预训练 MoE,用于 Emergent Modularity
Emergent ɪˈmɜːdʒənt
adj. 新兴的,处于发展初期的;(特征)突现的,突创的;(植物,尤指森林中的大树)突出的,露头的;(水生植物)露出水面的
n. 突创特征;露出水面的植物,(高于林中其他树木的)露头树
涌现式模块化
论文语境含义:模型在预训练中自发形成可独立使用、可组合的专家模块,无需人工预设领域标签
摘要
monolithic ˌmɒnəˈlɪθɪk
adj. 整体的;巨石的,庞大的;完全统一的
n. 单块集成电路,单片电路
degradation ˌdeɡrəˈdeɪʃn
n. 丢脸,落魄,侮辱;损害,恶化,衰退;降解;陵夷,剥蚀
practicality ˌpræktɪˈkæləti
n. 实用性,可行性;务实,实事求是;实例,实际情况(practicalities)
prior ˈpraɪə(r)
adj. 先前的,事先的;<正式>优先的,更重要的;<正式>在前面的(prior to)
n. <美,非正式>犯罪前科;小修道院院长;大修道院副院长;托钵会会长
priors 先知先觉、先验
composition ˌkɒmpəˈzɪʃ(ə)n n. 成分构成,成分;(音乐、艺术、诗歌的)作品;创作,作曲;构图;作文
encourage ɪnˈkʌrɪdʒ v. 鼓励,激励;鼓动,怂恿;刺激,促进
constraint kənˈstreɪnt n. 限制,束缚;克制,拘束
coherent kəʊˈhɪərənt
adj. 有条理的,连贯的;说话条理清晰的,易于理解的;团结一致的,凝聚的;(波)相干的,相参的;黏着的,黏连的
expert / ˈekspɜːt /
specialize ˈspeʃəlaɪz
vi. 专门研究(或从事),专攻;专营;(生)使(器官)专化,使特化
syntactic sɪnˈtæktɪk adj. 句法的;语法的;依据造句法的
composable kəm'pəuzəbl adj. 组成的
Large language models are typically deployed as monolithic systems, requiring the full model even when applications need only a narrow subset of capabilities, e.g., code, math, or domain-specific knowledge. Mixture-of-Experts (MoEs) seemingly offer a potential alternative by activating only a subset of experts per input, but in practice, restricting inference to a subset of experts for a given domain leads to severe performance degradation. This limits their practicality in memoryconstrained settings, especially as models grow larger and sparser.
大型语言模型通常以整体式系统部署,即便应用仅需代码、数学或领域知识等少量特定能力,也必须加载完整模型(full model)。混合专家模型(MoE)看似(seemingly)能通过对每个输入仅激活部分专家提供解决方案(a potential alternative),但实际应用中,针对特定领域仅使用部分专家进行推理会导致性能大幅下降(severe performance degradation)。这限制了其在内存受限(memory constrained)场景下的实用性,尤其在模型规模不断扩大、稀疏度持续提升的情况下。
We introduce EMO, an MoE designed for modularity---the independent use and composition of expert subsets---without requiring human-defined priors. Our key idea is to encourage tokens from similar domains to rely on similar experts. Since tokens within a document often share a domain, EMO restricts them to select experts from a shared pool, while allowing different documents to use different pools. This simple constraint enables coherent expert groupings to emerge during pretraining using document boundaries alone.
我们提出EMO:一种以模块化为设计目标的(designed for modularity)混合专家模型 ------ 支持专家子集独立使用与组合(composition of expert subsets),且无需人工预设先验知识(priors)。其核心思路是:让相似领域的 token 依赖相似的专家 (encourage tokens from similar domains to rely on similar experts)。这一设计基于一个直观的观察------同一文档内的 token 通常属于同一领域(如一篇数学论文中的 token 大多与数学相关),因此 EMO 约束这些 token 从共享专家池中选择激活专家,同时不同文档则可使用不同的专家池。仅依靠文档边界(using document boundaries alone)这一简单约束,就能让模型在预训练阶段自发形成(to emerge)结构清晰的(coherent)专家分组(expert groupings)。
We pretrain a 1B-active, 14B-total EMO on 1T tokens. As a full model, it matches standard MoE performance. Crucially, it enables selective expert use: retaining only 25% (12.5%) of experts incurs just a 1% (3%) absolute drop, whereas standard MoEs break under the same setting. We further find that expert subsets in EMO specialize at semantic levels (e.g., domains such as math or code), in contrast to the low-level syntactic specialization observed in standard MoEs.
