Ontology 存储结构与读写方式
本文主要关注 Palantir Foundry Ontology 数据对象的存储与读写机制 :对象数据物理上落在哪里、如何索引、如何查询、如何写回。官网没有明确披露 OSv2 的底层存储实现,本文的内容主要基于官方文档、架构图与开发手册做分析与推测。更多文章请访问:microwind.github.io
一、OSv2 并不是单一的数据库或索引
1.1 总体架构图
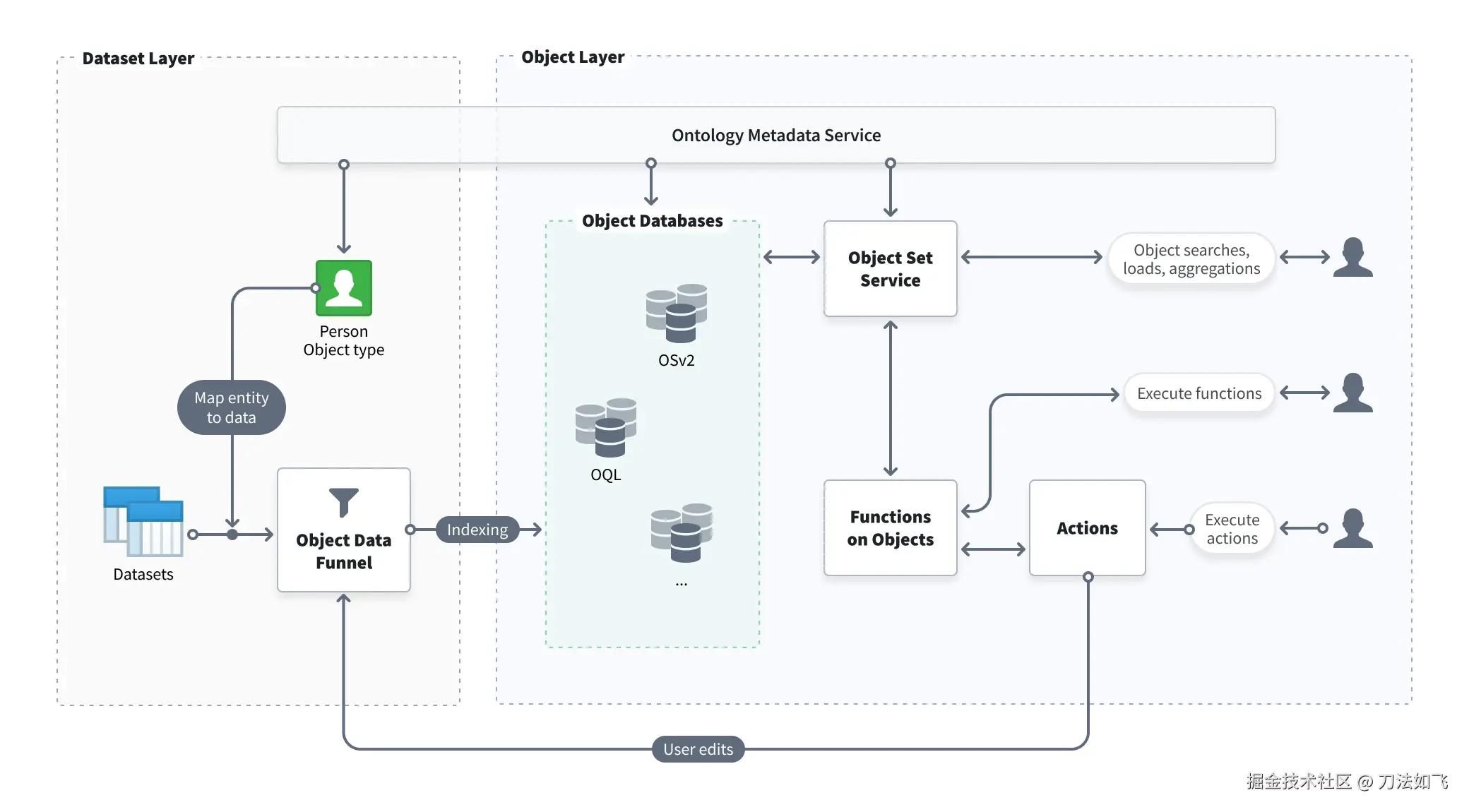
- Ontology 后端是一组微服务协作体系 。Ontology 对象最终由 Object Storage V2(OSv2) 对外提供对象查询、搜索、关联遍历与访问能力,但 OSv2 不是传统意义上的"单一数据库",而是围绕对象模型构建的存储、索引与查询运行体系(storage / index / query runtime)。官方原话:"a system backed by multiple specialized object databases in parallel"------目标不是统一所有存储形态,而是按不同的访问模式、性能、索引、扩展需求挑不同的底层。
- 官方未公开 OSv2 底层用了哪一种引擎 (Cassandra、Elasticsearch、Postgres、KV、Graph Store 等都没明说),也没披露对象数据在物理层面的真实组织结构。从公开文档和架构图能推断的是:
- "Ontology Object" 是逻辑视图,不一定等同于底层物理结构;
- OSv2 更像一层对象化的索引 + 查询运行时(object indexing / query layer);
- 底层事实数据可来自 Dataset、Streaming Datasource、RDBMS、NoSQL;
- Funnel 负责把这些数据编排、映射、索引为可查询的 Ontology Object;
- OSS(Object Set Service)则对外提供统一的对象查询接口。
- 读写职责分开 :写入由
Object Data Funnel统一编排进对象库,查询由Object Set Service (OSS)对外服务。这是 OSv2 相对 OSv1(Phonograph)最显眼的架构变化。
