1. 背景
2024年10月中旬公司打算切换美股行情数据源,在此之前使用的是Polygon(已改名为Massive),Polygon的优点有两个:1.价格便宜,每月2000$ 2.接入简单,通过ws和rest接口即可获取所有数据,无需接入方自己计算和存储数据。缺点是数据不准,经常出现和业内主流券商对不上的情况,以AAPL为例, 其它券商展示价格是298.55,我们平台展示298.43。在金融领域,数据是核心基础,数据不准,其它一切搞的再好都是白搭,因为用户不会信任,长此以往,用户自然流失。在此背景下,公司决定从业内顶级数据供应商伦敦交易所集团(LSEG)采购数据,LSEG数据的优点有两个:1.数据实时性强 2.数据准确性高,缺点也有两个:1. 成本高,几倍于Polygan。2. 接入复杂,因为只买了实时行情数据,没有全量历史数据,需要业务侧自己基于实时行情进行计算与存储。
2. 任务
接入lseg实时行情数据并全量替换现有接口。
3. 难点与解决方案
3.1 难点1·海量数据实时接收与清理
平均每个交易日接收80M消息(极端行情100M+),平均200K/min, 平均3.5K/s,峰值1.2M/min, 20K/s。接收速度慢会导致ws连接断开,数据丢失。
