一、问题背景
某 Windows Server 2016 服务器上部署了一套 Oracle 11g 数据库,实例名为 MONITOR。
日常巡检时发现数据库本地连接异常,执行:
sqlplus / as sysdba返回:
已连接到空闲例程。继续查询实例状态:
select instance_name, status from v$instance;报错:
ORA-01034: ORACLE not available从现象看,Oracle 服务似乎存在,但数据库实例并未正常可用。
二、初步确认 Oracle 服务状态
首先检查 Windows 上 Oracle 服务:
sc query OracleServiceMONITOR结果显示:
STATE : 4 RUNNING说明 OracleServiceMONITOR 服务处于运行状态。
继续查看 Oracle 进程:
tasklist | findstr /I oracle结果显示存在 oracle.exe 进程。
进一步查看进程命令行:
wmic process where "name='oracle.exe'" get ProcessId,CommandLine输出类似:
e:\oracle\app\administrator\product\11.2.0\dbhome_1\bin\ORACLE.EXE MONITOR这里说明:Oracle 进程存在,且对应实例名为 MONITOR。
但是,本地连接仍然显示"空闲例程",说明不能简单认为"服务 RUNNING = 数据库正常 OPEN"。
三、检查监听状态
继续查看监听:
lsnrctl status发现监听中只有:
Service "CLRExtProc" 包含 1 个实例。没有看到类似:
Service "MONITOR" has 1 instance(s).
Instance "MONITOR", status READY这说明数据库实例没有正常注册到监听,进一步验证了实例状态异常。
四、查看 Oracle alert 日志
找到 alert 日志:
dir /s /b E:\oracle\app\Administrator\diag\rdbms\*alert*.log找到路径:
E:\oracle\app\Administrator\diag\rdbms\monitor\monitor\trace\alert_monitor.log查看最后 120 行:
powershell -Command "Get-Content 'E:\oracle\app\Administrator\diag\rdbms\monitor\monitor\trace\alert_monitor.log' -Tail 120"发现关键错误:
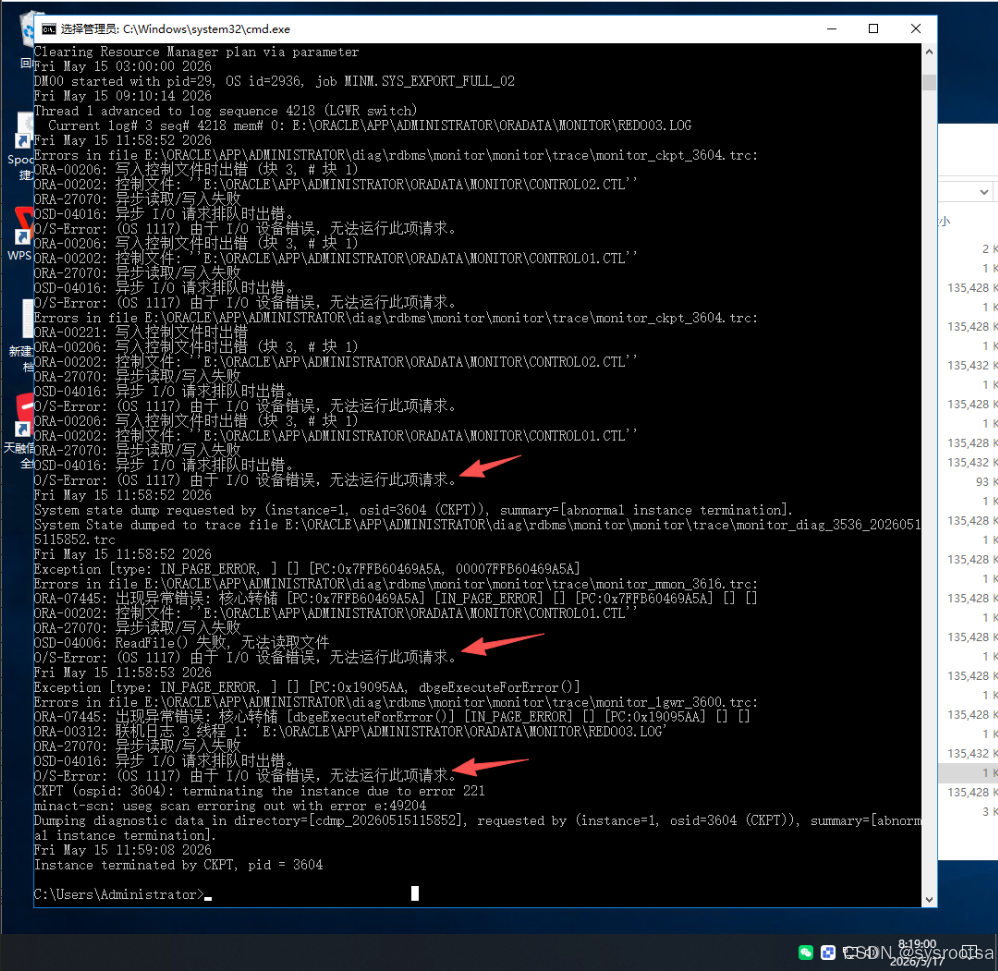
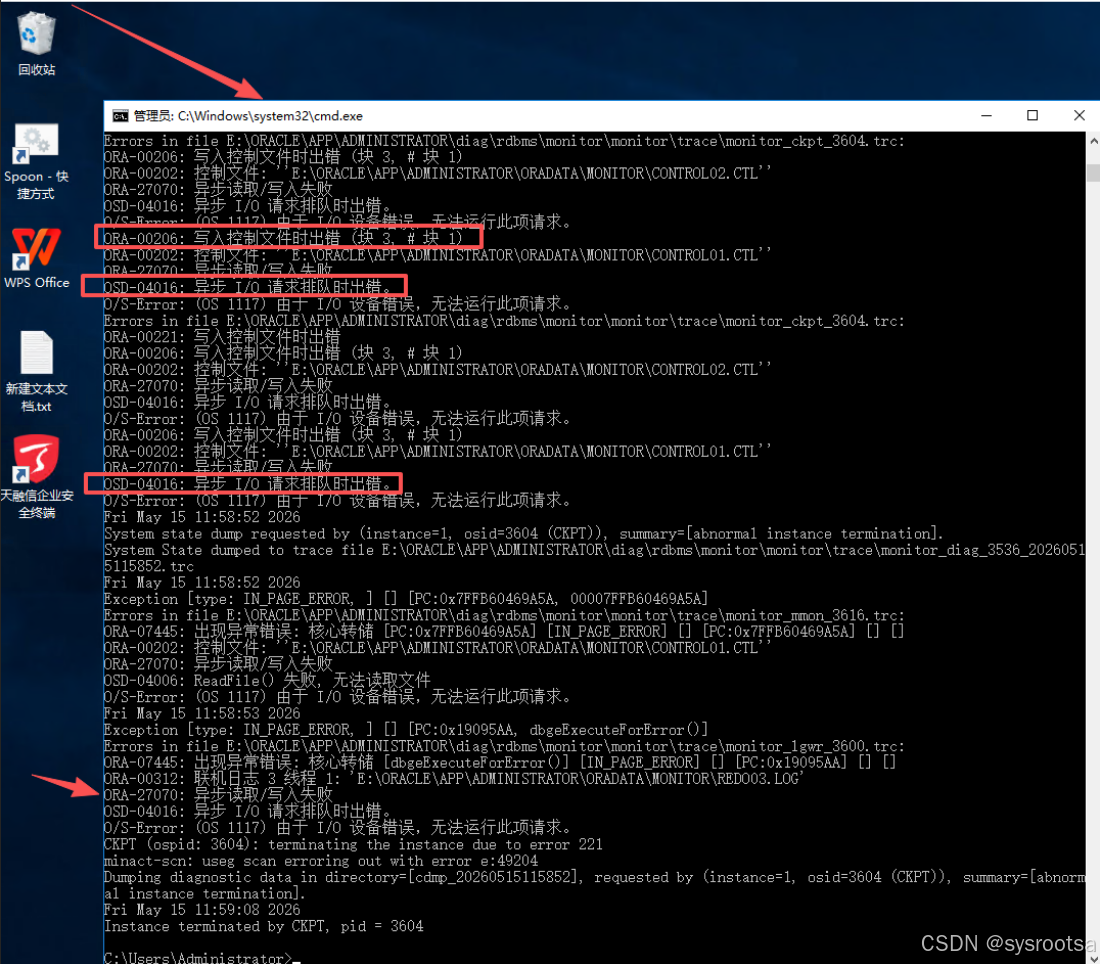
ORA-00206: 写入控制文件时出错
ORA-00202: 控制文件: 'E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR\CONTROL02.CTL'
ORA-27070: 异步读取/写入失败
O/S-Error: (OS 1117) 由于 I/O 设备错误,无法运行此项请求。同时还有:
ORA-00312: 联机日志 3 线程 1: 'E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR\REDO03.LOG'
ORA-27070: 异步读取/写入失败
CKPT terminating the instance due to error 221
Instance terminated by CKPT至此基本可以判断:
数据库实例不是正常关闭,而是因为控制文件、redo 日志写入失败,被 CKPT 进程异常终止。
这已经不是普通数据库参数或监听问题,而是底层存储 I/O 异常引发的数据库实例异常。
五、检查 Windows 系统日志
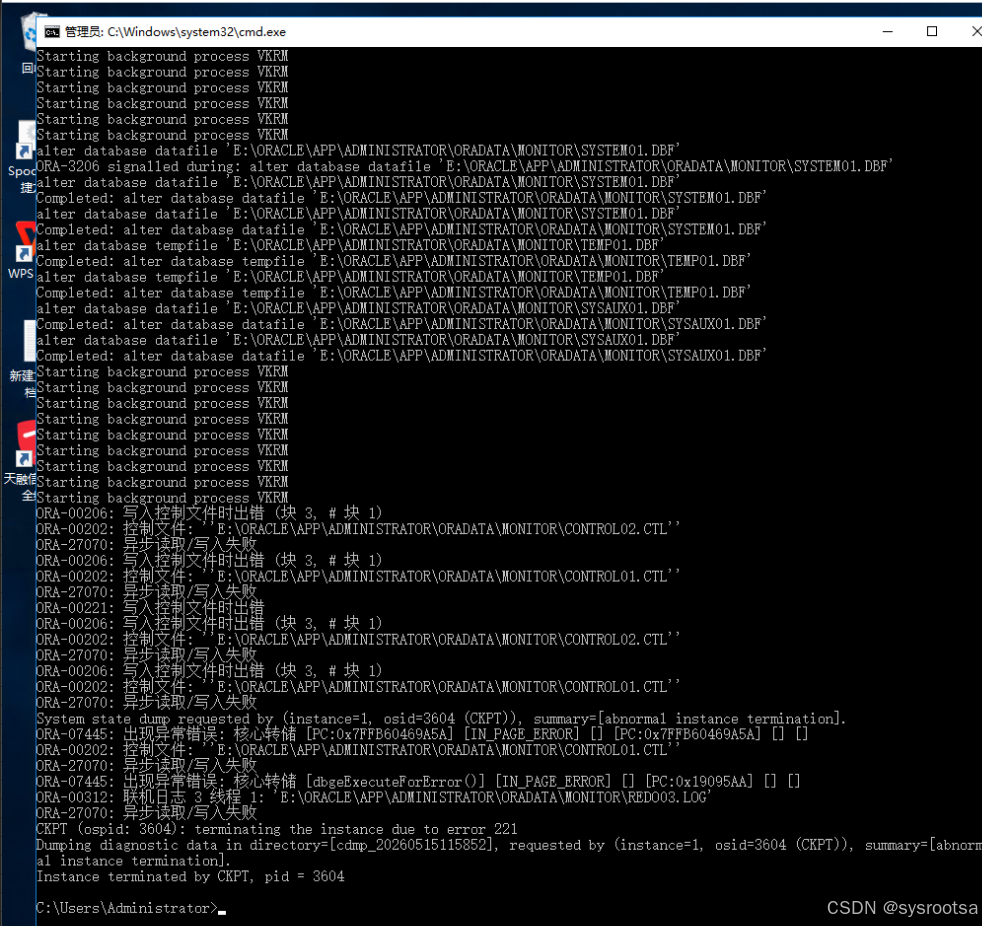
继续查看 Windows System 日志,发现磁盘相关告警:
Source: Disk
Event ID: 153
已在磁盘 2 的逻辑块地址处重试 IO 操作。同时还有:
Source: LSI_SAS
Event ID: 129
