MapReduce 快速入门
MapperReduce代码编写组成
一个MapReduce程序由三部分组成:Mapper、Reducer、Dirver。
Mapper
编写Mapper部分需要用户自定义一个类,并继承Hadoop 中的Mapper类,Mapper以行为单位读取split中的数据,转换成K,V格式,K表示读取当前行数据的offset偏移量,V表示读取当前行数据的内容。针对读取过来的数据用户需要在自定义Mapper类中实现map方法完成相应业务逻辑处理数据,读取到的每行数据都会调用一次map方法,最终返回一条K,V对的数据,便于Reduce端拉取。
Reducer
编写Reducer部分也需要用户自定义一个类,并继承Hadoop的Reducer类,Reducer端输入的数据类型是Mapper的输出的K,V类型。从Map端拉取过来的数据会按照key组进行处理,每组数据<K,V>调用一次reduce()方法。
Driver
编写好Mapper和Reducer代码后需要将Mapper和Reducer最终写入到一个Java类中,这个类就会被称作为Driver类,Driver类中包括MapReduce作业的整体逻辑,包括配置作业、设置Mapper和Reducer类、指定输入
代码案例


- 编写Reducer代码
创建WordCountReducer 代码如下:
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
//创建写出的value
IntWritable total = new IntWritable();
//每组key会调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
//累加
for (IntWritable value : values) {
sum += value.get();
}
//设置当前key对应value结果值
total.set(sum);
//结果写出
context.write(key,total);
}
}以上Reducer<Text, IntWritable,Text,IntWritable>中泛型表示从Map端获取K,V格式数据key的类型、从Map端获取K,V格式化数据Value的类型、Reduce处理完数据写出数据Key的类型、Reduce处理完数据写出数据Value的类型。
- 编写Driver代码
Driver中主要将Mapper和Redcuer代码设置在一起,并设置对应的参数。有如下几个步骤需要设置:
(1) 获取配置信息及job对象。
(2) 设置Driver 程序对应的jar/类。
(3) 设置Mapper和Reducer对应的类。
(4) 设置Mapper输出key、value类型。
(5) 设置最终输出K,V类型。
(6) 设置数据输入和结果写出路径。
(7) 运行任务。
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
if(args.length!=2){
System.out.println("输入输入路径和输出路径参数");
System.exit(1);
}
//1.获取配置信息及job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置Driver 程序对应的jar/类
job.setJarByClass(WordCountDriver.class);
//3.设置Mapper和Reducer对应的类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4.设置Mapper输出key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终输出K,V类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置数据输入和结果写出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.运行任务,运行成功返回true
//参数true 表示打印job执行的信息,例如:读取数据大小,读取和写出条数等。
boolean success = job.waitForCompletion(true);
if (success) {
// 任务执行成功的逻辑
System.out.println("任务执行成功");
} else {
// 任务执行失败的逻辑
System.out.println("任务执行失败");
}
}
}以上代码读取数据是本地文件数据,我们也可以将数据文件上传到HDFS中读取分析,然后将结果写出到HDFS路径中。
MapReduce数据序列化
MapReduce中Map阶段和Reduce阶段需要将数据写入到磁盘,这就涉及到数据序列化与反序列化,Hadoop中提供了自定义的序列化类型Writable类型,这些类型是基于Hadoop的Writable接口实现的,Writable类型在Hadoop中通常用于表示MapReduce作业的输入和输出键值对的键和值类型,可以结合Java中的序列化类型来理解Writable类型,相比于Java 序列化类型,Writable类型可以避免一些Java序列化中的开销,提供的序列化方式更高效。
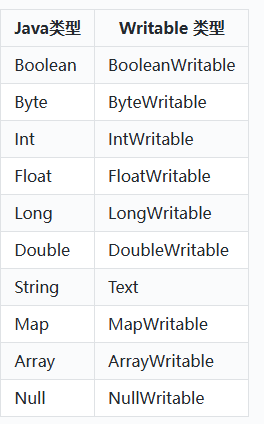
自定义序列化



