文章目录
摘要
本周主要学习了变分自编码器 VAE 的基本原理、正向传播过程和损失函数构成。VAE 通过 Encoder 输出均值和标准差,构造隐变量的概率分布,再从中采样得到隐变量 z,并由 Decoder 完成数据重建,从而实现生成任务。
Abstract
This week, we mainly learned the basic principle, forward propagation process and loss function composition of the variational self encoder VAE. VAE outputs the mean and standard deviation through the encoder, constructs the probability distribution of the hidden variable, and then samples the hidden variable Z, and the data is reconstructed by the decoder, so as to realize the generation task.
自编码器 AE 与变分自编码器 VAE
自编码器AE
是一种无监督学习模型,主要用于学习数据的有效表示。它的基本结构由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责将原始输入数据压缩成一个低维的隐含表示,也可以理解为提取数据中的核心特征;解码器则根据这个隐含表示尽可能还原出原始数据。模型训练的目标是让输出结果与输入数据尽可能接近,因此自编码器本质上是在"压缩---重建"的过程中学习数据内部的规律。
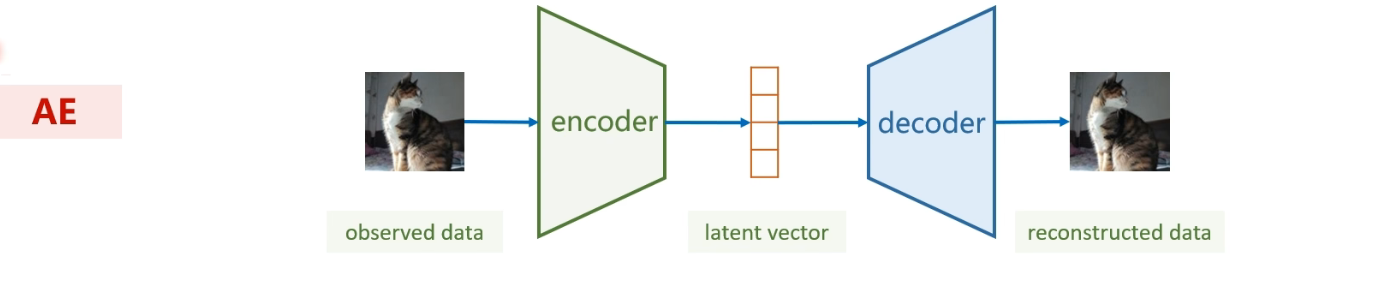
在实际应用中,AE 常用于数据降维、特征提取、图像去噪、异常检测等任务。
VAE的基本架构
