arvix:https://arxiv.org/pdf/1511.07247
参考代码:https://github.com/Nanne/pytorch-NetVlad
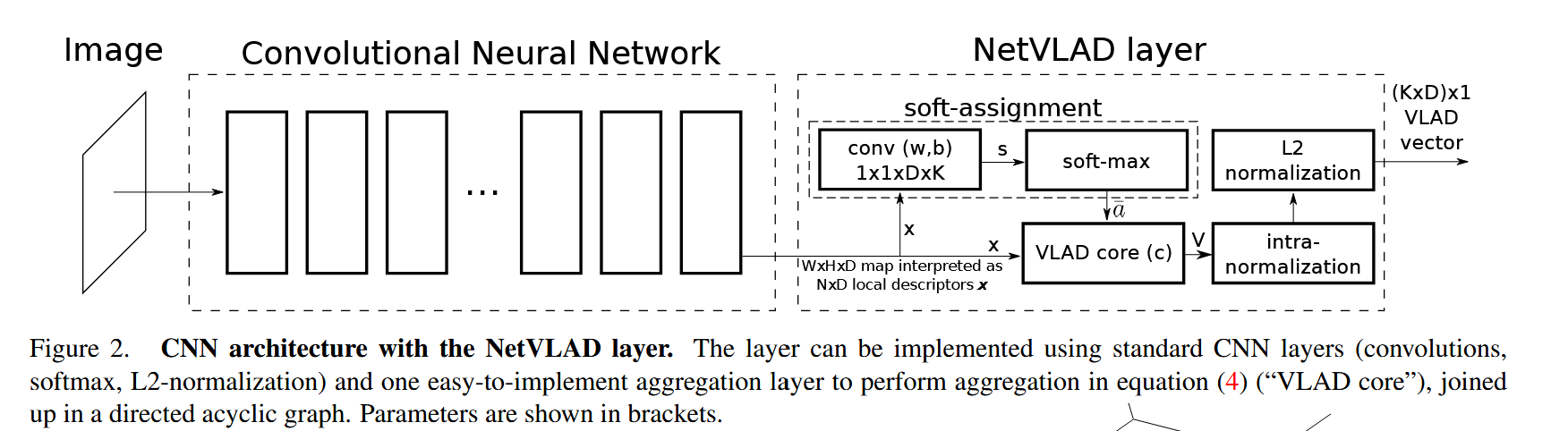
基于论文 NetVLAD: CNN architecture for weakly supervised place recognition,整个网络的结构可以总结为以下三个主要阶段:
1. 基础卷积特征提取器
- 采用 AlexNet 或 VGG-16 作为骨干网络
- 截断 到最后一个卷积层(conv5,即 ReLU 激活之前)
- 输出特征图的尺寸为 H×W×DH \times W \times DH×W×D
- 可以理解为:在 H×WH \times WH×W 个空间位置上,每个位置有一个 DDD 维的局部描述子(即 conv5 的激活向量)
- 对于 Max 池化(Baseline)版本,不使用额外归一化;对于 NetVLAD 版本,先对每个 DDD 维描述子做 L2 归一化(描述子间归一化)
2. NetVLAD 聚合层(核心创新)
输入 :H×W×DH \times W \times DH×W×D 的特征图(即 N=H×WN = H \times WN=H×W 个 DDD 维描述子)
内部操作:
-
1×11 \times 11×1 卷积
- KKK 个滤波器 {wk}\{w_k\}{wk},每个是 DDD 维,加上偏置 bkb_kbk
- 输出得分:sk(xi)=wkTxi+bks_k(x_i) = w_k^T x_i + b_ksk(xi)=wkTxi+bk
-
Softmax 沿聚类维度
- 软分配权重:aˉk(xi)=ewkTxi+bk∑k′ewk′Txi+bk′\bar{a}k(x_i) = \frac{e^{w_k^T x_i + b_k}}{\sum{k'} e^{w_{k'}^T x_i + b_{k'}}}aˉk(xi)=∑k′ewk′Txi+bk′ewkTxi+bk
-
残差聚合
- 对每个聚类 kkk,计算加权残差和:V:,k=∑i=1Naˉk(xi)⋅(xi−ck)V_{:,k} = \sum_{i=1}^{N} \bar{a}_k(x_i) \cdot (x_i - c_k)V:,k=i=1∑Naˉk(xi)⋅(xi−ck)
- ckc_kck 是可学习的聚类中心(DDD 维向量),输出矩阵 VVV 大小为 K×DK \times DK×D,KKK个聚类生成的VVV(DDD维向量)
-
归一化
- 列内 L2 归一化,展平为 K⋅DK \cdot DK⋅D 维向量,再整体 L2 归一化
输出 :(K⋅D)(K \cdot D)(K⋅D) 维全局图像描述子。
3. 可选的后处理(PCA + 白化)
- 将 K⋅DK \cdot DK⋅D 维向量降维(如 256256256 维),进行白化和 L2 归一化。
4. 整体结构流程
text
输入图像 (3×H×W)
↓
CNN骨干网络 (截断于 conv5)
↓
conv5 特征图 (H'×W'×D)
↓
[可选] 描述子间 L2 归一化
↓
NetVLAD 层:
- 1×1 卷积 + Softmax → 软分配权重 (特征图CHW 转换为 KHW,每个点对K个聚类的得分)
- 加权残差聚合 → K×D 矩阵 (计算上方的V,V大小为特征通CHW中的C,有K个聚类,为KC)
- 展平 + L2 归一化
↓
(K×D) 维全局描述子
↓
[可选] PCA + 白化 + L2 归一化
↓
最终紧凑描述子5. 训练时的损失函数
弱监督三元组排序损失:
Lθ=∑jmax(minidθ2(q,piq)+m−dθ2(q,njq), 0) L_{\theta} = \sum_{j} \max\left( \min_{i} d_{\theta}^2(q, p_i^q) + m - d_{\theta}^2(q, n_j^q),\; 0 \right) Lθ=j∑max(imindθ2(q,piq)+m−dθ2(q,njq),0)
