动一个子进程,通过标准输入/输出管道传递 JSON-RPC 消息。
arduino
Claude Code → stdin → MCP Server 子进程
Claude Code ← stdout ← MCP Server 子进程
Claude Code ← stderr ← MCP Server 日志这是最古老、最简单、社区最常用的方式------约 70% 的 MCP server 配置都是 Stdio。但正是这种方式存在一个架构级隐患,详见第五节。
SSE------服务器推送
typescript
export const McpSSEServerConfigSchema = lazySchema(() =>
z.object({
type: z.literal('sse'),
url: z.string(),
headers: z.record(z.string(), z.string()).optional(),
}),
)SSE(Server-Sent Events)是 HTTP 的单向流:客户端发 HTTP 请求,服务器通过长连接持续推送事件。适合"结果可能需要等很久"的场景,但单向设计意味着客户端必须通过另一条 HTTP 连接发送请求。逐步被 Streamable HTTP 取代。
Streamable HTTP------双向流,2026 路线图主力
typescript
export const McpHTTPServerConfigSchema = lazySchema(() =>
z.object({
type: z.literal('http'),
url: z.string(),
headers: z.record(z.string(), z.string()).optional(),
oauth: McpOAuthConfigSchema().optional(),
}),
)Streamable HTTP 支持 OAuth 2.1 认证和双向流式传输,是 Anthropic 2026 路线图的重点方向。远程部署的 MCP server 首选这种传输。
WebSocket------IDE 桥接
WebSocket 用于 VS Code SDK MCP server------通过长连接把 IDE 能力(获取诊断、打开文件、终端操作)暴露给 Claude Code。支持的 TLS 客户端证书和 HTTP 代理配置让它适合企业内网环境。
In-Process------零延迟的进程内通信
这是最值得细品的传输方式:
📂 展开源码:InProcessTransport 完整实现(57行)
typescript
// src/services/mcp/InProcessTransport.ts
class InProcessTransport implements Transport {
private peer: InProcessTransport | undefined
private closed = false
onclose?: () => void
onerror?: (error: Error) => void
onmessage?: (message: JSONRPCMessage) => void
_setPeer(peer: InProcessTransport): void {
this.peer = peer
}
async start(): Promise<void> {}
async send(message: JSONRPCMessage): Promise<void> {
if (this.closed) {
throw new Error('Transport is closed')
}
// 异步投递到对端,避免同步请求/响应导致的栈溢出
queueMicrotask(() => {
this.peer?.onmessage?.(message)
})
}
async close(): Promise<void> {
if (this.closed) return
this.closed = true
this.onclose?.()
if (this.peer && !this.peer.closed) {
this.peer.closed = true
this.peer.onclose?.()
}
}
}
export function createLinkedTransportPair(): [Transport, Transport] {
const a = new InProcessTransport()
const b = new InProcessTransport()
a._setPeer(b)
b._setPeer(a)
return [a, b]
}createLinkedTransportPair() 创建一对互相连接的内存传输通道------A 的 send() 投递到 B 的 onmessage,反之亦然。零网络开销,零序列化延迟,零进程启动时间。
queueMicrotask 的选择很精妙。如果 send() 直接同步调用 peer.onmessage(),而 onmessage 的回调里又立即 send() 响应------这会形成同步递归,栈溢出。queueMicrotask 把每次投递放到下一个微任务队列里打断了调用链。为什么不是 setTimeout(fn, 0)?微任务在事件循环的同一次迭代中执行,延迟远小于宏任务。
