****论文题目:****TOKEN STATISTICS TRANSFORMER: LINEAR-TIME ATTENTION VIA VARIATIONAL RATE REDUCTION(令牌统计数据转换器:通过降低变分率实现线性时间关注)
会议:ICLR2025
****摘要:****注意算子可以说是变压器架构的关键区别因素,它已经在各种任务中展示了最先进的性能。然而,变压器注意算子通常会带来很大的计算负担,其计算复杂度随着令牌的数量呈二次增长。在这项工作中,我们提出了一种新的变压器注意算子,其计算复杂度与令牌的数量呈线性增长。我们通过扩展先前的工作推导出我们的网络架构,该工作表明变压器风格的架构自然地由"白盒"架构设计产生,其中网络的每一层都被设计为实现最大编码率降低目标(MCR2)的增量优化步骤。具体来说,我们推导了一种新的MCR2目标的变分形式,并表明由该变分目标的展开梯度下降产生的架构导致了一个新的注意力模块,称为令牌统计自注意力机制(TSSA)。TSSA具有线性计算和记忆复杂性,并且从根本上背离了计算标记之间成对相似性的典型注意力架构。在视觉、语言和长序列任务上的实验表明,简单地将TSSA交换为标准的自注意力机制(我们称之为令牌统计转换器(TOST)),可以实现与传统转换器竞争的性能,同时显著提高计算效率和可解释性。我们的结果也在一定程度上质疑了传统的观点,即两两相似风格的注意机制对变压器架构的成功至关重要。
Token Statistics Transformer(ToST):用线性注意力颠覆 Transformer 的认知
一、Transformer 的"阿喀琉斯之踵"
自 Vaswani 等人 2017 年提出"Attention is All You Need"以来,Transformer 已经统治了从自然语言处理到计算机视觉、时间序列预测的几乎所有领域。其核心------自注意力(Self-Attention)------允许序列中任意两个位置直接交互,捕捉全局依赖关系。
然而,标准自注意力有一个无法回避的代价:它需要计算所有 token 对之间的相似度 (即缩放点积),导致计算复杂度和内存复杂度均为 O(n²),其中 n 为 token 数量。当序列长度翻倍,计算量变为原来的四倍;处理 10,000 个 token 时,所需内存是处理 1,000 个 token 的 100 倍。
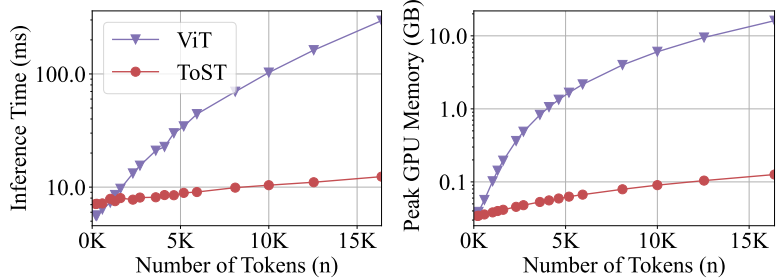
📊 【此处配图 Figure 1】
图1展示了 ToST 与 ViT 在推理时间和 GPU 显存上的对比(log 坐标轴)。随 token 数增加,ViT 的曲线急剧攀升,而 ToST 几乎保持线性增长。
面对这一瓶颈,学术界提出了诸多缓解方案:
- Longformer / BigBird:对 token 分组或使用滑动窗口,只在局部范围内计算注意力;
