文章目录
摘要
本周继续延续上周的工作,在寻找内容匹配相关的解决办法,阅读了论文Visual Matching Is Enough for Scene Text Retrieval,理解论文处理的流程,并对自己的数据集架构做了一些实验。
Abstract
This week continued the work from last week, looking for solutions related to content matching, reading the paper 'Visual Matching Is Enough for Scene Text Retrieval,' understanding the process handled in the paper, and conducting some experiments on my own dataset architecture.
1 Visual Matching Is Enough for Scene Text Retrieval
作者的意图是场景文本检测,在一组风格文本图片中,检索出自己需要的内容的图片。
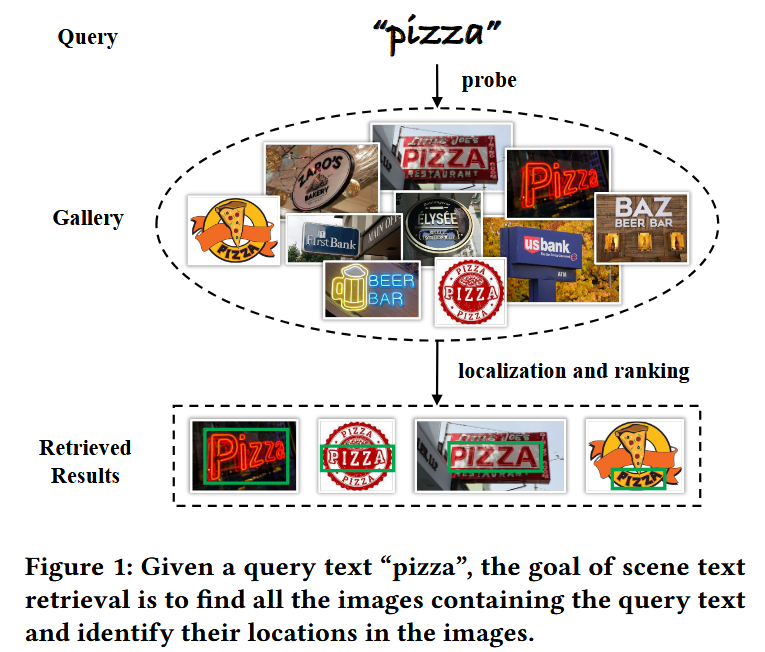
示意图
作者的做法是将输入的单词查询(Query)每一个单词生成单个的固定大小的Glyph图片,这是为了保存每一个单词的特征,避免连续渲染破坏掉单词的单独的特征,然后将这些单个的Glyph拼接成一个长的Glyph图片。
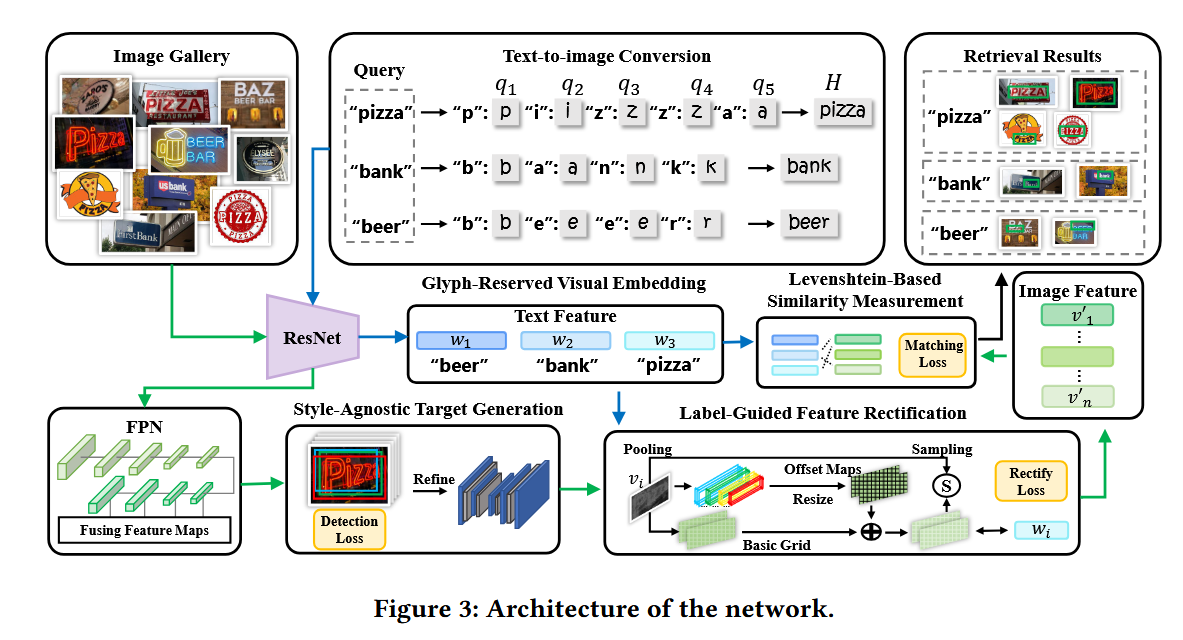
示意图
首先将Gallery经过ResNet提取到特征,然后将Gallery提取到的特征输入FCOS生成候选框,然后将候选框和文字区域计算检测损失(Detection Loss),检测出文本区域之后,经过一个重构网络,将特征重构为检测图,这个检测图要经过流形场预测,就是要把Gallery的文本区域经过流形场与Query的对齐,计算一个对齐损失,与此同时,拼接好的Query也经过ResNet提取特征,得到每个文本查询的特征,将流形场对齐之后的Gallery和Query计算匹配损失。 匹配损失计算如下:

示意图
要对Query特征,Gallery特征、Gallery特征、Gallery特征、Qeury特征、QUery特征之间分别计算损失,最后相加作为match损失。流形场的预测损失由Glyph来监督。
2 实验
作者并没有公开源码,但是模型的逻辑理解也不困难,我在此之上有所实现,但是前提是我的数据集没有检测区域的标签,那么就意味着应用不了检测损失。首先是不需要检测损失的实验。
python
rect_loss = F.mse_loss(output['f1_rect'], output['f2'])
f1_norm = F.normalize(output['f1_pool'], dim=1)
f2_norm = F.normalize(output['f2_pool'], dim=1)
text = batch['text']
i_matrix = f1_norm @ f1_norm.T # [特征,特征]