| 传输方式 | 延迟 | 适用场景 | 安全风险 |
|---|---|---|---|
| Stdio | 低(进程启动有开销) | 本地 MCP server | 命令注入面(第五节) |
| SSE | 中 | 远程单向流(逐步淘汰) | HTTP 劫持 |
| Streamable HTTP | 中 | 远程双向流 + OAuth 2.1 | 依赖 TLS 配置 |
| WebSocket | 低 | IDE 桥接、企业内网 | 长连接劫持 |
| In-Process | 零 | SDK 嵌入、插件内嵌 | 无,不跨进程 |

三、MCP 工具的完整生命周期:从 .mcp.json 到模型调用结果
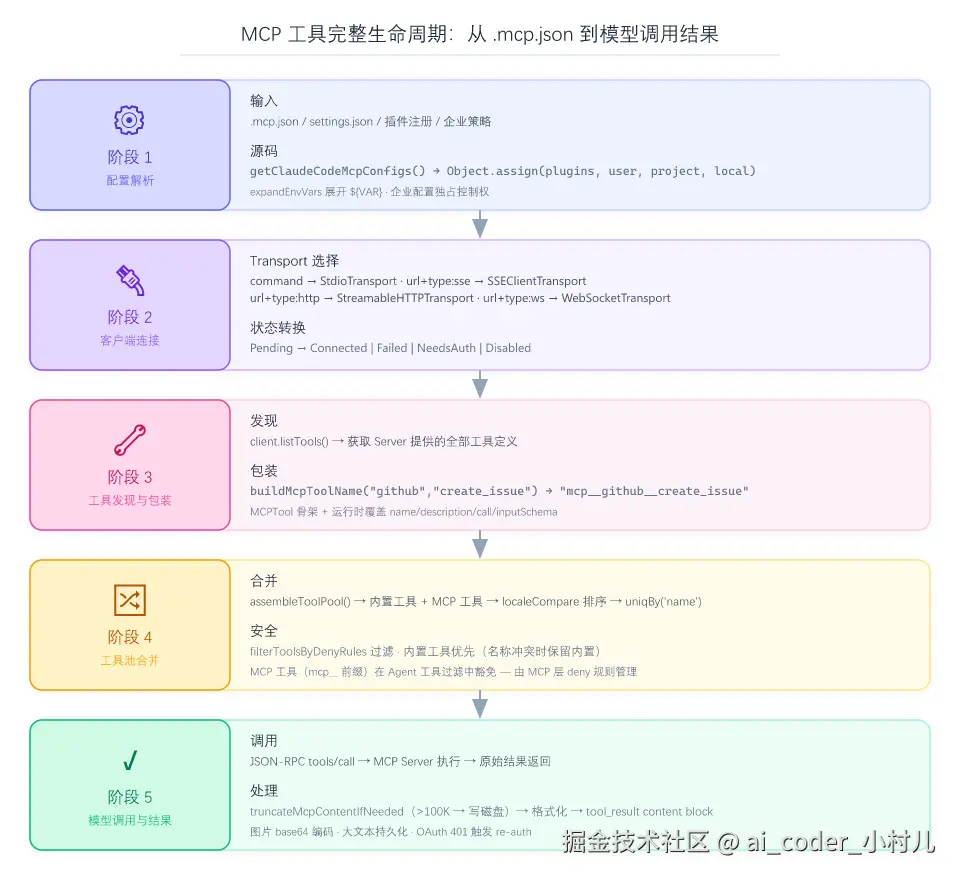
一个 MCP 工具从你在 .mcp.json 里写下一行配置,到 Claude 模型实际调用它,中间经历了五个阶段。每个阶段都有对应的源码锚点。
配置解析 → 客户端连接 → 工具发现与包装 → 工具池合并 → 模型调用与结果返回阶段 1:配置解析
typescript
// src/services/mcp/config.ts
export async function getClaudeCodeMcpConfigs(): Promise<{
servers: Record<string, ScopedMcpServerConfig>
}> {
// 企业配置独占检查
if (doesEnterpriseMcpConfigExist()) {
return { servers: filtered, errors: [] }
}
// 按优先级合并:插件 < 用户 < 项目 < 本地
const configs = Object.assign(
{},
dedupedPluginServers,
userServers,
approvedProjectServers,
localServers,
)
}七种配置作用域的完整说明见第四节。
阶段 2:客户端连接
配置文件里的 command/url 被翻译成对应的 Transport 实例。Stdio 启动子进程,HTTP 发起连接请求,In-Process 创建配对的传输通道。连接后,MCP Client 和 Server 完成 JSON-RPC 握手------Client 发送 initialize 请求,Server 返回能力和协议版本。
连接状态有五种:Pending → Connected → Failed → NeedsAuth → Disabled。状态转换由 JSON-RPC 的响应码和异常驱动,MCPConnectionManager(React Context)在 UI 层暴露 reconnectMcpServer 和 toggleMcpServer 给 /mcp 命令和设置面板。
阶段 3:工具发现与包装
连接成功后,Client 调用 listTools() 获取 Server 提供的工具列表:
typescript
// 连接后立即列出工具
const toolsResult: ListToolsResult = await client.listTools()每个工具的原始名称(如 create_issue)被规范化为 mcp__github__create_issue:
typescript
// src/services/mcp/mcpStringUtils.ts
export function buildMcpToolName(serverName: string, toolName: string): string这个 mcp__ 前缀不是装饰------它让 MCP 工具和内置工具在同一个命名空间里不冲突,也让权限过滤规则能一刀切地识别所有 MCP 工具。
然后,每个 MCP 工具被包装成 MCPTool 实例:
typescript
// src/tools/MCPTool/MCPTool.ts
export const MCPTool = buildTool({
isMcp: true,
name: 'mcp', // 运行时动态覆盖为真实工具名
maxResultSizeChars: 100_000,
// description(), prompt(), call(), userFacingName() 都在 mcpClient.ts 中运行时覆盖
})name、description、prompt、call、userFacingName 这五个属性全部标了 Override in mcpClient.ts。MCPTool 本身只是一个"骨架"------真正的内容(工具描述、输入 JSON Schema、实际调用逻辑)由 mcpClient.ts 在连接后动态注入。这不是设计缺陷,是 MCP 的"动态发现"特征决定的:连接前你不知道一个 MCP server 提供了哪些工具,所以只能用骨架占位,连接后再填肉。
阶段 4:工具池合并
typescript
// src/tools.ts
export function assembleToolPool(
permissionContext: ToolPermissionContext,
mcpTools: Tools,
): Tools {
