本篇目标:装好 Ollama,跑起第一个模型,知道基本操作,遇到报错能自己解决
Ollama 是什么?
一句话:用一行命令跑起大模型,不需要懂 Docker、不需要配环境变量、不需要折腾 CUDA。
Ollama 的设计哲学是「能多简单就多简单」------你不用关心模型文件存在哪、量化参数怎么配、GPU 怎么调度,它全帮你搞定。
适用场景:
- 本地开发调试
- 多模型快速切换研究
- 个人日常使用(本地 AI 助手)
- API 服务(中小并发)
不适用场景:
- 需要同时服务几十上百个并发请求 → vLLM
- 完全没有显卡 → LM Studio(不过Ollama 也算可以)
第一步:安装
Windows
官网下载(最简单):
下载 Windows 安装包,双击运行,装完就自带命令行工具了。
装完之后,打开命令提示符 (Win+R → 输入 cmd → 回车),输入:
ollama --version看到版本号就说明装好了,例如 ollama version 0.5.x。
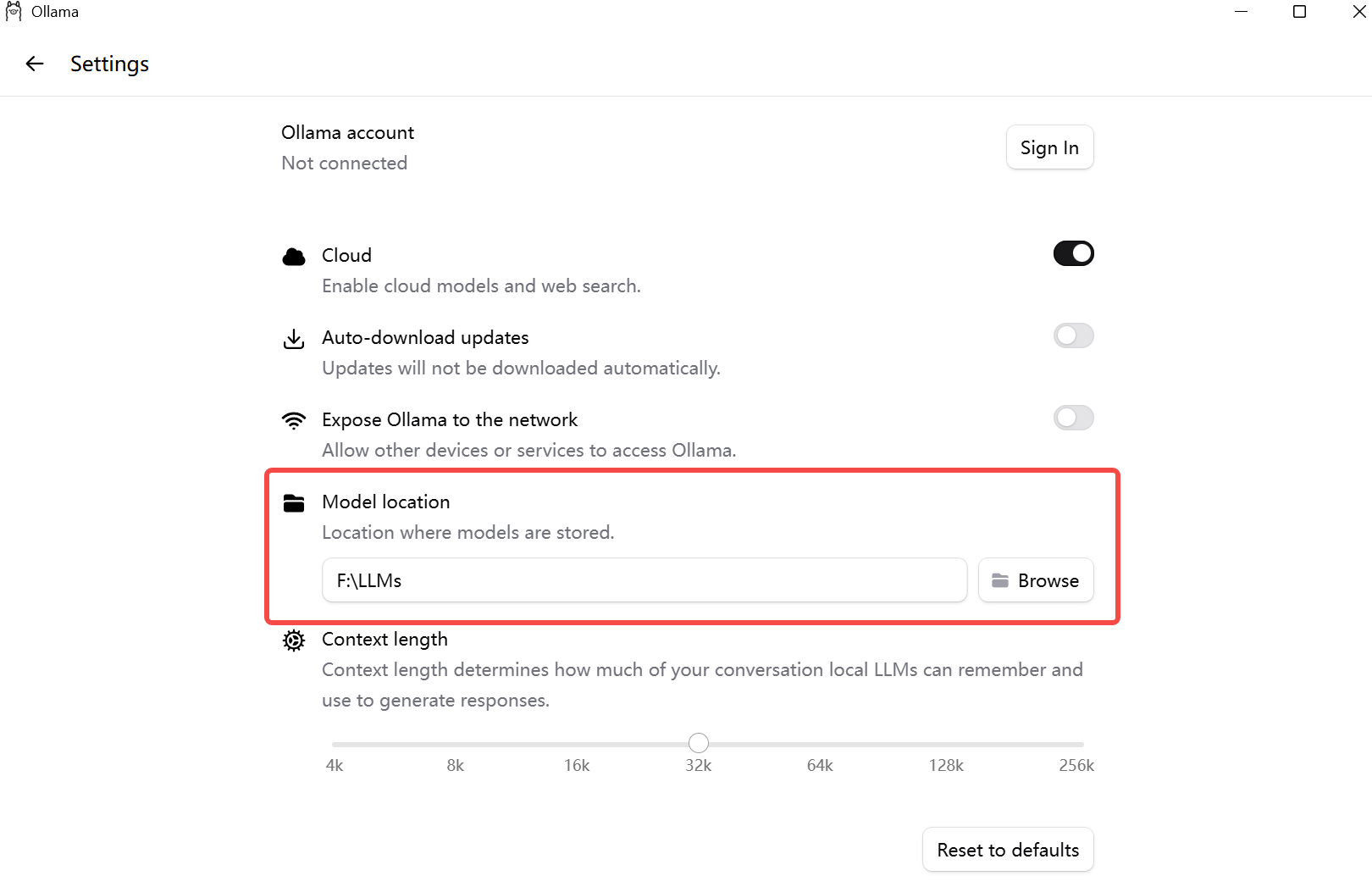
💡 Ollama 默认安装路径 :模型文件存在
C:\Users\你的用户名\.ollama\models,存储不够的话记得提前清理。最新版(0.22.1)已经支持设置模型存储目录,并且也通过命令指定安装目录:
OllamaSetup.exe /DIR="D:\Ollama"。
macOS
官网下载 dmg 包,或者用 Homebrew:
bash
brew install ollamaLinux
一行命令:
bash
curl -fsSL https://ollama.com/install.sh | shLinux环境可能会遇到网络问题,更详细的安装使用步骤如果需要可以留言。
第二步:拉取你的第一个模型
Ollama 的模型保存在「模型仓库」里,类似 Docker Hub,但存的是大模型文件。
📋 推荐从 Qwen2.5 开始
为什么?中文支持好,体积适中,生态完善。
拉取 7B 模型(RTX 4060 8GB 可以跑):
ollama pull qwen2.5:7b💡 第一次运行会下载模型文件,大概 4~5GB,取决于你的网速,可以泡杯咖啡等着。
其他常用模型推荐:
| 模型 | 大小 | 适合场景 | RTX 4060 能否跑 |
|---|---|---|---|
qwen2.5:0.5b |
~400MB | 快速测试 | ✅ 轻松跑 |
qwen2.5:1.5b |
~1GB | 日常对话 | ✅ 轻松跑 |
qwen2.5:7b |
~4.5GB | 主力推荐 | ✅ 可以跑 |
qwen2.5:14b |
~9GB | 更高质量 | ⚠️ RTX 4060 勉强 |
llama3.1:8b |
~4.7GB | 国际对标 | ✅ 可以跑 |
deepseek-r1:7b |
~4.7GB | 推理能力强 | ✅ 可以跑 |
💡 显存够不够怎么判断? 粗略估算:7B Q4量化约占用 4 ~ 5GB 显存,RTX 4060 8GB 跑起来没问题。14B Q4量化约 8 ~ 9GB,RTX 4060 有压力,建议降到 7B。