3.2 难点2·海量数据实时计算与存储
美股Ticker总数10K+,需要实时计算min1, min5, min10, min30, min60, day等等。日均新增K线5M,平均每分钟50K+,因为K线窗口都是固定的,峰值K线生成速度也是50K+。这里有两个要求,1. 计算性能要快,处理慢会导致数据丢失或者数据延迟,进而影响所有依赖的业务。2.存储要快,因为存在时间热点问题,存储系统要支持高并发写入。
3.3 难点3·数据准确性保证
行情数据不准的来源有两个:1. K线生成公式没有统一的标准,各家处理规则不一致,成交数据包含不同的类型,比如普通成交、大额成交、碎股成交。有些券商统计这些数据,有些券商没有。因此光自己计算还不够,还需要和外界比对。2. 随着时间的迁移,历史价格会因为公司分红、拆并股等事件变更,需要及时更新,否则误差会越来越大。
3.4 难点1的解决方案
初版方案是单线程串行处理,流程见图1
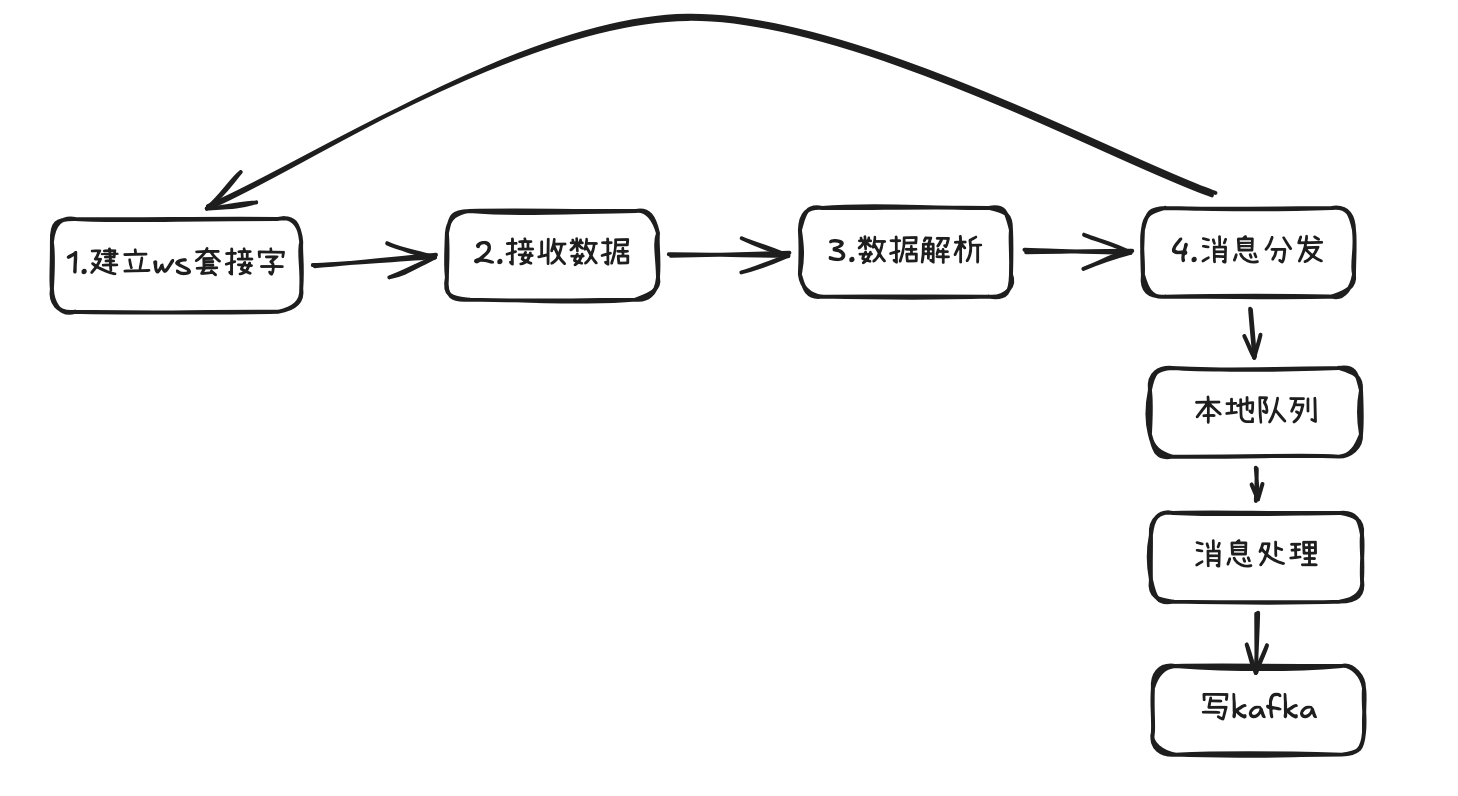 图1
图1
这个版本存在的问题是经常因为接收速度慢导致ws连接中断。
