目录
- 序言
- OpenSpec
-
- 快速入门
-
- [Delta Spec 工作机制](#Delta Spec 工作机制)
- [示例:你的第一个变更(Example: Your First Change)](#示例:你的第一个变更(Example: Your First Change))
-
- [1. 开始变更(默认方式)](#1. 开始变更(默认方式))
- [2. 创建了什么(What Gets Created)](#2. 创建了什么(What Gets Created))
- [3. 执行实现(Implement)](#3. 执行实现(Implement))
- [4. 归档(Archive)](#4. 归档(Archive))
- [验证与查看(Verifying and Reviewing)](#验证与查看(Verifying and Reviewing))
- 命令大全
- [多语言指南(Multi-Language Guide)](#多语言指南(Multi-Language Guide))
-
- [语言示例(Language Examples)](#语言示例(Language Examples))
- 使用建议(Tips)
-
- [处理技术术语(Handle Technical Terms)](#处理技术术语(Handle Technical Terms))
- [与其他上下文组合使用(Combine with Other Context)](#与其他上下文组合使用(Combine with Other Context))
- 验证配置(Verification)
- 引导教程
- 工作流(Workflows)
-
- [工作流模式(Expanded Mode Patterns)](#工作流模式(Expanded Mode Patterns))
-
- [⚡ 快速功能开发(Quick Feature)](#⚡ 快速功能开发(Quick Feature))
- 探索式工作流(Exploratory)
- [并行开发(Parallel Changes)](#并行开发(Parallel Changes))
- [完成一个变更(Completing a Change)](#完成一个变更(Completing a Change))
- [什么时候用哪个(When to Use What)](#什么时候用哪个(When to Use What))
- [最佳实践(Best Practices)](#最佳实践(Best Practices))
-
- [保持变更的聚焦(Keep Changes Focused)](#保持变更的聚焦(Keep Changes Focused))
- [对不清晰需求使用 `/opsx:explore`](#对不清晰需求使用
/opsx:explore) - [在归档前使用 `/opsx:verify`](#在归档前使用
/opsx:verify) - [给 change 起清晰的名字](#给 change 起清晰的名字)
- 结尾
序言
在之前关于 SDD(Spec Driven Development)的文章中,我只是对这一理念做了一个初步的概括,并简单提及了 OpenSpec、Spec Kit 等相关工具。
但在进一步了解这些工具之后,我逐渐产生了一个更实际的判断:SDD 本身的方向是合理的,但它的落地方式并不一定需要依赖"重框架"。
很多围绕规范驱动开发的方案,往往会不自觉地走向一个问题------它们试图把"规范化"这件事做得过于完整,从而引入复杂的流程、额外的抽象层,以及较高的接入成本。但对于日常开发来说,这种"完整性"本身可能会变成一种负担。
相比之下,OpenSpec 更吸引我的地方在于它的定位:**它并不是一个重型开发框架,而是一种轻量级的规范表达与协作方式。**它试图在不显著改变原有开发习惯的前提下,把"先写清楚规范再实现"的思想嵌入到实际工作流中。
换句话说,如果说很多 SDD 方案是在"重构开发流程",那么 OpenSpec 更像是在"轻量插入一个规范层"。
正因为这种轻量性,它更适合作为我进入 SDD 实践的第一步------不需要一次性重构整个开发体系,而是从一个可控、低成本的切口开始,逐步观察规范驱动开发在真实工程中的作用边界。
因此,这篇文章的目的不是去评价 OpenSpec 是否完美,而是尝试从一个更实际的角度出发:它是否足够轻,以至于可以真正进入日常开发流程,而不会成为负担。
OpenSpec
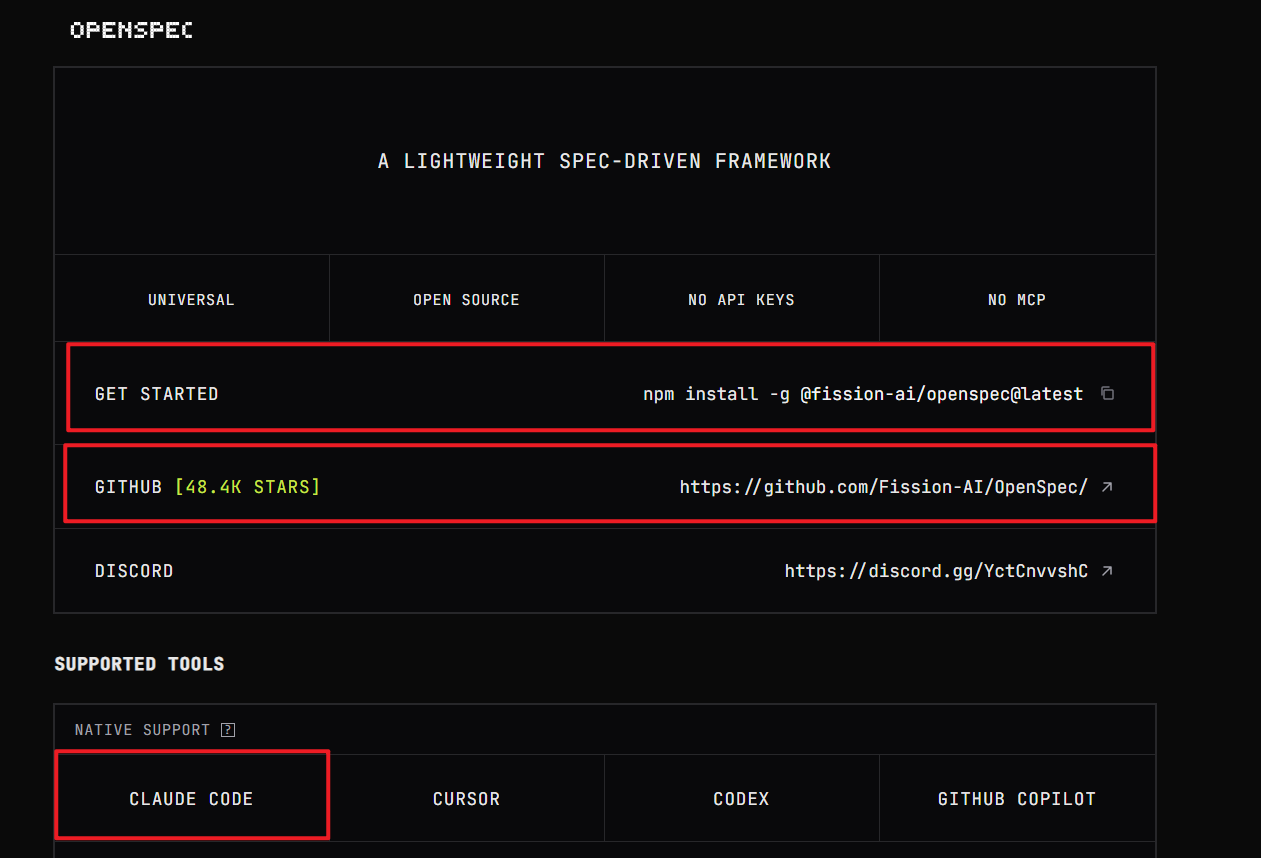
OpenSpec 的一个重要特点在于,它并不绑定特定的开发模型或工具链,而是可以与现有的 AI Coding 工作流进行组合使用,例如 Claude Code 等环境。
在理想情况下,这类基于规范驱动的开发方式,往往会依赖能力较强的编码模型来保证从 Spec 到实现的稳定映射。但在实际使用中,出于成本与可用性的考虑,并不总是需要使用最昂贵的生产级模型。
在本次实践中,我选择使用 OpenSpec + Claude Code 的工作方式作为整体开发框架,同时在模型层面采用 GLM-4.7-Flash 作为主要执行模型,在保证基本代码生成能力的前提下,控制整体成本开销。
这种组合更接近一种"工程折中方案":用 OpenSpec 提供结构化规范约束,用轻量模型承担实现任务,从而验证 SDD 在低成本环境下的可行性与稳定性。
claude code配置如下:
bash
{
"env": {
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "your api key",
"ANTHROPIC_MODEL": "glm-4.7-flash",
"API_TIMEOUT_MS": "300000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
}
}这里注意要选择质谱兼容anthropic的base_url!