1.2 OSv2 涉及哪些核心服务?
下表列出 Ontology 读写过程中的核心服务;实际运行中涉及的服务可能更多。
| 服务 | 角色 | 写时路径 | 读时路径 |
|---|---|---|---|
| OMS(Ontology Metadata Service) | 元数据库:存放 ObjectType / LinkType / ActionType / Function / 权限契约的定义 | 校验所写数据是否符合类型契约 | 决定对象长什么样、有哪些字段、被哪种密级保护 |
| OSv2(Object Storage V2) | 对象存储与索引体系(多服务集合的对外名字),实际承载对象、链接与索引数据 | 接受 Funnel 的索引写入 | 被 OSS 调用以返回对象 |
| Funnel(Object Data Funnel) | 写入编排:从数据集 / 流 / 用户编辑读取变更,统一写入 OSv2 索引 | 主写路径,全部写操作必经 | 负责保证读路径上的索引最新 |
| OSS(Object Set Service) | 读对外网关:搜索、过滤、聚合、加载、searchAround |
不直接参与 | 主读路径,所有客户端读请求经它路由 |
| Actions service | 写入业务编排:参数校验、Submission Criteria、权限、副作用编排 | 写路径的"业务逻辑" | 不直接参与 |
| Functions | 无副作用计算:在 Action 校验内或独立调用 | 提供 Submission Criteria 校验 | 提供派生属性、聚合、Search-Around 函数 |
简化记忆:OMS 管"对象长什么样",Funnel + OSv2 管"对象在哪、写完多久能读到",OSS 管查询,Actions service 管写入和留痕。
1.3 OSv2 存储 / 索引架构推测
⚠ 本节为架构推测。素材是官方架构图、服务职责描述与系统行为模式;官方对接入流水线的事实描述则是 Changelog → Merge → Indexing → Hydration 四阶段。这一节回答"运行环境长什么样"。
1.3.1 OSv2 更像一个"对象语义索引运行时"
根据前面把 OSv2 当作一座**多层协作的"对象数据工厂"**来看,可以拆成四层职责:
| 层 | 干什么 | 对应工厂里的角色 |
|---|---|---|
| 存储层(Storage) | 持久保存对象本体 | 仓库本身 |
| 索引层(Index) | 让仓库对象可被快速检索 | 货架旁的索引卡片 |
| 查询层(Query Runtime) | 接外部请求并路由到对应索引 | 对外窗口 |
| 对象投影层(Object Projection) | 按调用方需要的形状返回数据 | 配货员 |
下面用一张推测的分层架构图把这四层与具体服务(Funnel / OMS / Action / Function)连起来。
1.3.2 推测的分层架构
读懂这张图------把它想象成一座"对象数据加工厂":
-
Data Sources Layer(数据源层)是原料入口:所有数据(批数据、实时流、权限裁剪视图、用户在 UI 上的编辑)都从这里进入 Ontology。
-
Funnel Layer(写入编排层)是入口闸门 :所有数据进系统前必须先过 Funnel,不能绕过它直接写存储 。它负责对象化映射、Schema 校验、索引更新、变更日志生成,类比于
CDC + ETL + Materializer的组合体。 -
Metadata Layer(元数据层)是产品说明书 :OMS 不存业务数据,只描述"对象长什么样"------有哪些 Object、Link、Action、Function,谁能访问哪些字段。类比于
Semantic Catalog + Data Dictionary。 -
OSv2 Core(对象存储与索引体系)是核心车间,三层货架------
Storage Tier(存储层)------仓库货架:
S1 KV / 事实宽表库:存对象真实内容,如"V123 是红色、属于张三",类似Cassandra / Bigtable的宽表 KV;S2 Routing / Partition Catalog:存物理分片、路由、节点位置等内部元信息,类似Postgres Catalog + etcd;S3 Append / 变更流 / 持久日志:Funnel 拥有的 Foundry Dataset,存对象变更流水账,用于故障恢复与索引重建,类似Iceberg Append Log。
Index Tier(索引层)------货架旁的索引卡片:
I1 倒排属性索引:按属性查,例如"所有红色车辆",类似Elasticsearch / Lucene;I2 Link Graph 关系图谱索引:按关系跳,例如"张三名下还有哪些车",类似JanusGraph adjacency index;I3 Object Set Index:做集合代数与聚合,例如"红色 ∩ 上海 ∩ VIP",底层很像Roaring Bitmap。
Runtime Layer(运行时层)------仓库对外窗口:
R1 Object Set Service (OSS):所有查询先到这里,负责权限过滤、查询规划与索引路由,类似GraphQL Gateway + Query Planner;R2 Search Around Engine:专门处理关系跳跃与searchAround,类似Gremlin Traversal;R3 Projection Engine:把多个对象、索引与关系拼成调用方需要的最终结果,类似Federation Resolver。
-
API / Action Layer(业务行为层)是提单台:
Actions Service:带规则的写入提单("我要改 V123 的颜色"),经校验后交给 Funnel,类似DDD Command Service;Functions:只读计算逻辑("风险评分""价格推导"),被 Action 校验或 OSS 投影时调用,类似SQL UDF。
一次Ontology写入的过程
用户改对象 → Actions Service 校验 → Object Data Funnel 立刻 把变更同时写到 对象事实存储(S1) 与三个索引(属性索引 I1 / 关系索引 I2 / 集合索引 I3 )------这就是 4.2 节"读后写一致"在物理上的来源 。随后 (图中虚线)Funnel 再把这次编辑追加到 持久日志(S3) 做异步备份;search node 宕机或索引重建时靠它回源。
一次Ontology读取的过程
客户端发查询 → 对象集运行时(OSS / R1)判断请求类型 → 智能路由:
- 纯属性过滤 → 走 属性索引 I1;
searchAround关系跳跃 → 走 R2 + 关系索引 I2;- 集合代数 / 聚合 → 走 集合索引 I3;
- 需要返回对象完整内容 → 投影引擎 R3 回拽 对象事实存储 S1 兜底拼装。
S2 ≠ M1 OMS(这里容易混淆):OMS 管的是业务语义------"这是一辆汽车,由这几个属性组成",给人和上层应用看;S2 Routing Catalog 管的是物理布局------"V123 这条数据现在分在 7 台机器的 21 个分片里",是 OSv2 内部自己用的。
1.3.3 推测的"专用对象库"维度
官方原文是"multiple data storage types in parallel"------但并未列出"哪些专用维度"。基于 3.2 节的三类查询和常见对象库设计模式,可能的专用化方向有:
| 专用维度 | 解决的查询类型 | 业界类似实现 |
|---|---|---|