- Linformer:对 token 做低秩投影后再计算相似度;
- Nystromformer:用 Nyström 扩展近似全局注意力矩阵;
- XCiT:改为在特征通道维度上计算点积,将复杂度降为 O(p²n)。
这些方法的共同逻辑是:承认 pairwise 相似度是必须的,只是想算得更快或更省内存。
本文作者提出了一个更激进的问题:计算 token 之间的两两相似度,真的是 Transformer 成功的根本原因吗? 答案可能是否定的。
二、从数学原理出发的"白盒"设计
2.1 MCR² 目标函数
理解本文的出发点,需要先了解**最大编码率压缩(Maximal Coding Rate Reduction,MCR²)**原则。
MCR² 的核心思想是:好的特征表示应当同时满足两个目标:
- 扩张(Expansion):所有 token 的特征整体尽量"铺展开",占据更大的空间;
- 压缩(Compression):同一语义组内的 token 特征尽量"聚拢",落在低维子空间中。
用公式表达为:
其中 是扩张项,
是压缩项,
是 token 到各语义组的软归属矩阵。
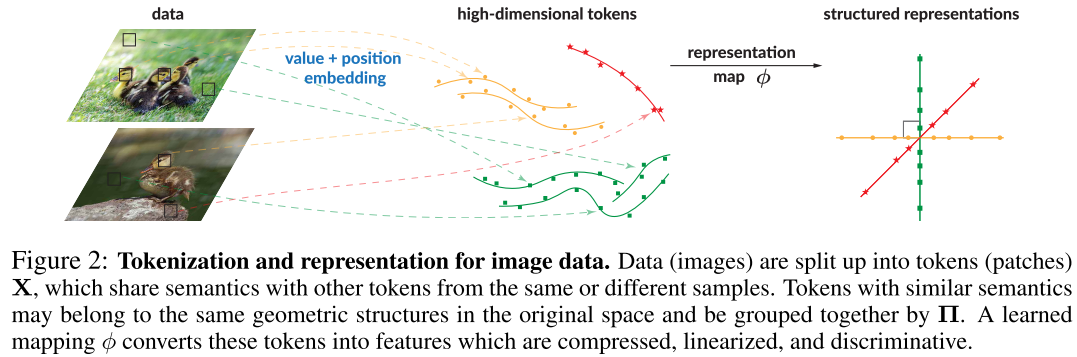
📊 【此处配图 Figure 2】
图2直观展示了从原始图像数据到结构化特征表示的过程:图像被切分为 patch token,语义相近的 patch 被分配到同一组(Π),经过映射 φ 后,同组 token 落在相互正交的低维子空间中。
Yu 等人(CRATE,2024)已经证明,对 MCR² 目标的压缩项 做梯度下降展开,自然地导出了多头自注意力算子。也就是说,Transformer 的自注意力本质上是在优化一个特征压缩目标。但 CRATE 的注意力结构与标准 Transformer 几乎相同,依然是 O(n²) 复杂度。
2.2 一个全新的变分定理
本文的核心数学贡献是 Theorem 1(及其推广形式 Theorem 2):
Theorem 1 :设
非递减、凹且
这个定理的威力在于:它将原本需要计算大矩阵完整谱 的目标函数,转化为只需计算矩阵乘积对角元的变分上界。大矩阵的谱计算是 O(n³) 的,而对角元的计算可以做到线性。
基于此,论文将压缩项 改写为变分形式:
其中 是每个注意力头的投影矩阵。
三、Token Statistics Self-Attention(TSSA)的推导
3.1 对变分目标做梯度下降
对变分压缩目标 关于第 j 个 token
求梯度,并做一步梯度下降(步长 τ),得到:
其中对角矩阵 的每个元素是投影 token 二阶矩统计量的非线性变换。
这就是 TSSA 算子的核心:
3.2 语义直觉
每个注意力头的操作可以理解为:
- 将 token 特征投影到子空间
- 在投影空间中,计算各方向上 token 的二阶矩(类似"能量");
