本次实战深入讲解Spark SQL中Parquet文件的处理机制与Schema合并技术。Parquet作为列式存储格式,具备Schema自动保存和空值兼容性等优势。实战中通过read.parquet()和write.parquet()完成基本读写操作,重点掌握SaveMode配置解决目录冲突。核心内容是Schema合并功能,通过spark.read.option("mergeSchema", true)或spark.sql.parquet.mergeSchema配置启用,能自动整合不同结构但相容的Parquet文件。通过具体案例演示先写入(name,age)再写入(name,score),最终合并为完整三列结构,配合groupBy聚合实现数据整合,展现了Spark SQL在处理异构数据源时的强大能力。
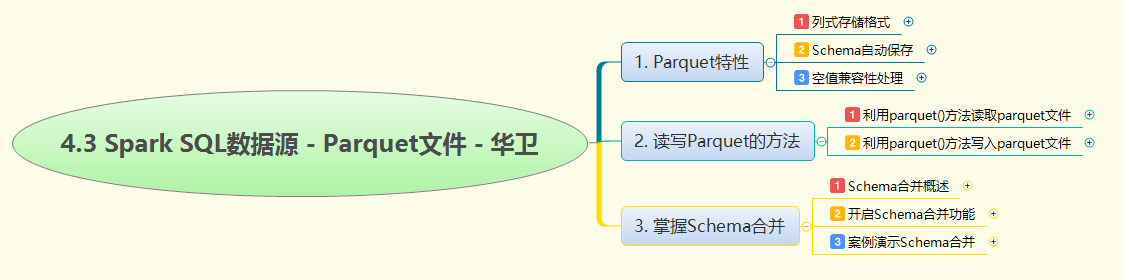
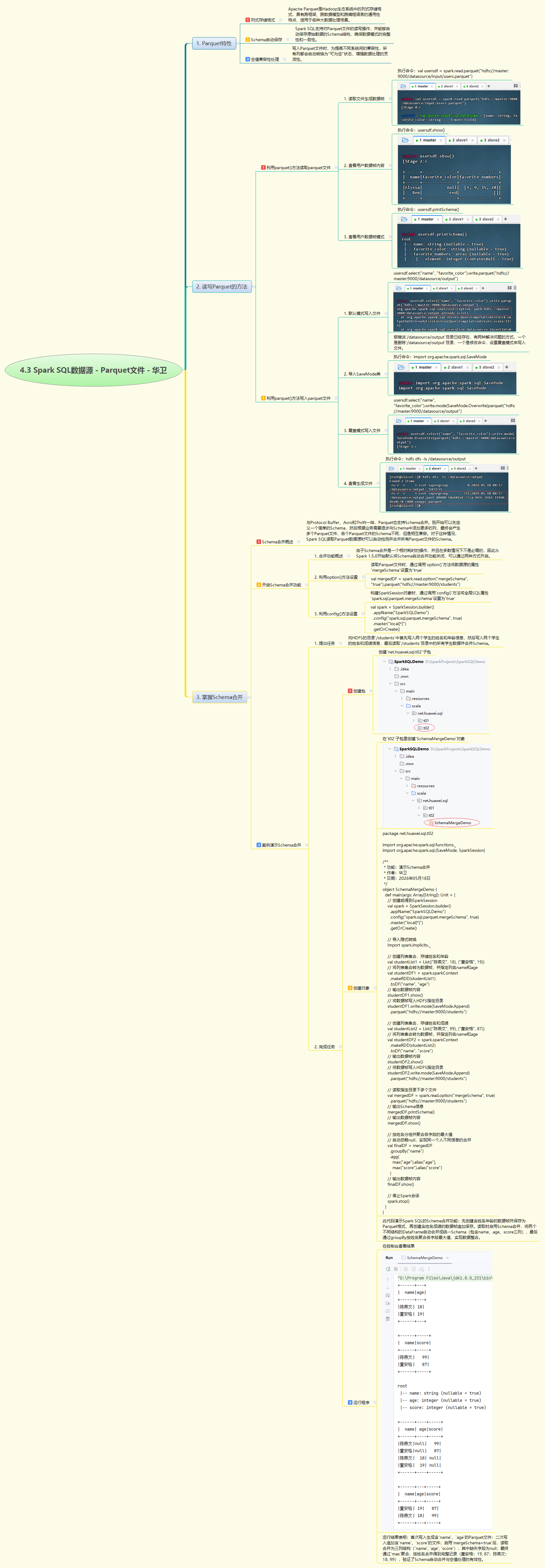
4.3 Spark SQL数据源 - Parquet文件
howard20052026-05-19 18:15