摘要
本周学习了rag向量数据库相关知识以及余弦相似度,并且在本地部署了大模型并尝试调用一般大模型与聊天大模型
abstract
This week, I learned about RAG vector database concepts and cosine similarity. I also deployed a large model locally and tried calling both general large models and conversational large models.
向量数据库与向量
向量数据库是专门为高效存储、索引和检索高维向量数据而设计的数据库系统。这里的"向量",可以理解为一串有序的数字列表(例如0.2, 0.5, -0.1, 0.8),它能将文本、图像、音频等非结构化数据转化为数学上的空间点。通过某种嵌入模型(如Word2Vec、BERT等),语义相近的内容会被映射到向量空间中彼此靠近的位置。向量数据库的核心价值就在于它能快速执行"近似最近邻"搜索,从海量向量中找出与目标向量最相似的那些对象,常被用于推荐系统、语义搜索、AI记忆等场景。

余弦相似度
在向量空间中,判断两个向量的相似程度常用余弦相似度。它的计算方法是:先求出两个向量的点积,再分别除以它们各自的长度(模长)的乘积,结果是一个介于-1到1之间的数值:越接近1,表示两个向量的方向几乎完全一致,即内容高度相似;接近0则意味着几乎正交(不相关);接近-1则表示方向相反。例如,用向量表示两句话的语义后,若算出余弦相似度为0.95,就表明它们在含义上非常相近。
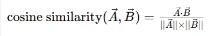
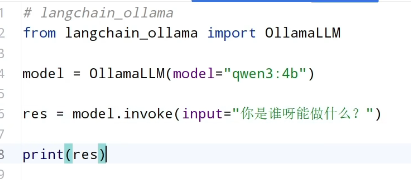
代码实现

大语言模型与聊天模型
一般大模型(或称基础模型)通常是指在海量、多样化的无标注文本数据上通过自监督学习训练而成的通用语言模型,例如原始的GPT-3或BERT。它的特点在于功能广泛但不带特定交互范式:能够完成补全句子、提取关键词、文本分类、生成续写等多种任务,但输出形式往往比较"原始"------可能是一段未加修饰的续写,或者是直接根据前缀生成的补全结果,没有专门针对多轮对话进行优化,也不具备主动的角色扮演或安全回复机制。

大模型的调用
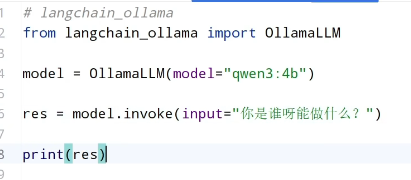
聊天大模型(如ChatGPT、通义千问、文心一言)则是以一般大模型为基础,通过指令微调和基于人类反馈的强化学习(RLHF)等技术专门改造而成的对话导向模型。其最大特点是具备了对话格式的理解能力,能主动遵循"用户---助手"的交互模式,区分多轮上下文,输出更自然、结构化、友好的回答。此外,聊天大模型通常会引入安全对齐机制,拒绝回答有害或违规问题,并倾向于以有帮助、诚实、无害(HHH)的原则呈现答案,而一般大模型在没有额外微调时往往不会有这些"对话礼仪"和安全约束。

聊天大模型的调用