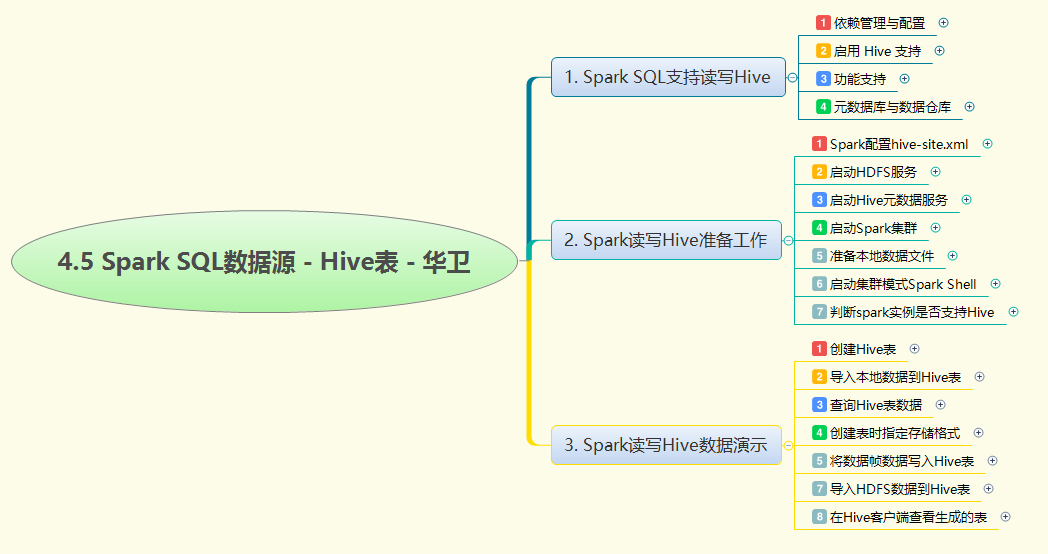
Spark SQL 与 Hive 集成实战展示了如何在 Spark 环境中操作 Hive 数据。首先需配置 hive-site.xml 文件,确保 Spark 能够访问 Hive 的元数据库,并启动 HDFS、Hive 元数据服务及 Spark 集群。接着,在 Spark Shell 中验证 Hive 支持是否生效。
实战中通过 Spark SQL 创建了 student 表,定义了 id、name、gender、age 字段,并使用 LOAD DATA LOCAL INPATH 将本地数据导入表中。随后演示了多种查询操作,包括全表查询和按性别分组统计平均年龄。此外,还创建了采用 Parquet 列式存储格式的 t_parquet 表,展示了不同存储格式的优势。
进一步地,实战演示了将数据帧处理结果写入新表的功能,通过 filter 和 select 操作提取男生数据并保存为 boy_student 表。最后,还展示了从 HDFS 导入数据到 Hive 表的完整流程,并在 Hive 客户端验证了所有创建的表及其数据,充分验证了 Spark 与 Hive 的无缝集成能力。