const builtInTools = getTools(permissionContext)
const allowedMcpTools = filterToolsByDenyRules(mcpTools, permissionContext)
// 排序保证 prompt cache 稳定性
const byName = (a: Tool, b: Tool) => a.name.localeCompare(b.name)
return uniqBy(
[...builtInTools].sort(byName).concat(allowedMcpTools.sort(byName)),
'name',
)
}内置工具和 MCP 工具统一排序、去重后合并。名称冲突时 uniqBy 保留先出现的------内置工具优先(因为它在数组前面)。排序用 localeCompare 而非简单的字符比较,保证了工具列表的可预测顺序,进而保证了 prompt cache 的稳定性。
阶段 5:模型调用与结果返回
当 Claude 决定调用 mcp__github__create_issue 时,Claude Code 解析出 server 名和工具名,通过 MCP Client 发送 JSON-RPC tools/call 请求,Server 执行后返回结果。结果经过截断(默认 100,000 字符上限)、格式化、持久化(超大结果写入磁盘而非塞进上下文),最终以 tool_result 类型的 content block 返回给模型。
📂 展开源码:MCP 工具结果截断逻辑
typescript
// src/utils/mcpValidation.ts
export function truncateMcpContentIfNeeded(
content: MCPToolResult,
maxSizeChars: number,
): MCPToolResult {
// 超过上限的内容写入磁盘,返回文件路径而非内容
if (mcpContentNeedsTruncation(content, maxSizeChars)) {
return persistBinaryContent(content)
}
return content
}这个设计避免了 MCP 工具返回 500KB 的数据库查询结果塞满 Claude 的上下文窗口。
Agent 专属 MCP:子代理为什么需要自己的 MCP Server
生命周期章节里有一个容易被忽略但非常关键的源码细节------Sub-agent 可以有自己的 MCP server,独立于父 Agent:
📂 展开源码:Agent frontmatter 中的 mcpServers 字段
typescript
// src/tools/AgentTool/loadAgentsDir.ts
const AgentMcpServerSpecSchema = lazySchema(() =>
z.union([
z.string(), // 按名称引用已有 MCP server
z.record(z.string(), McpServerConfigSchema()), // 内联定义新 MCP server
]),
)
// 在 Agent 定义中
mcpServers: z.array(AgentMcpServerSpecSchema()).optional(),一个 Agent 的 frontmatter 可以写:
yaml
mcpServers:
- github # 引用父 Agent 已有的 server(共享连接)
- my-custom-db: # 内联定义 Agent 专属 server(新建连接,Agent 结束自动清理)
command: node
args: [".mcp/db-server.js"]initializeAgentMcpServers() 在 Agent 启动时执行------如果 agent 只引用已有 server 名称,就复用父 Agent 的连接;如果是内联定义,就创建新连接并在 Agent 清理阶段自动关闭。这个设计让"代码审查 Agent 能访问 GitHub"、"数据分析 Agent 能访问数据库"各自有各自的工具集,互不污染。
四、MCP 配置体系:七种作用域,谁覆盖谁
Claude Code 的 MCP 配置不是只有一个 .mcp.json 文件那么简单。源码定义了七种配置作用域:
typescript
// src/services/mcp/types.ts
export const ConfigScopeSchema = lazySchema(() =>
z.enum([
'local', // .claude/settings.local.json(不入 git)
'user', // ~/.claude.json(全局用户配置)
'project', // .mcp.json(项目共享,入 git)
'dynamic', // 运行时动态注入
'enterprise', // 企业管理策略(独占控制权)
'claudeai', // Claude.ai 连接器
'managed', // 托管配置
]),
)优先级:插件 < 用户 < 项目 < 本地 < 企业独占