- 对能量大的方向(即与当前组 token 高度对齐的方向)保留 ,对能量小的方向抑制;
- 再投影回原始空间(乘以
这与标准自注意力的根本区别在于:标准注意力通过 query-key 点积衡量"这两个 token 有多相似";而 TSSA 通过二阶矩统计量衡量"这个方向上 token 整体有多少能量"。前者需要 O(n²) 的 pairwise 计算,后者只需 O(pn)。
3.3 token 归属矩阵 Π 的估计
TSSA 需要知道每个 token 属于哪个子空间(即 Π 矩阵)。论文假设 token 服从低维高斯混合模型,推导出:
即通过 softmax 将 token 归属到与其投影范数最大的子空间,η 是可学习的温度参数。
3.4 复杂度分析

📊 【此处配表 Table 1】
表1对比了 ViT、CRATE、XCiT 和 ToST 各自注意力模块的时间与空间复杂度。
ToST 在时间和空间上均是渐近最优的,且同时在 n 和 p 两个维度上都优于其他方法。
四、ToST 架构总览
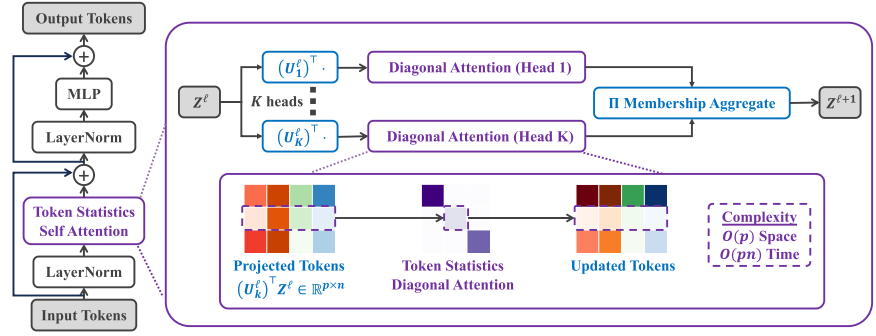
📊 【此处配图 Figure 3】
图3展示了 ToST 一个 Transformer block 的完整结构:输入 token 经过 LayerNorm → TSSA → 残差连接 → LayerNorm → MLP → 残差连接,输出到下一层。TSSA 内部展示了 K 个 diagonal attention head 的并行计算和 Π membership aggregation 过程,并标注了 O(p) 空间和 O(pn) 时间复杂度。
整体架构中,ToST 继承了 XCiT 的大部分非注意力设计选择(去除了 Local Patch Interaction 模块以符合理论推导),将 XCiT 的注意力算子替换为 TSSA。对于语言模型任务,则继承 GPT-2 框架并引入因果版本的 TSSA(通过 cumsum 操作实现因果掩码)。
五、实验结果
5.1 TSSA 是否真的在优化其设计目标?
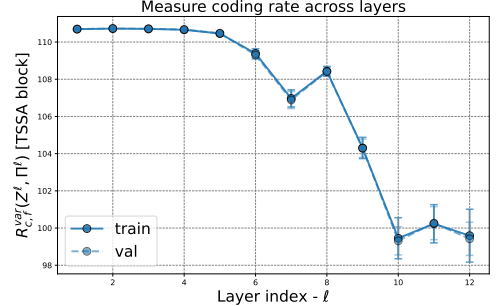
📊 【此处配图 Figure 4(左图)】
图4左图展示了变分压缩目标
实验表明,ToST-S 模型在训练和验证集上,压缩目标值随层数单调递减(仅在最后几层略有波动),说明每一层的 TSSA 算子确实在量化地优化其理论设计目标。这是白盒设计区别于黑盒神经网络的独特优势------网络行为可被精确追踪和解释。

📊 【此处配图 Figure 4(右图)】
图4右图可视化了 Π 矩阵(membership matrix)。对于每张输入图像,将 Π 的每一列 reshape 为图像大小,可以看到前景物体的 patch 被聚类到同一子空间,背景被归为另一类------ToST 在没有任何分割标注的情况下,自动学到了语义分割能力。