在此基础上优化的方案是读写分离,和Redis 多线程类似,将数据解析、处理与数据接收分离出来,读协程只负责数据接收,收到数据之后写入本地队列即可。由本地worker 异步消费队列。如图2:
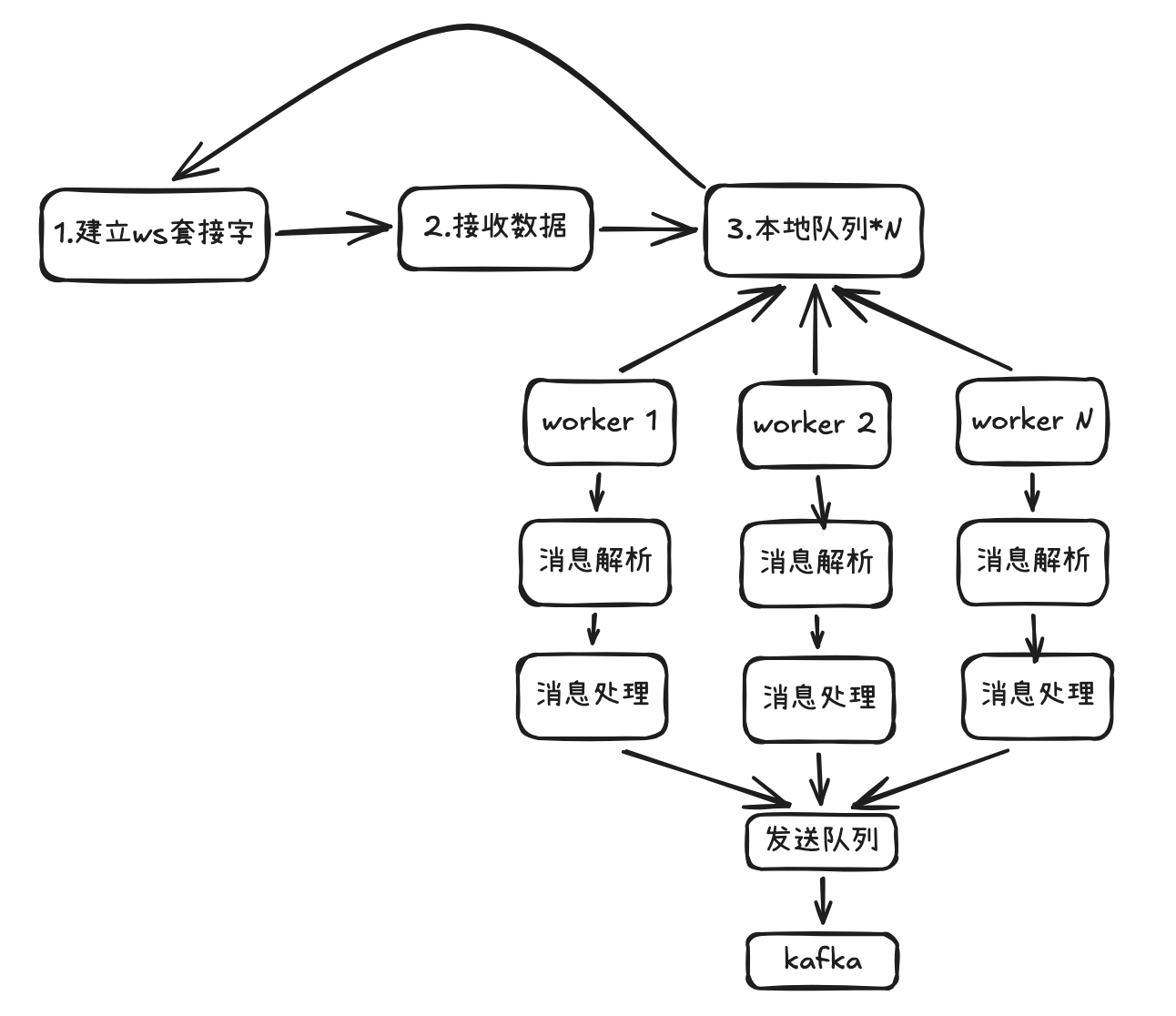 图2
图2
这一版的问题大幅减少了ws连接中断的问题,但还是因为本地队列发送慢导致数据丢失问题。因此进一步优化了数据发送流程,改为多协程异步批量发送。如图3:
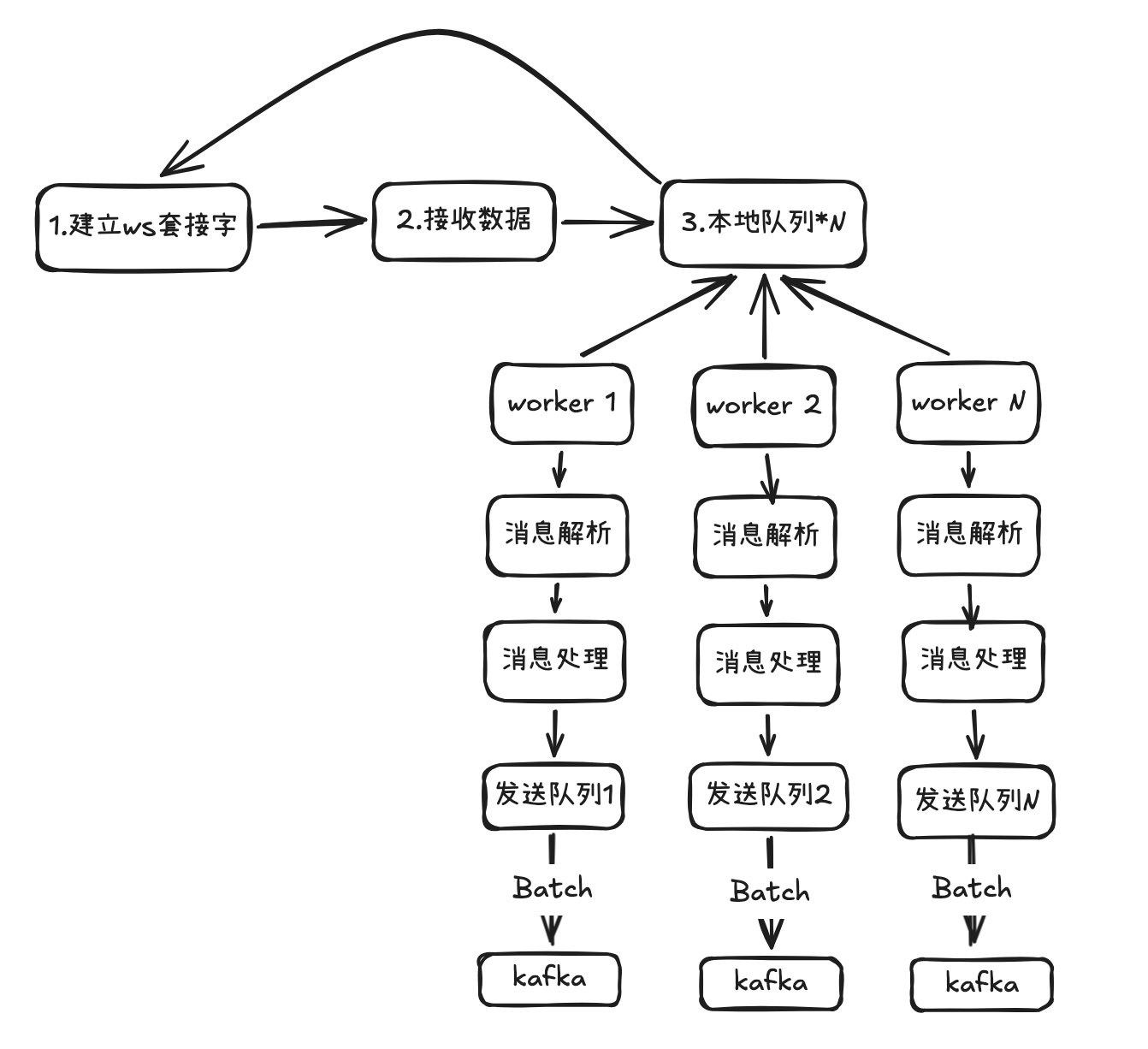 图3
图3
除了上述的处理,还有其他一些优化
-
开启ws链路压缩,减少数据量。
-
调优套接字接收缓冲区,减少系统调用次数。
-
开启kafka压缩, 调整ACK参数
3.5 难点2的解决方案
针对难点2,需要实时生成不同时间粒度K线数据,如min1, min5, min10, min30, min60, day等等。Ticker总数10K+,因为K线窗口固定,因此同一粒度K线同一时刻生成,存在写入热点问题。另外这里要求计算K线要性能快,计算慢会导致本地队列移除数据包丢失从而影响K线的准确度。