| 主键点查 / 行式 KV | GET /objects/{type}/{id} |
Cassandra / HBase / DynamoDB |
| 倒排 / 属性过滤 | Base Query 的 filter |
Elasticsearch / OpenSearch / Lucene |
| 链路邻接 / 图遍历 | Search Around 沿 LinkType 跳跃 | JanusGraph / Neo4j / Neptune |
| 位图 / 集合代数 | Object Set 的交并差、Aggregation | Roaring Bitmap / Pinot |
| 地理空间 | geoPoint 字段的范围与最近邻 |
PostGIS / Elasticsearch geo |
| 时序 | 流入对象的时间属性范围扫描 | InfluxDB / TimescaleDB |
| 向量 / 语义检索 | Semantic Search(Palantir 列为扩展基元) | Milvus / Pinecone / pgvector |
注:这只是可能的专用化维度清单,并不代表 Foundry 内部一定是按这套实现。
1.3.4 各层节点的开源对照(用于自建参考)
自建一个类 Palantir OSv2 分层构架的对象库,可以参考下表。
| 节点 | 角色 | 首选开源对照 | 备选 | 推测准确性 | 依据 |
|---|---|---|---|---|---|
| S1 KV / 事实宽表库 | 对象主体内容 | Apache Cassandra + AtlasDB(Palantir 自家事务层) | ScyllaDB / FoundationDB / HBase | 高 | AtlasDB README 明确说在 Cassandra 上做 MVCC;多份招聘提到 Cassandra |
| S2 Routing / Partition Catalog | 分片 / 路由 / 副本拓扑 | etcd 或 Apache ZooKeeper | Consul / 自研 Postgres 元表 | 中 | 大规模分布式系统的标准选择 |
| S3 持久日志 / Funnel Dataset | 变更流水账 + 灾备底 | Parquet on S3 / ADLS + Iceberg-style 目录 | Delta Lake / Apache Hudi | 高(Parquet)/ 中(Iceberg) | Foundry Dataset 长期是 Parquet;表格式管理细节未公开 |
| Funnel 队列(Action offset) | 写入指令排序 | Apache Kafka | Apache Pulsar / Pravega / 自研 | 高 | Palantir 多次提到 Kafka,且 offset 语义直接对应 Kafka topic offset |
| I1 倒排属性索引 | 属性过滤 / 全文 / 模糊匹配 | Elasticsearch 或 OpenSearch | Apache Solr / Vespa / Lucene 自封装 | 高 | OSv1(Phonograph)官方文档承认使用 ES;OSv2 大概率沿用 |
| I2 Link Graph 关系图谱索引 | LinkType 邻接 / searchAround |
JanusGraph(落 Cassandra/HBase) | HugeGraph / Dgraph / 自研 Cassandra adjacency 表 | 中 | JanusGraph 在 Cassandra 之上是最自然的组合;具体实现未公开 |
| I3 Object Set Index | 集合代数 + Aggregation | RoaringBitmap(Java 库)+ 自研列存 | Apache Pinot / ClickHouse / Apache Druid | 中 | RoaringBitmap 是 Java 生态 bitmap 标准;与 Palantir Java stack 匹配 |
| M1 OMS | ObjectType / LinkType / Action / ACL 定义 | PostgreSQL + JSON Schema + Open Policy Agent (OPA) | Confluent Schema Registry / Apache Atlas | 中 | Postgres 是元数据存储的常见选择;ACL 部分 Palantir 自研 Multipass |
| F1 Object Data Funnel | 写入编排 / CDC / Materialization | Apache Spark Streaming + 自研编排 | Apache Flink / Kafka Streams | 高(Spark)/ 中(Flink) | Foundry 数据管道公开使用 Spark;批 / 流统一 |
| R1 OSS Query Router | 查询路由 + 权限过滤 + 规划 | 自研 Java 服务 (基于 Witchcraft + Conjure) | Apollo Federation / GraphQL Yoga | 高(自研框架确证) | Palantir 已开源 Witchcraft 与 Conjure,是其后端服务的标准底座 |
| R2 Search Around Engine | 关系扩散 / 图遍历 | Apache TinkerPop Gremlin(配 JanusGraph) | Cypher / GSQL / 自研 BFS | 中 | TinkerPop 是 JanusGraph 标配;具体引擎未公开 |
| R3 Projection Engine | 跨索引数据拼装 | DataLoader 模式 + Conjure RPC(自研拼接器) | Apollo Federation | 中 | 多索引并发取 + 主键合并,自研可能性大 |
| A1 Actions Service | 命令路径 / Submission Criteria | 自研 Java 服务(Witchcraft + Conjure) | --- | 高 | 同 R1 |
| A2 Functions | 无副作用计算 | TypeScript / Python 沙盒运行时 | GraalVM JS / V8 Isolates | 高 | 官方 Functions on Objects 文档明确支持 TS/Python |
Palantir 的开源"组件"
下面是 Palantir OSv2 拓扑相关的开源项目,自建Object Storage可以直接使用:
| 项目 | 功能 | 链接 |
|---|---|---|
| AtlasDB | S1 的事务性 KV 大宽表(MVCC、可序列化隔离),基于Cassandra/Postgres 之上 | github.com/palantir/atlasdb |
| Conjure | 强类型 RPC / REST 接口契约------R1 / R2 / R3 / A1 服务之间的接口定义 | github.com/palantir/conjure |
| Witchcraft (Java) | Java 微服务框架------TLS、健康检查、观测、配置;R1 / A1 等服务的运行时 | github.com/palantir/witchcraft-java-runtime |
| Tritium | Java 高性能指标库------观测面(与 1.3.2 没直接节点对应,但任何服务都用得到) | github.com/palantir/tritium |