5.2 视觉分类:ImageNet-1k 及迁移学习
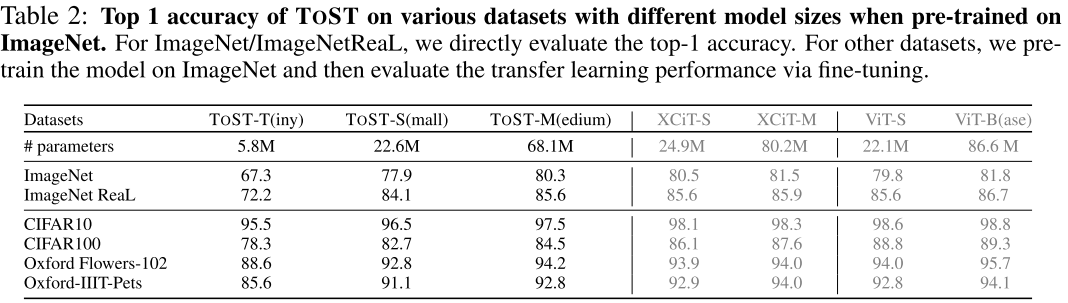
📊 【此处配表 Table 2】
表2汇报了 ToST 在 ImageNet-1k 上的 Top-1 精度,以及在 CIFAR-10/100、Oxford Flowers-102、Oxford-IIIT-Pets 上的迁移学习性能,并与 XCiT、ViT 系列做对比。
关键数据:
- ToST-M(68.1M 参数) 在 ImageNet 上达到 80.3%,接近 XCiT-S(80.5%,24.9M)和 ViT-B(81.8%,86.6M);
- ToST-S(22.6M) ImageNet 77.9%,ImageNet ReaL 84.1%,均与参数量相当的 XCiT-S 和 ViT-S 竞争;
- 随着模型规模增大(T→S→M),ToST 与其他架构的性能差距持续缩小,显示出良好的规模扩展性;
- 在迁移学习任务上,ToST-M 在 Oxford Flowers-102(94.2%)和 Oxford-IIIT-Pets(92.8%)上与 XCiT-S(93.9%/92.9%)非常接近。

📊 【此处配图 Figure 5】
图5对比了 ToST-S、XCiT-S 和 ViT-S 的 CLS token 注意力图可视化。ToST 的注意力图能更清晰地突出前景物体,呈现出更有意义的语义分割效果,优于 XCiT 和 ViT。
5.3 长序列建模:Long-Range Arena(LRA)
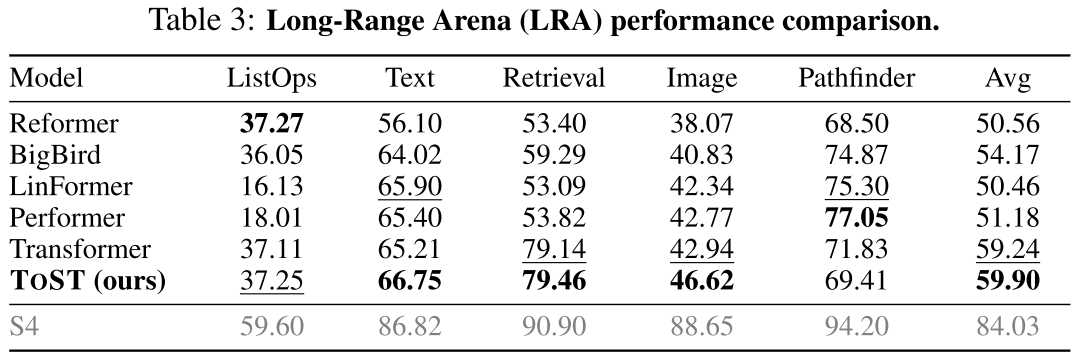
📊 【此处配表 Table 3】
表3展示了 ToST 与 Reformer、BigBird、LinFormer、Performer、标准 Transformer 以及 S4 在 LRA 基准5个子任务(ListOps、Text、Retrieval、Image、Pathfinder)上的性能对比。
结果显示:
- ToST 在5项任务的平均分为 59.90,高于标准 Transformer(59.24)以及所有其他 efficient transformer 变体(最高的 BigBird 也只有 54.17);
- ToST 在 Text(66.75)、Retrieval(79.46)、Image(46.62)三项任务上均超过标准 Transformer;
- 唯一被超越的是以 S4 为代表的状态空间模型(平均 84.03),但 S4 属于完全不同的模型类别(非 Transformer 架构),在 LRA 上本就处于领先地位。
这一结果尤其令人印象深刻------线性复杂度的 TSSA 在长序列任务上不仅没有退步,反而比标准 O(n²) 注意力表现更好,验证了摆脱 pairwise 相似度计算的可行性。
