文章目录
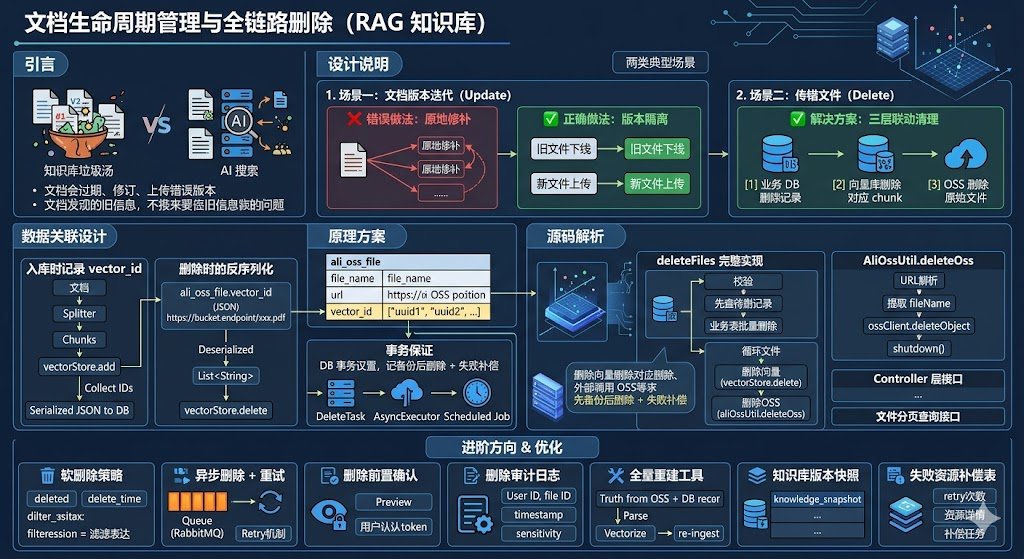
引言
知识库不是一次性建立就万事大吉的。文档会过期、会修订、会上传错误版本。如果不能优雅地处理"更新"和"删除",向量库很快就会变成一锅杂乱的"垃圾汤"------新旧内容混在一起,AI 回答时会从过期或错误的内容中检索信息。
本篇将解析项目中文档生命周期管理的设计:从 OSS、向量库到业务表的"全链路清洗"机制。
设计说明
两类典型场景
场景一:文档版本迭代(Update)
例如《公司报销制度》每年更新,需要把旧版本替换为新版本。
❌ 错误做法:原地修补
试图找出旧文档的几百个 chunk,逐一对比内容,只更新变动的部分。这条路在工程上是灾难性的:
- 逻辑极其复杂(需要语义对比)
- 容易产生数据碎片
- 一旦更新错了无法回滚
✅ 正确做法:版本隔离
把每个文档当作一个独立的"知识库单元"。文档更新 = 删除旧版 + 上传新版。如果业务需要保留历史,可以让旧文件不删除,只是从用户的"可见列表"中下线。
场景二:传错文件(Delete)
例如运营人员误将一份涉密 Excel 上传到了公开知识库,必须立即彻底删除。
✅ 解决方案:三层联动清理
[1] 业务 DB 删除文件记录
↓
[2] 向量库删除对应 chunk
↓
[3] OSS 删除原始文件任何一层残留,都可能造成信息泄露或检索污染。
数据关联设计
整个删除链路能跑通的前提,是入库时就建立了完整的关联:
ali_oss_file 表
├── file_name # 业务可读
├── url # OSS 物理位置
└── vector_id # JSON 数组,记录所有 chunk 的向量库 IDvector_id 是关键。入库时把每个 chunk 在 Milvus 中的 ID 序列化为 JSON 数组存起来,删除时反序列化逐个删除。
为什么不直接按 source 元数据删除?
理论上可以这样:
java
vectorStore.delete("source == 'xxx.pdf'");但有几个问题:
- 不同向量库支持不同:Milvus 的 expression 语法和别家不一样,跨库迁移困难
- 元数据可能重复:同一文件名可能上传过多次,删除会误伤
- 删除时机不一致:业务表删除成功了,向量库可能因为表达式问题失败
显式记录 vector_id 是最稳的方式。
原理方案
入库时记录 vector_id
java
List<Document> splitDocuments = tokenTextSplitter.apply(documents);
vectorStore.add(splitDocuments);
// 收集所有 chunk 的 ID
List<String> ids = splitDocuments.stream()
.map(Document::getId)
.collect(Collectors.toList());
aliOssFileService.save(AliOssFile.builder()
.fileName(originalFilename)
.vectorId(JSON.toJSONString(ids))
.url(url)
.createTime(new Date())
.updateTime(new Date())
.build());vectorStore.add(documents) 内部会为每个 Document 分配 UUID 作为 ID(如果没有显式设置)。这些 ID 就是后续删除时的依据。
删除时的反序列化
java
List<String> vectorIds = JSON.parseArray(aliOssFile.getVectorId(), String.class);
vectorStore.delete(vectorIds);把 TEXT 字段中存的 JSON 数组反序列化为 List<String>,调用 vectorStore.delete(ids) 批量删除。
事务保证
业务表的删除应该用事务保证原子性:
java
@Transactional(rollbackFor = Exception.class)
public BaseResponse deleteFiles(List<Long> ids) {
// ...