快速入门
需要 Node.js 20.19.0 或更高版本。
安装 OpenSpec(全局安装)
bash
npm install -g @fission-ai/openspec@latest然后进入你的项目目录并初始化:
bash
cd your-project
openspec initinit 命令在开发工具中其实并不陌生,无论是 git init 还是 go mod init,本质上都是在做同一件事情:为当前项目建立一个可被工具识别和管理的基础环境结构。
OpenSpec 中的 openspec init 也是同样的逻辑,只是它初始化的不再是版本控制系统或依赖管理系统,而是一套"规范驱动开发"的工作目录结构。
执行 openspec init 之后,项目中会生成 spec 与 change 两个核心目录,以及用于承载规范与变更流转的基础文件结构。从这一刻开始,项目不再只是"代码仓库",而是一个可以围绕 Spec 进行演进的工作空间。
接下来告诉你的 AI:
bash
/opsx:propose <你想构建的内容>如果你想使用扩展工作流(例如):
- /opsx:new
- /opsx:continue
- /opsx:ff
- /opsx:verify
- /opsx:bulk-archive
- /opsx:onboard
可以通过以下方式启用:
bash
openspec config profile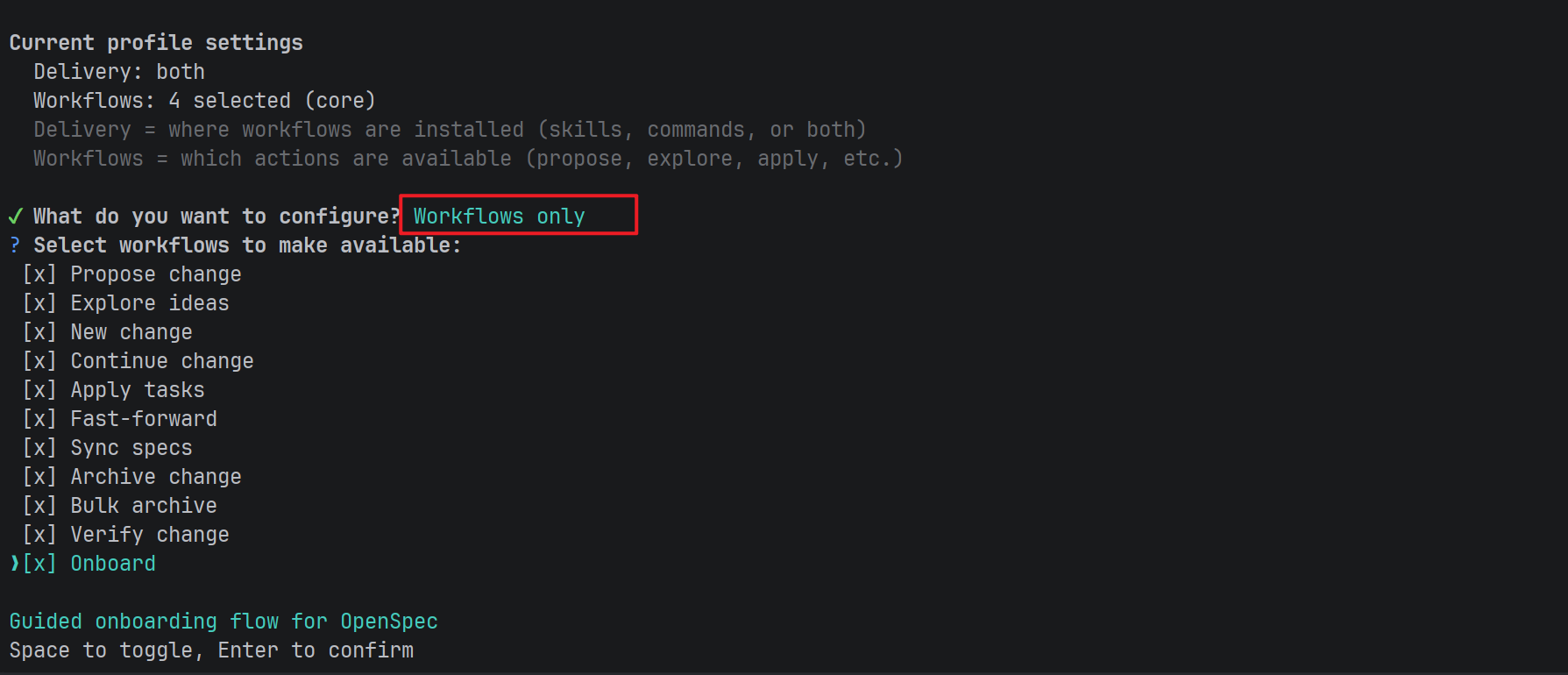
然后执行:
bash
openspec update可以在claude code的界面看到,所有斜杠命令都打开了:

OpenSpec 的核心目标是:在任何代码编写之前,帮助你和 AI 编程助手就"要构建什么"达成一致。
默认快速路径(核心流程)
/opsx:propose ──► /opsx:apply ──► /opsx:sync ──► /opsx:archive扩展路径(自定义工作流)
/opsx:new ──► /opsx:ff 或 /opsx:continue ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive默认的全局 profile 为 core,包含 propose、explore、apply、sync 和 archive 等命令。
你可以通过 openspec config profile 和 openspec update 启用扩展工作流命令。
执行 openspec init 后,项目结构如下:
openspec/
├── specs/ # 事实来源(系统行为的真实定义)
│ └── <domain>/
│ └── spec.md
├── changes/ # 提议的变更(每个变更一个目录)
│ └── <change-name>/
│ ├── proposal.md
│ ├── design.md
│ ├── tasks.md
│ └── specs/ # 差量 spec(变更内容)
│ └── <domain>/
│ └── spec.md
└── config.yaml # 项目配置(可选)specs/
系统的"唯一事实来源(source of truth)"。这些 spec 描述当前系统的行为。通常按领域组织,例如 specs/auth/、specs/payments/。
changes/
对系统的变更提案目录。每个变更都会生成一个独立文件夹,包含所有相关工件(artifact)。当变更完成后,其 spec 会合并回主 specs/ 目录。
每个 change 目录中包含一组用于指导开发的工件:
| 工件 | 作用 |
|---|---|
| proposal.md | "为什么做 & 做什么"------记录意图、范围与整体方案 |
| specs/ | 差量 spec(delta spec),描述新增 / 修改 / 删除的需求 |
| design.md | "如何做"------技术方案与架构设计 |
| tasks.md | 实现任务清单(带 checkbox) |
工件之间的关系:
proposal ──► specs ──► design ──► tasks ──► implement
▲ ▲ ▲ │
└───────────┴──────────┴────────────────────┘
在实现过程中持续迭代更新在实现过程中,你可以随时回头修改前面的工件,以反映新的理解。
Delta Spec 工作机制
Delta spec 是 OpenSpec 中的核心概念。它用于展示相对于当前系统 spec 的变化内容。
Delta spec 使用不同的"节"来表示变更类型:
md
# Delta for Auth
## ADDED Requirements
### Requirement: 双因素认证(Two-Factor Authentication)
系统在登录时必须要求第二验证因素。
#### Scenario: OTP required
- GIVEN 用户已启用 2FA
- WHEN 用户提交有效凭证
- THEN 系统应发起 OTP 验证流程
## MODIFIED Requirements
### Requirement: Session Timeout
系统应在 30 分钟无操作后使会话失效。
(之前为:60 分钟)
#### Scenario: Idle timeout
- GIVEN 已认证会话
- WHEN 超过 30 分钟无操作
- THEN 会话应被注销
## REMOVED Requirements
### Requirement: Remember Me
(已废弃,由 2FA 替代)Archive 之后发生什么(What Happens on Archive)
当一个 change 被归档(archive)时:
- ADDED 的需求会被追加到主 spec 中
- MODIFIED 的需求会替换原有版本
- REMOVED 的需求会从主 spec 中删除
随后,该 change 文件夹会被移动到:
txt
openspec/changes/archive/用于审计与历史追踪。
示例:你的第一个变更(Example: Your First Change)
下面以"为应用添加深色模式"为例说明完整流程。
1. 开始变更(默认方式)
你执行:
bash
/opsx:propose add-dark-modeAI 返回:
text
Created openspec/changes/add-dark-mode/
✓ proposal.md --- 为什么要做、改什么
✓ specs/ --- 需求与场景
✓ design.md --- 技术方案
✓ tasks.md --- 实现清单
Ready for implementation!如果启用了扩展 workflow profile,也可以拆分为两步:
bash
/opsx:new → /opsx:ff(或 /opsx:continue 逐步执行)2. 创建了什么(What Gets Created)
proposal.md(意图说明)
md
# Proposal: 添加深色模式
## Intent
用户希望支持深色模式,以减少夜间使用时的视觉疲劳。
## Scope
- 在设置中增加主题切换
- 支持系统主题检测
- 将用户偏好存储在 localStorage
## Approach
使用 CSS 自定义属性(CSS variables)进行主题化,
并通过 React Context 管理状态。specs/ui/spec.md(Delta 需求)
md
## ADDED Requirements
### Requirement: 主题选择(Theme Selection)
系统必须允许用户在浅色与深色主题之间切换。
#### Scenario: 手动切换
- GIVEN 用户在任意页面
- WHEN 用户点击主题切换按钮
- THEN 主题立即切换
- AND 偏好会跨会话持久化
#### Scenario: 系统偏好
- GIVEN 用户未设置主题偏好
- WHEN 应用首次加载
- THEN 使用系统默认颜色模式tasks.md(任务清单)
md
# Tasks
## 1. Theme 基础设施
- [ ] 1.1 创建 ThemeContext(light/dark 状态)
- [ ] 1.2 添加 CSS variables 定义颜色
- [ ] 1.3 实现 localStorage 持久化
## 2. UI 组件
- [ ] 2.1 创建 ThemeToggle 组件
- [ ] 2.2 添加到设置页面
- [ ] 2.3 在 Header 添加快捷切换
## 3. 样式系统
- [ ] 3.1 定义 dark theme 调色板
- [ ] 3.2 将组件颜色替换为 CSS variables3. 执行实现(Implement)
bash
/opsx:applyAI 输出:
text
Working through tasks...