每日新增5M记录,K线包含(OHLCV+Ticker+Timestamp+ID), 单条记录占用字节20*5+8*2+32 = 148字节。存储空间近 700MB,一个月15GB
先说一下存储的选型,典型的存储包含以下几种:
内存数据库、磁盘数据库、时序数据库
内存数据库,典型的如Redis,写入速度最快,但是成本最高,且无法缓存全量数据,需要业务侧做聚合处理,比较麻烦。
磁盘数据库,如MySQL,顺序写入速度还行,不支持高并发写入,存储成本低。需要分表。
时序数据库,如AWS timestream, 写入速度很快,存储成本低,IO费用高。
在我们的业务场景中,K线是基础数据,各种各样的业务都依赖它,如回测系统、策略系统等等,很多业务场景都需要读取大量的行情数据,如果基于IO次数收费,成本过高。基于性能、成本综合考虑,我们选用了MySQL 作为存储。针对数据量特别大的粒度,如min1, min5,使用一致性哈希分表。
初版方案是创建10K协程,每个ticker一个,本地维护一个行情消息队列,收到消息后串行计算不同粒度K线,当K线窗口结束之后,写入到数据库并创建新的K线,流程如图4
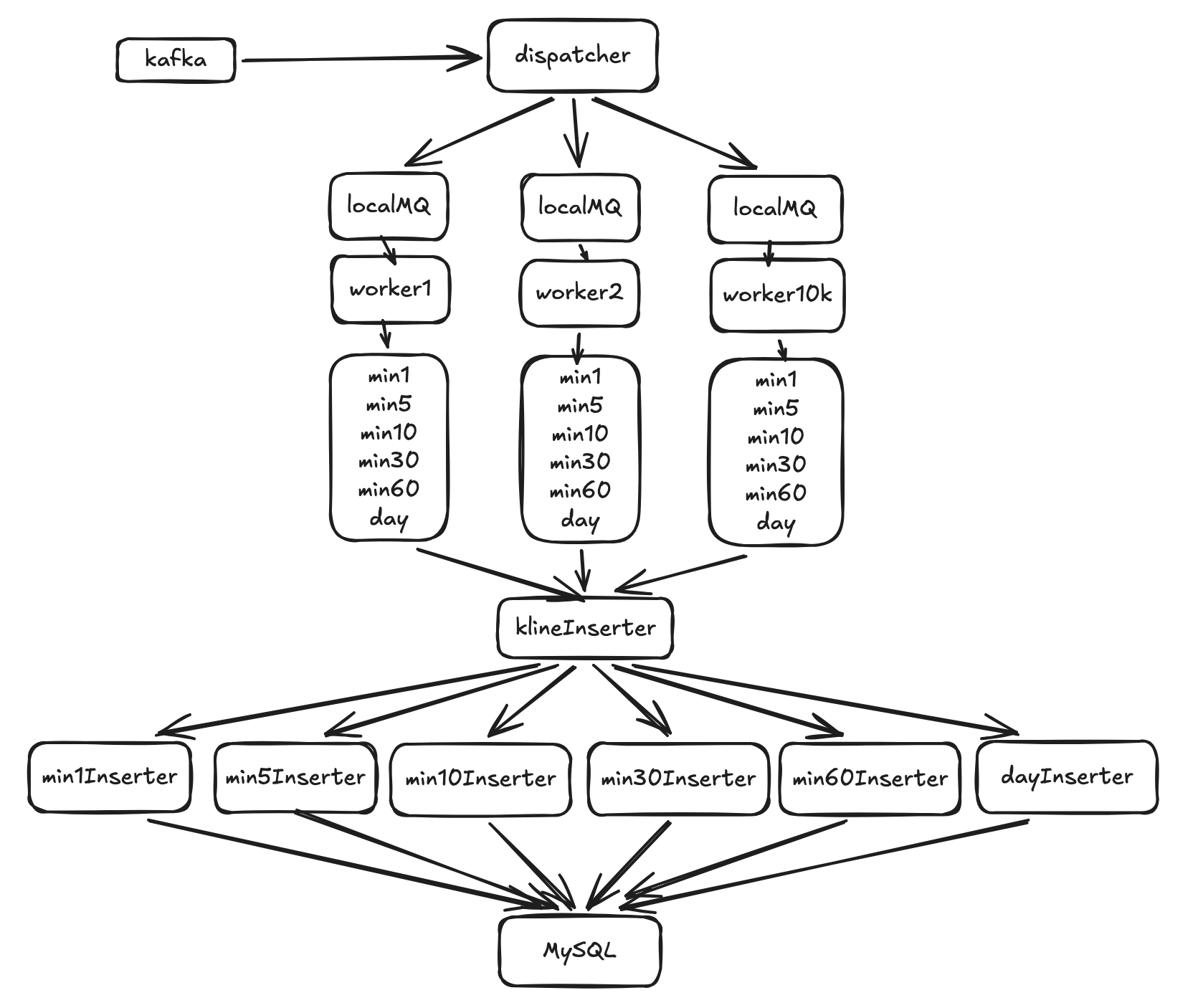 图4