我们基于 1 万亿 token 预训练了一个激活参数量 10 亿(1B-active)、总参数量 140 亿(14B-total)的 EMO 模型。作为完整模型时,其性能与标准混合专家模型相当。关键优势在于它支持专家选择性使用:仅保留 25%(12.5%)的专家时,性能仅绝对下降 1%(3%)(retaining only 25% of experts incurs just a 1% absolute drop,retaining only 12.5% of experts incurs just a 3% absolute drop);而标准混合专家模型在相同条件下会完全失效(break)。我们进一步发现,EMO 的专家子集在语义层面(semantic)(如数学、代码等领域)形成专业化能力(specialize at semantic levels),而非标准混合专家模型中常见的(observed)底层句法层面专业化。
Altogether, our results demonstrate a path toward modular, memory-efficient deployment of large, sparse models and open new opportunities for composable architectures.
总体而言,本研究为大型稀疏模型的模块化、低内存高效部署提供了可行路径,并为可组合架构开辟了新方向。
介绍
purple ˈpɜːp(ə)l
adj. 紫色的,紫红色的;(作品)词藻华丽的,华而不实的;帝王的
n. 紫色,紫红色;紫色衣服(或料子);(古罗马,拜占庭)紫色衣服(the purple);(从某些软体动物提取的)深红色染料;(古罗马)要职,高位,拥有特权的职位(the purple);(红衣主教的)大红袍(the purple)
v. (使)成紫色,(使)发紫
paradigm ˈpærədaɪm
n. 典范,范例;样板,范式;词形变化表;纵聚合关系语言项
prepositions 介词
punctuation 标点符号
recurring rɪˈkɜːrɪŋ
adj. 反复出现,再次发生;循环小数的;经常性的
v. 再发生,反复出现;(思考或讲话时)重新回到,反复提及(recur to);(小数)循环
corpus ˈkɔːpəs n. 文集,全集;语料库;体,身体;胃体;本金
Large language models (LLMs) are typically trained and deployed as monolithic systems: a single model is pretrained, finetuned, and served as one unified entity 1, 2, 3. While effective, this paradigm becomes increasingly restrictive as models scale. In many deployment settings, applications require only a narrow subset of capabilities---such as code generation, mathematical reasoning, or domain-specific knowledge---but must still serve the full model, incurring unnecessary computational cost and memory use. Moreover, the monolithic design prevents isolating, updating, or improving specific capabilities without retraining and redeploying the entire system.
大型语言模型(LLMs)通常以整体式系统的方式进行训练与部署:单一模型会被预训练、微调,并作为一个统一整体(one unified entity)对外提供服务 1,2,3。这种模式虽有效,但随着模型规模不断扩大,其局限性愈发明显。在诸多部署场景中,应用仅需代码生成、数学推理或领域专属知识等少数特定能力,却仍需加载完整模型,产生不必要的计算开销与内存占用。此外,整体式设计导致无法单独更新或优化某项能力(specific capabilities),必须对整个模型重新训练与部署。
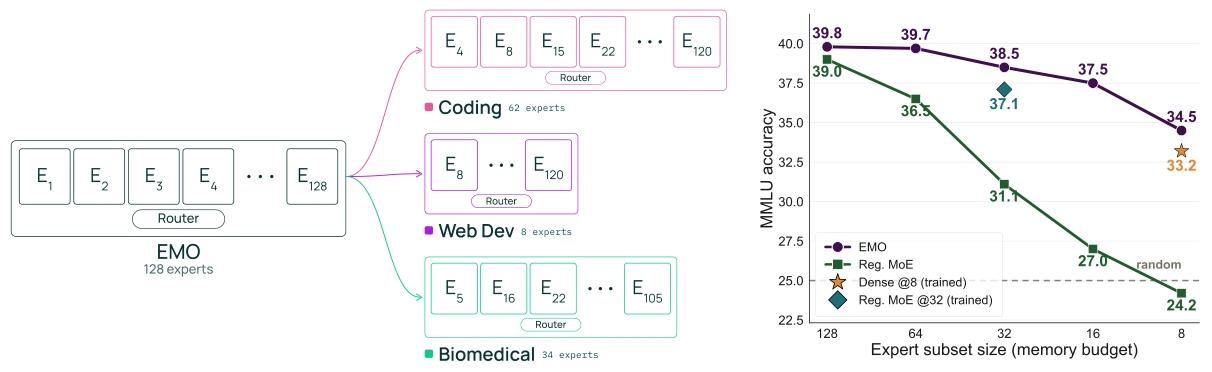
Figure 1: (Left) EMO is an MoE trained with modularity as a first-class objective. For a given domain (e.g., math, code, biomedical), users can select a small subset of experts of any size and retain near full-model performance. This turns a single model into a composable architecture, enabling flexible deployment with improved memory-accuracy tradeoffs for large, sparse MoEs.
Figure 1: (Right) Averaged performance over 16 MMLU categories across different memory budgets. EMO (purple) and Reg. MoE (green) are single models evaluated with expert subsets of different sizes. EMO expert subsets push the Pareto frontier in memory-accuracy trade-off, outperforming standard MoEs and even fixed-budget models trained from scratch.