5.4 因果语言模型:与 GPT-2 对比
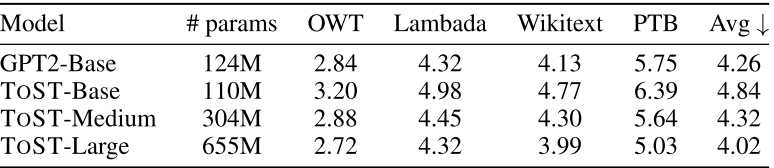
📊 【此处配表 Table 4(左)】
表4左侧汇报了 GPT2-Base 与不同规模 ToST 在 OWT、Lambada、Wikitext、PTB 四个数据集上的 zero-shot 交叉熵损失(越低越好)。
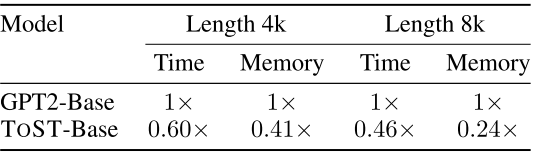
📊 【此处配表 Table 4(右)】
表4右侧汇报了在序列长度 4k 和 8k 下,ToST-Base 相对 GPT2-Base 的时间和内存相对开销。
核心数据:
- ToST-Large(655M) 平均损失 4.02,优于 GPT2-Base(4.26,124M),仅用参数量约 5 倍的代价换来了更好性能;
- 即使是参数更少的 ToST-Base(110M),平均损失 4.84,与 GPT2-Base 的差距在合理范围内,且尚未做超参数调优;
- 效率优势显著 :在 8k 序列长度下,ToST-Base 只需 GPT2-Base 46% 的推理时间 和 24% 的 GPU 内存;
- 随着模型扩大(Base→Medium→Large),ToST 的语言建模损失稳定下降,显示良好的规模扩展性。
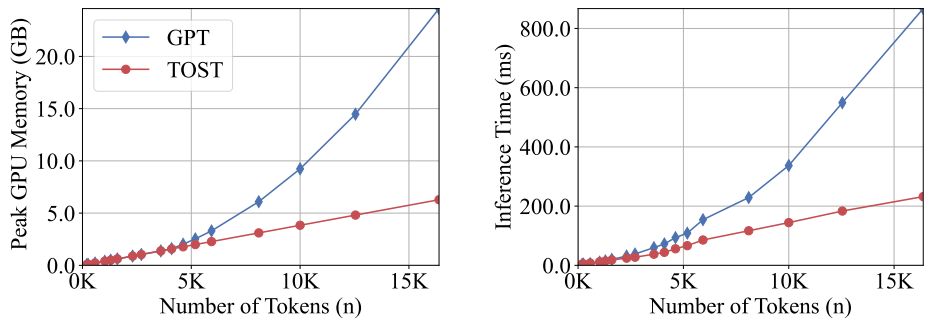
📊 【此处配图 Figure 8】
图8展示了 Causal-ToST 与 GPT-2 在自回归生成任务中的显存占用和推理时间对比,ToST 在所有 token 长度下均大幅占优。
5.5 计算效率的量化对比
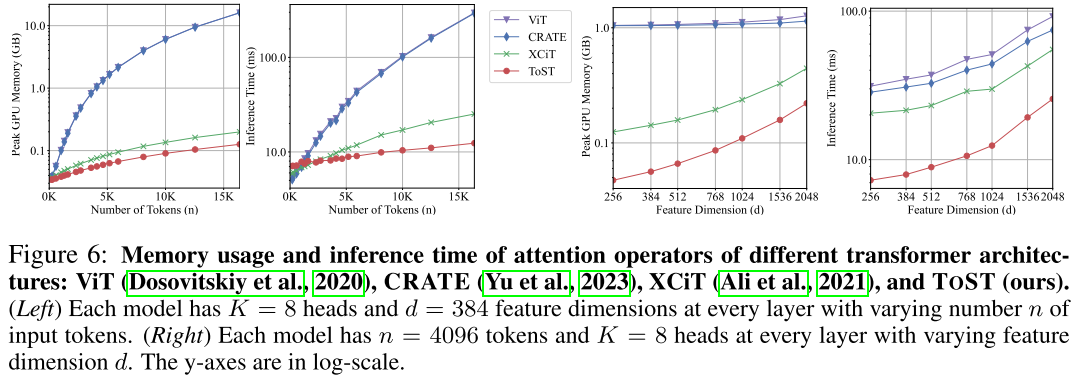
📊 【此处配图 Figure 6】
图6(4张子图)展示了在固定 K=8 heads 条件下,随 token 数 n 变化(左两图)和随特征维度 d 变化(右两图)的 GPU 显存与推理时间对比(log 坐标轴,涵盖 ViT、CRATE、XCiT、ToST)。
关键数字(均在 log 坐标下读出,以 10k token 为例):
- ToST 比 ViT 推理速度快约 10 倍;
- ToST 比 ViT 显存占用少约 100 倍;
- 相比之下,XCiT 虽然优于 ViT,但仍远逊于 ToST。
六、消融实验与设计选择
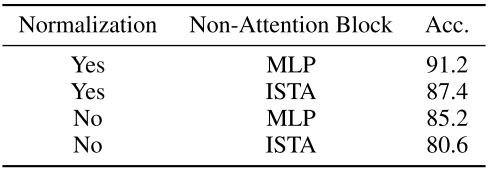
📊 【此处配表 Table 8】
表8展示了 ℓ₂ 归一化和非注意力模块(MLP vs. ISTA)两个设计选项的消融结果(CIFAR-10,400 epochs,ToST-S)。
| 归一化 | 非注意力模块 | 准确率 |
|---|---|---|
| ✅ | MLP | 91.2% |