}但要注意:vectorStore.delete() 和 aliOssUtil.deleteOss() 是外部资源调用,不在事务范围内。即使这两步失败,业务表的删除也会提交。
更稳的方案是"先备份后删除 + 失败补偿":
java
// 1. 先记录待删除的资源
DeleteTask task = new DeleteTask();
task.setVectorIds(vectorIds);
task.setOssUrl(url);
deleteTaskService.save(task);
// 2. 删除业务表(事务内)
fileService.removeByIds(ids);
// 3. 异步执行外部删除
asyncExecutor.submit(() -> {
vectorStore.delete(vectorIds);
aliOssUtil.deleteOss(url);
deleteTaskService.markDone(task.getId());
});
// 4. 定时任务扫描未完成的 DeleteTask 重试源码解析
deleteFiles 完整实现
java
@Override
@Transactional(rollbackFor = Exception.class)
public BaseResponse deleteFiles(List<Long> ids) {
// 1. 校验
if (ids.isEmpty()) {
return ResultUtils.error(ErrorCode.PARAMS_ERROR, "请选择文件");
}
// 2. 查询待删除的文件记录
List<AliOssFile> aliOssFiles = aliOssFileMapper.selectByIds(ids);
// 3. 业务表删除
int count = aliOssFileMapper.deleteBatchIds(ids);
if (count == 0) {
return ResultUtils.error(ErrorCode.OPERATION_ERROR, "删除失败");
}
// 4. 全链路清理
for (AliOssFile aliOssFile : aliOssFiles) {
// 4.1 删除向量库中的 chunk
List<String> vectorIds = JSON.parseArray(aliOssFile.getVectorId(), String.class);
vectorStore.delete(vectorIds);
// 4.2 删除 OSS 原始文件
aliOssUtil.deleteOss(aliOssFile.getUrl());
}
return ResultUtils.success("成功删除" + count + "个文件");
}逐步解析:
- 先查后删 :必须先
selectByIds拿到完整记录(含 vector_id 和 url),否则删除后这些信息就丢了 - 业务表先删:先删 ali_oss_file 表的记录,确认删除成功后再清理外部资源
- 批量循环:每个文件分别清理向量和 OSS
- JSON 反序列化 :
JSON.parseArray(vectorId, String.class)把 TEXT 字段还原为 List
Controller 层接口
java
@Operation(summary = "delete", description = "文件删除")
@DeleteMapping("/delete")
public BaseResponse deleteFiles(@RequestParam List<Long> ids) {
return aliOssFileService.deleteFiles(ids);
}支持批量删除,前端可以勾选多个文件一次性清理。
AliOssUtil.deleteOss 实现
java
public boolean deleteOss(String objectName) {
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
URL url = new URL(objectName);
// 从 URL 中提取 OSS 的 objectName(去掉前导斜杠)
String fileName = url.getPath().replaceFirst("/", "");
ossClient.deleteObject(bucketName, fileName);
} catch (MalformedURLException e) {
throw new RuntimeException(e);
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
return true;
}注意点:
- 业务表存的是完整 URL(如
https://bucket.endpoint/xxx.pdf),需要先解析出 path replaceFirst("/", "")去掉前导斜杠,得到 OSS 的 objectName- 删除后释放 OSSClient,避免连接泄漏
文件分页查询接口
java
@Override
public BaseResponse queryPage(QueryFileDTO request) {
Page<AliOssFile> page = new Page<>(request.getPage(), request.getPageSize());
IPage<AliOssFile> fileList = aliOssFileMapper.findByFileNameContaining(page, request.getFileName());
return ResultUtils.success(fileList);
}支持按文件名模糊搜索,前端展示已上传的所有文档。
文档更新的实现思路
项目代码中没有显式的"更新"接口,但可以基于"删除 + 重新上传"实现:
java
@PostMapping("/update")
@Transactional(rollbackFor = Exception.class)
public BaseResponse updateFile(
@RequestParam Long oldFileId,
@RequestParam("file") MultipartFile newFile) {
// 1. 删除旧文件(业务表 + 向量库 + OSS)
aliOssFileService.deleteFiles(Collections.singletonList(oldFileId));
// 2. 上传新文件(走原有 upload 流程)
return uploadSingle(newFile);
}或者保留旧文件,新文件作为新的版本:
java
// 旧文件状态置为 ARCHIVED,从用户列表中下线
aliOssFile.setStatus("ARCHIVED");
aliOssFileService.updateById(aliOssFile);