c_matrix = self.similarity_matrix(text, text) # [内容,内容]
g_matrix = f2_norm @ f2_norm.T
matrix = f1_norm @ f2_norm.T
ff_loss = F.smooth_l1_loss(i_matrix, c_matrix)
tt_loss = F.smooth_l1_loss(g_matrix, c_matrix)
ft_loss = F.smooth_l1_loss(matrix, c_matrix)只计算形变损失和匹配损失,训练时发现rect_loss下降得很快,迅速从0.3下降到0.003,那么意味着模型大概率已经坍塌了,推测原因是由于没有检测损失定位文本区域,受制于复杂的背景,模型学习背景的特征通过形变对齐Glyph的特征,所以模型没有学习到任何的特征。
于是就在思考寻找一个可以替代内容检测损失的监督项,认为可以采用交叉注意力热图来表示监督区域,Gallery图片和Qeury图片之间只有内容相似,那么由Glyph得到的内容特征和Gallery之间计算注意力,得到的热图更多的关注的就是文本区域。
再加入一个对比损失,由文本编辑距离作为软标签,避免模型不学习Glyph内容特征,从而掩码失效
python
rect_loss = F.mse_loss(output['f1_rect'], output['f2'])
f1_norm = F.normalize(output['f1_pool'], dim=1)
f2_norm = F.normalize(output['f2_pool'], dim=1)
text = batch['text']
i_matrix = f1_norm @ f1_norm.T # [特征,特征]
c_matrix = self.similarity_matrix(text, text) # [内容,内容]
g_matrix = f2_norm @ f2_norm.T
matrix = f1_norm @ f2_norm.T
ff_loss = F.smooth_l1_loss(i_matrix, c_matrix)
tt_loss = F.smooth_l1_loss(g_matrix, c_matrix)
ft_loss = F.smooth_l1_loss(matrix, c_matrix)
info_loss, var_loss = self.info_loss(g_matrix,c_matrix,0.05)在训练时发现模型仍然是过拟合的,而且可视化热力图发现,对于全图都是均匀的红色,没有任何注意力关注到了内容区域,意味着编辑距离作为软标签是不合理的,模型还是在坍塌。

示意图
那么意味着resnet提取到的还不是内容特征,那么就要限制从Glyph提取到的真的是内容特征,既然可以限制ResNet可以提取出内容特征,还是需要内容匹配的,因为ResNet提取内容特征是在Glyph这种简单的条件下,对于Gallery这种复杂情况可能会失效,所以还需要论文的工作来解决泛化的问题。
总结
经过理解和实验,发现在我的数据集上还不能work,具体的原因是没有强制提取内容特征,那么问题就移动到在Glyph中提取内容特征。