发出了对设备 \Device\RaidPort0 的重置。这与 Oracle alert 日志中的 OS 1117 I/O 设备错误 完全对应。
初步判断为:磁盘 2 所在的虚拟磁盘或底层存储链路发生过 I/O 抖动,导致 Oracle 控制文件和 redo 日志写入失败。
六、确认磁盘 2 对应的盘符
执行:
powershell -Command "Get-Disk | Format-Table Number,FriendlyName,SerialNumber,HealthStatus,OperationalStatus,Size -Auto"输出显示:
Number FriendlyName HealthStatus OperationalStatus Size
------ ------------ ------------ ----------------- ----
2 VMware Virtual disk Healthy Online 214748364800继续确认磁盘 2 的分区:
powershell -Command "Get-Partition -DiskNumber 2 | Format-Table DiskNumber,PartitionNumber,DriveLetter,Size,Type -Auto"结果显示:
DiskNumber PartitionNumber DriveLetter Size
---------- --------------- ----------- ----
2 2 E 214612049920可以确认:
磁盘 2 = E 盘而 Oracle 控制文件、redo、数据文件都位于:
E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR故障链路已经非常清晰:
磁盘 2 / E 盘 I/O 异常
↓
控制文件、redo 写入失败
↓
CKPT 进程终止 Oracle 实例
↓
数据库无法正常连接七、检查 E 盘文件系统状态
为了确认当前文件系统是否仍然异常,执行:
fsutil dirty query E:结果:
卷 - E: 没有损坏再做只读检查:
chkdsk E:结果显示:
Windows 已扫描文件系统并且没有发现问题。
无需采取进一步操作。