// 新文件正常入库
uploadSingle(newFile);验证结果
单文件删除
请求:
DELETE /api/v1/knowledge/delete?ids=1响应:
json
{
"code": 0,
"data": "成功删除1个文件"
}验证:
-
业务表:
sqlSELECT * FROM ali_oss_file WHERE id = 1; -- (返回空) -
向量库:通过 Attu 查询 vector_store collection,确认对应 chunk 已删除
-
OSS:登录阿里云控制台,确认对应文件已不存在
批量删除
请求:
DELETE /api/v1/knowledge/delete?ids=1,2,3响应:
json
{ "code": 0, "data": "成功删除3个文件" }容错测试
场景:向量库连接断开时删除
预期:业务表删除成功,向量库删除抛出异常,导致整个事务回滚(rollbackFor = Exception.class)。
实际:因为 vectorStore.delete 在事务内调用,异常会触发回滚。但这里有个隐患------OSS 已经被删除(OSS 操作不可回滚)。
更稳的实现需要"补偿队列"机制,前面已经讨论过。
优化方向
软删除策略
物理删除不可恢复,运营误操作会造成大麻烦。可以引入软删除:
sql
ALTER TABLE ali_oss_file ADD COLUMN deleted TINYINT DEFAULT 0;
ALTER TABLE ali_oss_file ADD COLUMN delete_time TIMESTAMP NULL;
java
public BaseResponse softDelete(List<Long> ids) {
UpdateWrapper<AliOssFile> uw = new UpdateWrapper<>();
uw.set("deleted", 1)
.set("delete_time", new Date())
.in("id", ids);
aliOssFileService.update(uw);
// 同时把向量库的对应 chunk 加上 metadata 标记
// 检索时 filter expression 排除 deleted=1
return ResultUtils.success("已删除");
}定时任务清理"已删除超过 30 天"的记录,真正释放资源。
异步删除 + 重试
业务接口快速返回,外部资源清理放到队列:
java
@DeleteMapping("/delete")
public BaseResponse deleteFiles(@RequestParam List<Long> ids) {
// 1. 业务表标记为待删除
aliOssFileService.markPendingDelete(ids);
// 2. 推送到 RabbitMQ
rabbitTemplate.convertAndSend("delete.queue", ids);
// 3. 立即返回
return ResultUtils.success("删除请求已提交");
}
@RabbitListener(queues = "delete.queue")
public void handleDelete(List<Long> ids) {
// 真正执行删除,失败时 reject 重新入队
}删除前置确认
对涉密文件做二次确认:
java
// 1. 调用 /delete/preview,返回将要删除的资源详情
// 2. 用户确认
// 3. 调用 /delete/confirm,传入 token(来自 preview 接口)防止误删。
删除审计日志
java
@Loggable
@DeleteMapping("/delete")
public BaseResponse deleteFiles(@RequestParam List<Long> ids) {
log.warn("用户 {} 删除文件: {}", BaseContext.getCurrentId(), ids);
return aliOssFileService.deleteFiles(ids);
}任何敏感数据操作都应留痕,便于事后审计。
全量重建工具
如果向量库数据出现严重不一致,可以基于 ali_oss_file 表 + OSS 中的原始文件重建:
java
public void rebuildVectorStore() {
// 1. 清空 Milvus collection
vectorStore.delete(allIds);
// 2. 遍历 ali_oss_file
for (AliOssFile file : aliOssFileService.list()) {
// 3. 从 OSS 下载
byte[] bytes = aliOssUtil.download(file.getUrl());
// 4. 重新解析 + 向量化 + 入库
List<Document> docs = parse(bytes);
vectorStore.add(docs);
// 5. 更新 vector_id
file.setVectorId(JSON.toJSONString(docs.stream().map(Document::getId).toList()));
aliOssFileService.updateById(file);
}
}OSS 中的原始文件是最可靠的"真相源",永远保留。
知识库版本快照
每次大规模更新前打个快照:
sql
CREATE TABLE knowledge_snapshot AS SELECT * FROM ali_oss_file;或者把 vector_id 做成版本化的:
v1.vector_id_for_file_1
v2.vector_id_for_file_1回滚就是切换到旧版本。
失败资源补偿表
专门一张表记录"删除失败待重试"的资源:
sql
CREATE TABLE delete_compensation (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
resource_type VARCHAR(20), -- 'vector' / 'oss'
resource_id TEXT,
retry_count INT DEFAULT 0,
last_error TEXT,
created_at TIMESTAMP,
completed BOOLEAN DEFAULT FALSE
);定时任务扫描未完成的,按指数退避策略重试。
小结
本篇梳理了文档生命周期管理:
- 入库时记录 vector_id,是后续删除的关键
- "业务表 → 向量库 → OSS"三层联动清理
- 事务能保证业务表的原子性,但外部资源需要补偿机制
- 文档更新 = 删除旧版 + 上传新版,避免原地修补
进阶方向:软删除、异步队列、版本快照、补偿重试。
下一篇将聚焦"防幻觉与召回率优化"------如何让 RAG 系统更可靠、更准确。