Object.assign({}, plugins, user, project, local) 这条链中,后写入覆盖先写入。但企业配置是特例:如果存在企业 MCP 配置文件(managed-mcp.json),所有其他来源直接被忽略------不是优先级最高,而是独占控制权。这个设计背后的意图是:企业 IT 管理员需要一个"锁死"机制,阻止员工绕过公司安全策略自行添加 MCP server。
Denylist/Allowlist:双重过滤
配置加载后,还要经过安全策略过滤:
- Denylist(黑名单)优先检查:被禁用的服务器直接拒绝连接
- Allowlist(白名单)二次检查:如果有白名单,只允许名单内的服务器连接
三种匹配维度:按服务器名称、按命令(['npx', '@scope/server-name'])、按 URL 模式(https://*.company.com/* 支持通配符)。urlPatternToRegex 函数把通配符 * 翻译成正则 .*,既支持精确匹配也支持域名级控制。
去重机制
同一个 MCP server 可能出现在多个配置来源中(插件装了,用户又手动配了)。去重通过"服务器指纹"实现:
typescript
// stdio 类型:命令数组的 JSON 序列化
`stdio:${jsonStringify(cmd)}`
// 远程类型:URL(CCR 代理 URL 先解包再指纹计算)
`url:${unwrapCcrProxyUrl(url)}`
// SDK 类型:无指纹(不参与去重)规则:手动配置 > 插件配置;先注册 > 后注册;启用的 > 禁用的。CCR 代理 URL 需要先"解包"(unwrapCcrProxyUrl)再计算指纹------否则同一个远程 server 经过代理和直连的指纹不同,去重失效。
五、安全模型与 2026 社区风暴:一个设计选择引发的连锁反应
这一节是全文最长的一节,因为它把安全架构、漏洞披露、社区分裂三条线合成一个叙事:MCP 的安全设计意图是什么 → 这个设计怎么被现实攻破 → 各方怎么反应。 这篇不是安全新闻综述------每条分析都对应前面四节的技术地基。
五层安全控制的意图
从源码看,MCP 有五层安全控制:
- 配置级------哪些服务器被允许存在(denylist/allowlist)
- 工具级 ------
filterToolsByDenyRules按工具名禁止敏感操作 - 执行级 ------
canUseTool运行时检查权限 - 通道级 ------
channelPermissions控制服务器的通道访问 - OAuth 级 ------
services/mcp/auth.ts处理远程服务器的认证
OAuth 认证流程是一条完整的序列:连接请求 → 服务器返回 401 → Claude Code 发起 OAuth 流程 → 获取令牌 → 带令牌重连。
一个微妙的豁免:MCP 工具在 Agent 过滤中被放行
📂 展开源码:filterToolsForAgent 中的 MCP 工具豁免
typescript
// src/tools/AgentTool/agentToolUtils.ts
export function filterToolsForAgent({ tools, isBuiltIn, isAsync }): Tools {
return tools.filter(tool => {
// MCP 工具(mcp__ 前缀)不受工具禁用列表限制------始终可用
if (tool.name.startsWith('mcp__')) return true
if (ALL_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false
if (!isBuiltIn && CUSTOM_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false
if (isAsync && !ASYNC_AGENT_ALLOWED_TOOLS.has(tool.name)) return false
return true
})
}MCP 工具(mcp__ 前缀)被豁免 于所有内置工具禁用规则。即使你配置了 disallowedTools: [Bash, Write],MCP server 提供的工具依然可以通过。这不是漏洞------这是设计选择:MCP server 的权限应该由 MCP 层的 deny 规则管理,不走内置工具过滤通道。
但它留下了隐患:如果你配置了一个社区 MCP server 但没有在 MCP 层额外设置 deny 规则,这个 server 的所有工具相当于拥有白名单通行权。
2026 年 4 月:OX Security 的"协议级"攻击披露
2026 年 4 月中旬,安全公司 OX Security 披露了一个系统性漏洞,影响所有官方 MCP SDK(Python、TypeScript、Java、Rust),波及约 1.5 亿次下载量、7000+ 公开暴露的服务器实例。
漏洞的根因恰好出在第二节讲到的 Stdio 传输设计上 :命令执行在先,协议验证在后。StdioClientTransport 的构造函数启动子进程时,命令就已经在宿主系统上执行了------不管这个子进程后续是否成功完成 MCP 初始化握手。攻击者只需要在 .mcp.json 的 command 字段或 args 数组里注入恶意命令。
为什么五层安全控制全都没拦住?