(左)EMO 是以模块化为核心目标训练的混合专家模型。针对数学、代码、生物医学等特定领域,用户可选取任意规模的少量专家子集,同时保持接近完整模型的性能。这将单一模型转变为可组合架构,让大型稀疏混合专家模型实现灵活部署,并优化内存占用与精度的权衡关系( improved memory-accuracy tradeoffs,内存和大模型精度的权衡)。
(右)在不同内存预算下(memory budgets),16 个 MMLU 类别上的平均性能。EMO(紫色)与标准混合专家模型(绿色)均使用不同规模的专家子集进行评估。EMO 的专家子集在 内存--精度 帕累托最优前沿上取得突破(push the Pareto frontier),性能优于标准混合专家模型,甚至超过从零开始训练(from scratch)的固定预算模型。
Mixture-of-Experts (MoE) models appear to offer a natural path toward relaxing this constraint, as they consist of many small FFNs (experts), of which only a small subset is activated for each input token 2, 4. However, existing MoEs still require the full model for any task: tokens within the same input activate different experts, causing most or all experts to be used over the course of a task. As we show, this behavior---partially driven by experts specializing in low-level lexical patterns (e.g., prepositions, punctuation)---prevents subsets of the model from being usable independently, limiting the deployability of MoEs in memory-constrained settings, an issue that becomes increasingly important as models grow larger and sparser 5, 2, 3.
混合专家模型(MoE)看似是提供了解决这一限制的自然方案:这类模型由多个小型前馈网络(专家)构成,且每个输入 token 仅激活其中一小部分专家2,4。然而,现有 MoE 在执行任何任务时仍需加载完整模型:同一输入中的不同 token 会激活不同专家,导致任务执行过程中绝大多数乃至全部专家都会被调用。如本文所示,这种现象部分源于专家仅专注于底层词法模式(如介词、标点符号)的专业化学习,导致模型子集无法独立使用,进而限制了 MoE 在内存受限场景下的部署可行性。随着模型规模不断扩大、稀疏度持续提升,这一问题变得愈发关键 5,2,3。
We instead seek to train MoE models in which experts organize into coherent groups that can be selectively used and composed. Concretely, we train an MoE model to be modular, i.e., to support (1) the independent use of expert subsets and (2) their composition into a strong general-purpose model. Achieving this in practice, however, is challenging. Prior work has explored partitioning training data into predefined domains (e.g., math, coding) and training separate experts 6, 7, but this is too restricted for model's learning and limits the model's overall performance.
我们转而致力于训练这样一类混合专家(MoE)模型:专家能自发组织成连贯的分组,可被选择性调用与组合。具体而言,我们将 MoE 模型训练为模块化形态,即满足两大特性:
- 专家子集可独立使用
- 这些子集可组合为性能强劲的通用模型
然而在实践中实现这一目标极具挑战。现有研究曾尝试将训练数据按人工预定义领域(如数学、编程)划分,分别训练独立专家 6,7,但这种方式对模型的学习限制过大,会降低模型整体性能。
In this work, we propose to train MoE models in which modular structure emerges directly from the data, without relying on human-defined prior, and introduce EMO, an MoE that follows this approach. Our key intuition is that tokens from the similar domains should activate similar subsets of experts. Assuming that tokens within a document tend to share a domain, we enforce this structure by restricting all tokens in a document to select their active experts from a shared pool.
For example, in an MoE with 128 total and 8 active experts, all tokens from a document select their active subset from a shared pool of 32 experts. Different documents may use different expert pools, allowing the model to learn recurring expert subsets across the training corpus. Importantly, EMO does not require predefined task or domain labels: expert subsets emerge in a self-supervised way, using document boundaries as the only grouping signal.
在本研究中,我们提出训练一类模块化结构可直接从数据中自发涌现的混合专家(MoE)模型,无需依赖人工定义的先验知识,并据此提出EMO模型。我们的核心直觉是:来自相似领域的词元(token)应激活相似的专家子集。基于同一文档内的词元通常属于同一领域这一假设,我们通过约束机制实现该结构 ------同一文档内的所有词元只能从一个共享专家池中选取激活专家。
举例来说,在一个总专家数为 128、每个词元激活 8 个专家的 MoE 模型中,某一文档内的所有词元都只能从包含 32 个专家的共享池中选择激活子集。不同文档可使用不同的专家池,让模型能在训练语料中学习到反复出现的(recurring)专家子集。
关键在于,EMO无需预定义任务标签或领域标签:专家子集以自监督(self-supervised)的方式涌现,仅将文档边界作为唯一的分组信号。
We train a 1B-active, 14B-total parameter EMO model on 1 trillion tokens. As a full model, EMO matches the overall performance of a standard MoE. More importantly, however, it enables effective composition of expert subsets, which standard MoEs fail to support. Across domain-specific subsets of MMLU and MMLU-Pro (e.g., math, physics, biology, social sciences), identifying and deploying only the most relevant experts largely preserve performance, e.g., 1% absolute performance drop when retaining 25% of experts, and 3% when retaining 12.5%. This is in contrast to standard MoEs that see severe degradation under the same constraint, e.g., 10% and 15% drops, respectively. These results show that EMO makes MoEs significantly more practical and accessible: instead of loading the full model, one can serve only a small subset of experts relevant to a given task or domain (Figure 1), which has important implications for deployment in memory-constrained settings 8, 9, 10.