✓ 1.1 创建 ThemeContext
✓ 1.2 添加 CSS variables 到 globals.css
✓ 1.3 实现 localStorage 持久化
✓ 2.1 创建 ThemeToggle 组件
...
All tasks complete!在实现过程中,如果发现设计需要调整,可以直接修改 artifact 并继续执行。
4. 归档(Archive)
bash
/opsx:archive输出:
text
Archiving add-dark-mode...
✓ 已将 spec 合并到 openspec/specs/ui/spec.md
✓ 已移动到 archive 目录:
openspec/changes/archive/2025-01-24-add-dark-mode/
Done! Ready for the next feature.此时,该变更已经正式成为系统规范的一部分。
验证与查看(Verifying and Reviewing)
bash
# 查看所有 active changes
openspec list
# 查看某个 change 详情
openspec show add-dark-mode
# 校验 spec 格式
openspec validate add-dark-mode
# 可视化界面
openspec view命令大全
这是 OpenSpec 的斜杠命令参考文档。这些命令会在你的 AI 编程助手聊天界面中调用(例如 Claude Code、Cursor、Windsurf)。
默认快速路径(core profile)
| 命令 | 作用 |
|---|---|
/opsx:propose |
创建一个变更,并在一步中生成规划工件 |
/opsx:explore |
在正式提交变更前进行思考与探索 |
/opsx:apply |
执行并实现变更中的任务 |
/opsx:sync |
将 delta spec 合并到主 spec |
/opsx:archive |
归档已完成的变更 |
扩展工作流命令(自定义 workflow 选择)
| 命令 | 作用 |
|---|---|
/opsx:new |
创建一个新的变更骨架 |
/opsx:continue |
基于依赖关系继续生成下一个工件 |
/opsx:ff |
快进模式:一次性生成全部规划工件 |
/opsx:verify |
校验实现是否符合工件定义 |
/opsx:bulk-archive |
批量归档多个变更 |
/opsx:onboard |
引导式教程,完整走一遍工作流 |
/opsx:propose
在一步中创建一个新的变更并生成规划工件。这是 core profile 中的默认起始命令。
语法
bash
/opsx:propose [change-name-or-description]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name-or-description | 否 | kebab-case 格式的变更名称,或用自然语言描述的变更 |
该命令会:
- 创建目录
openspec/changes/<change-name>/ - 在实现前生成所需的工件(spec-driven 流程中包括:proposal、specs、design、tasks)
- 在变更准备好进入
/opsx:apply阶段时停止
示例
text
You: /opsx:propose add-dark-mode
AI: Created openspec/changes/add-dark-mode/
✓ proposal.md
✓ specs/ui/spec.md
✓ design.md
✓ tasks.md
Ready for implementation. Run /opsx:apply.提示(Tips)
- 这是最快的端到端工作流入口
- 如果你希望更细粒度控制每个工件的生成过程,可以启用扩展 workflow,使用
/opsx:new + /opsx:continue
/opsx:explore
在提交变更之前,用于思考、分析问题并澄清需求。
语法
bash
/opsx:explore [topic]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| topic | 否 | 你想要探索或分析的主题 |
功能说明
该命令会:
-
启动一个非结构化的探索式对话
-
分析代码库以回答问题
-
对比不同方案与实现路径
-
生成图示或结构化说明以辅助理解
-
在理解清晰后,可切换到:
/opsx:propose(默认路径)/opsx:new(扩展 workflow)
示例:
text
You: /opsx:explore
AI: 你想探索什么问题?
You: 移动端应该如何处理认证?
AI: 我先分析你当前的认证系统...
[分析代码库]
你当前 Web 使用的是 session-based auth。
对于移动端,有三种主要方案:
1. JWT tokens(无状态,可离线)
2. OAuth2(适合第三方登录)
3. 扩展现有 session(更简单,但依赖连接)
你们的 API 已经配置了 CORS。你更倾向哪种方案?
You: 选 JWT,可以开始一个变更吗?
AI: 可以,执行 /opsx:propose add-jwt-auth 即可开始。提示(Tips)
- 当需求不清晰或需要调研时使用
- 不会生成任何 artifacts
- 适合在确定方案前对多种路径进行对比
- 可以读取文件并搜索整个代码库
/opsx:new
启动一个新的变更骨架(change scaffold)。该命令会创建变更目录,并等待你通过 /opsx:continue 或 /opsx:ff 来生成后续工件。
该命令属于扩展工作流集合(默认 core profile 中不包含)。
语法
bash
/opsx:new [change-name] [--schema <schema-name>]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 变更名称(如果未提供会提示输入) |
| --schema | 否 | 使用的工作流 schema(默认来自 config 或 spec-driven) |
功能说明
该命令会:
- 创建目录
openspec/changes/<change-name>/ - 在变更目录中生成
.openspec.yaml元数据文件 - 展示第一个待创建的工件模板
- 如果未提供参数,会提示输入变更名称与 schema
创建内容
text
openspec/changes/<change-name>/
└── .openspec.yaml # 变更元数据(schema、创建时间等)示例
text
You: /opsx:new add-dark-mode
AI: Created openspec/changes/add-dark-mode/
Schema: spec-driven
Ready to create: proposal
Use /opsx:continue 创建它,或使用 /opsx:ff 一次性创建所有工件。使用提示(Tips)
- 使用具有语义的名称,例如:
add-feature、fix-bug、refactor-module - 避免使用过于模糊的名称,例如:
update、changes、wip - schema 也可以在项目配置中设置(
openspec/config.yaml)
这一部只是创建一个文件夹,是不包含AI交互的。
/opsx:continue
在依赖链中创建下一个工件(artifact),每次只生成一个,用于逐步推进变更流程。
语法
bash
/opsx:continue [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要继续的变更名称(若不提供则从上下文推断) |
功能说明
该命令会:
- 查询工件依赖关系图(dependency graph)
- 显示哪些工件可创建、哪些被阻塞
- 创建当前可执行的第一个工件
- 读取依赖文件作为上下文
- 显示创建后解锁的下一步工件
示例
text
You: /opsx:continue
AI: Change: add-dark-mode
Artifact status:
✓ proposal (已完成)
◆ specs (可创建)
◆ design (可创建)
○ tasks (被阻塞 - 依赖: specs)
Creating specs...
[读取 proposal.md,根据需求生成 specs]
✓ 已创建 openspec/changes/add-dark-mode/specs/ui/spec.md
下一步可用:tasks
运行 /opsx:continue 继续创建下一个工件使用提示(Tips)
- 适合逐步审查每个工件的场景
- 适用于复杂变更,需要更强控制力
- 多个工件可能同时变为可创建状态
- 创建后可以手动修改工件再继续执行
/opsx:ff
快速推进(fast-forward)工件创建流程,一次性生成所有规划阶段的工件。
语法
bash
/opsx:ff [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要快速推进的变更名称(若未提供则从上下文推断) |
功能说明
该命令会:
- 按依赖顺序创建所有工件(artifact)
- 使用 todo list 跟踪进度
- 在所有"可用于 apply 阶段"的工件完成后停止
- 在创建每个工件前读取其依赖内容作为上下文
示例
text
You: /opsx:ff add-dark-mode
AI: Fast-forwarding add-dark-mode...
✓ 创建 proposal.md
✓ 创建 specs/ui/spec.md
✓ 创建 design.md
✓ 创建 tasks.md
所有规划工件已完成!
已准备好进入实现阶段。运行 /opsx:apply 开始执行。使用提示(Tips)
- 适用于你已经清楚要构建内容的情况
- 比
/opsx:continue更快,适合结构清晰的需求 - 工件创建完成后仍然可以手动修改
- 适合中小型功能开发
/opsx:apply
根据 change 中的 tasks 执行实现工作,逐项推进任务列表,编写代码并标记完成项。
语法
bash
/opsx:apply [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要执行的变更名称(若未提供则从上下文推断) |
功能说明
该命令会:
- 读取
tasks.md并识别未完成任务 - 按顺序逐个执行任务
- 编写代码、创建文件、按需运行测试
- 在任务完成后打勾标记
[x]
示例
text
You: /opsx:apply
AI: 正在实现 add-dark-mode...
读取 tasks.md:
- [ ] 1.1 创建 ThemeContext
- [ ] 1.2 添加 CSS variables
- [ ] 1.3 实现 localStorage 持久化
正在执行 1.1:创建 ThemeContext...
[创建 src/context/ThemeContext.tsx]
✓ 1.1 完成
正在执行 1.2:添加 CSS variables...