与普通自动编码器一样,变分自动编码器有编码器Encoder与解码器Decoder两大部分组成,原始图像从编码器输入,经编码器后形成隐式表示(Latent Representation),之后隐式表示被输入到解码器、再复原回原始输入的结构。然而,与普通Autoencoders不同的是,变分自用编码器的Encoder与Decoder在数据流上并不是相连的,我们不会直接将Encoder编码后的结果传递给Decoder,而是要使得隐式表示满足既定分布。
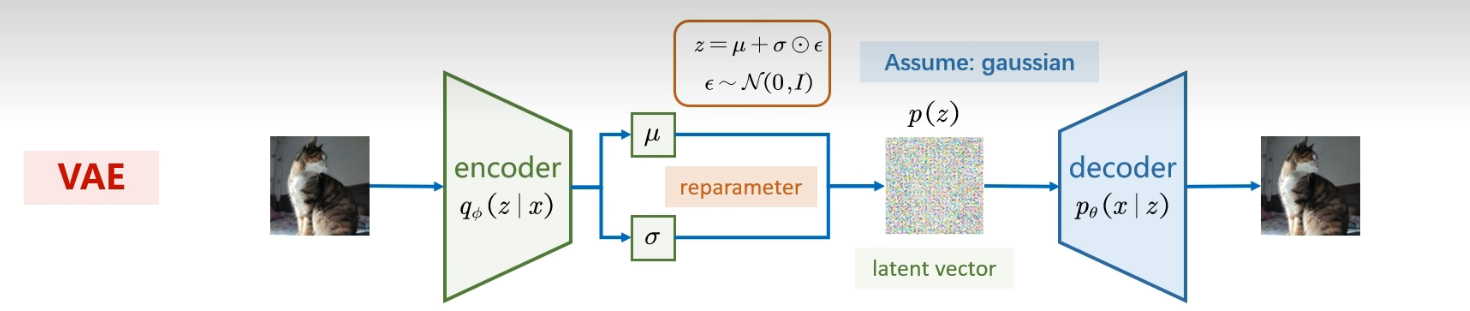
变分自编码器 VAE 的 Encoder 并不会像普通 AE 那样直接输出一个固定的隐式表示,而是会根据输入数据输出两个参数:均值 μ 和 标准差 σ。随后,模型会根据这两个参数构造一个正态分布,并从该分布中随机采样得到隐变量 z,再将 z 输入到 Decoder 中进行解码。
对于 Decoder 来说,它接收到的并不是原始数据被压缩后的某一个确定表示,而是从与原始数据相关的概率分布中采样得到的信息。也就是说,VAE 传递给 Decoder 的是带有概率特征的隐变量,而不是单一、固定的隐式编码。
问题来了,AE能否作为一个生成模型呢?
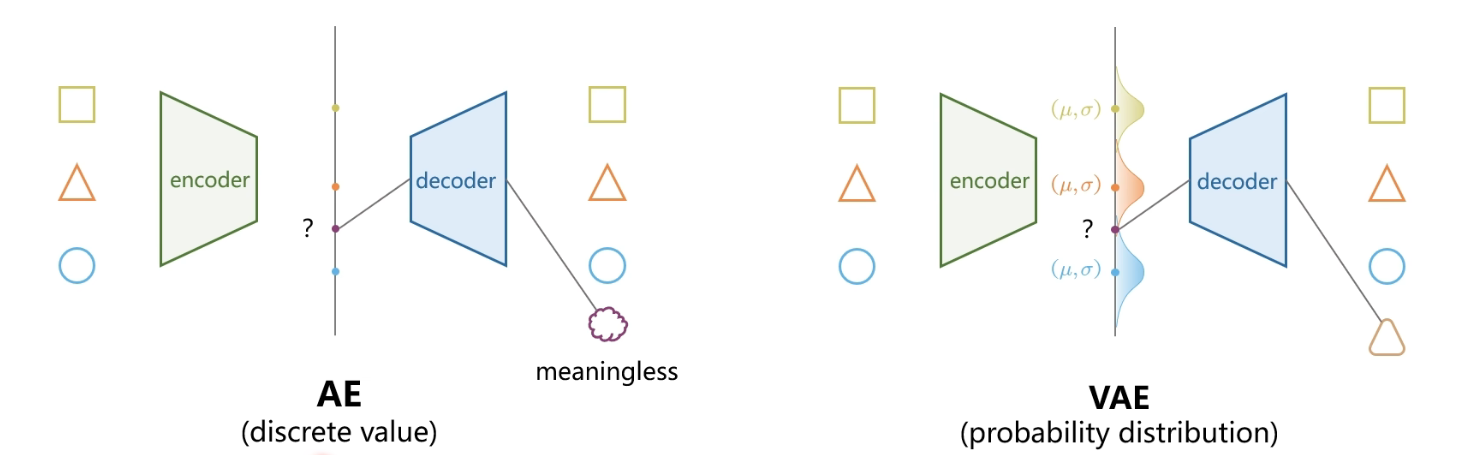
AE 不能很好地作为生成模型,是因为它编码后得到的是一个个确定的离散隐变量点,潜在空间不连续、不规则。随机取一个隐变量输入解码器时,可能落在模型没有学习过的区域,生成结果容易没有意义。
VAE 可以作为生成模型,是因为它编码得到的不是单个点,而是一个概率分布,并且通过约束让潜在空间更加连续、规则。这样就可以从潜在空间中随机采样,再通过解码器生成新的、有意义的数据。
因此AE 主要适合重建,VAE 既能重建,也能通过随机采样生成新样本。
VAE的正向传播
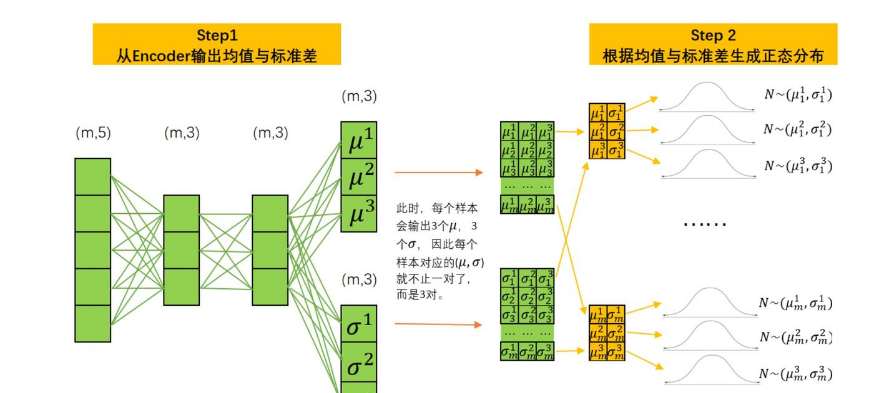
