目录
[逐段解释:代码行 → 对应知识点](#逐段解释:代码行 → 对应知识点)
引言
学完
fork、pipe、waitpid这些进程基础概念后,你是不是也有一种"知识点都懂,但就是不知道怎么串起来"的感觉?🤔写一个迷你进程池,正是把这些零散知识拧成一股绳的最佳实践。通过亲手实现,你将:
- 真正理解父子进程如何通过管道协同工作
- 掌握进程创建、通信、回收的完整生命周期
- 踩一遍初学者最容易掉进去的坑(僵尸进程、描述符泄漏......)
- 获得一个可以反复把玩的"进程玩具",为后续学习线程池、IO多路复用打下坚实基础
核心设计思路
我们的进程池模型非常朴素,只有三个角色:
- 主进程(Master):负责创建子进程、生成任务、分发任务码
- 工作进程(Worker):预先创建好的子进程,阻塞等待任务,执行完后继续待命
- 管道(Pipe):每对父子之间有一条独立的匿名管道,Master 写,Worker 读
任务分发采用最简单的轮询策略------Master 按顺序把任务码依次发给各个 Worker,实现基础的负载均衡。当所有任务派发完毕,Master 关闭所有管道的写端,Worker 读到 EOF 后自动退出,最后由 Master 统一回收。
完整代码展示
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>
#include <time.h>
#define WORKER_NUM 3 // 工作进程数量
#define TASK_COUNT 10 // 模拟生成的任务数量
// 任务函数:每个任务对应一个编号
void do_task(int task_code) {
printf("[Worker %d] 执行任务 #%d\n", getpid(), task_code);
// 模拟任务耗时
usleep((rand() % 500 + 100) * 1000);
}
int main() {
int pipes[WORKER_NUM][2]; // 每个子进程对应一个管道
pid_t workers[WORKER_NUM]; // 记录子进程 PID
int i;
srand(time(NULL));
// 1. 创建子进程和管道
for (i = 0; i < WORKER_NUM; i++) {
if (pipe(pipes[i]) == -1) {
perror("pipe");
exit(1);
}
pid_t pid = fork();
if (pid == -1) {
perror("fork");
exit(1);
}
if (pid == 0) {
// 子进程:关闭写端,只保留读端
close(pipes[i][1]);
int task_code;
// 阻塞读取任务码,直到父进程关闭写端(read返回0)
while (read(pipes[i][0], &task_code, sizeof(task_code)) > 0) {
do_task(task_code);
}
close(pipes[i][0]);
printf("[Worker %d] 任务结束,退出\n", getpid());
exit(0);
} else {
// 父进程:关闭读端,只保留写端
close(pipes[i][0]);
workers[i] = pid;
}
}
// 2. 父进程:轮询分发任务
printf("[Master] 开始分发 %d 个任务...\n", TASK_COUNT);
for (i = 0; i < TASK_COUNT; i++) {
int worker_idx = i % WORKER_NUM; // 轮询选择子进程
int task_code = rand() % 5; // 随机生成 0~4 的任务码
write(pipes[worker_idx][1], &task_code, sizeof(task_code));
printf("[Master] 任务 #%d 分发给 Worker %d (PID=%d)\n",
i, worker_idx, workers[worker_idx]);
}
// 3. 关闭所有写端,通知子进程退出