[更新 src/styles/globals.css]
✓ 1.2 完成
...使用提示(Tips)
- 支持断点恢复(中断后可继续执行)
- 可通过指定 change name 并行处理多个变更
- 完成状态由
tasks.md中的勾选框记录
/opsx:verify
验证实现是否与 change 中的 artifacts 保持一致,检查完整性、正确性与一致性。
语法
bash
/opsx:verify [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要验证的变更名称(若未提供则从上下文推断) |
功能说明
该命令会:
- 从三个维度检查实现质量
- 在代码库中搜索实现证据
- 将问题分类为 CRITICAL / WARNING / SUGGESTION
- 不会阻止 archive,但会提示潜在问题
验证维度(Verification Dimensions)
| 维度 | 校验内容 |
|---|---|
| 完整性(Completeness) | 所有任务是否完成、所有需求是否实现、所有场景是否覆盖 |
| 正确性(Correctness) | 实现是否符合 spec 意图、边界情况是否处理 |
| 一致性(Coherence) | 设计是否在代码中体现、整体结构与模式是否一致 |
示例
text
You: /opsx:verify
AI: 正在验证 add-dark-mode...
COMPLETENESS(完整性)
✓ tasks.md 中所有 8 个任务已完成
✓ specs 中所有需求都有对应实现
⚠ 场景 "System preference detection" 未找到测试覆盖
CORRECTNESS(正确性)
✓ 实现符合 spec 意图
✓ 场景中的边界条件已处理
✓ 错误状态符合定义
COHERENCE(一致性)
✓ 设计决策已体现在代码结构中
✓ 命名规范与 design.md 一致
⚠ design.md 说明使用 "CSS variables",但实现使用的是 Tailwind classes
SUMMARY(总结)
─────────────────────────────
Critical issues: 0
Warnings: 2
Ready to archive: Yes(带警告)
建议:
1. 为 system preference detection 增加测试
2. 更新 design.md 或调整实现以统一技术方案使用提示(Tips)
- 建议在 archive 前执行,用于提前发现不一致问题
- warning 不会阻止归档,但表示潜在风险
- 非常适合在 AI 自动实现后做"审计"
- 可用于发现 artifacts 与真实代码之间的偏差
/opsx:sync
(可选命令)将 change 中的 delta specs 合并到主 specs 中。
通常 archive 会在需要时提示执行 sync,因此大多数情况下无需手动调用。
语法
bash
/opsx:sync [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要同步的变更名称(若未提供则从上下文推断) |
功能说明
该命令会:
- 读取 change 中的 delta specs
- 解析 ADDED / MODIFIED / REMOVED / RENAMED 结构
- 将变更合并到主
openspec/specs/目录 - 保留未被 delta 提及的已有内容
- 不会归档 change(仍保持 active 状态)
示例
text
You: /opsx:sync
AI: 正在同步 add-dark-mode 的 delta specs...
读取:
openspec/changes/add-dark-mode/specs/ui/spec.md
目标:
openspec/specs/ui/spec.md
将应用变更:
✓ ADDED: Theme Selection 需求(2 个场景)
✓ ADDED: Accessibility requirement(1 个场景)
正在合并...
✓ 已更新 openspec/specs/ui/spec.md
当前 change 仍处于 active 状态
完成后可运行 /opsx:archive何时需要手动使用(When to use manually)
| 场景 | 是否推荐 sync |
|---|---|
| 长周期变更,希望提前合并 spec | ✅ 推荐 |
| 多个并行变更,需要更新基础 spec | ✅ 推荐 |
| 想单独审查 merge 过程 | ✅ 推荐 |
| 简单功能,直接进入 archive | ❌ 不需要(archive 会处理) |
使用提示(Tips)
- sync 是"智能合并",不是简单 copy-paste
- 可以在不重复内容的情况下追加 scenario
- sync 后 change 仍然保持 active
- 多数用户不需要手动调用(archive 会自动提示)
/opsx:archive
归档一个已完成的变更(change)。该命令会最终完成变更,并将其移动到 archive 文件夹中。
语法
bash
/opsx:archive [change-name]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-name | 否 | 要归档的变更名称(若未提供则从上下文推断) |
功能说明
该命令会:
-
检查工件(artifact)完成状态
-
检查任务完成情况(若未完成会发出警告)
-
若尚未同步 delta spec,会提示是否执行 sync
-
将 change 文件夹移动至:
openspec/changes/archive/YYYY-MM-DD-<name>/ -
保留所有工件用于审计追踪(audit trail)
示例
text
You: /opsx:archive
AI: 正在归档 add-dark-mode...
工件状态:
✓ proposal.md 存在
✓ specs/ 存在
✓ design.md 存在
✓ tasks.md 存在(8/8 完成)
Delta specs:尚未同步
→ 是否现在同步?(推荐)
text
You: Yes
AI: ✓ 已同步 specs 到 openspec/specs/ui/spec.md
✓ 已移动到 openspec/changes/archive/2025-01-24-add-dark-mode/
归档成功使用提示(Tips)
- 即使任务未完成也不会阻止归档,但会发出警告
- delta spec 可以在归档前或归档过程中同步
- 已归档的 change 会完整保留用于历史追踪
- 建议先运行
/opsx:verify提前发现问题
/opsx:bulk-archive
批量归档多个已完成的 change,并处理不同 change 之间的 spec 冲突。
语法
bash
/opsx:bulk-archive [change-names...]参数
| 参数 | 是否必填 | 说明 |
|---|---|---|
| change-names | 否 | 要归档的变更列表(若未提供则提示选择) |
功能说明
该命令会:
- 列出所有已完成的 changes
- 在归档前逐个验证 change 状态
- 检测多个 change 之间的 spec 冲突
- 通过检查实际代码库解决冲突
- 按时间顺序进行归档
示例
text
You: /opsx:bulk-archive
AI: 找到 3 个已完成的 changes:
- add-dark-mode (8/8 tasks 完成)
- fix-login-bug (3/3 tasks 完成)
- update-footer (2/2 tasks 完成)
正在检查 spec 冲突...
⚠ add-dark-mode 与 update-footer 同时修改了 specs/ui/
正在分析代码库解决冲突...
两个变更均已实现,将按时间顺序合并:
1. add-dark-mode(创建于 Jan 20)
2. update-footer(创建于 Jan 22)
是否归档全部 3 个 changes?
text
You: Yes
AI: ✓ 已归档 add-dark-mode
✓ 已归档 fix-login-bug
✓ 已归档 update-footer
specs 合并顺序:
add-dark-mode → update-footer使用提示(Tips)
- 适合并行开发多个功能后的统一收尾
- 冲突解决是 agent 自动完成(基于代码库检查)
- 按创建时间顺序归档
- 在覆盖 spec 前会主动提示确认
/opsx:onboard
通过完整的 OpenSpec 工作流进行引导式上手体验。这是一个使用你真实代码库的交互式教程。
语法
bash
/opsx:onboard功能说明
该命令会:
- 以讲解方式完整演示一轮工作流循环
- 扫描你的代码库,寻找真实的改进机会
- 创建一个真实的 change(包含真实 artifacts)
- 执行实际开发工作(小型、安全的改动)
- 完成后归档该 change
- 在每个步骤发生时进行解释说明
执行阶段(Phases)
该流程包含以下阶段:
- 欢迎与代码库分析
- 寻找可优化点
- 创建 change(
/opsx:new) - 编写 proposal
- 创建 specs
- 编写 design
- 创建 tasks
- 执行任务(
/opsx:apply) - 验证实现
- 归档 change
- 总结与下一步建议
示例
text
You: /opsx:onboard
AI: 欢迎使用 OpenSpec!
我将带你完整走一遍工作流。
我们会从你的真实代码库中找一个小的优化点,
创建一个规范化 change,然后实现并归档。
正在扫描代码库...
[分析代码库]
我发现以下几个可改进点:
1. 为 contact 表单添加输入校验
2. 改进 auth 流程的错误提示
3. 为异步按钮添加 loading 状态
你对哪个感兴趣?(或者你也可以自己提一个)使用提示(Tips)
- 最适合新用户学习完整 workflow
- 使用真实代码,而不是示例项目
- 会生成一个真实 change(可保留或删除)
- 通常耗时 15--30 分钟
多语言指南(Multi-Language Guide)
配置 OpenSpec,使其可以生成除英文以外的其他语言工件。
在 openspec/config.yaml 中添加语言指令:
yaml
schema: spec-driven
context: |
Language: Portuguese (pt-BR)
All artifacts must be written in Brazilian Portuguese.