因为漏洞不在任何一层"安全控制"的范围内------它发生在第零层:进程创建时。 Stdio 的 command 字段执行本质上等同于用户在终端里跑 eval(command)。之后五层安全全部正常工作------只是它们检查的是一个已经被攻破了的进程。
研究人员编目了四种利用方式:
- 未认证的 UI 注入------通过 MCP 配置面板注入恶意命令
- 安全强化绕过------利用有效的 MCP 配置绕过企业 denylist(denylist 用的是命令指纹匹配,恶意命令的指纹和合法命令可以不同)
- 零点击 prompt 注入------在 IDE 环境中通过 MCP 工具描述注入恶意指令
- 恶意市场分发------发布带有后门的 MCP server 包到 npm/PyPI
Anthropic 的回应引爆了更大争议:他们拒绝修复协议层面的根因,称这是"预期行为",将安全责任放在了 MCP server 开发者和下游用户的肩上。 OX Security 的研究人员评论道:"协议层面的一次架构变更本可以保护每一个下游项目、每一位开发者、每一位依赖 MCP 的终端用户。"这句话击中了要害------Stdio 的 command 字段可以用沙箱子进程或 OCI 容器隔离来限制攻击面,但 Anthropic 选择不作为。
到目前为止已分配 10+ 个高危/严重 CVE,其中包括 CVSS 10.0 和 9.6 评分。
所以你应该怎么做 :审查
.mcp.json中每一个command的内容------这是进入你系统的入口点。优先使用官方维护的 MCP server;对远程 HTTP MCP server 启用 OAuth 认证;在企业环境用 managed-mcp.json 锁定允许的服务器列表。
Perplexity 放弃 MCP(2026 年 3 月)
AI 搜索引擎 Perplexity 宣布放弃 MCP 集成,核心数据:MCP 工具定义消耗了 72% 的上下文窗口。 在一个 200K token 的窗口里,140K tokens 被工具描述、参数 JSON Schema、Server 元数据吃掉了,留给实际对话和推理的空间仅剩 60K。
Scalekit 的独立分析印证了这个数字:MCP 方案比 CLI 等价方案消耗 4-32 倍的 token。
这里需要联系第三节的阶段 3(工具发现与包装)来理解:MCP server 在 listTools() 时返回的每个工具定义,包含完整的 description 和 inputJSONSchema。如果 JSON Schema 嵌套很深(比如一个"创建订单"的工具需要的参数结构),仅这个工具的 token 开销就可能超过 2000 tokens。三四个功能丰富的 MCP server,轻松让工具定义成为上下文最大消费者。
这不是 MCP 协议本身有问题------这是"通用协议"的代价。CLI 命令只是一个字符串在 prompt 里,MCP 工具定义则是一套完整的形式化接口描述。形式化在"多 Agent 共享"时的收益,在"单人单次调用"时变成了纯粹的开销。
国家黑客利用 MCP 进行 AI 编排攻击(2025 年 11 月)
Anthropic 披露了一个被标记为 GTG-1002 的攻击组织,使用 Claude Code + MCP 工具对约 30 个组织实施了 AI 编排入侵。AI 自主完成了 80-90% 的战术工作------侦察、横向移动、凭证收集------人类只在 4-6 个关键决策点介入。世界经济论坛确认这是首例"生产级自主 AI 网络攻击"。
这个案例里 MCP 的角色是攻击面放大器------一个被攻破的 MCP server 不是泄露一个工具,是泄露一套完整的外部系统访问能力。如果企业配置了允许访问数据库、CI/CD 流水线、云基础设施的 MCP server,攻击者拿到一个入口就能编排所有这些系统。
三个阵营的分裂
2026 年的 MCP 社区呈现清晰的阵营分化:
- 安全研究者:"MCP 的信任模型从根本上就坏了。工具定义、API 响应、用户提示都在上下文窗口里,Agent 默认全信。补丁修不了架构问题。"
- 企业平台团队:"MCP 是必选项。没有统一的工具协议,50 个 Agent 管不动。治理、网关、审计跟踪都在路上。"
- 独立开发者 :"MCP 太重了。配置烦、调试难、token 烧得心疼。我一个人用
gh十秒钟搞定的事,MCP 要搞半小时。"
这场分裂的本质不是技术路线的分歧,而是使用场景的不重叠。MCP 的设计偏向解决企业平台团队的需求(数十个 Agent、几百个工具、需要审计和治理),独立开发者的痛苦是附带伤害。
MCP vs A2A 与路线图
Google 的 Agent-to-Agent(A2A)协议在 2026 年出现,解决的是和 MCP 不同但互补的问题:
- MCP = Agent ↔ 工具("让 Agent 能用同一个接口调不同工具")