| ✅ | ISTA | 87.4% |
| ❌ | MLP | 85.2% |
| ❌ | ISTA | 80.6% |
两个关键发现:
- 在计算 Π 时对投影 token 做 ℓ₂ 归一化(沿特征维度对每行归一化)对训练稳定性和最终性能影响巨大,去掉后准确率下降近 6 个百分点;
- 使用 MLP(而非 CRATE 中的 ISTA 稀疏促进块)更适合 ToST,这与 CRATE 的设计经验不同,表明 TSSA 与 MLP 的组合比 TSSA 与 ISTA 的组合更加协同。
七、可解释性:可视化学到的子空间

📊 【此处配图 Figure 11】
图11可视化了 TOST-S 不同层的 TSSA 块中学到的投影矩阵
从第 1 层到第 10 层,可以观察到矩阵越来越接近块对角结构,说明不同注意力头的子空间逐渐变得近似正交(不相关),与 MCR² 理论预测的最优几何结构(各组特征落在正交子空间)高度吻合。这是黑盒模型无法提供的深层可解释性。
八、局限性与未来方向
论文作者坦诚地指出了当前工作的局限:
- 规模验证不足:目前仅在 ImageNet-1k(中等规模)上验证,尚未在超大规模数据集(如 ImageNet-21k、LAION)或更大模型(如 GPT-3 级别)上测试,线性注意力是否能在极大规模下保持竞争力尚待验证;
- MLP 块未优化:本文专注于改进注意力模块,MLP 模块沿用标准设计。初步消融实验表明 ISTA 块对 ToST 并不适合,设计更高效、更白盒的 MLP 替代品是未来方向;
- 超参数调优有限:语言建模实验中,所有 ToST 规模均沿用 GPT-2 的超参数,未做针对性调优,这在一定程度上低估了 ToST 的真实潜力。
九、总结与意义
ToST(Token Statistics Transformer)这篇论文的贡献不仅仅是提出了一个更快的注意力模块,它在更深层次上挑战了一个长久以来被默认为真理的假设:Transformer 的成功依赖于计算 token 对之间的 pairwise 相似度。
ToST 的核心洞见是:注意力机制的本质是对 token 特征进行数据相关的低秩压缩 ,而实现这种压缩并不需要 pairwise 相似度------只需要二阶矩统计量即可,且后者可在线性时间内计算。
从数学角度看,这一结论来自对 MCR² 目标函数的一个新颖变分分解(Theorem 1),本身具有独立的数学价值,可能对其他谱函数优化问题也有启发。
实验结果表明,简单地用 TSSA 替换标准自注意力,在视觉、语言、长序列三类任务上均能维持甚至超越原有性能,而推理速度和内存效率大幅提升(10k token 时快约 10 倍、省约 100 倍内存)。
在大模型时代,序列长度和模型规模不断攀升,O(n²) 的注意力已越来越成为瓶颈。ToST 提供了一条从数学原理出发 、兼具效率与可解释性的新路径,值得关注。