# 你的其他项目上下文写在下面...
Tech stack: TypeScript, React, Node.js配置完成后,所有生成的 artifacts 都将使用葡萄牙语(巴西版本)。
语言示例(Language Examples)
葡萄牙语(巴西)
yaml
context: |
Language: Portuguese (pt-BR)
All artifacts must be written in Brazilian Portuguese.西班牙语
yaml
context: |
Idioma: Español
Todos los artefactos deben escribirse en español.中文(简体)
yaml
context: |
语言:中文(简体)
所有产出物必须用简体中文撰写。日语
yaml
context: |
言語:日本語
すべての成果物は日本語で作成してください。法语
yaml
context: |
Langue : Français
Tous les artefacts doivent être rédigés en français.德语
yaml
context: |
Sprache: Deutsch
Alle Artefakte müssen auf Deutsch verfasst werden.使用建议(Tips)
处理技术术语(Handle Technical Terms)
你可以明确指定技术术语的处理方式:
yaml
context: |
Language: Japanese
Write in Japanese, but:
- Keep technical terms like "API", "REST", "GraphQL" in English
- Code examples and file paths remain in English与其他上下文组合使用(Combine with Other Context)
语言设置可以与其他项目配置共同生效:
yaml
schema: spec-driven
context: |
Language: Portuguese (pt-BR)
All artifacts must be written in Brazilian Portuguese.
Tech stack: TypeScript, React 18, Node.js 20
Database: PostgreSQL with Prisma ORM验证配置(Verification)
验证语言配置是否生效:
bash
# 查看生成指令,应包含语言上下文
openspec instructions proposal --change my-change输出结果中会包含你的语言设置内容。
引导教程
在claude code的界面输入/opsx:onboard,我们就可以进行官方提供的学习流程了,为了验证SDD的开发范式,我提前准备了一个agent的demo,我会在引导中逐步要求模型实现一个好看的GUI界面:
如果这里遇到无法运行openspec脚本的问题:
这是 Windows 的安全机制。RemoteSigned 策略允许运行你本地编写的脚本,是开发者的标准配置。
以 管理员身份 运行 PowerShell,输入以下命令并回车:
bash
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
然后退出claude,重新运行:/opsx:onboard !
首先,AI会读取当前项目,并且提出一些改进点,问我们对哪个比较感兴趣,我们可以选择其他,然后告诉AI我们的需求:
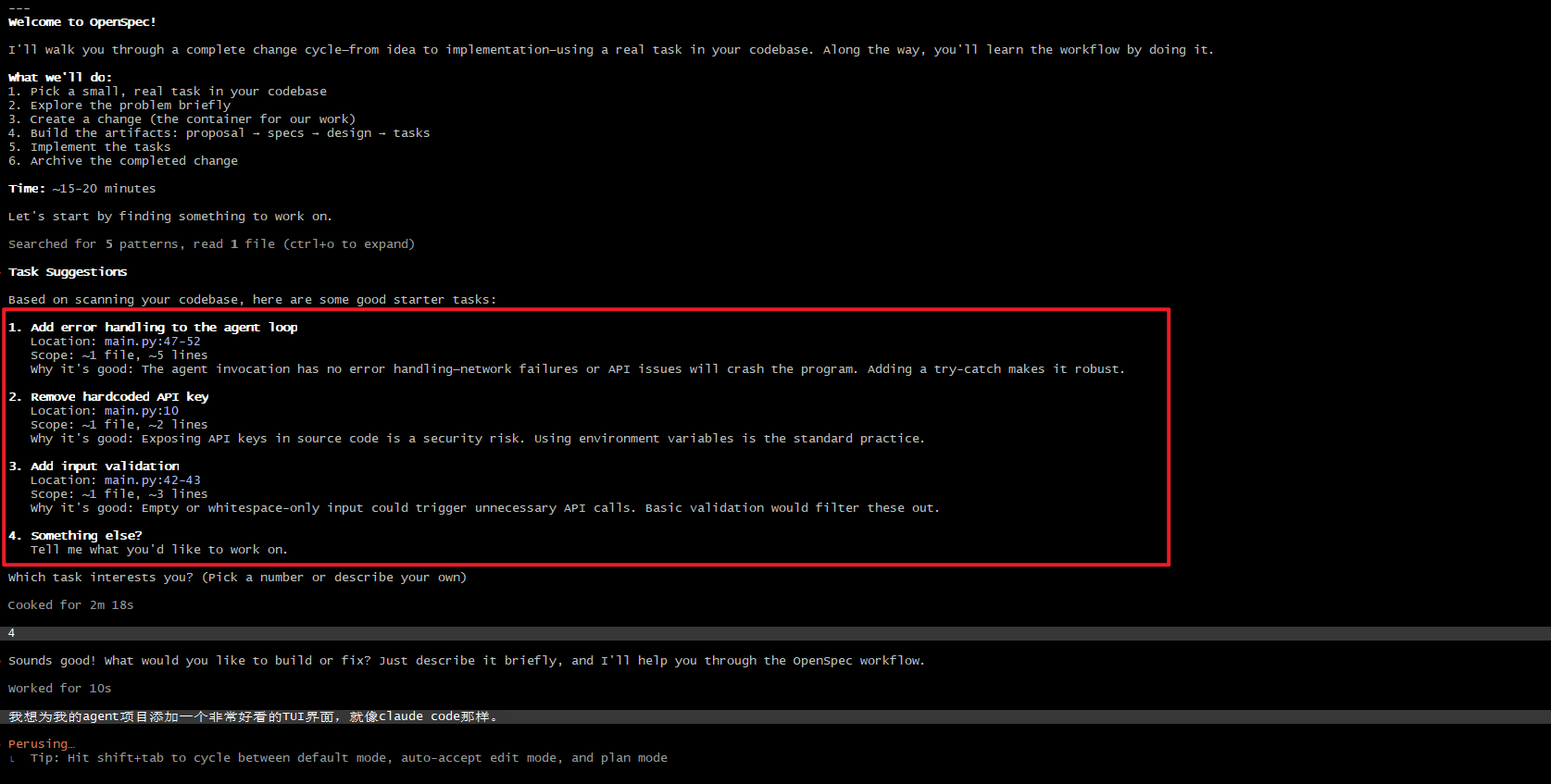
这里我选择了2,只改动建议的TODO:
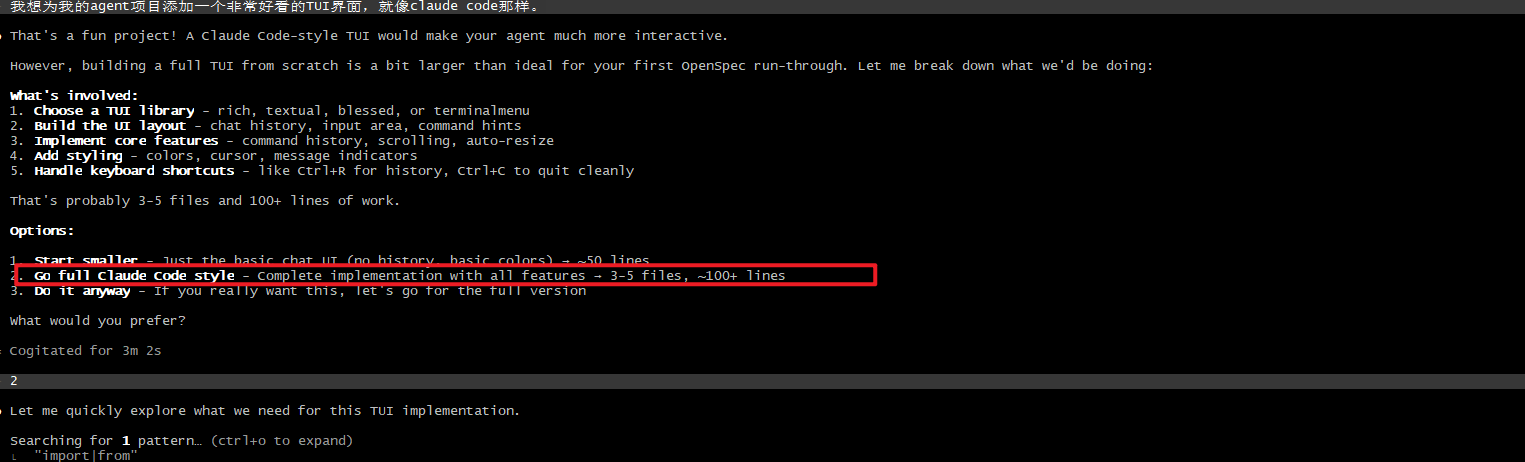
这里提示我们使用探索模式去决策具体需求(因为我们一开始的需求给的非常模糊,实现一个claude code TUI和实现一个淘宝没啥区别):
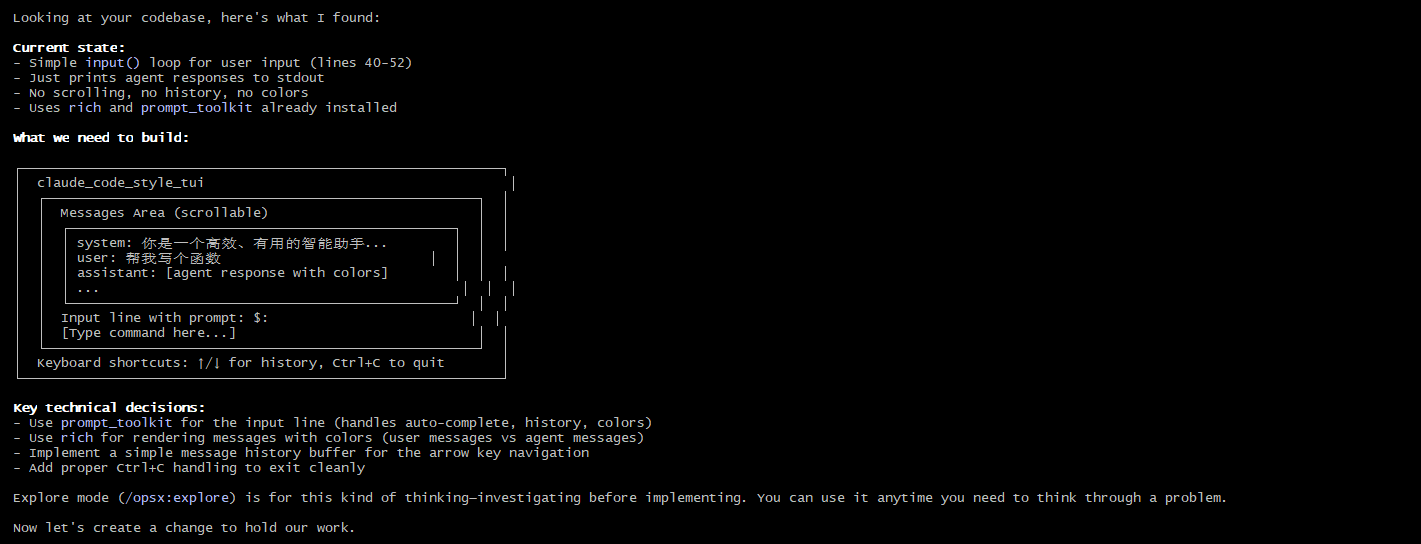
然后就是一些需求的问答探索,和普通对话一样:
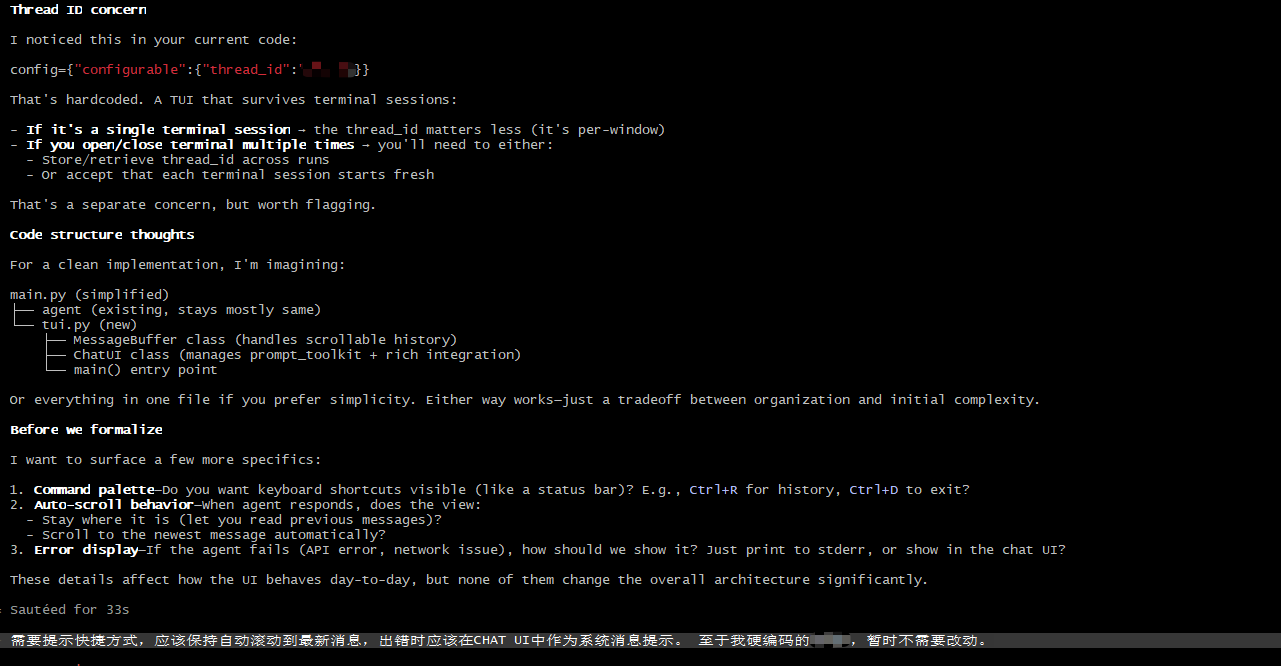
确认需求后,就会询问是否还有新的需求:
然后AI会自动帮我们执行/opsx命令,创建一系列文件,接下来我们就是回复一大堆工具的批准指令!(也许应该加载一个老板skill.md呢)
进入到我们的代码目录,已经可以看到自动生成的文件了,查看这些规格文件,我们可以发现,这是BDD的写法:
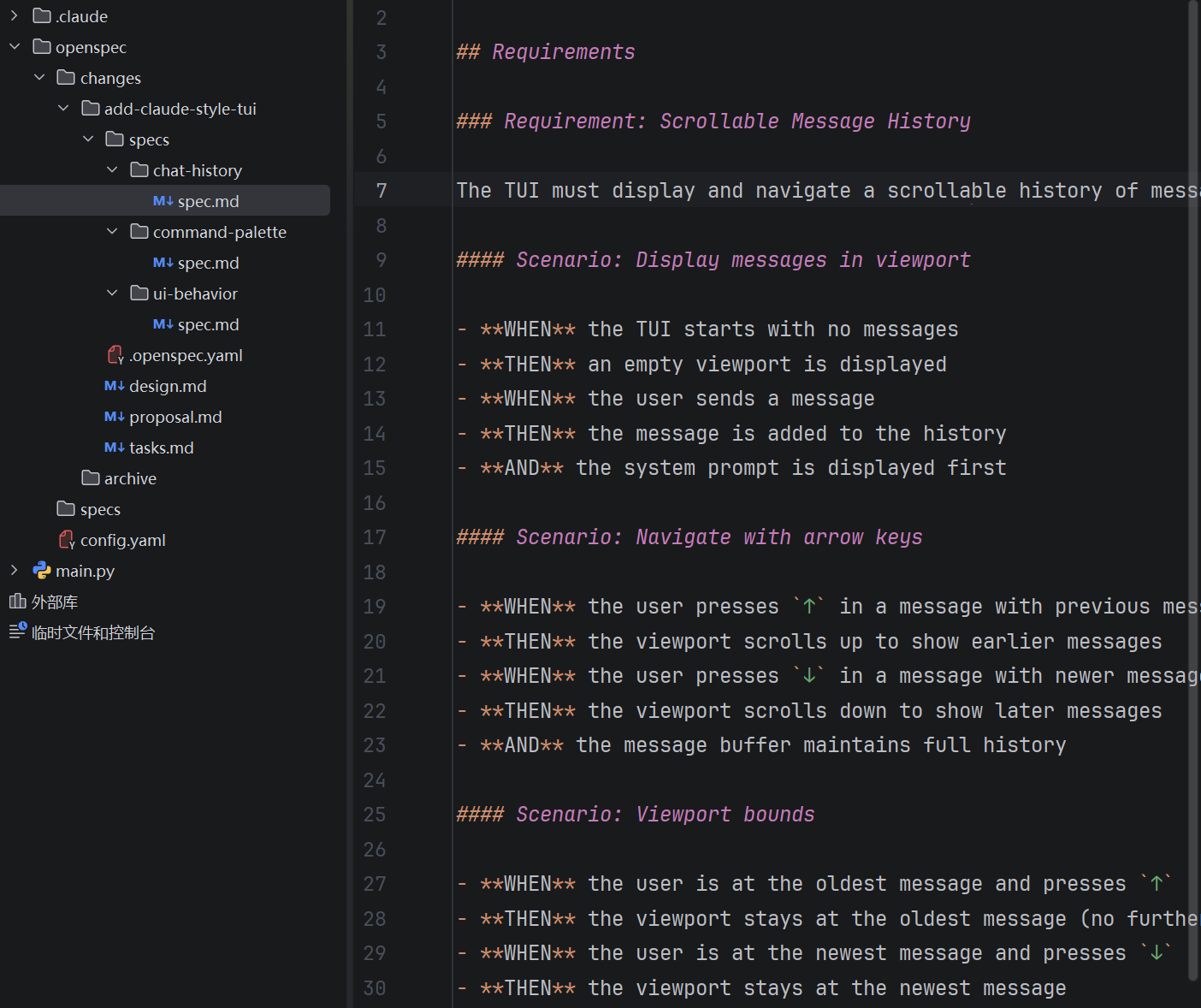
然后AI就会在sepc的约束下,更新代码,同时更新任务文件:
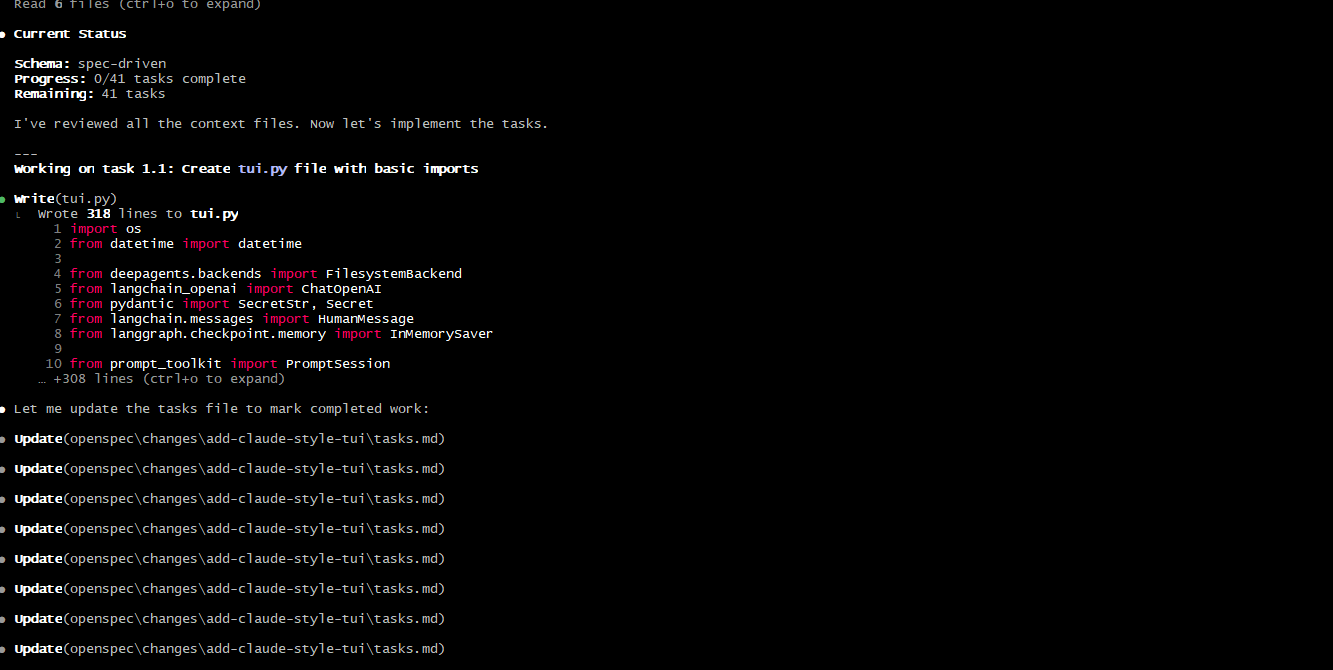
当需求已经实现后,AI会问我们是否存档,依旧yes即可:
然后就会询问我们是否进行TDD或者存档(这里都可以,如果先测试,之后就可以手动执行存档,这里我偷懒选择1,建议先测试,发现问题可以在一个变动中修复,不需要额外提一个fix):
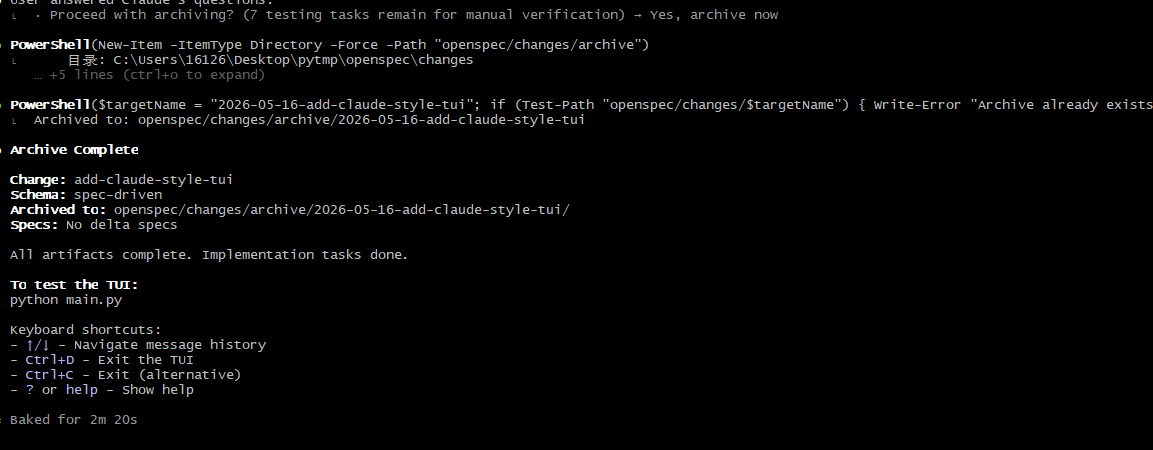
至此,我们的流程就已经走完了,然后AI会和你说已经归档完了,测试命令是python main.py你自己用着玩吧:
工作流(Workflows)
本指南介绍 OpenSpec 中常见的工作流模式,以及每种模式适用的场景。
传统工作流会强制你按照阶段推进:先规划,再实现,最后完成。但现实中的开发工作并不总是严格分段的。
OPSX 采用不同的方式:
c
### 传统方式(阶段锁定)
PLANNING ────────► IMPLEMENTING ────────► DONE
│ │
│ "不能回退" │
└────────────────────┘
### OPSX 方式(流动式动作)
proposal ──► specs ──► design ──► tasks ──► implement核心原则
-
动作,而不是阶段
命令是"你可以执行的动作",而不是"你必须停留的阶段"
-
依赖是能力,而不是限制
dependency 表示"你能做什么",而不是"你下一步必须做什么"
工作流模式(Expanded Mode Patterns)
⚡ 快速功能开发(Quick Feature)
当你已经明确要做什么,只需要执行时:
text
/opsx:new ──► /opsx:ff ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive示例对话
text
You: /opsx:new add-logout-button
AI: Created openspec/changes/add-logout-button/
Ready to create: proposal
text
You: /opsx:ff
AI: Creating all planning artifacts...
✓ proposal.md
✓ specs/
✓ design.md
✓ tasks.md
Ready for implementation!
text
You: /opsx:apply
