


前言
大家好,这里是程序员阿亮!今天来给大家讲解一下MCP!
想象一下,如果在计算机诞生的早期,你买的每一个鼠标、键盘、打印机,都需要你专门为它们定制一个专属的接口插槽,那将会是怎样的灾难?今天的 AI 应用开发,正处于这样一个"接口灾难"的蛮荒时代。为了让大模型访问本地文件、查询数据库、调用 GitHub API,开发者们正在重复编写无数的"胶水代码"。
直到 Anthropic 牵头推出了 Model Context Protocol (MCP)。这不仅仅是一个协议,它是 AI 应用迈向标准化的"破局者"。本文将带你扒开 MCP 的外衣,深度洞悉它的底层架构与核心价值。
一、 楔子:"缸中之脑"与 N×M 灾难
在探讨 MCP 之前,我们必须先认清当前大语言模型(LLM)的处境。
无论 GPT-4o 还是 Claude 3.5 Sonnet 有多聪明,只要它没有外部数据输入,它就是一个**"缸中之脑"**------它的世界观停留在训练数据的截止日期,它不知道你昨晚刚修改的代码,也看不到你公司内网的数据库。
为了打破这个"缸",开发者们发明了各种外围框架(LangChain, LlamaIndex)和插件系统(OpenAI Plugins, Cursor Features)。但这引发了一个更加致命的工程问题,我们称之为 N × M 灾难。
假设市场上有 N 种 AI 客户端(Claude Desktop, ChatGPT, Cursor, Zed, 你的自研 Agent),同时有 M 种外部数据源(GitHub, Notion, 本地 SQLite, 公司内部的 Jira)。
在过去,为了让每一个 AI 都能用上这些工具,整个行业需要编写 N×MN×M 种适配器!
-
你想让 LangChain 连通 Notion?去找 LangChain-Notion-Tool。
-
你想让 Cursor 连通你的本地数据库?抱歉,目前不支持,除非 Cursor 官方给你写个插件。
生态被严重割裂,开发者在不断重复造轮子。而 MCP,就是为了终结这一切而生的。

二、 什么是 MCP?------ AI 世界的 HTTP 协议
Model Context Protocol (MCP),即"模型上下文协议",是一个开源的、标准的双向通信协议。
如果说 HTTP 协议 标准化了 Web 浏览器与 Web 服务器之间的数据交换;
那么 MCP 协议 就是用来标准化 AI 应用程序 与 外部数据/工具 之间的上下文交换。
核心架构:优雅的 Client-Server 解耦
MCP 采用了经典的客户端-服务端(Client-Server)架构,并在其上叠加了 JSON-RPC 2.0 作为通信载体。我们先理清这三个核心实体的角色:
-
MCP Host(宿主程序) :
这是直接面向用户或大模型的程序。比如你正在使用的 IDE (Cursor)、桌面客户端 (Claude Desktop),或者你自己用 Python 写的自动化 Agent。Host 负责发起意图,并展示结果。
-
MCP Client(协议客户端) :
运行在 Host 内部的底层组件。它不管大模型怎么想,它只负责按照 MCP 标准格式,将 Host 的需求打包成协议消息,向外部发送。
-
MCP Server(协议服务端) :
这是一个轻量级的独立进程。它是真正的"数据守门员"和"动作执行者"。比如一个 SQLite MCP Server,它内部包含了怎么连数据库、怎么执行 SQL 的所有逻辑,然后向外暴露统一的 MCP 接口。
类比理解:就像你的电脑(Host)通过 USB 控制器(Client)连接到一个带有 USB-C 接口的 U 盘(Server)。

三、 降维打击:有 MCP 与没有 MCP 的天壤之别
理解了概念,我们来看看 MCP 到底在工程上带来了多大的震撼。
