
SANA-WM,英伟达SANA系列新进展,2.6B开源世界模型,可以在单个GPU上将一张图像和一条相机轨迹转换为720p、时长一分钟、可控的视频,36倍更高吞吐
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
Haoyi Zhu, Haozhe Liu, Yuyang Zhao, Tian Ye, Junsong Chen, Jincheng Yu, Tong He, Song Han, Enze Xie
nVidia
Project: https://nvlabs.github.io/Sana/WM/
Code: https://github.com/NVlabs/Sana (SANA-WM代码尚未release)
arXiv: https://arxiv.org/abs/2605.15178
摘要

SANA-WM 是英伟达发布的 2.6B 参数开源世界模型,能在单张 GPU 上将一张图像和一条相机轨迹转换为 720p、时长一分钟的可控视频。其核心突破来自三项设计:混合线性 Diffusion Transformer (将 Gated DeltaNet 与稀疏 Softmax Attention 交替堆叠,将 961 帧长序列的显存复杂度从 O ( T 2 ) O(T^2) O(T2) 降至 O ( D 2 ) O(D^2) O(D2))、双分支相机控制 (Coarse 分支用 UCPE 建立 6-DoF 相机坐标系,Fine 分支用 Plücker Raymap 捕获帧内高频运动),以及两阶段生成流水线 (Base 模型产出初稿,17B Refiner 修复时序退化)。基准测试中 SANA-WM 吞吐量达 24.1 videos/hr,比最近的 480p 开源基线高出 36×,相机旋转误差 4.50°、平移误差 1.39,均优于参数量大 5× 以上的竞品。论文已于 2026-05 发布在 arXiv(2605.15178)。
一、问题背景
1.1 现有方法的局限
当前开源世界模型面临两个根本矛盾:
-
长序列效率 :生成一分钟 720p 视频意味着处理 ~961 帧的 token 序列。Transformer Softmax Attention 的 O ( T 2 ) O(T^2) O(T2) 显存复杂度使其无法在单卡上跑通;已有方案(LingBot-World 14B+14B)需要多卡且吞吐量仅 0.6 videos/hr。
-
相机精度与泛化:互联网视频没有精确的相机内外参标注。现有标注依赖单目深度(内参不准)或商业 MASt3R(闭源),生成视频的相机轨迹偏差普遍超过 15°(旋转)。
1.2 SANA-WM 的应对思路
| 问题 | SANA-WM 的解法 |
|---|---|
| O ( T 2 ) O(T^2) O(T2) 显存 | Gated DeltaNet 线性递归状态,每帧仅保留 O ( D 2 ) O(D^2) O(D2) 状态矩阵 |
| 稀疏全局依赖 | 每 4 块插入一次 Softmax Attention(5/20 块)维持远程精度 |
| 相机标注缺失 | VIPE 引擎融合 Pi3X + MoGe-2 得到度量尺度 6-DoF 位姿 |
| 时序退化 | 两阶段:Base 模型生成 + LTX-2 Refiner 修复后段质量下降 |
二、核心方法
2.1 整体框架
双分支相机控制
单帧图像 + 相机轨迹
LTX2-VAE 编码
C=128 潜空间
Hybrid Linear DiT
20 blocks / 2.6B
初步 720p 视频
60s @ 16fps
Long-Video Refiner
LTX-2 17B LoRA
最终输出
720p 60s 视频
Coarse: UCPE
帧级 6-DoF
Fine: Plücker Raymap
逐像素 48ch
整体遵循四阶段渐进训练:
Stage 1: VAE 适配
50K steps / 3.5 days
替换为 LTX2-VAE
Stage 2: 混合架构适配
30K steps / 2 days
短片段训练
Stage 3: 分钟级扩展
31K steps / 8 days