| Dialogue | 高性能 HTTP/2 客户端,服务间调用 | github.com/palantir/dialogue |
使用上的注意:这些是"组件"不是"成品"。把 Cassandra + AtlasDB + Elasticsearch + JanusGraph + Kafka 拼出一个对象存储库的最小版本,工程量大致是数月起步;做到 Foundry 同等成熟度(权限、审计、Scenario、热升级、跨域复制)通常是数年。
二、数据如何写入到对象库
2.1 哪些数据可以成为对象的"数据源"
在 OSv2 中,一个 ObjectType 必须挂载一个或多个支撑数据源(backing datasource),才能被实例化为对象。官方支持的数据源类型:
- Foundry Dataset:批数据集,支持 APPEND / UPDATE / SNAPSHOT 三种事务类型。
- Restricted View:在数据集之上做行/列级裁剪后形成的视图,用于权限隔离。
- Streaming Datasource:Foundry 内的事件流。
约束条件:
- 不能含
MapType/StructType列:backing datasource 中复杂类型列不允许。 - 主键必须确定性(deterministic):官方强调 "Primary keys should be deterministic. If the primary key is non-deterministic and changes on build, edits can be lost and links may disappear."------若构建时主键发生变化,已有用户编辑可能丢失,已建链接也可能失效。
- 权限随源走:官方原文 "permissions of the objects of a type are determined by the location of their backing datasources"------对象的可见性由其支撑数据源所在位置的权限决定,并非在 ObjectType 上确定。
2.2 Funnel 数据集管道:四个阶段的流水线
以数据集作为来源时,入库通过 Funnel 批管道完成,整体分为四个阶段(每个阶段都会产出一个中间数据集):
- Changelog:Funnel 自动比对上次入库与当前的事务,会生成"只包含变更行"的中间数据集。官方原文:"Funnel automatically computes the data difference for all datasources when the datasources receive new data or transactions, then creates intermediate changelog datasets."
- Merge Changes:把变更与 Action 带来的用户编辑按 ObjectType 的主键合并;这一步决定了"管道侧改一次、Action 侧改一次"的两路写入最终落到同一个对象上。
- Indexing:将合并后的结果转换成对象库可检索的索引格式(这里不清楚是倒排索引还是向量索引),最终产出索引数据集。
- Hydration:把索引文件下载到对象库的 search node 内存 / 本地存储中(这里还不清楚具体实现,可能综合了缓存、ES、向量库等能力),使其可以被查询。
一条属性的"物理旅程"(举例:Vehicle.status)
以汽车厂 Vehicle 对象的 status 字段为例,把它从源头到查询面走一遍,能帮你把上面的四阶段和 1.3 的推测层级对上:
| 阶段 | 物理形态 | 在哪一层 |
|---|---|---|
| ① 源系统 MES 写入 | 表/topic 里的一行:(vin=V123, status='WELDING', ts=...) |
外部 |
| ② Foundry 接入 | Parquet 列:status: string 写到 backing dataset 的一个 transaction |
Foundry Data Lake(Iceberg / Parquet) |
| ③ Changelog | 仅含变化行:vin=V123, status='WELDING', _op='UPDATE' |
Funnel 中间 dataset |
| ④ Merge Changes | 与 Action 编辑按 vin 合并后的全字段行 |
Funnel 中间 dataset |
| ⑤ Indexing | 索引 doc:倒排(status 值 → vin 列表)、属性宽表行 | OSv2 索引文件 dataset |
| ⑥ Hydration | search node 内存 / 本地盘里的可查段 | OSv2 live index(对应 1.3.2 的 I1/I3) |
| ⑦ 持久化 flush | 与上次 flush 比对的增量,落入 Funnel-owned Foundry Dataset | 1.3.2 的 S3(耐久层) |
| ⑧ OSS 查询返回 | JSON 对象:{"vin":"V123","status":"WELDING",...} |
客户端 |
容易混淆的一点:Funnel 的"持久化数据集"(步骤 ⑦)和 backing dataset(步骤 ②)不是一回事------前者由 Funnel 拥有,装的是"合并后已生效的对象快照";后者由上游系统拥有,装的是"原始来料"。重建索引时是从前者 rehydrate 的,这也是 OSv2 耐久性的来源。
2.3 增量与全量、Live 与 Replacement
增量索引:OSv2 默认对所有管道做增量索引。一个常被引用的例子是:input 数据集有 100 条对象,本次 transaction 只改了 10 条,则 Funnel 不会重做全部 100 条,而是在 changelog 数据集里追加一个 APPEND transaction,只包含这 10 条改动。
触发全量重建分两种情况:
- 单次事务中 > 80% 的行发生变化(启发式判断);
- ObjectType / LinkType 的 schema 变更(如属性增删)。
两类管道并存:
- Live pipelines :在以下两种时机执行------
- 数据源接收到新 transaction;
- 即便数据源静止,每 6 小时检测一次用户编辑------若有则触发一次合并,把内存中的用户编辑落到持久化数据集。
- Replacement pipelines:仅当 schema 发生变化时被自动调度,在后台另起一条管道重建,不打断现有读取流量。
2.4 Funnel 数据流管道:低延迟入库
事件流源(Foundry Stream)走 Funnel 流管道:
- 延迟:官方表述 "on the order of seconds or minutes"。
- 顺序假设 :流被当作 changelog,最新事件覆盖旧值("most recent update wins")。前提:上游必须按主键分区、按事件时间戳排序,否则会落到 Ontology 里错乱的值。
- 一致性可选 :
exactly-once(牺牲一点延迟,无重复)或at-least-once(更低延迟,偶发重复)。 - 限制 :
- 不支持 Action 用户编辑(要写就要走批量的 ObjectType);
- 不支持多数据源对象类型(MDO);
- 单条记录上限 1 MB ,单个对象最多 250 个属性。
2.5 多数据源对象类型(MDO,Multi-datasource Object Type)
OSv2 特有:一个 ObjectType 可以同时由多个数据源拼合而成。