其中各符号的含义为:
- max(⋅,0)\max(\cdot, 0)max(⋅,0):铰链损失(hinge loss),当括号内值为正时取该值,否则取 0。
- mini\min_{i}mini:从查询 qqq 的潜在正例集合中,选取使距离平方最小的那个索引 iii,即最可能正例
- dθ2(q,piq)=∥fθ(q)−fθ(piq)∥2d_{\theta}^2(q, p_i^q) = \| f_{\theta}(q) - f_{\theta}(p_i^q) \|^2dθ2(q,piq)=∥fθ(q)−fθ(piq)∥2:查询 qqq 与潜在正例 piqp_i^qpiq 在特征空间中的欧氏距离的平方。
- dθ2(q,njq)d_{\theta}^2(q, n_j^q)dθ2(q,njq):查询 qqq 与负例 njqn_j^qnjq 的欧氏距离的平方。
- qqq:训练查询图像。
- piqp_i^qpiq:查询 qqq 的第 iii 个潜在正例(GPS 距离 < 10 米,至少一个是真正的同位置图像)。
- njqn_j^qnjq:查询 qqq 的第 jjj 个确定负例(GPS 距离 > 25 米,肯定不是同位置)。
举例
好的,我们把之前的例子扩展成多个负例的情况,完整演示损失计算过程。
设定
- 查询 qqq
- 潜在正例集合:p1,p2,p3p_1, p_2, p_3p1,p2,p3(距离平方已知)
- 负例集合:n1,n2,n3n_1, n_2, n_3n1,n2,n3(三个确定负例)
- margin m=0.2m = 0.2m=0.2
当前网络给出的平方欧氏距离:
| 图像 | d2d^2d2 |
|---|---|
| p1p_1p1 | 0.8 |
| p2p_2p2 | 0.3 |
| p3p_3p3 | 1.2 |
| n1n_1n1 | 0.5 |
| n2n_2n2 | 0.9 |
| n3n_3n3 | 0.4 |
步骤 1:找到最佳正例
minid2(q,pi)=min(0.8,0.3,1.2)=0.3 \min_i d^2(q, p_i) = \min(0.8, 0.3, 1.2) = 0.3 imind2(q,pi)=min(0.8,0.3,1.2)=0.3
对应 p2p_2p2。
步骤 2:对每个负例计算个体损失
损失公式:
ℓj=max(minid2(q,pi)+m−d2(q,nj), 0) \ell_j = \max\left( \min_i d^2(q, p_i) + m - d^2(q, n_j),\; 0 \right) ℓj=max(imind2(q,pi)+m−d2(q,nj),0)
负例 1 (n1n_1n1):
0.3+0.2−0.5=0.0⇒ℓ1=max(0.0,0)=0 0.3 + 0.2 - 0.5 = 0.0 \quad \Rightarrow \quad \ell_1 = \max(0.0, 0) = 0 0.3+0.2−0.5=0.0⇒ℓ1=max(0.0,0)=0
负例 2 (n2n_2n2):
0.3+0.2−0.9=−0.4⇒ℓ2=max(−0.4,0)=0 0.3 + 0.2 - 0.9 = -0.4 \quad \Rightarrow \quad \ell_2 = \max(-0.4, 0) = 0 0.3+0.2−0.9=−0.4⇒ℓ2=max(−0.4,0)=0
负例 3 (n3n_3n3):
0.3+0.2−0.4=0.1⇒ℓ3=max(0.1,0)=0.1 0.3 + 0.2 - 0.4 = 0.1 \quad \Rightarrow \quad \ell_3 = \max(0.1, 0) = 0.1 0.3+0.2−0.4=0.1⇒ℓ3=max(0.1,0)=0.1
步骤 3:总损失