图4
这一版可以用,但是存在两个问题,一个是计算慢导致本地队列溢出丢数据,另一个是时间热点,不同粒度的K线在同一个时间点结束,导致瞬时写入负载大,造成数据库抖动。
对于计算慢的问题,一种思路是并行计算,开多个协程,每个K线粒度对一个协程,N个粒度创建N个协程。这种方案会导致协程数量爆炸,因为ticker总数已经是10K,再乘以N,虽然golang 协程创建开销小,但是一旦协程数量多,cpu调度开销就会急剧上升。因此不可行。
后来想到了一个新颖的方案,聚合计算。K线原本的计算逻辑是这样,将当前窗口的第一个成交价作为open, 最后一个成交作为close,中间的成交数据用来更新high,low,累加每一个事件的volume。如果收到N个成交事件,K个粒度,则总的计算量是NK,但如果采用聚合计算的方式,只计算min1, 仅当min1结束之后,再使用这根已结束的min1更新其它粒度,如此一来计算量就减少K倍,只需计算一次,大幅减少计算量。
另外针对时间热点问题,比如在T60min结束时刻,所有日内粒度都结束当前这个窗口期,需要写入db,每个粒度10K,N个粒度写入量为N*10K,MySQL扛不住太高的并发写入。这里采用的优化方向有三个,一个是对K线做优先级排序,业务层面使用最多的粒度,写入尽可能实时,对于优先级不高的,可以延迟写入,针对不同粒度,引入了随机的写入延迟,避免时间热点问题。另一个优化是并发写入。比如min1,原本写10K次,如果改为每次写入100条,则只需要写入100次。随机延迟和解决缓存雪崩问题方案一样,都是避免同一时刻触发。除此之外,还有一些其它方案可以解决时间延迟问题,比如写入kafka削峰限流,不过代价是数据更新延迟。还有一个优化方案是减少写入的粒度,由业务层做聚合处理,比如取消写入min10,min30,改为业务侧基于min5聚合处理,这样也极大缓解写入量,代价是读取的时候稍微慢一点。
优化后的方案如图5:
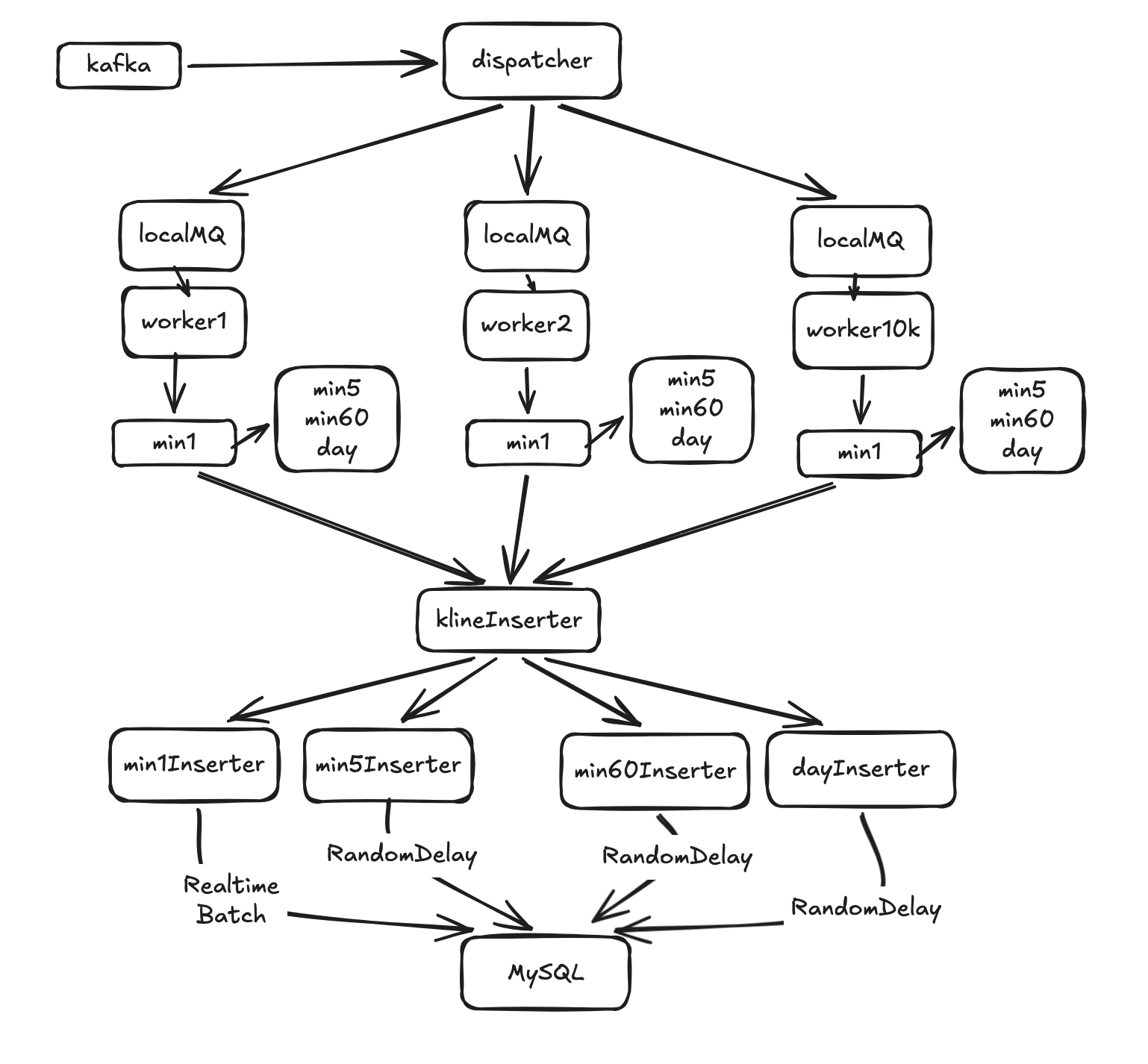 图5
图5
3.6 难点3的解决方案
实时K线准确度问题,虽然lseg不提供全量历史数据,但提供2年最新数据。对于实时生成的K线准确度问题,盘中及盘后会定时异步从lseg拉取最新的K线增量覆盖数据库, 这里不是无脑覆盖,而是先检查之前有没有更新过,如果有更新过则跳过本次更新,减少数据库写入量,代价是需要缓存已更新数据。
历史K线准确度问题,市面上没有哪一家数据提供商能够提供完全准确无误数据,我们这里采用的是多源比对取共识。每周进行一次全量检查。优先和Polygon对比,如果发现存在不一致,则进一步检查Yahoo, Nasdaq, Stooq。取这三家有共识的数据,比如如果有两家数据一样,则取一家数据覆盖更新,如果三家都不一致,则告警人工处理。
4. 结果
-
lseg ws平均接收延迟70ms, max 100ms。
-
kafka平均发送延迟10ms,max50ms。
5. 总结
关于高性能,可以围绕数据传输、计算、存储三个角度来进行优化。数据传输层面,考虑编码方式(文本或者二进制,如json vs protobuf),传输协议选择(udp, tcp), 数据压缩。计算层面,优化的方式包括并发、异步、缓存、预处理、批量等等。存储层面包括存储引擎选择(B+树 vs LSM-Tree), 批量、缓存等等。
另外上述结果还可以进一步优化
-
创建多个ws链接,提升并发处理量。代价是成本增加,lseg按照连接数收费。
-
采用pb编码,数据量估计可以减少一半。我们没有使用是因为当前lseg仅在java sdk提供pb编码,和我们技术栈不一样,维护困难。