- A2A = Agent ↔ Agent("让不同 Agent 之间能互相说话、协商、传递任务")
大多数企业未来可能需要两者共存。Anthropic 的 2026 MCP 路线图包括:OAuth 2.1 正式规范、Streamable HTTP 正式规范、工具治理(Tool Governance)API、可观测性标准。
MCP 远未死亡------但它的"青少年期"结束了。接下来几年是它证明自己是"有用的基础设施"还是"过度设计的中间层"的关键期。
六、决策框架:把前面五节的地基变成选择能力
前面五节建立了技术地基。这一节是地基的产物------你理解 MCP 怎么传、怎么跑、怎么配、怎么出事之后,"该不该用"不再是一个需要背的规则,而是从技术理解中自然得出的判断。
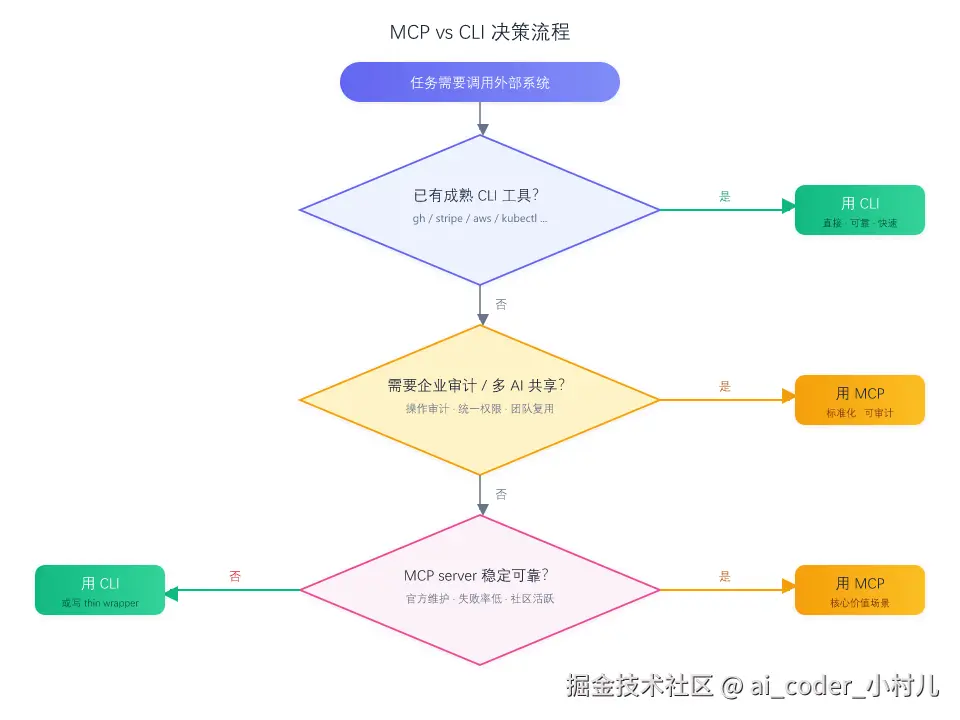
问题一:这个任务有团队级重复性吗?
这个判断直接来源于第三节的阶段 3(工具发现与包装):每个 MCP 工具的完整定义都会被注入到每次 API 请求中。如果 5 个人用同一个 MCP server,5 个人都受益于同一个标准化接口。但如果只有你一个人偶尔用一次,你为 100 个工具定义支付的 token 成本永远得不到摊薄。
MCP 的经济学是规模经济。 固定成本(配置、调试、维护、token 开销)需要足够多的调用频次和使用者来均摊。
问题二:已有成熟 CLI 工具吗?
这个判断来源于第二节的传输层分析:每多一层中间代理,就多一层的失败模式。GitHub MCP server 的工具调用失败率约 15%,而直接调 gh CLI 是约 2%。为什么?
arduino
MCP 路径(5层):
Claude Code → MCP Client → JSON-RPC → MCP Server → GitHub API → 数据库
CLI 路径(4层):
Claude Code → Shell → gh CLI → GitHub API → 数据库少一层就少一层失败概率。GitHub 有 gh、Stripe 有 stripe、AWS 有 aws、Vercel 有 vercel------这些 CLI 经过了成千上万用户的验证,错误处理完善。除非你需要多个 AI 应用共享同一套工具接口,CLI 通常更可靠。
问题三:你是否需要企业级的权限和审计?
CLI 工具没有统一的认证框架、操作审计、权限模型。MCP server 层可以统一管理这些。第四节讲的七种配置作用域、Denylist/Allowlist 双重过滤、OAuth 认证------这些东西只有在"多人多 Agent 多系统"的规模下才有存在意义。
快速决策速查
| 场景 | 推荐方案 | 对应的技术原因 |
|---|---|---|
| 个人偶尔调用 GitHub API | gh CLI |
4 层调用链 vs 5 层,失败率低 |
| 团队共享内部数据库查询 | MCP server | 工具定义一次性注入,全员复用 |
| CI/CD 流水线自动化 | CLI | MCP server 运行状态不可控 |
| 多 AI 应用共享工具 | MCP server | MCP 的核心价值场景 |
| 安全敏感操作 | 两者配合 | CLI 执行 + MCP 记录 + 人工审批 |
核心规则:如果你要在 prompt 里反复解释同一个工具的用法,MCP 值得考虑。如果工具用法一目了然,CLI 更快。
七、常见失败模式与源码级诊断
参照 Sub-agents 篇的写法,每个失败模式不仅有技术原因分析,还有"心理根因"------读者为什么会掉进这个坑。因为源码里它是机械规则,不会"觉得该总结"、"理解权限为什么被拒"。
失败模式 1:MCP server 突然不可用,AI 反复重试
症状:Claude Code 反复尝试调用同一个 MCP 工具,每次都失败,但你看到错误信息后不知道问题出在哪。
心理根因:你以为"工具在列表里 = 工具能用"。这个心理预判来自于日常使用 UI 的习惯------APP 里的按钮点了没反应,你会觉得是 APP 卡了,不会觉得是按钮背后的服务器挂了你没收到通知。
源码级原因 :MCP Client 的连接状态有五种。当 Server 从 Connected 转入 Failed 时,工具依然在 assembleToolPool() 合并后的统一工具池里。Claude 基于工具池做决策,不知道某个工具的背后连接已经断了------它收到的工具列表中 mcp__server__tool 看起来和其他工具一模一样,没有"健康状态"标注。
解决方案:在 prompt 里建立明确的回退规则(见第八节案例 2)。
失败模式 2:MCP 工具定义占用过多上下文
症状:启用了三四个 MCP server 后,Claude Code 的"变笨"现象明显------回答质量下降,容易忘记你之前说过的话。