Lθ=ℓ1+ℓ2+ℓ3=0+0+0.1=0.1 L_{\theta} = \ell_1 + \ell_2 + \ell_3 = 0 + 0 + 0.1 = 0.1 Lθ=ℓ1+ℓ2+ℓ3=0+0+0.1=0.1
解释
- 只有 n3n_3n3 违反了 margin 要求(距离 0.40.40.4,小于 0.3+0.2=0.50.3 + 0.2 = 0.50.3+0.2=0.5),贡献正损失 0.10.10.1。
- n1n_1n1 恰好等于边界(0.50.50.5),损失为 000。
- n2n_2n2 距离足够远(0.90.90.9),远大于 0.50.50.5,损失为 000。
训练时,梯度会主要来自 n3n_3n3(使其被推开)以及 p2p_2p2(使其被拉近),其他负例因为已经满足约束,暂不参与梯度更新(除非后续训练中它们又变成 hard negatives)。
多个负例求和的意义
- 如果只选最难的负例(这里最违反的是 n3n_3n3,损失 0.10.10.1),总损失也是 0.10.10.1,看起来一样。
- 但如果存在多个违反 margin 的负例(比如 n3n_3n3 和 n4n_4n4 都违反),求和会让总损失变大,推动模型同时处理所有违反者,而不是只关注最严重的那一个。这有助于更快的收敛和更平衡的嵌入空间。
例如,假如还有 n4n_4n4 且 d2(q,n4)=0.35d^2(q,n_4)=0.35d2(q,n4)=0.35,则:
- 对 n4n_4n4:0.3+0.2−0.35=0.150.3+0.2-0.35 = 0.150.3+0.2−0.35=0.15,损失 0.150.150.15
- 总损失变为 0.1+0.15=0.250.1 + 0.15 = 0.250.1+0.15=0.25
此时模型必须同时推开 n3n_3n3 和 n4n_4n4。
6. NetVLAD公式推理
K-means
K-means 是一种经典的聚类算法,目标是将 NNN 个数据点 {x1,x2,...,xN}\{x_1, x_2, \dots, x_N\}{x1,x2,...,xN}(每个 xi∈RDx_i \in \mathbb{R}^Dxi∈RD)划分到 KKK 个簇中,使得簇内平方和最小,KKK是超参数。
目标函数:
minC,{mk}∑k=1K∑xi∈Ck∥xi−μk∥2 \min_{C, \{m_k\}} \sum_{k=1}^{K} \sum_{x_i \in C_k} \|x_i - \mu_k\|^2 C,{mk}mink=1∑Kxi∈Ck∑∥xi−μk∥2
其中 {C1,...,CK}\{C_1, \dots, C_K\}{C1,...,CK} 是划分的簇,μk=1∣Ck∣∑xi∈Ckxi\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_iμk=∣Ck∣1∑xi∈Ckxi 是第 kkk 个簇的中心。
迭代步骤:
- 初始化 :随机选择 KKK 个点作为初始中心 μ1,...,μK\mu_1, \dots, \mu_Kμ1,...,μK。
- 分配 :将每个点 xix_ixi 分配到最近的中心:
Ck={xi:∥xi−μk∥2≤∥xi−μj∥2 ∀j} C_k = \left\{ x_i : \|x_i - \mu_k\|^2 \le \|x_i - \mu_j\|^2 \ \forall j \right\} Ck={xi:∥xi−μk∥2≤∥xi−μj∥2 ∀j} - 更新 :重新计算每个簇的中心:
μk=1∣Ck∣∑xi∈Ckxi \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1xi∈Ck∑xi - 重复步骤 2 和 3 直到中心不再变化或达到最大迭代次数。
前身VLAD
先明确 VLAD 要做什么
VLAD 的全称是 Vector of Locally Aggregated Descriptors。