for (i = 0; i < WORKER_NUM; i++) {
close(pipes[i][1]);
}
// 4. 回收所有子进程
for (i = 0; i < WORKER_NUM; i++) {
int status;
pid_t ret = waitpid(workers[i], &status, 0);
if (ret == workers[i]) {
printf("[Master] 回收 Worker %d (PID=%d),退出状态: %d\n",
i, workers[i], WEXITSTATUS(status));
}
}
printf("[Master] 所有子进程已回收,进程池关闭\n");
return 0;
}逐段解释:代码行 → 对应知识点
| 代码片段 | 对应知识点 | 说明 |
|---|---|---|
pipe(pipes[i]) |
匿名管道创建 | 管道是半双工的,返回两个 fd:pipes[i][0] 读端,pipes[i][1] 写端 |
fork() 后判断 pid == 0 |
进程复制 | 子进程获得父进程的完整副本,包括打开的文件描述符 |
子进程 close(pipes[i][1]) |
关闭不需要的端 | 每个进程只保留自己需要的端,避免干扰 |
父进程 close(pipes[i][0]) |
同上 | 父进程只写不读,关闭读端 |
read(..., &task_code, sizeof(task_code)) |
阻塞读 | 管道无数据时,read 会阻塞,直到有数据写入或写端关闭 |
write(..., &task_code, sizeof(task_code)) |
管道写入 | 写入的数据是字节流,子进程按固定大小读取避免粘包 |
close(pipes[i][1]) 循环 |
写端关闭触发 EOF | 所有写端关闭后,子进程的 read 返回 0,从而退出循环 |
waitpid(workers[i], &status, 0) |
进程回收 | 阻塞等待指定子进程结束,避免产生僵尸进程 |
WEXITSTATUS(status) |
退出状态解析 | 获取子进程 exit 时传递的退出码 |
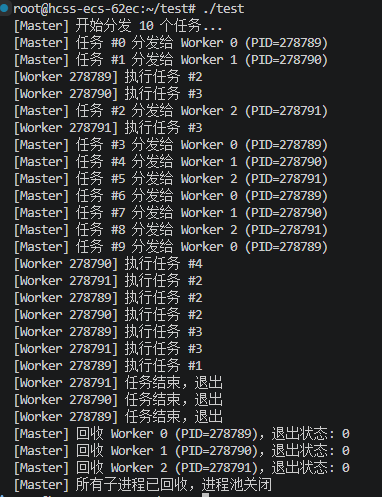
运行效果示例
常见坑点提醒
僵尸进程 :如果父进程没有调用
waitpid回收子进程,子进程结束后会变成僵尸进程,占用系统资源。一定要在适当位置统一回收。管道写端未关闭导致阻塞 :如果父进程忘记关闭某个管道的写端,子进程的
read永远不会返回 0,会一直阻塞等待。同理,如果子进程没有关闭读端,父进程写入的数据可能无法被正确读取。描述符泄漏 :
fork后子进程继承了父进程的所有 fd。如果不及时关闭不需要的端,不仅浪费资源,还可能导致管道无法正常关闭。每个进程只保留自己需要的 fd,其余一律关闭。任务码粘包 :如果写入的数据大小不固定,子进程可能一次读到多个任务码或只读到半个。解决方案是固定每次读写的大小(如
sizeof(int)),或者使用自定义协议头。
进阶扩展思路
支持 exec 执行外部命令 :子进程收到任务码后,可以
fork一个孙子进程来exec执行外部程序,自己继续等待下一个任务,实现更灵活的任务处理。双向通信:为每个子进程再创建一条反向管道(子写父读),让子进程可以汇报执行结果或请求更多数据。
信号量通知退出:不用关闭写端的方式,而是通过发送一个特殊任务码(如 -1)来通知子进程退出,配合信号量或共享内存实现更优雅的退出机制。
动态调整池大小:根据任务队列长度动态增加或减少工作进程数量,实现自适应负载均衡。
结尾总结
通过手搓这个迷你进程池,你实际上已经串联起了 Linux 进程编程中最核心的几个概念:
- 进程创建 :
fork的写时拷贝机制- 进程通信:匿名管道的单向字节流特性
- 进程同步:管道的阻塞读/写自带同步效果
- 进程回收 :
waitpid避免僵尸进程- 文件描述符管理:关闭不需要的 fd 防止泄漏
下一步,你可以尝试用同样的思路实现一个线程池 (使用 POSIX 线程或 C++11 的
std::thread),对比进程和线程在创建开销、通信方式上的差异。