我们基于1 万亿词元(tokens)预训练了一个激活参数量 10 亿、总参数量 140 亿的 EMO 模型。作为完整模型时,EMO 的整体性能与标准混合专家模型(MoE)相当。
但更重要的是,EMO 实现了专家子集的有效组合使用,这是标准 MoE 无法做到的。在 MMLU 与 MMLU‑Pro 的领域专属子集(如数学、物理、生物、社会科学)上,仅选取并部署最相关的专家就能大幅保留性能:
保留25% 专家时,性能绝对下降仅 1%;
保留12.5% 专家时,性能绝对下降仅 3%。
与之形成对比的是,标准 MoE 在相同约束下性能急剧衰减,分别下降10%与15%。
这些结果表明,EMO 让混合专家模型变得更加实用易用:无需加载完整模型,只需加载与当前任务 / 领域相关的少量专家子集即可提供服务(见图 1),这对内存受限场景下的部署具有重要意义 8,9,10。
qualitatively ˈkwɒlɪtətɪvli adv. 定性地;从品质上讲
We further analyze routing patterns and find that expert subsets specialize at higher-level semantic granularity, such as domains and topics (e.g., math, code), which is in contrast to experts in standard MoEs that specialize in lower-level syntactic patterns (e.g., prepositions, punctuation). This difference suggests that expert specialization in EMO is qualitatively distinct and underlies its modularity.
我们进一步对路由模式展开分析,发现:
EMO 中的专家子集在更高层级的语义粒度(semantic granularity)上形成专业化,例如数学、代码等领域与主题;
这与标准 MoE 中专家仅专注底层句法模式(如介词、标点符号)形成鲜明对比。
这一差异表明,EMO 的专家专业化(expert specialization)具有本质上的独特性(distinct),这也是其能够实现模块化的核心原因。
Together, these results demonstrate that modularity can be built into large language models, opening a path for broader functionalities, such as targeted extension training or more interpretable and debuggable components to better regulate model behavior. We release both EMO and a matched baseline trained on the same data to support reproducibility and further study.
综上,这些结果表明模块化可以被内置到大型语言模型中,这为拓展模型功能开辟了道路,例如定向扩展训练,或构建更具可解释性(interpretable)、更易调试的(debuggable)组件,从而更好地规范模型行为。我们开源了EMO 模型以及在相同数据上训练的对照基线模型,以支持可复现研究与后续探索。
Modular Mixture of Experts (EMO)
EMO含义
The goal of EMO is to pre-train an MoE with modularity as the first-class objective, i.e., (1) expert subsets should be usable in isolation for a particular downstream domain, and (2) their composition--- the full model---remains a strong general-purpose model.
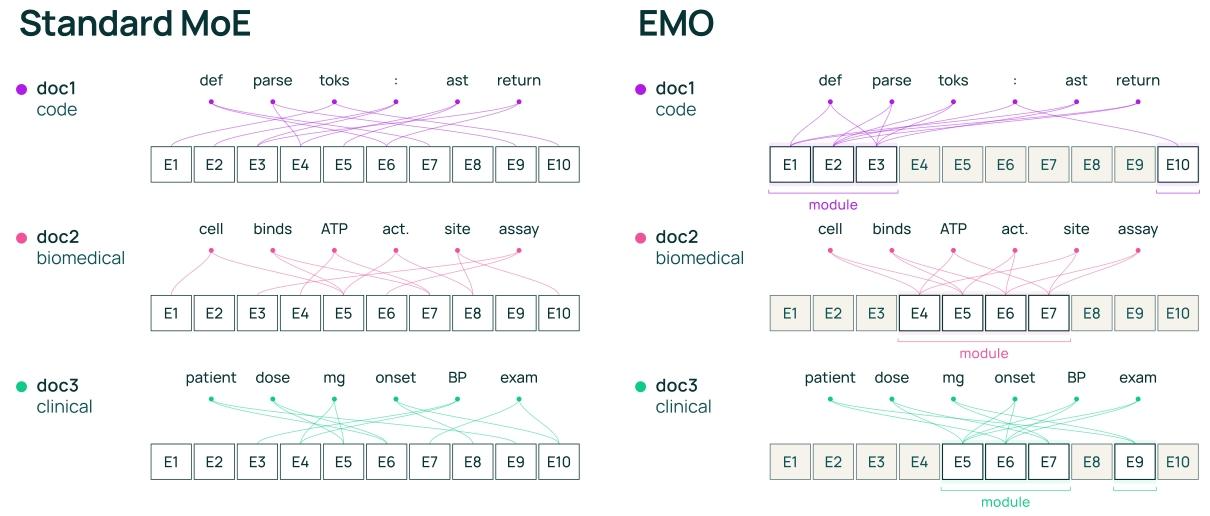
Figure 2: Comparison of training of a standard MoE and EMO ( (k=2) , (n=10) , shared experts omitted for simplicity).