输入 :一张图 → 提取出 NNN 个局部特征(比如 SIFT),每个特征是一个 DDD 维向量,例如 D=128D=128D=128。
目标 :把这 NNN 个向量聚合成一个固定大小的全局向量,用来表示整张图。
1. 建立聚类中心(视觉词典)
首先对所有图片的所有局部特征 做 K-means 聚类,得到 KKK 个聚类中心 c1,c2,...,cKc_1, c_2, \dots, c_Kc1,c2,...,cK。
每个 ckc_kck 也是一个 DDD 维向量,代表一类局部模式(比如一种角点、一种纹理)。
这一步是离线完成的。
2. VLAD 的聚合过程
对于一张图片,它的 NNN 个局部特征 xix_ixi 会被分配到最近的聚类中心。
这就是 硬分配(hard assignment):
ak(xi)={1if k=argminj∥xi−cj∥0otherwise a_k(x_i) = \begin{cases} 1 & \text{if } k = \arg\min_{j} \|x_i - c_j\| \\ 0 & \text{otherwise} \end{cases} ak(xi)={10if k=argminj∥xi−cj∥otherwise
即:每个 xix_ixi 只属于一个聚类 kkk,且那个聚类是距离它最近的。
3. 计算残差(Residual)
残差 = 描述子向量 − 聚类中心向量
xi−ck x_i - c_k xi−ck
它的维度也是 DDD。
为什么要用残差?
因为聚类中心 ckc_kck 表示"这一类特征的平均模样",残差则表示"这个具体特征和平均模样的差异"。
这样能保留更多细节,比简单计数(BoW)信息更丰富。
4. 聚合:对每个聚类,累加它内部所有特征的残差
对于每个聚类 kkk,我们将所有分配到它的描述子的残差向量求和:
Vk=∑i:ak(xi)=1(xi−ck) V_k = \sum_{i: a_k(x_i)=1} (x_i - c_k) Vk=i:ak(xi)=1∑(xi−ck)
VkV_kVk 是一个 DDD 维向量。
不同聚类之间不可能共享同一个描述子(因为硬分配),所以每个 xix_ixi 只会贡献给一个 VkV_kVk。
最终 VLAD 输出是一个 K×DK \times DK×D 的矩阵,可以展平成 K⋅DK \cdot DK⋅D 维的向量。
5. 公式对照
公式:
V(j,k)=∑i=1Nak(xi)⋅(xi(j)−ck(j)) V(j,k) = \sum_{i=1}^{N} a_k(x_i) \cdot (x_i(j) - c_k(j)) V(j,k)=i=1∑Nak(xi)⋅(xi(j)−ck(j))
- jjj 是向量的第 jjj 维(111 到 DDD)
- kkk 是第 kkk 个聚类中心(111 到 KKK)
- xi(j)x_i(j)xi(j) 是第 iii 个描述子的第 jjj 维数值
- ck(j)c_k(j)ck(j) 是第 kkk 个聚类中心的第 jjj 维数值
- ak(xi)a_k(x_i)ak(xi) 是硬分配(000 或 111)
所以:
对每个聚类 kkk,把它的所有描述子的每一维残差分别加起来 ,放入 V(j,k)V(j,k)V(j,k)。
6. 举个极简例子(假设 D=2D=2D=2, K=2K=2K=2, N=3N=3N=3)
聚类中心:
- c1=(0,0)c_1 = (0, 0)c1=(0,0)
- c2=(10,10)c_2 = (10, 10)c2=(10,10)
描述子:
- x1=(1,1)x_1 = (1, 1)x1=(1,1) → 离 c1c_1c1 近 → 属于聚类 1
- x2=(1.2,0.8)x_2 = (1.2, 0.8)x2=(1.2,0.8) → 属于聚类 1
- x3=(11,9)x_3 = (11, 9)x3=(11,9) → 离 c2c_2c2 近 → 属于聚类 2
计算:
-
对聚类 1:
x1−c1=(1,1)x_1 - c_1 = (1,1)x1−c1=(1,1)