场景:你想让 AI 帮你排查本地服务器的 Nginx 日志报错。
|-----------|------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------|
| 维度 | 没有 MCP 的时代(传统模式) | 拥抱 MCP 的时代(标准化模式) |
| 开发成本 | 你必须把庞大的日志文件手动复制粘贴给 AI;或者写一段 Python 脚本,用 API 把日志切片发给大模型。换个 AI 平台就得重写一次。 | 你只需运行一个标准的 File System MCP Server。任何支持 MCP 的 AI(Cursor/Claude)都能零配置 直接调用它读取日志。Write once, use everywhere. |
| 上下文压力 | 粗暴地把几万行日志塞进 Prompt,导致 Token 爆表,AI 出现"幻觉"或直接拒绝响应。 | 按需读取。MCP 允许 AI 先请求"列出日志目录",再请求"使用工具搜索 ERROR 关键字",精确获取最小必要上下文。 |
| 安全与权限 | 极其危险。为了让大模型读文件,经常直接赋予 AI 对整个系统的极高权限。 | 细粒度沙箱。MCP Server 在本地运行并受到严格控制。只有 Server 暴露的特定文件夹或特定 SQL 操作,AI 才能访问。大模型连数据库密码都摸不到。 |

四、 深度解剖:MCP 的三大核心原语 (Primitives)
MCP 并不是一个简单的 API 网关,它对 AI 需要的"上下文"进行了极其精准的哲学级抽象。它定义了世界上的外部知识与能力无外乎三种形态:Resources(资源), Prompts(提示词), Tools(工具)。
1. Resources(资源):AI 的"只读知识库"
资源向大模型提供了被动读取的数据。你可以把它理解为 AI 的"文件系统"。
-
形态:所有的资源都通过唯一的 URI 来标识。比如 file:///var/logs/nginx.log 或者 postgres://db/schema/users。
-
特性:资源不仅可以是文本,还可以是二进制数据(如图片,供多模态模型分析)。
-
杀手级功能 - 订阅 (Subscription):MCP 允许 Client 订阅某个资源。如果本地日志文件更新了,Server 会主动向 AI 推送通知 (Notification),AI 就可以实时感知外部世界的变化。
2. Prompts(提示词):服务端的"领域专家手册"
这是 MCP 中最容易被低估,却极其精妙的设计。
过去,我们将所有的 Prompt 工程都写在 AI 客户端里。但在 MCP 中,Prompt 可以由 Server 提供。
-
为什么这么设计? 假设你写了一个针对公司内部私有框架的 MCP Server。最懂这个框架的,是写 Server 的人,而不是通用的 AI。
-
机制 :Server 暴露一个带有参数的 Prompt 模板(例如 explain_code_architecture)。当用户让 AI 解释代码时,AI 向 Server 请求这个 Prompt,Server 会组装好包含该框架最佳实践的"神级 Prompt"返回给 AI。这实现了 Prompt 与大模型的完全解耦。
3. Tools(工具):AI 的"行动手臂"
这是让大模型具备改变世界能力(副作用/Side-effects)的途径。
-
形态 :Server 向 AI 声明自己有哪些工具,并提供严格的 JSON Schema 来定义参数。
-
安全性边界 :注意,MCP 协议强制规定,Tool 的执行必须遵循"Human-in-the-loop"(人类在环)的原则或由 Host 进行严格管控。大模型只是"建议"调用某个工具(比如 git_commit 或 drop_table),真正的执行权完全掌握在本地的 MCP Server 手中。如果参数不合法,Server 会直接拒绝并返回错误信息,让 AI 修正。