(Left) In a standard MoE, each token independently selects its top- k experts.
(Right) In EMO, the router first selects a subset of experts for each document, and all tokens are constrained to route within this subset.
This enforces consistent expert usage across the document, encouraging groups of experts to form domain specialization.
图 2:标准混合专家模型(MoE)与 EMO 的训练过程对比(k=2,n=10,为简化展示省略共享专家)
(左)在标准 MoE 中,每个 token 独立选择自己的 Top-k 专家
(右)在 EMO 中,路由模块先为每个文档选定一组专家子集,并约束该文档内所有 token 只能在这个子集内进行路由
这一机制保证了文档内专家使用的一致性,促使专家分组形成领域专业化(domain specialization)
instantiate ɪnˈstænʃɪeɪt v. 例示,举例说明;(哲)有例为证
specialization ˌspeʃəlaɪˈzeɪʃ(ə)n n. 专业;专业化,专门化;(生物)特化作用
biology baɪˈɒlədʒi n. 生物学;生命机理,作用方式;生理习性;(某个地区的)生物
clinic ˈklɪnɪk n. 诊所,门诊部;门诊时间;临床实习;讲习班;(医院的)科,室;减免费用的专业服务机构;健康讲座
clinical ˈklɪnɪk(ə)l adj. 诊所的,医务室的;临床的,临床诊断的;冷静的,无感情的;简陋的,无装饰的
supervisory ˌsuːpəˈvaɪzəri adj. 监督的
Naive Approach (天真朴素的方法)
A straightforward approach to develop modularity is to enforce expert specialization in MoEs by routing tokens to experts based on predefined semantic domains (e.g., math, biology, code). Methods such as FlexOlmo 7 and BTX 6 instantiate this idea. However, this formulation requires domain labels across pretraining data, which can be ambigious, difficult to obtain, and injects human biases. Having fixed domains also restricts flexibility, making it difficult for the model to be applied to new domains during inference.
实现模块化的一种直接方法,是在混合专家模型(MoE)中按照人工预定义的语义领域(如数学、生物学、代码)将词元路由到对应专家,以此强制实现专家专业化。FlexOlmo 7 和 BTX 6 等方法便是基于这一思路实现的。
然而,这种方案需要在预训练数据上标注领域标签(requires domain labels),而这些标签往往存在歧义、难以获取,还会引入人为偏见(be ambigious, difficult to obtain, and injects human biases)。
此外,固定的领域划分会限制模型灵活性,导致模型在推理阶段难以适配未见过的新领域。
EMO's Approach
Instead, we induce modular structure without explicit domain labels (Figure 2). Our key observation is that tokens within the same document usually come from the same domain. We therefore treat document boundaries as a weak supervisory signal: for each document, the router selects a shared expert pool, and all tokens in that document choose their active experts only from this pool. Different documents can use different pools, allowing modular expert subsets to emerge directly from the training data.