接入双分支相机控制
Stage 4: SFT + 蒸馏
10K steps / 2.5 days
Chunk-Causal 推理
2.2 混合线性注意力:Gated DeltaNet
问题 :961 帧序列的 Softmax Attention 需 O ( T 2 ) O(T^2) O(T2) 显存,单卡无法承受。
解法 :用 Gated DeltaNet (GDN) 替换大部分 Attention Block,将序列状态压缩为 D × D D \times D D×D 递归矩阵。
状态更新方程:
S t = S t − 1 M t + U t \mathbf{S}t = \mathbf{S}{t-1} \mathbf{M}_t + \mathbf{U}_t St=St−1Mt+Ut
M t = γ t ( I − K ^ t β t K ^ t ⊤ ) , U t = V t β t K ^ t ⊤ \mathbf{M}_t = \gamma_t \left(\mathbf{I} - \hat{\mathbf{K}}_t \beta_t \hat{\mathbf{K}}_t^\top\right), \quad \mathbf{U}_t = \mathbf{V}_t \beta_t \hat{\mathbf{K}}_t^\top Mt=γt(I−K^tβtK^t⊤),Ut=VtβtK^t⊤
O t = S t Q ^ t \mathbf{O}_t = \mathbf{S}_t \hat{\mathbf{Q}}_t Ot=StQ^t
其中 S t ∈ R D × D \mathbf{S}_t \in \mathbb{R}^{D \times D} St∈RD×D 为帧级递归状态, γ t ∈ ( 0 , 1 ] \gamma_t \in (0,1] γt∈(0,1] 为衰减门控, β t ∈ 0 , 1 \beta_t \in 0,1 βt∈0,1 为更新门控。每帧显存复杂度固定为 O ( D 2 ) O(D^2) O(D2),与序列长度 T T T 无关。
数值稳定性:键向量按以下方式归一化防止梯度爆炸:
K ^ t = K ˉ t ⋅ 1 D ⋅ S \hat{\mathbf{K}}_t = \bar{\mathbf{K}}_t \cdot \frac{1}{\sqrt{D \cdot S}} K^t=Kˉt⋅D⋅S 1
该归一化保证注意力矩阵的迹 ≤ 1 \leq 1 ≤1,确保状态转移为非扩张映射。实验表明仅用 1 / D 1/\sqrt{D} 1/D (L2 Norm)会在第 16 步出现 NaN 梯度。
混合策略 :20 个 Block 中第 { 3 , 7 , 11 , 15 , 19 } \{3,7,11,15,19\} {3,7,11,15,19} 位置(共 5 个)使用标准 Softmax Attention,其余 15 个使用 GDN。Softmax Block 专门处理跨度极长的全局依赖,GDN Block 处理局部时序压缩。
2.3 双分支相机控制
Coarse 分支:Ray-Local UCPE
在潜空间帧率下建立相机坐标系,以统一相机位置编码(UCPE)注入 6-DoF 轨迹:
Q ~ i c = ( D i ⊤ ⊕ RoPE i ) Q i c \tilde{\mathbf{Q}}^c_i = (\mathbf{D}_i^\top \oplus \text{RoPE}_i)\mathbf{Q}^c_i Q~ic=(Di⊤⊕RoPEi)Qic
( K ~ i c , V ~ i c ) = ( D i − 1 ⊕ RoPE i ) ( K i c , V i c ) (\tilde{\mathbf{K}}^c_i, \tilde{\mathbf{V}}^c_i) = (\mathbf{D}_i^{-1} \oplus \text{RoPE}_i)(\mathbf{K}^c_i, \mathbf{V}^c_i) (K~ic,V~ic)=(Di−1⊕RoPEi)(Kic,Vic)