x2−c1=(1.2,0.8)x_2 - c_1 = (1.2, 0.8)x2−c1=(1.2,0.8)求和 = (2.2,1.8)(2.2, 1.8)(2.2,1.8) → 这是 V:,1V_{:,1}V:,1
-
对聚类 2:
x3−c2=(1,−1)x_3 - c_2 = (1, -1)x3−c2=(1,−1)求和 = (1,−1)(1, -1)(1,−1) → 这是 V:,2V_{:,2}V:,2
VLAD 矩阵:
V=2.211.8−1 V = \begin{bmatrix} 2.2 & 1 \\ 1.8 & -1 \end{bmatrix} V=2.21.81−1
展平为向量:2.2,1.8,1,−12.2, 1.8, 1, -12.2,1.8,1,−1
7. 最后归一化
通常两步归一化(论文中提到):
- 列内归一化 (intra-normalization):对每个 VkV_kVk 单独 L2 归一化
- 整体 L2 归一化:把展平后的整个向量再归一化
最终得到用于比较的图像向量。
8. 硬分配的问题(为 NetVLAD 做铺垫)
硬分配不可微分,因为 ak(xi)a_k(x_i)ak(xi) 是阶跃函数。
所以无法在 CNN 中反向传播优化聚类中心。
NetVLAD 用 软分配 (softmax 权重)替代 0/10/10/1 权重,使得梯度可以流过,从而可以端到端训练。
总结:传统 VLAD 一句话解释
VLAD 把局部特征按最近邻聚类中心分组,对每组内所有特征与中心之差求和,得到一个能捕捉局部模式偏移量的全局向量。
对VLAD的改进
目标:让 VLAD 可微分
传统 VLAD 中:
- 硬分配 ak(xi)∈{0,1}a_k(x_i) \in \{0,1\}ak(xi)∈{0,1} (非 0 即 1)
- 梯度无法通过它传播 → 无法在 CNN 中端到端训练
NetVLAD 的核心思路:
把硬分配改成软分配(可微分配权重),并允许聚类中心等参数被训练。
1. 软分配公式(原版)
先给出一个连续的、可微的权重 ,而不是 0/10/10/1:
aˉk(xi)=e−α∥xi−ck∥2∑k′e−α∥xi−ck′∥2 \bar{a}k(x_i) = \frac{e^{-\alpha \|x_i - c_k\|^2}}{\sum{k'} e^{-\alpha \|x_i - c_{k'}\|^2}} aˉk(xi)=∑k′e−α∥xi−ck′∥2e−α∥xi−ck∥2
- α>0\alpha > 0α>0 是一个控制"软硬程度"的参数
- 分母:对所有聚类求和,确保所有权重加起来 =1= 1=1
- 当 α→+∞\alpha \to +\inftyα→+∞ 时,权重会趋近于硬分配(最近的那个聚类权重 →1\to 1→1,其他 →0\to 0→0)
这样,每个描述子 xix_ixi 不再只属于一个聚类,而是按相似度给所有聚类都分配一个 000~111 的权重。
这一公式已经是可微的(因为只有指数、平方、除法),但作者还做了进一步的化简,让它更便于实现。
2. 化简为 Softmax 形式
展开平方:
∥xi−ck∥2=xiTxi−2ckTxi+ckTck \|x_i - c_k\|^2 = x_i^T x_i - 2 c_k^T x_i + c_k^T c_k ∥xi−ck∥2=xiTxi−2ckTxi+ckTck
代入指数:
e−α∥xi−ck∥2=e−αxiTxi⋅e2αckTxi⋅e−αckTck e^{-\alpha \|x_i - c_k\|^2} = e^{-\alpha x_i^T x_i} \cdot e^{2\alpha c_k^T x_i} \cdot e^{-\alpha c_k^T c_k} e−α∥xi−ck∥2=e−αxiTxi⋅e2αckTxi⋅e−αckTck
注意 e−αxiTxie^{-\alpha x_i^T x_i}e−αxiTxi 这个因子与 kkk 无关,因此可以在分子和分母中约掉,得到:
aˉk(xi)=e2αckTxi−αckTck∑k′e2αck′Txi−αck′Tck′ \bar{a}k(x_i) = \frac{e^{2\alpha c_k^T x_i - \alpha c_k^T c_k}}{\sum{k'} e^{2\alpha c_{k'}^T x_i - \alpha c_{k'}^T c_{k'}}} aˉk(xi)=∑k′e2αck′Txi−αck′Tck′e2αckTxi−αckTck
现在定义:
- wk=2αckw_k = 2\alpha c_kwk=2αck (一个 DDD 维向量)
- bk=−α∥ck∥2b_k = -\alpha \|c_k\|^2bk=−α∥ck∥2 (一个标量)
那么:
aˉk(xi)=ewkTxi+bk∑k′ewk′Txi+bk′ \bar{a}k(x_i) = \frac{e^{w_k^T x_i + b_k}}{\sum{k'} e^{w_{k'}^T x_i + b_{k'}}} aˉk(xi)=∑k′ewk′Txi+bk′ewkTxi+bk
这就是标准的 Softmax 函数形式。
3. 关键变化:参数解耦
传统 VLAD 只有一组参数 {ck}\{c_k\}{ck}(聚类中心)。
在 NetVLAD 中:
- 原本 wkw_kwk 和 bkb_kbk 是由 ckc_kck 和 α\alphaα 计算得出的(受约束关系)
- 但论文 不再强制这种关系 ,而是把 {wk,bk,ck}\{w_k, b_k, c_k\}{wk,bk,ck} 当作独立的可训练参数
也就是说:
- wk,bkw_k, b_kwk,bk 负责软分配(决定描述子属于哪个聚类的权重)
- ckc_kck 负责残差计算 (xi−ckx_i - c_kxi−ck)
它们可以分开学习,互不绑定。
这比原始 VLAD 更灵活,因为分配方式和残差中心可以针对任务独立优化。
4. NetVLAD 的最终输出公式
把软分配权重代入传统 VLAD 的公式:
V(j,k)=∑i=1NewkTxi+bk∑k′ewk′Txi+bk′⋅(xi(j)−ck(j)) V(j,k) = \sum_{i=1}^{N} \frac{e^{w_k^T x_i + b_k}}{\sum_{k'} e^{w_{k'}^T x_i + b_{k'}}} \cdot \big( x_i(j) - c_k(j) \big) V(j,k)=i=1∑N∑k′ewk′Txi+bk′ewkTxi+bk⋅(xi(j)−ck(j))
对比传统 VLAD:
| 项目 | 传统 VLAD | NetVLAD |
|---|---|---|
| 分配权重 | ak(xi)∈{0,1}a_k(x_i) \in \{0,1\}ak(xi)∈{0,1} | softmax 权重 ∈(0,1)\in (0,1)∈(0,1) |
| 分配参数 | 由 ckc_kck 隐式决定 | 独立参数 wk,bkw_k, b_kwk,bk |
| 残差中心 | ckc_kck | 独立参数 ckc_kck |
| 可微性 | 不可微 | 可微(所有参数可训练) |
5. 网络实现上的好处
如图 2 所示(论文中):
- 输入:conv5 输出的 H×W×DH \times W \times DH×W×D 特征图
- 1×11 \times 11×1 卷积 :用 KKK 个滤波器 wkw_kwk + 偏置 bkb_kbk → 输出 H×W×KH \times W \times KH×W×K 的得分图
- Softmax :沿 KKK 维度做 softmax → 软分配权重图
- 聚合层 :对每个空间位置,用权重加权残差 (xi−ck)(x_i - c_k)(xi−ck) 并求和
- 归一化:L2 归一化(列内 + 整体)
全部操作都是标准 CNN 算子(卷积、softmax、求和、L2 norm),可以直接集成到任何 CNN 中,并用反向传播训练。
6. 直观理解:为什么解耦有用?