- 列向 MDO(column-wise) :不同数据源贡献不同的属性子集,按主键拼成同一对象。例:
Vehicle的产线状态来自 MES,订单字段来自 ERP,质检字段来自质量系统,三者按vin拼成完整的Vehicle对象。 - 行向 MDO(row-wise):官方说明 "Foundry currently does not support row-wise MDOs"------目前由 Restricted View 实现行级隔离,不是 MDO 直接职责。
- 上限 :每个 ObjectType 最多 70 个支撑数据源。
- 权限降级行为 :当请求方对某个支撑源无访问权限时,来自该源的属性显示为
null------而不是返回错误,也不会暴露存在性以外的信息。 - 流不可参与 MDO:MDO 的支撑源必须是 Foundry 数据集或受限视图。
三、数据如何查询(OSS 读取方式)
3.1 Object Type vs. Object Set
官方原文明确定义:
- Object type 是语义实体本身("the semantic representation of the entity itself")------类型层的定义。
- Object set 是符合该类型的实例集合("contains the objects themselves")。
OSS 的所有读 API 都基于 Object Set,而不是在"对象类型表"上查 SQL。
3.2 三类查询及其计算成本
| 查询类型 | 语义 | 最低 compute-seconds | 典型用途 |
|---|---|---|---|
| Base Query | 按属性过滤、加载、分页 | 2 | "拿到所有 status=IDLE 的 Vehicle" |
| Search Around | 在某个对象集的链路对端做二次过滤 | 5 | "拿到这些 Track 链路到的 IntelReport" |
| Aggregation | 在对象集的某属性上做 sum / avg 等聚合 |
5 | "按 plant 分组算 Vehicle 平均产时" |
| Action(写) | 写回路径,见第四节 | 18 + 1/对象 | 不属于"读",列在此对比 |
官方计费表述:"a fixed, minimum number of compute-seconds for query overhead. An additional scaling number of compute-seconds, which are measured by the amount of compute used to service the query." 当查询没有归属资源(如直接走平台 API)时,compute 归属到被查的 ObjectType;如果涉及多个 ObjectType,则平摊。
查询类型 ↔ 推测对应索引
把 3.2 的三类查询与 1.3.2/1.3.3 的索引层对照(推测):
| 查询类型 | 主用索引 | 走的运行时组件 |
|---|---|---|
| Base Query: PK 点查 | KV / 行式宽表(S1) | R1 OSS Query Router |
Base Query: 属性 filter / 全文搜索 |
倒排(I1) | R1 OSS |
| Base Query: 集合交并差 | 位图(I3) | R1 OSS |
Aggregation sum / avg / groupBy |
位图 + 列存(I3 + S1 兜底) | R1 + R3 Projection |
| Search Around 沿 LinkType 跳跃 | 关系图谱(I2) | R2 Search Around Engine |
| 地理 / 时序 / 向量字段查询 | 对应的专用索引(见 1.3.3) | R1 路由到对应专用库 |
这是把"查询类型"翻译成"该走哪个物理索引"的助记表。读者真正按此排查性能时,仍以 Foundry 查询计划与官方支持为准。
3.3 Search Around:用链路代替 JOIN
官方在 OSDK 中给出的最短示例(Employee 场景):
typescript
import { ObjectSet, Employee } from "@foundry/ontology-api";
// 1) 先按主键过滤员工
const employeeObjectSet: ObjectSet<Employee> =
Objects.search().employee().filter(exactMatch(employee_id));
// 2) 再沿 LinkType 跳到对端的对象集
const linkedObjs: ObjectSet<OtherObjectType> =
employeeObjectSet.searchAroundToOtherObjectType();要点:
searchAroundToOtherObjectType()是 OSDK 根据 LinkType 自动生成的方法,不需要写 JOIN 条件,链路语义本身已编码在 Ontology 里;- 过滤要前置 :官方明确建议先
filter缩小集合,再做 Search Around,因为 Search Around 与 Aggregation 都会随"集合大小"消耗 compute; - 链式调用:例如官方 Quiver 文档给出的例子------从
Tea Batch跳到Tea Vat,再跳到Tea Vat Sensors,三段一次写完。
3.4 链路遍历:SingleLink vs MultiLink
LinkType 支持 1-to-1 / 1-to-many / many-to-many。OSDK 把它们映射为两种字段类型:
- SingleLink (1 侧):用
.get()/.getAsync()取,返回值可能undefined; - MultiLink (many 侧):用
.all()/.allAsync()取数组。
typescript
// 单侧链
const manager = employee.manager.get();
// 多侧链
const reports = employee.reports.all();官方也专门提醒:直接在对象实例上做链路遍历"成本可能较高" ,因为这一步会把对端实例拉进内存;大集合场景应使用 ObjectSet 的 searchAroundTo*,让计算停留在集合层。
3.5 读路径的一致性
读路径上有两类截然不同的一致性语义,容易混淆:
(a) 列表分页扫描------最终一致 。List Objects API 的官方原话:
"This endpoint does not guarantee consistency. Changes to the data could result in missing or repeated objects in the response pages."
也就是说,分页过程中如果有人在写,可能漏读或重读。OSv1 单次最多返回 10000 个对象,OSv2 无上限。
(b) 单对象的"写完立刻读"------读后写一致(read-after-write) 。在 Action 走完 Funnel 队列、offset 应用到 live index 之后,同一查询里再访问该对象保证看到最新写入。官方原文:
"if an object read occurring as part of an ontology query happens after a user modification is sent, the object read is guaranteed to contain the user edits."