我们不依赖显式的领域标签,直接从数据中诱导(induce,引诱,诱导)出模块化结构(见图 2)。我们的核心观察(key observation)是:同一文档内的词元(token)通常属于同一个领域。因此,我们将文档边界当作一种弱监督信号(weak supervisory signal):路由模块先为每个文档选定一个共享专家池;该文档内的所有词元都只能从这个池子里选择激活专家。不同文档可以使用不同的专家池,让模块化的专家子集直接从训练数据中自发涌现(emerge)
Preliminary: Mixture of Experts Architecture (传统的MoE介绍)
basis ˈbeɪsɪs n. 基础,要素;基准,方式;理由,根据;主要成分(或部分)
fraction ˈfrækʃn n. 分数,小数;小部分,微量;持不同意见的小集团;分离

混合专家(MoE)模型是一种仅解码器的(decorder-only) Transformer 语言模型 30,其前馈子层被替换为稀疏的专家网络混合结构(MoE)。设模型共有 n 个专家,其中包括 nr 个路由专家和 ns 个共享专家 n = nr + ns
- 路由专家:按每个 token 动态选择激活
- 共享专家:始终处于激活状态


Cross-Entropy Loss(交叉熵损失):模型的主任务损失,和普通语言模型的目标完全一样,让模型尽可能准确地预测下一个 token,保证语言生成质量
Load Balancing Loss(负载均衡损失):MoE 模型的辅助损失,专门解决「专家扎堆、负载不均」的问题,让所有路由专家被使用的频率尽量均匀,避免出现 "少数专家被打爆,多数专家躺平" 的情况
Router Z‑Loss(RZ 损失):正则化路由器 logits 幅值,防止数值溢出、梯度消失、训练崩溃,只负责 "稳定",不管负载均衡

负载均衡损失中的惩罚

LB含义解读

Pi 是路由器的 "主观意愿",fi是实际发生的 "客观结果"
Pi = 0.4,fi = 0.2:路由器很看好专家 i,但它在实际 top-k 竞争中表现不佳,没拿到多少 token,属于 "叫好不叫座" 的专家,不会被负载均衡损失惩罚
Pi = 0.2,fi = 0.4:路由器主观上并不偏爱专家 i,但它在实际 top-k 选择中表现强势,拿到了远超预期的 token 负载。由于它的乘积项不高,负载均衡损失不会惩罚它,但路由器会被反向传播修正,调整对它的偏好和整体分流策略,这通常意味着其他专家的路由概率都很分散,而它虽然 "赔率" 不高,但在 token 选择中被频繁选中,属于 "黑马型专家"
EMO: An Objective to Induce Modularity

EMO 的目标是利用文档边界作为弱监督信号,诱导模型形成模块化结构。
EMO 的实现方式是:为每一篇文档选择一个文档专属专家池,并在训练过程中强制该文档内的所有 token 都只能在这个专家池中路由(如图 2 所示)。

超参数 d 控制专家子集的粒度:
d 越小,专家子集的专用性越强,但表达能力受限(例如 d=k 时,文档内所有 token 都必须使用同一批专家)
d 越大,模型的灵活性越高,但模块化结构会变弱(例如 d=nr 时,退化为标准 MoE)

Key Technical Considerations
Several technical choices were important for effective training of EMO (see §A for details).
Consideration 1. Load Balancing.
opposing əˈpəʊzɪŋ
adj. 对抗的,反对的;(事实、观点等)截然相反的,全然不同的;(方向或位置)相反的,相对的
v. 反抗,阻碍;与......竞争,与......角逐(oppose 的现在分词)
empirically ɪmˈpɪrɪkli adv. 以经验为主地
complementary ˌkɒmplɪˈment(ə)ri adj. 相互补充的,相辅相成的;互补色的;(基因序列、核苷酸等)互补的;(与)补充医学(有关)的;余角的,互为余角的
MoE的负载均衡是针对所有专家的,而EMO已经前置为每个文档选定了一个专家子集池,自然就不能用所有专家的LB了
A central challenge is that load balancing and documentlevel routing appear to impose opposing pressures. This conflict arises under standard micro-batch load balancing, where the load-balancing loss is computed over only a few documents. While this local implementation reduces cross-device communication and simplifies distributed training, it also encourages tokens from the same document to spread across many experts, directly opposing the shared-pool constraint and causing unstable training.
核心挑战在于:负载均衡与文档级路由会施加相互冲突的压力,这种冲突在标准的微批次(micro-batch)局部负载均衡下尤为突出 ------ 此时负载均衡损失仅基于少量文档计算。虽然这种局部实现能减少跨设备通信、简化分布式训练,但它也会鼓励同一文档的 token 分散到大量专家上,直接与「共享专家池约束」相悖,导致训练不稳定。
微批次里只有几篇文档,LB 损失会强行让这几篇文档的 token 均匀分散到所有专家
这会直接打破 EMO 的核心设定:「同一文档的 token 只能在专属池里路由」
结果就是:模型为了均衡,把同一篇文档的 token 打散到各个专家,模块无法形成,训练震荡
We address this by adopting global load balancing 31, aggregating routing statistics across dataparallel groups. Applied over a larger and more diverse set of documents, load balancing encourages uniform utilization of experts across documents, while our routing constraint enforces expert consistency within each document, making the two objectives largely complementary. Empirically, this is important for stable training: see Figure 7 in §A. (S A)
我们通过采用全局负载均衡31 来解决这个问题:在数据并行组(dataparallel groups)内聚合(aggregate)所有设备的路由统计信息。
当负载均衡作用于更大、更多样的文档集合时,它会鼓励专家在跨文档层面被均匀使用(uniform utilization);而我们的路由约束则强制文档内部保持专家一致性,从而让两个目标从冲突变为互补。实验表明,这对训练稳定性至关重要:详见附录 A 中的图 7。
不再只看微批次里的几篇文档,而是聚合所有设备的路由统计
LB 损失变成「跨文档层面的均衡」:鼓励不同领域的文档使用不同的专家,整体上所有专家都被用到
同时,文档级路由约束依然有效:同一文档的 token 必须在专属池里
两者现在是互补的:
全局 LB:让不同文档用不同专家,保证所有专家都有活干
文档级路由:让同一文档用同一批专家,保证模块内聚
Consideration 2. Choosing Expert Pool Size.