坏扇区 0 KB。说明当前 E 盘文件系统层面没有发现明显错误,但这不能否认之前发生过 I/O 异常。
这类问题常见于虚拟化平台、存储链路、阵列、控制器瞬时抖动,事后文件系统可能恢复正常,但数据库实例已经被异常终止。
八、确认 Oracle 关键文件是否存在
检查控制文件:
dir E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR\CONTROL*.CTL检查 redo 日志:
dir E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR\REDO*.LOG检查数据文件:
dir E:\ORACLE\APP\ADMINISTRATOR\ORADATA\MONITOR\*.DBF确认 CONTROL01.CTL、CONTROL02.CTL、REDO01.LOG、REDO02.LOG、REDO03.LOG 以及各数据文件均存在,且不是 0 字节。
这一步很关键:
文件存在且大小正常,说明具备尝试恢复实例的基础条件。
九、重启 Oracle 服务恢复
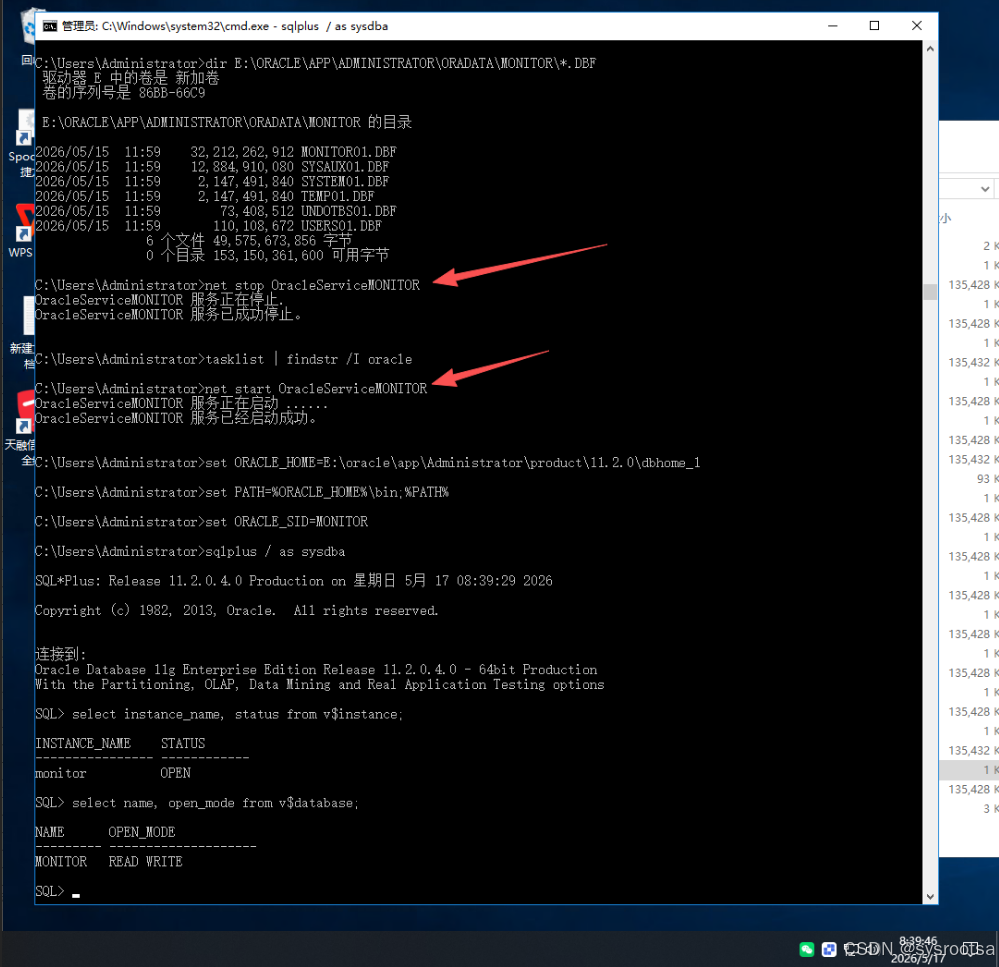
在确认当前 E 盘文件系统状态正常、Oracle 关键文件存在后,安排维护窗口重启 Oracle 服务。
执行:
net stop OracleServiceMONITOR确认 oracle.exe 进程已退出:
tasklist | findstr /I oracle然后启动服务:
net start OracleServiceMONITOR重新设置 Oracle 环境变量:
set ORACLE_HOME=E:\oracle\app\Administrator\product\11.2.0\dbhome_1
set PATH=%ORACLE_HOME%\bin;%PATH%
set ORACLE_SID=MONITOR登录数据库:
sqlplus / as sysdba验证实例状态:
select instance_name, status from v$instance;验证数据库打开状态:
select name, open_mode from v$database;如果返回类似:
INSTANCE_NAME STATUS
---------------- ------------
MONITOR OPEN以及:
NAME OPEN_MODE
--------- ----------
MONITOR READ WRITE说明数据库实例已经恢复成功。
十、故障总结
本次问题表面现象是 Oracle 数据库无法正常连接,执行 sqlplus / as sysdba 后显示"已连接到空闲例程",查询实例时报 ORA-01034。
进一步排查发现:
-
Windows Oracle 服务虽然处于
RUNNING,但数据库实例并未正常可用。 -
Oracle alert 日志显示控制文件、redo 日志写入失败。
-
Windows System 日志出现 Disk 153 I/O 重试和 LSI_SAS 129 RaidPort 重置。
-
磁盘映射确认 Disk 2 对应 E 盘,而 Oracle 数据文件、控制文件、redo 均位于 E 盘。
-
初步判断为 E 盘所在虚拟磁盘或底层存储链路发生 I/O 异常,导致 Oracle 实例被 CKPT 进程异常终止。
-
经检查当前 E 盘文件系统正常、Oracle 关键文件存在后,重启 Oracle 服务,数据库恢复正常。
十一、经验教训
这次故障有一个很重要的提醒:
Windows 服务 RUNNING,不代表 Oracle 数据库一定 OPEN。
Oracle 在 Windows 平台上,可能出现服务仍在、进程仍在,但实例已经异常终止或不可用的情况。
判断数据库是否真正正常,不能只看服务状态,还要结合:
select instance_name, status from v$instance;
select name, open_mode from v$database;同时,遇到 ORA-01034、ORA-27101 时,不要只盯着 Oracle 本身,还要查看:
Oracle alert 日志
Windows System 日志
磁盘 I/O 告警
存储/虚拟化平台事件数据库是跑在操作系统和存储之上的,底层 I/O 一抖,数据库就可能当场"倒地"。
排障时别只看数据库表象,要把 OS、磁盘、存储链路一起串起来看。这个链路打通了,问题就不玄学了。