工程含义:
- 用 OSDK 写完一个
ApproveStrikeAction,紧接着读Platform.UAV-301的engagementState------拿到的就是 ENGAGING,不需要等任何 6 小时的 flush; - 但若你做的是分页扫"所有 status 改过的 Vehicle"------这种长扫描期间到达的新写入不在一致性保证范围内。
3.6 OQL:在哪里出现、不在哪里出现
社区常把 "OQL = Palantir 的 SQL" 混为一谈------其实不准确。基于目前的公开材料:
- Foundry 的默认查询接口是 OSDK 与平台 REST/GraphQL API ------例如
GET /api/v1/ontologies/{ontologyRid}/objects/{objectType}、POST .../actions/{actionType}/apply,以集合代数(Object Set)为抽象; - OQL(Object Query Language)主要出现在 AIP Agent Studio------是 LLM 自动生成可执行查询时的过滤 DSL;公开文档对其完整语法描述较少,社区帖与租户内文档可见。
更准确的表述:Palantir 通过 OSDK / 平台 API 以集合代数 方式查询;OQL 是 AIP 场景里 LLM 的过滤语法,不是给应用开发者用来替代 SQL 的通用语言。
四、数据写回路径(Action)
4.1 写路径总体时序
关键步骤逐条说明见 4.2--4.5。
4.2 Funnel 队列与 offset 追踪
这是 OSv2 写路径最核心的一个机制,官方原文如下:
"When an Action is triggered, the Actions service sends a modification instruction to the Funnel service. This instruction is stored in a Funnel-managed queue that has offset tracking to support simultaneous user edits. Object Storage V2 tracks these offsets for any object type and any many-to-many link type with join tables. The offsets are applied to the live indexed data in the object database."
工程含义:
- Action 不直接 UPDATE 对象库,而是把"待执行的修改指令"投递到 Funnel 队列;
- 队列通过 offset 顺序保证:多个同时到达的编辑不会乱序覆盖------每个对象类型与每个多对多 LinkType(含 join table)都有各自的 offset;
- 应用到 live index 是即时的------instruction 落 offset 之后,读路径立即能看到新值,3.5(b) 的读后写一致就是这么来的;
- 之后再异步 flush 到 Funnel 自己拥有的持久化数据集------这一步不再影响读一致性,主要是为了让数据"在重启或重建索引时不丢"。
4.3 持久化 flush 的两个触发器
官方对持久化数据集的重建给了两条触发规则:
- 来自数据源的新 transaction:每当 backing datasource 有新事务,就把累计的用户编辑一并合并落盘;
- 每 6 小时:即便数据源静止,只要 Funnel 队列里有未落盘的用户编辑,就触发一次合并。
这也解释了一个常被问到的细节:为什么"刚做完 Action、紧接着 OSS 查询能看到新值"------因为查询读的是 live index(offset 已应用),不是持久化数据集(可能还没刷)。
耐久性与故障恢复
持久化数据集是 OSv2 的"灾备底"。search node 宕机或索引需重建时,会从 Funnel 拥有的这份 Foundry Dataset 重新 rehydrate。
"6h flush"不是性能调优数字,而是耐久性边界------这条规则是为了防止大量内存中的用户编辑随节点崩溃而丢。两次 flush 之间崩溃,理论上仍可能损失 6h 内未刷新的编辑;平台是否还有 WAL 之类的二级保护,官方未公开。
4.4 Submission Criteria:声明式的校验闭环
ActionType 的校验在 OSv2 中被称为 Submission Criteria(官方原名,前称 Validations)。可校验的内容:
- 参数约束 :
range、arraySize、oneOf、objectPropertyValue、objectQueryResult等; - 用户上下文 :通过
Current User模板访问当前用户的 ID / 组 / Multipass 属性; - 失败消息 :每条条件可配
configuredFailureMessage,运行时在 Object Explorer / Workshop / Quiver 等界面显示------调用方看得到、读得懂,这一点和"silent fail"的传统 CRUD 服务区别很大。
需要注意几条边界:
- 不查 Ontology 已有数据:官方明确 "validations will not consider existing objects or other data in Foundry. For example, the uniqueness of a primary key or the existence of a user ID will not be checked."------若需要这类校验,要么放进 Function(Function-backed Submission Criteria 可读 Ontology),要么在 Action 内部规则中实现,要么接受 Funnel 提交后的冲突;
- 敏感信息会被后端裁剪:无权编辑 ActionType 的用户看不到 Submission Criteria 详情,避免泄露字段值组合。
预演接口 :客户端可在真正 apply 之前调用 POST /api/v1/ontologies/{ontologyRid}/actions/{actionType}/validate,得到 VALID / INVALID 与每条参数 / Submission Criteria 的评估结果,用于 UI 的"按钮可用性"判断,或 Agent 的"提案可行性"预检。这一步不会进入 Funnel 队列,也不会写审计。
4.5 副作用与对外回写
ActionType 还可声明非数据修改的副作用:
- Notifications:通知特定用户(如官方示例 "notify the old and new manager of the change");
- Webhooks:调外部系统(MES、ERP、C2 系统、消息平台);
- Schedule triggers:触发管道构建;
- Media / Attachments:上传文件挂到对象上。
这里的顺序很关键:先写审计,再触发外部回写,否则可能出现"外部系统改成功了,但 Ontology 这边没留下痕迹"。
4.6 写路径 compute 成本
| 操作 | Compute-seconds |
|---|---|
| Action 固定开销 | 18 |
| 每多写一个对象(首个之外) | +1 |
这个数字解释了一个常见现象:批量 writeback 并不便宜。给 1000 个 Vehicle 改 status,开销大致是 18 + 999 = 1017 compute-second,量级直接抬到单对象 Action 的约 1000 倍。
五、安全模型如何随读写路径生效
前面第三节已指出 OSS 会按权限裁剪结果,3.5(a) 也提到列表扫描不强一致;这里把安全约束串到读写路径中:
| 检查发生在 | 检查内容 | 不通过结果 |
|---|---|---|