overfit 过拟合
Underfit 欠拟合
Fixing a single expert pool size d works well during training but limits inference-time flexibility. The model "overfits" only to expert sets of size d and performs poorly when deployed as expert subsets that isn't of size d
固定单一的专家池大小 d,在训练阶段效果很好,但会限制推理时的灵活性。模型会 "过拟合 overfits" 到只有大小为 d 的专家集合上,当部署为非 d 大小的专家子集时,性能会大幅下降。
To enable the model to support expert subsets of all sizes, we treat d as a random variable and sample it independently for each document during pretraining:
为了让模型能够支持所有大小的专家子集,我们将 d 视为一个随机变量,在预训练过程中为每篇文档独立采样:
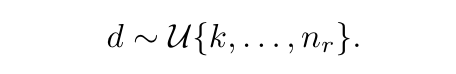
where k is the number of active experts per token and nr is the total number of routable experts. This exposes the model to a range of expert pool sizes during training, enabling it to support expert subsets of varying capacities for selective expert use.
其中 k 是每个 token 激活的专家数量,nr 是可路由专家的总数。这种方式让模型在训练过程中接触到多种专家池大小,从而支持不同容量的专家子集,实现灵活的选择性专家调用。
再次申明下MoE的缺点
Mixture-of-Experts (MoE) models appear to offer a natural path toward relaxing this constraint, as they consist of many small FFNs (experts), of which only a small subset is activated for each input token 2, 4. However, existing MoEs still require the full model for any task: tokens within the same input activate different experts, causing most or all experts to be used over the course of a task.
As we show, this behavior---partially driven by experts specializing in low-level lexical patterns (e.g., prepositions, punctuation)---prevents subsets of the model from being usable independently, limiting the deployability of MoEs in memory-constrained settings, an issue that becomes increasingly important as models grow larger and sparser 5, 2, 3.
附录
Mixture-of-Experts (MoE) models are decoder-only Transformer language models in which the feedforward sublayer is replaced by a sparse mixture of expert networks.
含义
混合专家(MoE)模型是一种仅解码器(decoder-only)的 Transformer 语言模型,其前馈(FFN)子层被替换为稀疏的专家网络混合结构:
MoE 是 Transformer 的一种结构变体,不是一个独立的新模型,而是对标准 Transformer 的改造,改造的位置:FFN 层
标准 Transformer 里,每个 block 里都有一个 Attention → FFN 的结构,MoE 把「单一的 FFN」换成了「很多个小 FFN(专家)+ 路由器」
核心特点:稀疏激活(sparse mixture),每个 token 只会激活少数几个专家(比如 top-2),而不是全量参数都参与计算。这样可以让模型总参数量极大,但计算量只和激活的专家成正比,实现 "低成本做大模型"
不是说 MoE 只能在 decoder-only 里用,而是论文语境里讨论的 MoE 模型,是基于 decoder-only 做的。
为什么 MoE 主流都用在 decoder-only Transformer 里?