O i c = ( D i ⊕ RoPE i − 1 ) ⋅ GDN cam ( Q ~ c , K ~ c , V ~ c ) i \mathbf{O}^c_i = (\mathbf{D}_i \oplus \text{RoPE}i^{-1}) \cdot \text{GDN}{\text{cam}}(\tilde{\mathbf{Q}}^c, \tilde{\mathbf{K}}^c, \tilde{\mathbf{V}}^c)_i Oic=(Di⊕RoPEi−1)⋅GDNcam(Q~c,K~c,V~c)i
其中 D i \mathbf{D}_i Di 为 4 × 4 4 \times 4 4×4 齐次 Ray-Local 变换矩阵,将世界空间光线转换到相机局部坐标系。
Fine 分支:Plücker Raymap 混合
以 8× 高频(原始帧率)捕获 VAE 内的帧间相机运动:
- 对每个像素 ( r , p ) (r, p) (r,p) 计算 Plücker 坐标: ρ r , p = ( d r , p , o r × d r , p ) ∈ R 6 \boldsymbol{\rho}{r,p} = (\mathbf{d}{r,p},\ \mathbf{o}r \times \mathbf{d}{r,p}) \in \mathbb{R}^6 ρr,p=(dr,p, or×dr,p)∈R6
- 将 8 个原始帧 Raymap 打包为 48 通道张量(每个潜空间帧对应 8 原始帧)
- 经零初始化的 3D Patch Embedder + 逐 Block 线性投影注入 DiT
| 消融配置 | 旋转误差 (°↓) | 平移误差 (↓) |
|---|---|---|
| 无相机控制 | 37.24 | 4.23 |
| UCPE 仅 Coarse | 7.73 | 0.1350 |
| UCPE + Plücker | 6.21 | 0.1162 |
2.4 两阶段生成流水线
Base SANA-WM
2.6B, 60步
初稿视频
存在后段退化
Long-Video Refiner
LTX-2 17B + rank-384 LoRA
截断-σ 流匹配
σ_start=0.909375
最终视频
ΔIQ: 3.79→1.17
Refiner 的截断-σ 流匹配公式:
x 1 = ( 1 − σ start ) x l + σ start ⋅ ε \mathbf{x}1 = (1 - \sigma{\text{start}})\mathbf{x}l + \sigma{\text{start}} \cdot \varepsilon x1=(1−σstart)xl+σstart⋅ε
α = σ t / σ start , x t = ( 1 − α ) x h + α ⋅ x 1 \alpha = \sigma_t / \sigma_{\text{start}}, \quad \mathbf{x}_t = (1-\alpha)\mathbf{x}_h + \alpha \cdot \mathbf{x}_1 α=σt/σstart,xt=(1−α)xh+α⋅x1
v ∗ = ( x 1 − x h ) / σ start \mathbf{v}^* = (\mathbf{x}_1 - \mathbf{x}h) / \sigma{\text{start}} v∗=(x1−xh)/σstart
其中 x l \mathbf{x}_l xl 为粗生成结果, x h \mathbf{x}_h xh 为已接受的前段帧(固定 KV Anchor),仅对后段去噪 3 步。
效果 :Simple 轨迹下 VBench Overall 从 79.29 → 80.62 ,时序质量退化指标 ΔIQ 从 3.79 → 1.17。
2.5 相机位姿标注流水线
互联网视频没有精确内参,SANA-WM 构建了 VIPE 引擎解决这个问题:
原始视频
Pi3X 多帧一致性深度
MoGe-2 度量尺度深度
深度融合
最小化加权 L2
逐帧内参优化
f_x, f_y, c_x, c_y
Bundle Adjustment
6-DoF 位姿
213K clips
度量尺度标注
深度融合目标函数:
min s ∑ i w i ( s ⋅ d i Pi3X − d i MoGe ) 2 \min_{s} \sum_i w_i \left(s \cdot d_i^{\text{Pi3X}} - d_i^{\text{MoGe}}\right)^2 smini∑wi(s⋅diPi3X−diMoGe)2
对非方形像素的互联网视频,BA 将 ( f x , f y , c x , c y ) (f_x, f_y, c_x, c_y) (fx,fy,cx,cy) 作为逐帧独立变量优化。
训练数据集构成(共 212,975 个 clips):
| 数据源 | 类型 | 时长 | Clips 数 | 位姿方法 |
|---|---|---|---|---|
| SpatialVID-HQ | 真实 | 10s | 158,369 | VIPE + Pi3X/MoGe-2 |
| DL3DV | 真实 | 10s | 5,691 | GT + Pi3X |
| DL3DV GS Refined | 合成 | 60s | 14,881 | 3DGS 增强 |
| OmniWorld | 合成 | 60s | 1,720 | VIPE + GT Depth |
| Sekai Walking-HQ | 真实 | 60s | 9,767 | VIPE + Pi3X/MoGe-2 |
| MiraData | 真实 | 60s | 18,987 | VIPE + Pi3X/MoGe-2 |
三、工程实现
模型架构参数
| 参数 | 值 |
|---|---|
| 总 Block 数 | 20(15 GDN + 5 Softmax) |
| 头维度 D D D | 112 |
| 模型维度 d model d_{\text{model}} dmodel | 2240 |
| VAE 潜空间通道 | 128(LTX2-VAE) |
| Softmax Block 位置 | {3, 7, 11, 15, 19} |
| 生成分辨率 | 720p |
| 生成时长 | 60s @ 16fps(961 帧) |
Context-Parallel 训练
961 帧序列跨 P P P 张 GPU 切片,通过仿射组合聚合状态:
S ˉ p + 1 = S ˉ p ⋅ C p + H p \bar{\mathbf{S}}_{p+1} = \bar{\mathbf{S}}_p \cdot \mathbf{C}_p + \mathbf{H}_p Sˉp+1=Sˉp⋅Cp+Hp
All-Gather 的是 ( D × D ) (D \times D) (D×D) 紧凑摘要而非完整激活值,通信量极小且数学等价。
推理部署变体
bash
# 全质量双向模式(推荐)
# 29.5 videos/hr,单 H100
python inference.py --mode bidirectional --steps 60
# Chunk-Causal 流式模式
# 24.1 videos/hr,支持增量生成
python inference.py --mode chunk_causal --steps 60
# 4 步蒸馏 + NVFP4 量化(消费级 GPU)
# RTX 5090 约 34 秒 / 60s 视频
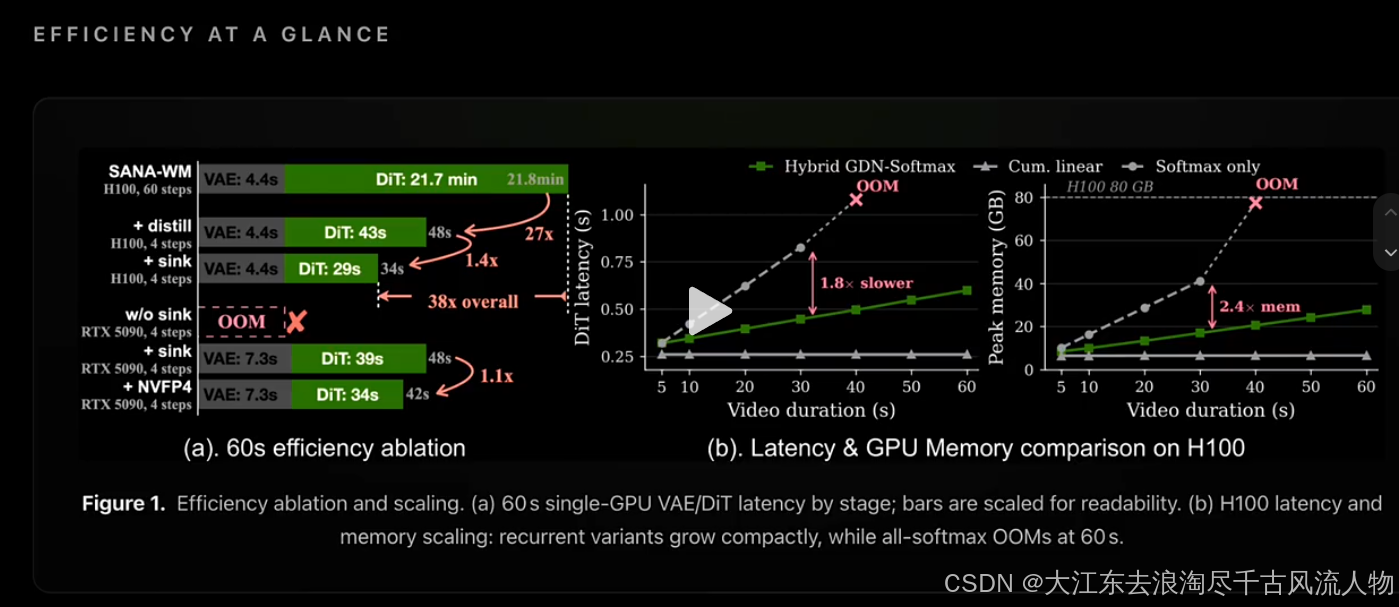
python inference.py --mode distilled --steps 4 --quant nvfp4四、实验分析
4.1 主基准对比(Simple 轨迹)
| 方法 | 参数量 | 分辨率 | 旋转误差(°↓) | 平移误差(↓) | VBench(↑) | 显存(GB↓) | 吞吐(vid/hr↑) |
|---|---|---|---|---|---|---|---|
| Infinite-World | 1.3B | 480p | 16.55 | 1.98 | 79.18 | 53.5 | 5.9 |
| LingBot-World | 14B+14B | 480p | 10.47 | 2.01 | 81.82 | 454.1 | 0.6 |
| HY-WorldPlay | 8B | 480p | 17.89 | 2.36 | 68.82 | 215.5 | 1.1 |