原始数据共有 m 个样本,每个样本有 5 个特征,因此输入数据的形状为 (m, 5)。数据经过 Encoder 后,Encoder 不会直接输出隐变量,而是为每个样本分别生成一个均值 μ 和一个标准差 σ。由于一共有 m 个样本,并且每个样本只对应一组均值和标准差,所以 μ 和 σ 的形状都是 (m, 1)。随后,每个样本都会根据自己的 μ 和 σ 构造一个正态分布,并从该分布中采样得到隐变量 z。最后,将采样得到的 z 输入 Decoder,由 Decoder 尽可能重建出原始的 5 个特征。
损失函数
VAE 的损失函数主要解决两个问题:一是让隐变量的分布更加规则,二是让模型能够尽可能还原原始输入。VAE 的损失函数由两部分组成:KL 散度损失和重建损失。
第一部分是 KL 散度损失。Encoder 根据输入样本 x 推断出隐变量 z 的分布,也就是𝑞𝜙(𝑧∣𝑥)。但是为了让模型后续可以方便地随机采样生成数据,我们希望这个分布尽量接近一个固定的先验分布 p(z),通常设为标准正态分布。因此,KL 散度的作用就是衡量𝑞𝜙(𝑧∣𝑥)和 p(z) 之间的差距。KL 散度越小,说明 Encoder 输出的隐变量分布越接近标准正态分布,隐空间也就越规则。
第二部分是 重建损失。从 Encoder 得到隐变量分布后,模型会采样得到 z,再将 z 输入 Decoder,生成重建结果 x′。为了保证生成结果不是随机无意义的,Decoder 输出的 x′应该尽可能接近原始输入 x。因此,重建损失用来衡量原始数据和重建数据之间的差距,常见形式有均方误差 MSE 或交叉熵损失。
所以,VAE的损失函数可以理解为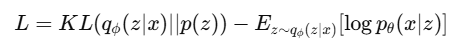
前一项是 KL 散度损失,负责约束隐变量分布;后一项可以理解为 重建损失,负责保证 Decoder 能够根据 z 还原出接近原始输入的数据。
总结
通过本次学习,我理解了 VAE 与普通 AE 的主要区别。AE 更侧重于数据压缩和重建,而 VAE 通过概率分布约束隐空间,使其更加连续和规则。VAE 的损失函数兼顾重建效果和分布约束,因此具备生成新样本的能力。