| OMS(类型契约) | ObjectType / Property / Action 是否对当前主体可见 | 字段消失或 ObjectType 整体不可见 |
| OSS(读路径) | 数据集级别 ACL + 字段级 Marking + Purpose | 行被过滤掉 / 字段裁为 null |
| Actions service(写路径) | Action permissions(角色 / 组)+ Submission Criteria | 返回 INVALID + 失败消息 |
| Funnel(写到对象库) | backing datasource 的写权限 | Action 提交时即拒绝 |
特别提一句 MDO 的"无权字段返回 null"(2.5):这是平台层做的事。应用与 Agent 拿到的对象,已经是按权限裁过的版本,不需要每个应用各写一遍密级过滤。在多租户、多任务、多密级共存的场景里,这一点能省下大量重复工作。
MDO (multi-datasource-objects)读路径的时序图(一个 Vehicle 来自三个数据源)
以 Vehicle 为例:status 来自 MES、orderId 来自 ERP、defectCount 来自质量系统。维护组用户只对 MES 有权。
要点:
- 按源并发拉 :MDO 的读不是先拼后裁,而是裁了再拼------OSS 知道哪几个源用户有权,无权的源直接跳过或丢弃;
- null 不区分"该字段没值"与"你无权看":官方语义是字段级保密,调用方看不到"该字段在另一个源里存在"这件事;
- 延迟取决于最慢源:并发拉、但要等齐,跨源读对 P99 不太友好,所以高频热路径上的对象建议把属性集中在少数几个源里。
六、两个领域实例
下面模拟两个案例,基于官方机制 + 仓库现有 milont / 数据存储与使用方式对比 文档做合理推演,便于把上面六节内容串起来看。
6.1 军事监测:从雷达流到打击授权(模拟Gotham军事演练场景)
数据源与入库
| 数据源 | 类型 | 入库管道 | 对应 ObjectType |
|---|---|---|---|
| 多型雷达 / 光电载荷的 Track 流 | Foundry Stream | 流管道(秒级) | Track |
| 人工 / 自动情报报告 | Foundry Dataset(增量 APPEND) | 批管道(Live) | IntelReport |
| 任务计划 / ROE 表 | Foundry Dataset(SNAPSHOT) | 批管道(替换式) | Mission、ROE |
| 平台台账 + 武器挂载(来自维护系统 + 出动状态) | MDO:维护表(属性 a 组)+ 出动表(属性 b 组) | 批 MDO | Platform |
| 目标台账 + No-Strike List | Foundry Dataset + Restricted View | 批管道 | Target |
要点:
- Track 走流管道 :上游必须按
trackId分区,并按观察时间戳排序;选择exactly-once一致性可以避免重复观测被合并成"多个 Track"------这是流管道的硬约束(2.4)。 - Platform 走 MDO :维护系统贡献
tail、maintenanceState、fuelPct,出动系统贡献engagementState、weaponLoadout------OSv2 按platformId拼合。维护组人员若不能访问出动数据源,他们看Platform时engagementState字段为null(2.5 的"无权字段降级")。
一次 OSS 读:找"质量可用、链接到 IntelReport 的高威胁 Track"
typescript
// 1) 在 Track 集合上先过滤------少量字段过滤优先
const candidateTracks = Objects.search()
.track()
.filter(t => t.confidence.gte(0.85))
.filter(t => t.observedAt.gte(now.minusMinutes(5)));
// 2) Search Around 到融合的 IntelReport(不需要 JOIN 写键)
const fusedReports = candidateTracks.searchAroundToIntelReport();
// 3) 再 Search Around 到 Target,过滤威胁等级
const threateningTargets = fusedReports
.searchAroundToTarget()
.filter(t => t.threatLevel.in(["HVT", "HPT"]));成本估算(按官方表 3.2):base + 两次 search around ≈ 2 + 5 + 5 = 12 compute-seconds 下限。
一次 Action 写:ApproveStrike
按照 military-exercise/ 中 ApproveStrikeAction 的契约:
- 校验阶段 (4.4):Submission Criteria 跑 7 条规则(PID、ROE、CDE、Airspace、WeaponLoaded、FriendlyDeconflict、NoStrikeList),其中
positiveIdentification与roeCompliance是 Function-backed------它们能读Track当前状态与ROE表; - 权限阶段 :Authority Checker 按 HVT / CDE bin 决定升级链------若需要 JFC 而调用方仅是 STRIKE_CELL_CHIEF,Submission Criteria 直接返回
INVALID+ 失败消息; - 写入阶段 (4.2):Effect 提交到 Funnel 队列------
Platform.engagementState=ENGAGING、createLink(ENGAGING, Platform→Target)、Platform.weaponLoadout减一。Offset 在Platform与ENGAGINGLinkType 上分别推进; - 审计 + 副作用(4.5):审计先落盘,再触发 Webhook 通知 C2 指控系统、值班长 Notification、可选挂图像证据(Media)。
紧接着读取 Platform.UAV-301 的客户端,会看到 engagementState=ENGAGING------这就是读后写一致(3.5(b))。
6.2 工业制造:物料短缺触发改派(模拟Foundry工业应用场景)
数据源与入库
| 数据源 | 类型 | 入库管道 | 对应 ObjectType |
|---|---|---|---|
| MES:产线状态(每分钟刷一次) | Foundry Stream | 流管道 | Line.status、Line.currentVehicle |
| ERP:销售订单、BOM、客户优先级 | Foundry Dataset(增量 UPDATE) | 批管道(Live) | Order、Customer、Material |
| WMS:物料库存 + 在途 | Foundry Dataset + Restricted View | 批管道 | MaterialStock |
| 质量系统:质检结果 | Foundry Dataset(SNAPSHOT) | 批管道(替换) | QualityEvent |
| Vehicle 主档 | MDO:MES(状态)+ ERP(订单关联)+ 质量(PPM) | 批 MDO | Vehicle |
要点:
- MDO 把 Vehicle 拼合起来 :MES 提供
status、currentLineId、startedAt;ERP 提供orderId、destination、customerTier;质量系统提供defectCount------三者按vin拼成一条Vehicle。最多 70 个支撑源(2.5),实际使用中 10~20 个较常见。 - 状态属性 250 个上限 :流管道侧的