AI: Working through tasks...
✓ 添加退出按钮到 header
✓ 实现 session 清理
✓ 添加确认弹窗
所有任务完成!
text
You: /opsx:archive
AI: ✓ 已合并 specs
✓ 已归档 change适用场景:
- 小型到中型功能开发
- bug 修复
- 结构清晰的改动
- 不需要复杂拆解的任务
探索式工作流(Exploratory)
当需求不清晰,或者你需要先调查再决定时:
text
/opsx:explore ──► /opsx:new ──► /opsx:continue ──► ... ──► /opsx:apply示例对话
text
You: /opsx:explore
AI: 你想探索什么?
text
You: 我想优化页面加载性能,但不确定瓶颈在哪里
text
AI: 我来帮你分析一下......
[分析 bundle 大小、慢查询、组件渲染模式]
我发现三个主要瓶颈:
1. 未优化的大型图片
2. ProductList 中的同步数据请求
3. context 变化导致的重复渲染
你想先解决哪个?
text
You: 先处理数据请求问题
text
You: /opsx:new optimize-product-list-fetching
AI: 已创建 change,准备生成 proposal
text
You: /opsx:continue
AI: 正在基于探索结果生成 proposal...
[将分析结果写入 proposal]
下一步可生成:specs、design
你想先做哪个?
text
You: /opsx:continue
AI: 正在生成 specs...适用场景:
- 性能优化
- bug 排查
- 架构决策
- 需求不明确的任务
并行开发(Parallel Changes)
可以同时处理多个变更:
text
Change A: /opsx:new ──► /opsx:ff ──► /opsx:apply (进行中)
│
切换上下文
│
Change B: /opsx:new ──► /opsx:ff ──► /opsx:apply示例对话:
text
You: 我正在做 add-dark-mode,但突然要修一个 bug
text
You: /opsx:new fix-login-redirect
AI: 已创建 openspec/changes/fix-login-redirect/
text
You: /opsx:ff
AI: ✓ 已生成全部 planning artifacts
text
You: /opsx:apply
AI: 正在修复 fix-login-redirect...
✓ 已完成所有任务
text
You: /opsx:archive
AI: ✓ 已归档 fix-login-redirect
text
You: 回到 dark mode
text
You: /opsx:apply add-dark-mode
AI: 正在恢复 add-dark-mode...
从 task 2.3 继续:更新 Header...适用场景:
- 并行任务流
- 紧急插入的 bug 修复
- 团队协作中断处理
当有多个已完成的变更时:
text
You: /opsx:bulk-archive
text
AI: 找到 3 个已完成变更:
- add-dark-mode
- fix-login-redirect
- update-footer
text
检查 spec 冲突中...
⚠ add-dark-mode 与 update-footer 同时修改 specs/ui/
text
检查代码实现...