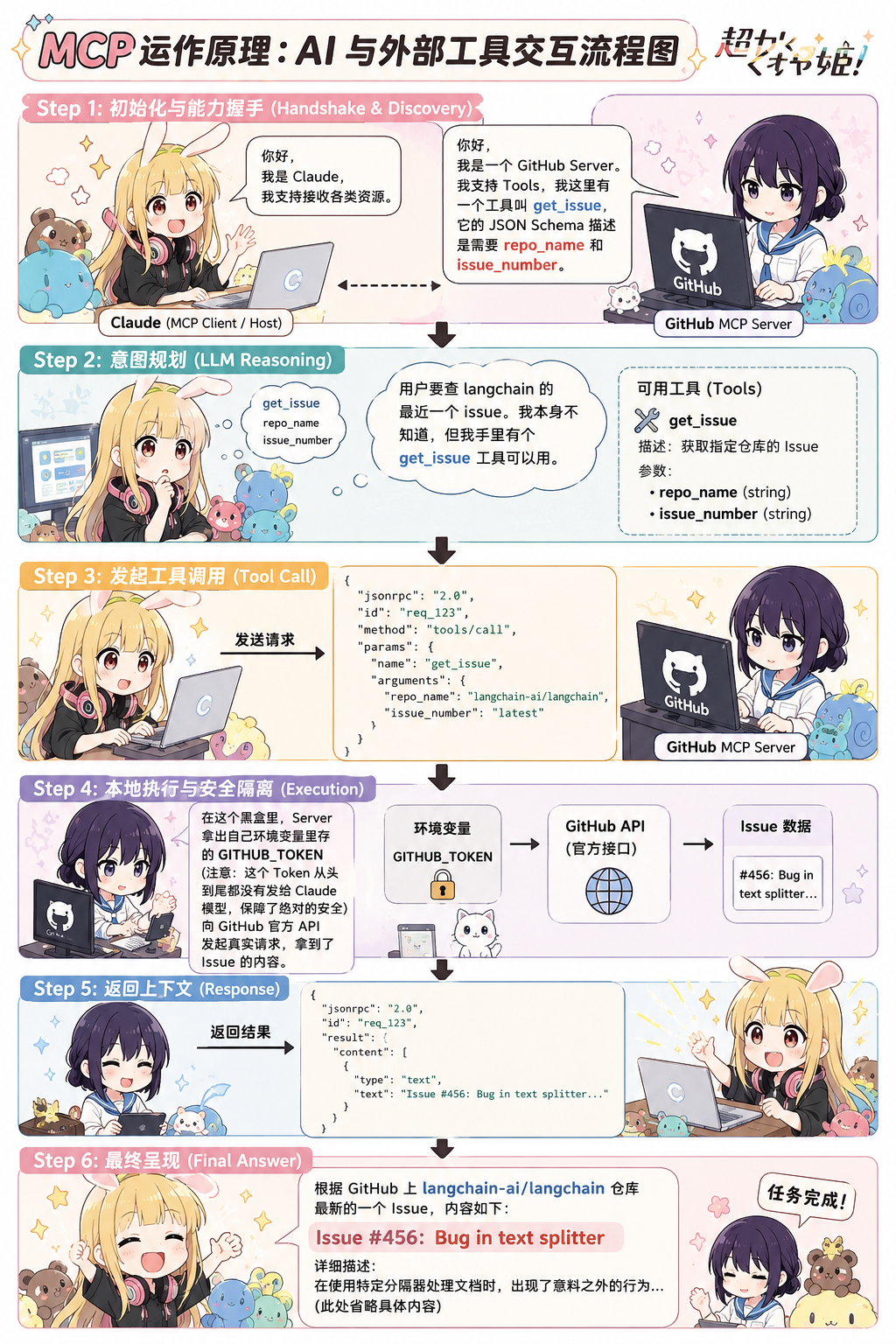
为了让你彻底弄懂 MCP 的运作原理,我们来"慢动作回放"一次 AI 与外部工具的交互过程。
五、 原理实战:一次典型 MCP 交互的底层抓包
场景 :你在 Claude Desktop(MCP Host)中输入:"帮我查一下 GitHub 上 langchain 仓库最近的一个 Issue 内容是什么。"
背后配置了一个 GitHub MCP Server。
Step 1: 初始化与能力握手 (Handshake & Discovery)
当 Claude 启动并连接到 Server 时,双方会交换一个协议报文:
-
Client: "你好,我是 Claude,我支持接收各类资源。"
-
Server : "你好,我是一个 GitHub Server。我支持 Tools,我这里有一个工具叫 get_issue,它的 JSON Schema 描述是需要 repo_name 和 issue_number。"
Step 2: 意图规划 (LLM Reasoning)
Claude 的大模型收到用户的自然语言请求。结合刚才拿到的 Server 工具列表,模型的大脑开始运转:
- "用户要查 langchain 的最近一个 issue。我本身不知道,但我手里有个 get_issue 工具可以用。"
Step 3: 发起工具调用 (Tool Call)
Claude 的 MCP Client 构建一个底层的 JSON-RPC 请求发送给 MCP Server:
{
"jsonrpc": "2.0",
"id": "req_123",
"method": "tools/call",
"params": {
"name": "get_issue",
"arguments": {
"repo_name": "langchain-ai/langchain",
"issue_number": "latest"
}
}
}Step 4: 本地执行与安全隔离 (Execution)
GitHub MCP Server 收到请求。在这个黑盒里,Server 拿出自己环境变量里存的 GITHUB_TOKEN(注意:这个 Token 从头到尾都没有发给 Claude 模型,保障了绝对的安全),向 GitHub 官方 API 发起真实请求,拿到了 Issue 的内容。
Step 5: 返回上下文 (Response)
Server 将拿到的数据格式化,通过 MCP 协议返回给 Claude:
{
"jsonrpc": "2.0",
"id": "req_123",
"result": {
"content": [
{
"type": "text",
"text": "Issue #456: Bug in text splitter..."
}
]
}
}Step 6: 最终呈现
Claude 模型拿到了这段真实的外部上下文,结合自身的语言生成能力,最终向用户输出了一段逻辑严密、排版精美的回答
辉夜姬万岁!!
总结
看完上述的拆解,你会发现 MCP 协议的伟大之处不在于它运用了多么高深的黑科技,而在于它克制而优雅的抽象设计。
它在不可控的大语言模型和复杂的真实物理世界之间,划定了一条清晰的标准边界。对于开发者而言,掌握 MCP,就意味着你拥有了为所有顶级 AI 注入灵魂(知识与能力)的钥匙。
下一篇预告:
在理解了 MCP 的宏观架构和核心要素后,我们将进入深水区。在下一篇博客中,我将为你详细剖析 MCP 的两种底层传输方式(stdio 与 HTTP/SSE) ,并且手把手教你如何在自定义的 Agent(如基于 LangChain、SpringAI)中深度集成 MCP Client,最后带你一览当前极速爆发的 MCP 社区生态。敬请期待!