| Matrix-Game 3.0 | 5B | 720p | 12.96 | 1.83 | 78.53 | 106.2 | 3.1 |
| SANA-WM | 2.6B | 720p | 7.59 | 1.59 | 79.29 | 51.1 | 24.1 |
| +Refiner | 2.6B+17B | 720p | 4.50 | 1.39 | 80.62 | 74.7 | 22.0 |
4.2 Hard 轨迹对比
| 方法 | 旋转误差(°↓) | 平移误差(↓) | VBench(↑) |
|---|---|---|---|
| Infinite-World | 41.31 | 2.49 | 79.51 |
| LingBot-World | 18.99 | 1.65 | 81.89 |
| Matrix-Game 3.0 | 18.79 | 1.67 | 78.79 |
| SANA-WM+Refiner | 8.34 | 1.39 | 81.89 |
Hard 轨迹下双分支相机控制的优势更明显,旋转误差比 LingBot(14B×2)小 56%,参数量仅为对方 9%。
4.3 时序稳定性(ΔIQ 越小越好)
| 配置 | PSNR(↑) | SSIM(↑) | LPIPS(↓) | ΔIQ(↓) |
|---|---|---|---|---|
| SANA-WM(Simple) | 14.16 | 0.333 | 0.458 | 3.79 |
| +Refiner(Simple) | 14.46 | 0.292 | 0.479 | 1.17 |
| SANA-WM(Hard) | 14.10 | 0.327 | 0.469 | 3.09 |
| +Refiner(Hard) | 14.80 | 0.312 | 0.458 | 0.31 |
ΔIQ 衡量视频后段的图像质量退化程度。Refiner 将 Hard 轨迹 ΔIQ 从 3.09 压缩到 0.31,即长视频末段画质几乎不衰减。
4.4 吞吐效率分析
LingBot-World (14B+14B, 480p): 0.6 vid/hr ← 最慢
HY-WorldPlay (8B, 480p): 1.1 vid/hr
Matrix-Game (5B, 720p): 3.1 vid/hr
Infinite-World (1.3B, 480p): 5.9 vid/hr
SANA-WM (2.6B, 720p): 24.1 vid/hr ← 最快,36× vs Infinite-WorldSANA-WM 在更高分辨率(720p vs 480p)下实现了最高吞吐,核心原因是 GDN 线性递归将 961 帧长序列的计算复杂度从 O ( T 2 ) O(T^2) O(T2) 降至 O ( T ⋅ D 2 ) O(T \cdot D^2) O(T⋅D2)。
小结
三个创新点的技术判断:
-
Hybrid GDN + Softmax(核心贡献) :GDN 的 O ( D 2 ) O(D^2) O(D2) 常数状态是本文效率突破的根本,"每 4 Block 插一个 Softmax"是工程折中------纯 GDN 会丢失远程依赖,全 Softmax 单卡跑不通。该设计具有强可迁移性,值得在其他长视频任务中复用。
-
双分支相机控制:UCPE(帧级粗粒度)+ Plücker(像素级细粒度)的组合解决了 VAE 时间下采样导致的相机信息丢失问题,Hard 轨迹下 ΔRot 比单 UCPE 降低 20%(7.73° → 6.21°,消融表 4)。
-
两阶段 Refiner:ΔIQ 从 3.79 → 1.17 说明 Base 模型本身存在系统性后段退化,Refiner 是工程补丁而非可选优化。若 Base 模型的长程一致性进一步提升,Refiner 的收益会缩小。
局限性:
- 代码尚未 release(截至 2026-05),只能参考论文复现
- 训练依赖 64 张 H100 共 15 天,门槛较高
- Refiner 引入的 17B 参数使完整系统实际参数量达 19.6B,并非真正的 2.6B 全链路
项目链接 :arXiv 2605.15178 | 项目主页 | GitHub