两者都已正确实现,将按时间顺序合并
text
是否归档全部变更?
text
You: Yes
AI: ✓ 已归档 add-dark-mode
✓ 已归档 fix-login-redirect
✓ 已归档 update-footer
已按顺序合并 specsbulk-archive 的能力:
- 自动检测多个变更是否修改同一 spec
- 自动检查实际代码实现状态
- 按时间顺序合并冲突
- 避免手动合并冲突错误
完成一个变更(Completing a Change)
推荐的完成流程:
text
/opsx:apply ──► /opsx:verify ──► /opsx:archive
│ │
验证实现是否正确 如有需要提示同步Verify:检查你的工作
/opsx:verify 会从三个维度验证实现是否符合你的 artifacts:
text
You: /opsx:verify
AI: 正在验证 add-auth...验证结果示例
text
COMPLETENESS
✓ tasks.md 中 12/12 个任务已完成
✓ 所有 specs 需求都有对应实现
⚠ "Session timeout after inactivity" 场景未测试
text
CORRECTNESS
✓ 实现符合 spec 意图
✓ 覆盖了场景中的边界情况
✓ 错误状态符合 spec 定义
text
COHERENCE
✓ 代码结构符合设计决策
✓ 命名规范与 design.md 一致
⚠ design 中提到"event-driven",但实现使用 polling
## 总结
Critical issues: 0
Warnings: 2
Ready to archive: Yes (with warnings)
1. 添加 session timeout 的测试
2. 要么改成 event-driven 实现,要么更新 design.mdVerify 检查什么?
| 维度 | 检查内容 |
|---|---|
| Completeness | 所有任务是否完成、需求是否实现、场景是否覆盖 |
| Correctness | 实现是否符合 spec 意图、是否处理边界情况 |
| Coherence | 设计是否在代码中得到一致体现 |
Verify 的特点:
- ❌ 不会阻止 archive
- ⚠️ 但会提示潜在问题
- ✅ 用于在归档前做质量检查
Archive:完成变更,/opsx:archive 用于最终完成并归档:
text
You: /opsx:archive
text
AI: 正在归档 add-auth...状态检查:
text
Artifact 状态:
✓ proposal.md 存在
✓ specs/ 存在
✓ design.md 存在
✓ tasks.md 存在(12/12 完成)Delta specs 状态:
text
Delta specs: 尚未同步到主 specs
→ 是否现在同步?
text
You: Yes
完成归档
✓ 已同步到 openspec/specs/auth/spec.md
✓ 已移动到 openspec/changes/archive/2025-01-24-add-auth/最终说明:
- archive 之前如果没 sync,会提示你
- 不会因为任务不完整而阻止归档,但会警告
- archive 是"最终确认变更已结束"的动作
什么时候用哪个(When to Use What)
/opsx:ff vs /opsx:continue
| 情况 | 使用命令 |
|---|---|
| 需求清晰,准备直接实现 | /opsx:ff |
| 仍在探索,需要逐步查看每一步 | /opsx:continue |
| 想在生成 specs 前反复调整 proposal | /opsx:continue |
| 时间紧张,需要快速推进 | /opsx:ff |
| 复杂变更,希望掌控每一步 | /opsx:continue |
经验法则(Rule of thumb):
如果你能一次性描述完整范围:
👉 用
/opsx:ff
如果你是在逐步理解问题:
👉 用
/opsx:continue
什么时候"更新变更" vs "重新创建"
一个常见问题是:
什么时候可以在原 change 上继续改?什么时候应该新建?
更新已有 change 的情况:
适用于:
- ✔ 意图没变,只是实现方式更精细
- ✔ scope 收缩(比如先做 MVP)
- ✔ 过程中发现代码实际情况不同,需要修正
- ✔ 基于实现反馈调整设计
新建 change 的情况:
适用于:
- ❌ 核心目标已经变了
- ❌ scope 膨胀成完全不同的任务
- ❌ 原 change 已经可以独立完成并归档
- ❌ 继续修改只会让结构更混乱
决策逻辑图:
text
┌─────────────────────────────────────┐
│ 这是同一个工作吗? │
└──────────────┬──────────────────────┘
│
┌──────────────────┼──────────────────┐
│ │ │
▼ ▼ ▼
是否同一意图? 是否 >50% 重叠? 原任务是否能独立完成?
│ │ │
┌────────┴────────┐ ┌──────┴──────┐ ┌───────┴───────┐
│ │ │ │ │ │
YES NO YES NO NO YES
│ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼
UPDATE NEW UPDATE NEW UPDATE NEW示例:Add Dark Mode:
❌ 变成新变更
"需要支持自定义主题系统"
👉 scope 已经扩展成新功能
✔ 更新原变更
"系统偏好检测比预期更复杂"
👉 还是同一个问题,只是实现更难
✔ 先更新再拆分
"先做 toggle,偏好系统以后再做"
👉 先 update 当前 change → 完成 → archive → 再开新 change
总结一句话:
- ff:你已经知道要做什么
- continue:你还在搞清楚要做什么
- update:同一个问题在演进
- new:已经是另一个问题了
最佳实践(Best Practices)
保持变更的聚焦(Keep Changes Focused)
每个 change 只应该对应一个逻辑完整的工作单元。
如果你在做类似:
"新增功能 X + 同时重构 Y"
建议拆成两个独立的 change。
为什么这样更好?
- 更容易 review 和理解
- archive 历史更清晰
- 可以独立发布(ship independently)
- 如果需要回滚更简单
对不清晰需求使用 /opsx:explore
在创建 change 之前,先用 explore 理清问题空间:
text
You: /opsx:explore
text
AI: 你想探索什么?
text
You: 我们应该如何做 API 限流?
text
AI: 我来帮你分析当前系统和可选方案...
[分析代码结构和设计模式]
我看到三种方案:
1. 中间件方式(简单,按 endpoint)
2. Redis 方案(可扩展,共享状态)
3. token bucket(更公平,但复杂)
你现在的系统更适合 #1 或 #2,你的规模如何?👉 exploration 的作用是:在生成 artifacts 前先理清思路
在归档前使用 /opsx:verify
用 verify 检查实现是否符合 spec:
text
You: /opsx:verify
text
AI: 正在验证 add-dark-mode...
text
✓ tasks 已全部完成
✓ specs 中的需求都有对应代码
✓ design 决策已正确实现
准备归档!👉 用于在关闭 change 前发现问题
给 change 起清晰的名字
好的命名会让 openspec list 更有用:
| 好的命名 | 不好的命名 |
|---|---|
| add-dark-mode | feature-1 |
| fix-login-redirect | update |
| optimize-product-query | changes |
| implement-2fa | wip |
结尾
关于 OpenSpec 的概念性内容,可以直接参考官方仓库文档:
- Concepts:https://github.com/Fission-AI/OpenSpec/blob/main/docs/concepts.md
- Customization:https://github.com/Fission-AI/OpenSpec/blob/main/docs/customization.md
如果现有流程不完全匹配你的项目需求,也可以基于 Customization 文档做进一步的子定制。
OpenSpec 以及类似的开源工具,本质上是在"工程化落地" BDD / SDD / TDD 这些方法论。
它做的事情并不神秘,甚至可以理解为一种"结构化提示工程":
我们都知道设计模式,也知道它们是好东西,但在实际写代码的时候,很多人并不会系统性地去应用。于是有人把设计模式、软件工程方法论整理成结构化流程,再包装成一套可以被 AI 执行的命令系统,比如 /设计模式 或 /opsx:apply 这样的接口。
这样一来,AI 不再是"随便写代码",而是被引导去"按工程规范逐步生成系统"。
从本质上讲,这是一个非常典型的 trade-off:
用 token 交换工程质量与可控性。
如果不使用 SDD,直接让 Claude Code 或其他模型"实现一个淘宝",结果往往是:
- 功能边界模糊
- 架构混乱
- 后期难以维护
- token 消耗还很高,但产出不可控
而如果引入 SDD / BDD 流程,模型的行为会被逐步约束:
比如:
- 先定义需求:用户点击支付会发生什么(BDD)
- 再拆解系统行为:支付状态流转、失败重试机制
- 再落到设计:接口、模块、数据结构
- 最后才是任务执行
最终产物可能只是一个"商品 CRUD + 支付系统"的雏形,但它是结构清晰、可扩展、可验证的,而不是一坨堆出来的 demo。
当然,这一切成立的前提是:
- 你有足够的 token 预算
- 你使用的是足够强的模型(例如 GPT-4o / Claude Opus 级别)
- 或至少是具备较强规划能力的 coding model
如果换成一些能力较弱的模型(比如某些轻量级 flash / 低参数模型),SDD 的收益会被明显放大,因为它本质是在"降低模型自由度",减少发散。
但反过来,如果模型本身很强,即使是简单的 plan → act 模式,也能得到不错的结果。
现实情况是比较割裂的:
很多企业一方面在谈"AI 提效",另一方面又不愿意为 token 和模型能力付费,甚至希望用低成本模型(例如小参数 Qwen / 蒸馏模型)完成复杂研发任务。
这种情况下,本质上就是:
想要 AI 的结果,但不愿意为 AI 的能力买单。
总结一句话:
在同等模型能力下,引入 BDD + SDD + TDD 这类结构化工程方法,基本一定会提升最终产出质量。
它不是银弹,但它确实是在"让 AI 更像工程师,而不是随机生成器"。
仅此而已。