Line对象若属性太多会越限,应把不常变的描述类字段移到批侧,或拆成独立 ObjectType(2.4)。
一次 OSS 读:找"受 SPM-XX 短缺影响的高优订单"
typescript
// 1) 找短缺物料
const shortMaterials = Objects.search()
.material()
.filter(m => m.stockLevel.lt(m.safetyStock));
// 2) Search Around 到使用该物料的 BOM
const affectedBoms = shortMaterials.searchAroundToBom();
// 3) 再 Search Around 到关联订单,按客户优先级排序
const urgentOrders = affectedBoms
.searchAroundToOrder()
.filter(o => o.customerTier.in(["A", "STRATEGIC"]))
.orderByDescending(o => o.dueDate);一次 Action 写:ReassignProduction
场景:系统检测到 SPM-307 物料短缺,A 类客户订单受影响,调度员从 Workshop 触发改派------把订单 ORD-1234 从 Line-A 改派到 Line-B。
- 预演 (4.4 末段):Workshop 内
Validate接口先跑------参数约束(orderId必填,targetLineId必须当前 IDLE)、Submission Criteria(目标线物料齐套、调度员有该工厂的LineSchedulingRole)、权限(操作员的Purpose必须为production-scheduling)。不通过则按钮置灰,给出可读失败消息; - Apply :提交到 Funnel 队列------
Order.assignedLineId改写、新增SCHEDULED_ON链路、原链路endedAt; - 副作用 :
- Webhook 推 MES → 实际产线排程更新;
- Notification 给班长 + 物料员;
- Schedule trigger → 触发 BOM 拉式计算管道;
- 审计 :记录
who / when / from-line → to-line / 影响订单数 / 失败规则(如有)。
随后,调度员在同一 Workshop 看板上立刻看到 Order.assignedLineId 改为 LINE-B------同样是读后写一致(3.5(b))。
七、与传统建模范式区别
| 维度 | 关系库 + 应用代码 | 图数据库(如 Neo4j) | Palantir Ontology(OSv2) |
|---|---|---|---|
| 数据放在哪 | 行 / 列 + 索引 | 顶点 / 边 + 属性 | Backing dataset / stream → Funnel → 专用对象库 |
| 是否单一存储 | 是 | 是 | 否,OSv2 是"多种专用对象库并行"的体系 |
| 关系怎么表达 | 外键 + JOIN | 边类型 + 遍历 | LinkType + 集合代数(Search Around) |
| 写入入口 | INSERT / UPDATE | Cypher / Gremlin Write | 必经 Action → Funnel 队列(offset 追踪) |
| 读后写语义 | 同一事务内可见,其他依赖隔离级别 | 取决于实现 | 同一查询内保证可见(live index);列表分页扫描不保证 |
| 校验放哪 | 应用层 / 数据库约束 | 应用层 | ActionType + Submission Criteria(声明式,全租户统一) |
| 权限放哪 | 应用层 / RBAC | 应用层 | 进入 OMS / OSS / Actions 三处的统一通道 |
| 审计放哪 | 应用层或外部 | 应用层或外部 | Action 内同事务必落,先于 Webhook |
| AI / Agent 接入 | 接 SQL 查表 | 接图查询 | OSDK + OQL(AIP 内)+ Function,全链经 Ontology 语义与权限 |
八、易被混淆的几个名词
| 名词 | 不是 | 是 |
|---|---|---|
| Ontology | 图数据库 | 由 OMS + OSv2 + OSS + Funnel + Actions 等微服务协作的语义层 |
| OSv2 | 某一种数据库 | "可插多种专用对象库"的对象数据存储 + 索引体系 |
| Funnel | ETL 工具 | 写入统一编排服务,所有写经它入对象库 |
| OSS | SQL 引擎 | 对象集合的读服务,按 ObjectSet 代数对外暴露 |
| Action | 存储过程 | 一等的变更契约,参数 / 校验 / 权限 / 副作用 / 审计都声明式表达 |
| OQL | Palantir 的 SQL 替代品 | AIP / Agent Studio 场景中 LLM 生成可执行查询所用的过滤 DSL;公开文档对其完整语法描述较少 |
| Scenario | 数据库事务分支 | 在 Ontology 之上做 copy-on-write 的"假如..."沙盒(见 技术原理介绍.md §3.3) |
| Object Storage V1(Phonograph) | 仍在维护 | 2026-06-30 之后不可用,需迁到 OSv2 |
九、参考资料
- Palantir 官方:The Ontology system(架构概览)
- Palantir 官方:Object backend overview(OSv2 / Funnel / OSS 总览与定义)
- Palantir 官方:Object Storage V1 (Phonograph) Planned deprecation(OSv1 现状与弃用时间)
- Palantir 官方:OSv1 to OSv2 migration(迁移注意点)
- Palantir 官方:Breaking changes between OSv1 and OSv2(架构差异)
- Palantir 官方:Funnel batch pipelines(批管道四阶段、增量索引)
- Palantir 官方:Funnel streaming pipelines(流管道约束、exactly-once / at-least-once)
- Palantir 官方:How user edits are applied(Funnel 队列、offset、读后写一致)
- Palantir 官方:Multi-datasource object types (MDOs)(列向 MDO、70 个上限、权限降级 null)
- Palantir 官方:Create an object type(支撑数据源、主键、权限)
- Palantir 官方:Action types overview(参数、副作用、Webhook)
- Palantir 官方:Submission criteria(前称 Validations,配置语义与失败消息)
- Palantir 官方:Permission checks for Actions(写权限的来源)
- Palantir 官方:Ontology query compute usage(Base / Search Around / Aggregation / Action 的 compute 成本)
- Palantir 官方:Functions on objects: Objects and links(OSDK SingleLink / MultiLink / Search Around 代码示例)
- Palantir 官方:List Objects API(列表扫描不强一致、V1/V2 上限差异)
- Palantir 官方:Validate Action API(apply 之前的预演接口)
本文档若与官方文档冲突,以官方文档为准。
更多文章,请访问AI编程核心资源库:microwind.github.io