根本原因:自回归语言建模的特性天然适配 MoE
decoder-only 模型是单方向、自回归生成
每个 token 的计算是独立路由的(per-token routing),每个 token 只需要选一次专家,逻辑简单
路由决策只在 decoder 的前向传播里做,和 causal mask 配合自然,没有 encoder-decoder 的跨注意力复杂度
训练目标是简单的交叉熵(autoregressive LM),可以直接把 MoE 层的输出喂给语言模型头,不需要额外的复杂损失设计
负载均衡损失(load balancing loss)等辅助损失也很容易加到 decoder-only 的训练流程里
技术实现:decoder-only 更容易做「稀疏 + 并行」
MoE 的并行度天然和 decoder-only 匹配
decoder-only 模型的每个层都是 "同构" 的,所有 token 走相同的结构,只是路由不同
专家可以很方便地分布在不同 GPU 上(专家并行),而 decoder-only 的线性结构不会引入复杂的跨设备依赖
encoder-decoder 模型(如 T5)做 MoE 会有额外负担
encoder 和 decoder 都需要 MoE 层,路由逻辑要处理双向注意力,复杂度翻倍
跨注意力(cross-attention)让路由变得更复杂,比如 encoder 的 token 和 decoder 的 token 可能要共享专家,或者路由逻辑不同,实现成本高
工程落地:decoder-only 模型更适合大参数量 MoE
行业主流大模型都是 decoder-only
GPT-3/4、LLaMA、Mixtral、Qwen 等,都是 decoder-only 架构。
这些模型的参数量从百亿到万亿级,是 MoE 发挥优势的主战场(参数量越大,MoE 的成本优势越明显)
MoE 主要解决的是 "做大模型但不显著增加计算量"
decoder-only 模型通常以 "单方向生成" 为核心,计算瓶颈主要在 FFN 层,而 MoE 正好把 FFN 换成稀疏专家,针对性解决瓶颈
encoder-decoder 模型(如机器翻译)的瓶颈更多在跨注意力,MoE 带来的收益没那么直接
不是 "不能用在 encoder-only/encoder-decoder",而是 "性价比低"
理论上,MoE 可以改造到任何 Transformer 架构上:
- encoder-only:BERT 类模型也有 MoE 变体(如 MoE-BERT),但工业界用得少
- encoder-decoder:T5 也有 MoE 版本(如 mT5-XL),但落地远不如 decoder-only MoE 多
原因是: - encoder-only 模型的参数量通常不大,MoE 的稀疏优势体现不出来
- encoder-decoder 模型的训练和推理流程复杂,MoE 会进一步增加工程难度,而收益不显著
RZ 损失( Router Z‑Loss)
背景
路由器(Router)输出的是原始分数 logits,比如:
logits = 50, 1, -10, -20
然后 softmax 变成概率:
prob = 1.0, 0.0, 0.0, 0.0
logits 太大 → softmax 直接饱和(一个接近 1,其他接近 0)
梯度几乎为 0 → 路由器学不动、训练崩(fp16/bf16 下尤其容易溢出)
路由器过早 "认死理",失去探索能力
RZ损失公式

RZ 损失就是专门惩罚 "logits 太大" 的,让 router 输出克制一点。
log‑sum‑exp(LSE)
没有正则(放任自流)
路由器打分:60, -50, -50, -50
softmax 直接锁死第一个专家,永远不变,训练废掉
加 RZ 正则(踩刹车)
模型自动压低高分:3,1,0,-1
分数平缓,路由器还能继续学习调整,训练稳定
这就叫:正则化约束参数幅值
MOE 前馈层输出(前向计算公式)


路由专家:
按 token 动态选择,只激活 top-k 个,实现稀疏计算
每个 token 只和少数几个路由专家交互,大幅降低计算成本
共享专家:
所有 token 都要经过,保证基础能力不丢失
用来学习通用语言知识,避免路由专家过度稀疏导致基础能力退化
隐藏状态xt
在 Transformer(包括 MoE)里,隐藏状态 xt 就是模型对第 t 个 token 的「向量理解」,它是一个高维向量,用来存储这个 token 的语义、上下文信息,是所有后续计算(注意力、FFN、MoE 路由)的基础数据
它在 Transformer 里的位置,以 decoder-only 模型为例:
输入层:文本 token 先被转换成「词嵌入向量」,这是 xt 的起点
Transformer Block:自注意力层处理上下文关联,更新 xt;FFN(或 MoE 层)进一步编码语义,更新 xt
输出层:最后一层的 xt 被映射成下一个 token 的概率
所以,每一层的 xt 都是上一层处理后的 "升级版理解",越深层的 xt 包含的语义信息越抽象、越丰富
假设输入一句话:今天天气真好,对应的 token 序列是:今天, 天气, 真, 好
对 token 天气,也就是 t=2:
输入的 x2 里,包含了它的词本身的含义,以及前面 今天 的上下文信息
路由器看到 x2 后,判断它属于 "日常话题",就把它路由给擅长处理日常文本的专家
专家处理完 x2,输出一个新的向量,这个向量里就包含了更丰富的 "天气" 相关语义(比如晴天、雨天、和 "今天" 的关联)

备注
向量形式:xt 是一个高维向量(比如 512/1024/4096 维),不是单个数字,每一个维度都代表模型学到的某种特征
上下文依赖:同一个词(比如 银行)在不同句子里,对应的 xt 是不一样的,因为上下文不同,模型的理解也不同
可学习:模型训练的过程,本质上就是在学习如何更新每一层的 xt,让它能更准确地捕捉语义信息
Pareto frontier 帕雷托前沿
多目标权衡最优解集:无法再做到「一个指标变好、其他指标不变差」的所有组合点,连成的曲线 / 边界就是帕累托前沿
目标 1:推理速度越快越好
目标 2:精度越高越好
提速 → 大概率精度下降
提精度 → 大概率速度变慢
不存在一个方案同时做到最快 + 最准
落在前沿线上:最优权衡点,改任何一个都会牺牲另一个
在线内部:还有优化空间,能同时提速又提准
在线外部:不可能达到