注意,加载到GPU内存后占用大小会放大到1.5~3倍 (与设置的上下文长度有关)
如图,RTX 4060 8GB 建议最大用4B模型,如果追求流畅度的话用3B、2B更合适。

查看你已经拉取了哪些模型:
ollama list第三步:直接开聊
装完模型,不用任何配置,直接对话:
ollama run qwen2.5:7b你会看到光标在闪烁,直接输入你的问题:
>>> 你好,请你用50字介绍一下量子计算
>>>
>>> 你好!量子计算是一种利用量子力学原理进行信息处理的技术。它
>>> 通过量子比特(qubit)实现并行计算,在特定问题上相比传统
>>> 计算机具有指数级加速潜力......输入 /bye 或者按两次 Ctrl+C 退出对话。
💡 第一次运行会稍微慢一点,因为 Ollama 要把模型加载进显存。之后每次
ollama run都会复用同一个实例,再次运行就快多了。
第四步:API 调用------把你的模型接进代码
这才是 Ollama 真正好用的地方:它自带 OpenAI-compatible API,你的 Python / JavaScript 代码只需要改一行地址,就能从调用 GPT-4 切换到调用本地模型。
启动 API 服务
Ollama 安装后就自动带了一个 API 服务,不需要额外操作。
💡 Ollama 会在后台运行一个 HTTP 服务,地址是
http://localhost:11434,默认端口 11434。
Python 调用示例
python
# 安装 openai SDK(Ollama 兼容 OpenAI 的格式)
pip install openai
# Python 代码
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # ← Ollama 的 API 地址
api_key="ollama" # ← Ollama 不需要真实 key,随便填
)
response = client.chat.completions.create(
model="qwen2.5:7b", # ← 你想用的模型
messages=[
{"role": "user", "content": "用一句话解释什么是Token"}
],
temperature=0.7,
)
print(response.choices[0].message.content)运行之前,确保 Ollama 正在运行(Windows 任务栏右下角有图标,或者直接运行 ollama serve 启动服务)。
切换模型只需要改一行
想把 GPT-4 换成本地模型?原来调 OpenAI 的代码,只需要把 base_url 和 model 改掉,其他代码一行不用动:
python
# OpenAI
client = OpenAI(api_key="sk-xxxx")
# 换成本地 Ollama(只改这两行)
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
model = "qwen2.5:7b"RTX 4060 8GB 实测:能跑哪些模型?