论文图 3 给了个例子:
- 两个不同图片的局部描述子(红、绿)可能被分到同一个聚类区域。
- 传统 VLAD 的残差中心 ckc_kck 是聚类中心(×\times×),可能让两个残差的向量点积较大(导致不匹配的图像也得分高)。
- 如果允许独立学习 wk,bkw_k, b_kwk,bk 来重新调整分配权重,同时独立学习残差中心 ckc_kck(例如移动到 ⋆\star⋆ 位置),就可以让不匹配的描述子对彼此贡献更小。
也就是说:
NetVLAD 可以"重分配"描述子到更合适的残差中心,即使这些中心不是数据聚类的几何中心。
总结:NetVLAD 对 VLAD 的三大改进
| 改进点 | 说明 |
|---|---|
| 软分配 | 用 softmax 权重代替硬 0/10/10/1,可微分 |
| 参数解耦 | wk,bkw_k, b_kwk,bk 控制分配,ckc_kck 控制残差,均可独立训练 |
| 端到端学习 | 整个聚合层可嵌入 CNN,用 SGD 直接优化最终目标(如地点识别) |
这样就回答了"怎么让 VLAD 变得可微并可训练"。
如果你愿意,下一步我可以结合 代码层面 或 反向传播的梯度流 再讲一层。
7. 核心代码分析
def forward(self, x):
N, C = x.shape[:2]
if self.normalize_input:
x = F.normalize(x, p=2, dim=1) # across descriptor dim
# soft-assignment
soft_assign = self.conv(x).view(N, self.num_clusters, -1)
soft_assign = F.softmax(soft_assign, dim=1)
x_flatten = x.view(N, C, -1)
# calculate residuals to each clusters
vlad = torch.zeros([N, self.num_clusters, C], dtype=x.dtype, layout=x.layout, device=x.device)
for C in range(self.num_clusters): # slower than non-looped, but lower memory usage
residual = x_flatten.unsqueeze(0).permute(1, 0, 2, 3) - \
self.centroids[C:C+1, :].expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
residual *= soft_assign[:,C:C+1,:].unsqueeze(2)
vlad[:,C:C+1,:] = residual.sum(dim=-1)
vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
vlad = vlad.view(x.size(0), -1) # flatten
vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize
return vlad
markdown
以下是 NetVLAD 核心代码的逐段解释,结合之前介绍的理论公式。
```python
def forward(self, x):
N, C = x.shape[:2] # N: batch size, C: descriptor dim (e.g. 256 for AlexNet)输入 x 是 CNN 最后一个卷积层输出的特征图,形状为 [N, C, H, W]。可以看作 N 张图像,每张图有 H*W 个局部描述子,每个描述子是 C 维向量。
python
if self.normalize_input:
x = F.normalize(x, p=2, dim=1) # across descriptor dim对应理论 :论文中提到对 NetVLAD 的输入描述子进行 L2 归一化(描述子间归一化)。
dim=1 表示对每个描述子向量(C 维)做 L2 归一化,使每个描述子模长为 1。这能提高数值稳定性,并与传统 VLAD 中使用 RootSIFT 归一化的做法一致。
1. 计算软分配权重
python
# soft-assignment
soft_assign = self.conv(x).view(N, self.num_clusters, -1)
soft_assign = F.softmax(soft_assign, dim=1)-
self.conv是一个 1×1 卷积层 ,输入通道数C,输出通道数self.num_clusters(即聚类数K)。对应理论中的
w_k和b_k:每个滤波器产生一个得分图s_k(x_i) = w_k^T x_i + b_k。输出形状为
[N, K, H, W]。 -
view(N, self.num_clusters, -1)将空间位置展平 → 形状[N, K, L],其中L = H*W。现在
soft_assign的第三维是空间位置索引i。 -
F.softmax(soft_assign, dim=1)沿聚类维度(dim=1)做 softmax,得到软分配权重:
aˉk(xi)=ewkTxi+bk∑k′ewk′Txi+bk′ \bar{a}k(x_i) = \frac{e^{w_k^T x_i + b_k}}{\sum{k'} e^{w_{k'}^T x_i + b_{k'}}} aˉk(xi)=∑k′ewk′Txi+bk′ewkTxi+bk形状仍为
[N, K, L]。
2. 准备描述子
python
x_flatten = x.view(N, C, -1) # [N, C, L]将输入特征图 [N, C, H, W] 展平成 [N, C, L],其中每张图的 L 个描述子按列排列。
3. 计算每个聚类的 VLAD 向量
python
vlad = torch.zeros([N, self.num_clusters, C], dtype=x.dtype, layout=x.layout, device=x.device)
for k in range(self.num_clusters):
residual = x_flatten.unsqueeze(0).permute(1, 0, 2, 3) - \
self.centroids[k:k+1, :].expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
residual *= soft_assign[:, k:k+1, :].unsqueeze(2)
vlad[:, k:k+1, :] = residual.sum(dim=-1)这段代码较难读,我们拆解其数学本质(避免被 permute 迷惑):
self.centroids是形状[K, C]的可学习参数,对应公式中的残差中心c_k。- 对于每个聚类
k:- 计算残差 :对于所有描述子
x_i,计算x_i - c_k。 - 加权 :乘以该聚类的软分配权重
soft_assign[:, k, :](形状[N, L]),并广播到C维。 - 求和 :对
L个位置求和,得到该聚类的 VLAD 向量V_k(形状[N, C])。
- 计算残差 :对于所有描述子
简化后的等效代码(更易理解):
python
for k in range(self.num_clusters):
# (1) 残差: x_flatten - centroids[k] -> [N, C, L]
residual = x_flatten - self.centroids[k][:, None] # 广播
# (2) 加权: 乘以软分配权重 -> [N, C, L]
weighted = residual * soft_assign[:, k, :].unsqueeze(1)
# (3) 求和: 沿 L 维度 -> [N, C]
vlad[:, k, :] = weighted.sum(dim=-1)对应公式:
V(:,k)=∑i=1Laˉk(xi)⋅(xi−ck) V(:,k) = \sum_{i=1}^{L} \bar{a}_k(x_i) \cdot (x_i - c_k) V(:,k)=i=1∑Laˉk(xi)⋅(xi−ck)
注意这里 V(:,k) 是 D 维向量(C = D),矩阵 V 形状为 [N, K, C]。
4. 归一化
python
vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
vlad = vlad.view(x.size(0), -1) # flatten: [N, K*C]
vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize-
dim=2归一化 :对每个聚类k内的C维向量分别做 L2 归一化。这是论文中提到的 列内归一化(intra-normalization),对应传统 VLAD 的改进 3。
-
展平 :将
[N, K, C]变成[N, K*C]的全局描述子。 -
整体 L2 归一化:对每个图像的完整描述子做 L2 归一化,使最终向量位于单位超球面上,便于用欧氏距离比较。
代码与理论对照表
| 理论组件 | 代码实现 |
|---|---|
| 输入描述子 xix_ixi | x_flatten 形状 [N, C, L] |
| 描述子 L2 归一化(可选) | F.normalize(x, dim=1) |
| 1×1 卷积计算得分 wkTxi+bkw_k^T x_i + b_kwkTxi+bk | self.conv(x) |
| 软分配权重 aˉk\bar{a}_kaˉk | softmax(conv_output, dim=1) |
| 残差中心 ckc_kck | self.centroids[k] |
| 加权残差和 Vk=∑aˉk(xi−ck)V_k = \sum \bar{a}_k (x_i - c_k)Vk=∑aˉk(xi−ck) | 循环内 residual * soft_assign[:,k] 并 sum |
| 列内归一化 | F.normalize(vlad, dim=2) |
| 展平并整体 L2 归一化 | view + F.normalize(dim=1) |
注意事项
- 代码中
for C in range(self.num_clusters)中的C与通道数C重名,实际应为for k in range(self.num_clusters)。原代码写法有误导,但逻辑正确。 - 循环可以用矩阵运算加速(例如
torch.einsum),但作者选择循环以降低内存占用。
最终输出 vlad 就是论文中描述的 NetVLAD 全局图像描述子,可以直接用于地点识别或图像检索。