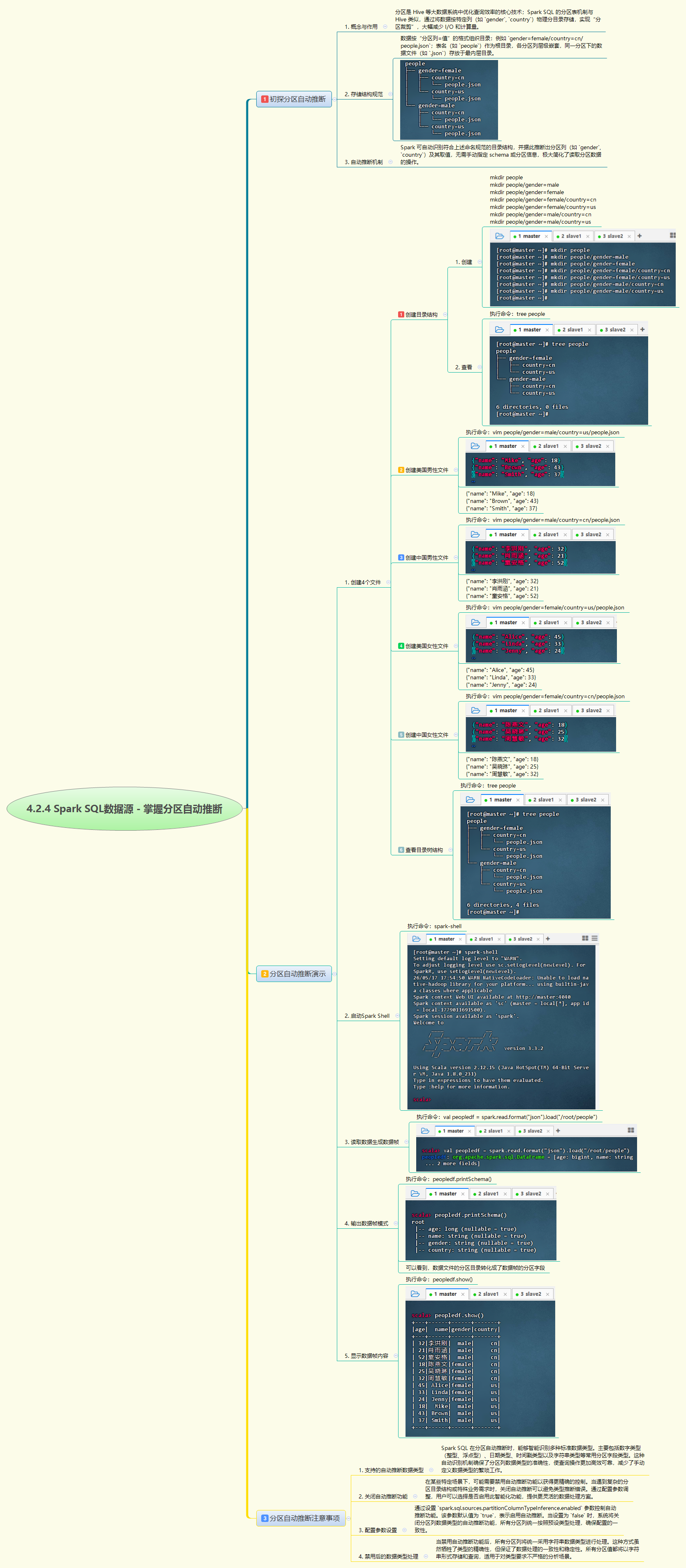
分区自动推断是Spark SQL的重要特性,它能自动识别符合"分区列=值"规范的目录结构并将其转化为数据帧的分区字段。实战中需先按规范创建嵌套目录结构,如gender=female/country=cn/,并将JSON数据文件存入对应分区目录。启动Spark Shell后使用spark.read.format("json").load()读取根目录,Spark会自动推断出gender和country为分区列,无需手动指定schema。该功能支持数字、日期、时间戳、字符串等类型自动推断,也可通过配置spark.sql.sources.partitionColumnTypeInference.enabled参数进行控制。
4.2.4 Spark SQL数据源 - 掌握分区自动推断
howard20052026-05-18 8:25