心理根因:你以为"多装几个 MCP server = 多几个能力",但没意识到每个能力都会静态占用 token 配额。这是典型的"附加功能"思维------在传统软件里,装 10 个插件对系统性能的影响通常很小。但在 LLM 上下文里,每增加一个工具定义就是直接从推理空间里扣减 token 预算。
源码级原因:每个 MCP server 的工具定义(名称 + 描述 + 参数 JSON Schema)都会在每次 LLM API 请求中发送------不管这个工具本次对话是否真的会被用到。这是第三节阶段 3 的"动态发现"机制的代价:MCP server 汇报的所有工具全量注入,Claude Code 不做按需裁剪。
解决方案 :按需启用/禁用 MCP server。/mcp disable server-name 不删除配置,只是断开连接。任务需要时再 enable。
失败模式 3:假设 MCP 工具的行为和文档描述一致
症状:你配置了一个社区 MCP server,文档说它支持某功能,但实际调用时总是出错。
心理根因:你把 MCP server 的工具描述当成了 API 文档里的"契约"------以为别人写的就是对的。在传统 REST API 开发中,OpenAPI/Swagger 文档通常是从代码生成或经过严格测试的。而 MCP 的工具描述是 MCP server 代码里的字符串,Claude Code 不验证它和实际实现的一致性。
源码级原因 :MCP 的工具描述(description、inputJSONSchema)是 MCP server 自己声明的,Claude Code 无条件信任。没有"工具描述的验证"机制------如果一个 MCP server 声称它的 create_issue 接受 assignee 参数但实际不支持,Claude 会在调用时才发现。MCPTool 的 buildTool({...}) 骨架不做任何服务端校验。
解决方案 :新的 MCP server 先用只读工具测试(list、get、search),确认稳定性后再用写操作。如果行为与描述不符,用 CLAUDE.md 中的说明覆盖 Claude 的默认理解。
八、实战案例
案例 1:团队内部"活文档"MCP server
场景:团队维护微服务集群,15 个服务、3 个数据库、一堆内部 API。新人入职要读几百页 Wiki。
方案 :写一个内部 MCP server,把常用操作封装成 query_users、get_order_status、check_deployment 等工具。工具描述就是活的文档------新人 git clone 后自动能用,不用读 Confluence。
json
// .mcp.json(项目级别,入 git)
{
"mcpServers": {
"internal-platform": {
"command": "node",
"args": [".mcp/internal-server.js"],
"env": {
"API_KEY": "${INTERNAL_API_KEY}"
}
}
}
}MCP server 的 listTools() 返回示例:
json
{
"tools": [
{
"name": "query_users",
"description": "查询用户表。支持按部门、角色、活跃状态筛选。返回 JSON 数组,最多 500 条。",
"inputSchema": {
"type": "object",
"properties": {
"department": { "type": "string", "description": "部门名,精确匹配" },
"role": { "type": "string", "description": "角色:admin / developer / viewer" },
"is_active": { "type": "boolean" }
}
}
}
]
}注意这里的关键设计:工具描述直接写明了"最多 500 条"------Claude 知道结果不会撑爆上下文,用户不用额外说明。参数名和描述就是 API 文档,不需要另一套 Confluence 页面。
案例 2:MCP 失败时的 CLI 回退设计
场景:你的核心工作流依赖 GitHub MCP server 管理 Issue。某天 MCP server 挂了怎么办?
方案:在 CLAUDE.md 里写一个确定性的回退规则,不给 Claude 纠结的空间:
markdown
## GitHub 操作回退策略
使用 GitHub MCP (`mcp__github__*`) 进行 Issue 操作。
规则:
1. MCP 调用优先
2. 如果 MCP 调用连续失败 2 次 → 立即回退到 gh CLI,不尝试第三次
3. 回退后使用以下命令:
- 列 Issue:gh issue list --state all --json title,body,labels --limit 100
- 创建 Issue:gh issue create --title "..." --body "..."