结合我们的 RTX 4060 8GB 实测参考:
| 模型 | 量化精度 | 显存占用 | 响应速度 | 质量 | 推荐度 |
|---|---|---|---|---|---|
| Qwen2.5-0.5B | Q4 | ~500MB | 非常快 | 基础可用 | ⭐⭐⭐ |
| Qwen2.5-1.5B | Q4 | ~1GB | 很快 | 日常对话 OK | ⭐⭐⭐⭐ |
| Qwen2.5-7B | Q4 | ~4.5GB | 较快 | 主力推荐 | ⭐⭐⭐⭐⭐ |
| Qwen2.5-14B | Q4 | ~9GB | 一般 | RTX 4060 有压力 | ⭐⭐ |
| Llama3.1-8B | Q4 | ~5GB | 较快 | 对话质量好 | ⭐⭐⭐⭐ |
💡 量化是什么? 简单说就是「把模型体积压缩的技术」。Q4_K_M 是目前最流行的平衡方案------压缩了模型大小,但质量损失很小。
常见报错 FAQ
❌ 报错:Error: model 'qwen2.5:7b' not found
原因 :模型还没拉取到本地。
解决:
ollama pull qwen2.5:7b❌ 报错:Error: insufficient memory to run model
原因 :显存不够,模型太大了。
解决:
- 换一个更小的模型:
ollama run qwen2.5:1.5b - 清理其他占用显存的应用(关掉游戏、浏览器标签页)
- 降低上下文长度(减少
max_tokens)
❌ 报错:Error: listen tcp 11434: bind: address already in use
原因 :11434 端口被其他程序占用了(可能是另一个 Ollama 实例)。
解决:
# 先杀掉现有进程
taskkill /f /im ollama.exe
# 然后重启
ollama serve❌ 报错:Connection refused(API 调用时)
原因 :Ollama 服务没启动。
解决 :打开命令行运行 ollama serve,或者在 Windows 任务栏找到 Ollama 图标点「Start Server」。
❌ 拉模型很慢 / 一直卡着
原因 :网络问题,Ollama 默认从国外服务器下载。
解决:配置国内镜像(可选,但推荐):
- 方法一:用代理/VPN
- 方法二:手动下载 GGUF 文件放到
~/.ollama/models/目录
Ollama 进阶操作
查看正在运行的模型
ollama ps会显示模型名称、加载时间、显存占用。
手动释放显存(停止模型)
ollama stop qwen2.5:7b释放之后显存就空出来了,想再跑再 ollama run。
创建自定义模型(高级)
如果社区模型不够用,你可以用 Modelfile 自定义系统提示词、温度等参数。
📋 完整示例:创建一个「中文技术写作助手」
Step 1:创建 Modelfile 文件
在任意目录下创建一个名为 Modelfile 的文件(无后缀),内容如下:
dockerfile
# 基于哪个模型
FROM qwen2.5:7b
# 调整推理参数
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER num_ctx 4096
# 设置系统提示词(决定模型的「人设」)
SYSTEM """
你是一个专业的中文技术写作助手。
- 用简洁有趣的语言解释复杂概念
- 优先用类比和例子,少用术语
- 每个回答控制在 200 字以内
"""
# 设置停止词(遇到这些词就停止生成)
PARAMETER stop ""Step 2:构建自定义模型
bash
ollama create my-writer -f ./Modelfile看到 success 就说明构建成功了。
Step 3:运行并测试
bash
ollama run my-writer测试效果:
>>> 解释什么是 KV Cache
KV Cache 就像是「记笔记」。大模型推理时会把中间结果
存下来,下次遇到相似的上下文就能直接复用,不用从头算。
就像你做数学题,把中间步骤记在草稿纸上,下次遇到类似
题目直接翻草稿,更快。Step 4:管理你的自定义模型
bash
# 查看所有模型(包括自定义的)
ollama list
# 查看模型详情
ollama show my-writer
# 删除自定义模型
ollama rm my-writer💡 Modelfile 能做什么?
- 设置系统提示词(让模型扮演特定角色)
- 调整 temperature、top_p 等参数
- 设置停止词、上下文长度
- 甚至可以基于 GGUF 文件创建本地模型
本篇小结
| 你做到了 | 说明 |
|---|---|
| ✅ 安装了 Ollama | Windows/macOS/Linux 三平台支持 |
| ✅ 拉取了第一个模型 | ollama pull qwen2.5:7b |
| ✅ 跑起了第一个对话 | ollama run qwen2.5:7b |
| ✅ 会用 API 调用 | OpenAI-compatible 格式,Python 一行改地址 |
| ✅ 能处理常见报错 | OOM / 端口占用 / 连接拒绝 |
| ✅ 知道 RTX 4060 能跑什么 | 7B Q4 是主力推荐 |
RTX 4060 8GB 推荐配置:Qwen2.5-7B Q4量化,日常对话足够流畅。
下一篇文章我们来聊聊另一个选择------如果你完全不想碰命令行,LM Studio 可能是更好的入门方式。