前一篇文章说了FFT在聚合风险精算模型中的顶层思路,下面再介绍一些中观的思想。
一、最关键的思路:用概率分布的特征函数来推导概率分布。
已知一个概率分布特征函数是 , 那么这个概率分布的概率密度函数可以有特征函数推导出,即如下公式:
其中,特征函数 的定义式为
, 其中 i 代表的是复数里的 i,于是上式可以变为:
从这个公式最右的 这一项来看,是否让我们联想到了经常用于做信号分离的傅里叶分析?其实,也正是这个原因,才允许我们使用快速傅里叶变换。
进一步地说, 就是做一次快速傅里叶变换的过程,对应 python 代码中的 np.fft.fft(),而
代表的就是做一个快速傅里叶变换的逆变换,对应着 python 代码中的 np.fft.ifft()。所以,跑完一次 python 代码,就得到了 f(Z) 的向量,这就是 FFT 算法能在聚合风险精算模型中的应用的原因。
二、说完特征函数 很重要,那怎么才能求出
?
这个就要用到聚合风险精算模型中的一个重要公式,即:
这个公式在 FFT 算法中非常重要,所以一定要记住,用来计算总损失 Z 的特征函数 。它的含义是,总损失 Z 的特征函数
等于令 t=
时的损失次数变量 N 的概率母函数,其中
代笔每次损失金额 X 的特征函数。
所以,在上一篇文章的 python 代码中,我们用到了np.exp(lamb*(np.fft.fft(v)-1)),其实这一步使用的就是上面的公式,只是因为 N 服从泊松分布了 所以才有这条代码。
三、又一个示例
【问题】已知损失次数 N 服从 PrN=0,1,3,7,8,9,10 =0.3, 0.2, 0.1, 0.1, 0.1, 0.1, 0.1。每个损失的损失金额有 0.5 的概率等于1、有 0.5 的概率等于3. 要计算N个损失变量Xi(i=1,2,3,...,N)之和 Z=X1+X2+X3+......+XN 的概率分布。
【解】直接用 python 写如下的代码:
import numpy as np
m=32
v = np.zeros(m)
v[1]=0.5
v[3]=0.5
t=np.fft.fft(v)
ff=0.3*1+0.2*t+0.1*(t**3)+0.1*(t**7)+0.1*(t**8)+0.1*(t**9)+0.1*(t**10)
iff=np.fft.ifft(ff)
print(np.real(iff))运行后得到结果如下:
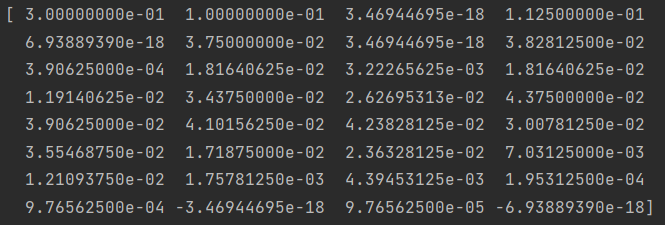
结果向量代表的意思是,总损失 Z =0 的概率是向量中的第一个数 0.3,总损失 Z =1 的概率是向量中的第二个数0.1,总损失 Z =2 的概率是第三个数0,总损失 Z =3 的概率是第四个数 0.1125,以此类推。
我们在算法中选取了 m=32 ,这是因为在这个示例里 Z 的最大值是 30 (最多发生10次损失,每次损失是3)。所以,我们取 m=32 就够了。
根据上面的结果,可以算出 EZ=7.8,它正是 EN*EX=3.9*2 的结果。