- 查看 Issue:gh issue view <number>
4. 回退时在回复中说"已从 MCP 回退到 gh CLI"这不是让 Claude 在 MCP 和 CLI 之间"选择"------是给它一个确定的决策规则。失败两次就切,不纠结。这个设计的来源是第七节的失败模式 1(工具在池里但连接断了)。
案例 3:Stripe 集成------MCP 的 100 个工具 vs CLI 的 3 个
场景:你经常需要让 Claude Code 查询 Stripe 交易数据。
方案 A(MCP):用 Stripe 官方 MCP server。官方维护、稳定性好。但 Stripe API 有 100+ 个端点,MCP server 的工具集也庞大------Claude 每次请求都要消耗 token 去理解 80 个你从来不用的工具。按第三节的 token 开销逻辑,100 个 Stripe 工具的定义可能吃掉 15-20K tokens。
方案 B(CLI + 薄包装):
bash
#!/bin/bash
# stripe-query.sh ------ 只暴露你真正需要的 3 个操作
case $1 in
transactions) stripe transactions list --limit ${2:-10} --json | jq '.data[] | {id, amount, status}' ;;
customer) stripe customers retrieve $2 --json | jq '{id, email, balance}' ;;
invoice) stripe invoices list --customer $2 --limit ${3:-10} --json | jq '.data[] | {id, amount_due, status}' ;;
esac对比:
| 维度 | 方案 A(MCP) | 方案 B(CLI 薄包装) |
|---|---|---|
| 工具定义 token | ~15K(100 个工具) | ~200(3 行用法说明) |
| 失败调试 | 需理解 MCP 协议全栈 | 直接重跑脚本看输出 |
| Stripe API 变更 | 等 MCP server 更新 | 改一行 jq 过滤器 |
| 多 AI 复用 | 可以 | 不可以(只有 Claude Code 能用) |
| 适合规模 | 团队 | 个人/小团队 |
对个人使用,方案 B 更实际。但如果团队有 3 个工程师都在用 Claude Code 调 Stripe,方案 A 的 15K token 开销被 3 人分摊,标准化收益开始显现。选择取决于规模------又一次回到第六节问题一的逻辑。
案例 4:给 Sub-agent 配专属 MCP------避免权限泄露
场景 :你有一个"数据库查询 Agent"和一个"代码审查 Agent"。数据库 Agent 应该能用 mcp__postgres__*,代码审查 Agent 不应该。
方案 :在 .claude/agents/ 的两个 Agent 定义中,分别配各自的 mcpServers:
yaml
# .claude/agents/db-query.md
---
name: db-query
description: 只读数据库查询 Agent
tools: [Read, Grep, Glob]
mcpServers:
- postgres-readonly
---
# .claude/agents/code-review.md
---
name: code-review
description: 代码审查 Agent,不需要数据库访问
tools: [Read, Grep, Glob]
# 没有 mcpServers 字段 ------ 继承父 Agent 的 MCP 连接但不增加新的db-query Agent 启动时,initializeAgentMcpServers() 会连接 postgres-readonly;code-review Agent 不配 mcpServers,只能访问父 Agent 已有的 MCP 连接。数据库工具对审查 Agent 完全不可见。
本篇实践任务
任务一:审计你当前的 MCP 配置
检查 ~/.claude.json 和项目的 .mcp.json,列出你启用了哪些 MCP server。逐一评估:这个 server 的 command/url 是什么?真的常用吗?有没有 CLI 替代方案?根据评估,禁用不必要的 server。
任务二:写一个 MCP 回退策略
在 CLAUDE.md 里为你最依赖的 MCP server 写一段回退规则。格式参考第八节案例 2:明确触发回退的条件(连续失败 N 次)、回退到的 CLI 命令、回退后要不要汇报。
任务三:读一个 MCP server 的入口文件
在 npm 上找一个你正在用或想用的 MCP server,花 30 分钟读它的入口文件。关注:它暴露了哪些工具?工具描述写得清不清楚?inputSchema 是否准确?有没有把用户输入直接拼接到 shell 命令里?
下篇预告
第 13 篇:内置工具深度解析------Claude Code 的 "手" 是怎么设计的
MCP 讲的是"外部工具怎么接入 Claude Code 的统一工具池"。但工具池的另一半------Bash、Read、Write、Edit、Glob、Grep、Agent(Sub-agent)、Task、Skill 这十几个内置工具------各有自己的设计取舍:Bash 的沙箱策略、Edit 的精确替换 vs Write 的全量覆盖、Agent 工具的上下文 fork 机制。下一篇从源码层面对比每个内置工具的设计决策,以及它们和 MCP 工具的镜像关系------一个是"外部统一接入",一个是"内部各自分工"。
AI Coding 系列持续更新。MCP 不是银弹,也不是废铁------它是一个有明确边界和具体取舍的工程协议。理解它的传输、生命周期、配置和安全模型,你就能不被人云亦云牵着走。