自定义序列化案例

- 自定义Bean
java
/**
* 自定义类 实现 writable 接口
*/
public class CarInfo implements Writable {
//1.定义空构造
public CarInfo() {
}
//2.定义属性
private String car ;
private Double avgSpeed ;
private Double totalKm ;
//3.设置get set方法和toString方法
public String getCar() {
return car;
}
public void setCar(String car) {
this.car = car;
}
public Double getAvgSpeed() {
return avgSpeed;
}
@Override
public String toString() {
return car + "\t"+ avgSpeed +"\t"+ totalKm ;
}
public void setAvgSpeed(Double avgSpeed) {
this.avgSpeed = avgSpeed;
}
public Double getTotalKm() {
return totalKm;
}
public void setTotalKm(Double totalKm) {
this.totalKm = totalKm;
}
//3.实现序列化、反序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(car);
out.writeDouble(avgSpeed);
out.writeDouble(totalKm);
}
@Override
public void readFields(DataInput in) throws IOException {
this.car = in.readUTF();
this.avgSpeed = in.readDouble();
this.totalKm = in.readDouble();
}
}

- Driver代码
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CarAnalyDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取配置信息及job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置Driver 程序对应的jar/类
job.setJarByClass(CarAnalyDriver.class);
//3.设置Mapper和Reducer对应的类
job.setMapperClass(CarAnalyMapper.class);
job.setReducerClass(CarAnalyReducer.class);
//4.设置Mapper输出key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CarInfo.class);
//5.设置最终输出K,V类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CarInfo.class);
//6.设置数据输入和结果写出路径
FileInputFormat.setInputPaths(job,new Path("data/carinfo.txt"));
FileOutputFormat.setOutputPath(job,new Path("output/"));
//7.运行任务,运行成功返回true
//参数true 表示打印job执行的信息,例如:读取数据大小,读取和写出条数等
boolean success = job.waitForCompletion(true);
if (success) {
// 任务执行成功的逻辑
System.out.println("任务执行成功");
} else {
// 任务执行失败的逻辑
System.out.println("任务执行失败");
}
}
}MapReduce Shuffle
在MapReduce中有一个非常重要的概念:Shuffle。根据之前学习过的MapReduce数据处理流程,我们知道,在Map阶段处理完数据后,会将具有相同key的数据进行重新分区、排序,并最终将每个Map任务的输出合并成一个文件。然后,在Reduce阶段通过数据拷贝将数据传送到相应的Reduce任务进行处理。这个过程就是Shuffle过程的核心。简而言之,MapReduce中的Shuffle过程指的是在Map方法执行后、Reduce方法执行前对数据进行处理和准备的阶段。
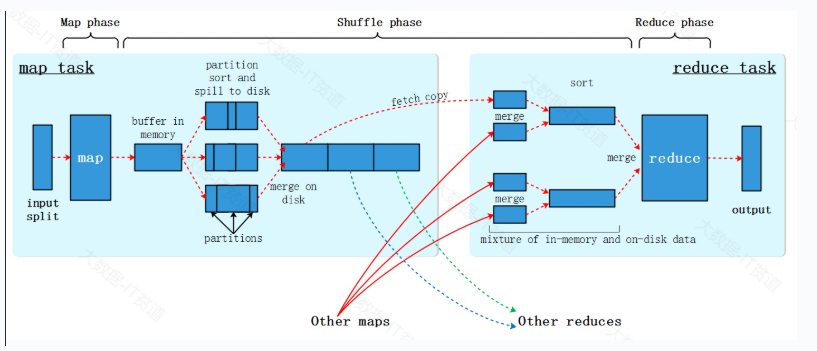
上图Shuffle更加详细的流程如下图所示,Map Task处理完的数据首先写入到默认100M的环形缓冲区,底层使用数组是实现,一半存储数据,一般存储数据对应的索引信息,当环形缓冲区中的空间被使用到80%时数据会发生溢写,同时,会找到剩余空间的中间位置反向继续写入数据和索引,这样做的好处是更好的利用存储空间存储更多的数据。溢写的数据会经过分区、快速排序形成小文件数据,用户可以选择是否使用Combiner进行map预聚合,如果使用每个分区内的数据还会进行合并,多次溢写的小文件最终会通过归并排序合并成一个大磁盘文件,如果设置了压缩,会将数据压缩后最终写入磁盘文件。
Reduce Task会将多个Map Task处理的数据复制到Redcue端,首先会放入内存缓冲区中,当内存不足时会将数据写入到磁盘文件,后续经过归并排序将从不同的Map Task拉取过来的数据合并成一个文件,根据相同的key分成对应的一组组数据,最终被Reduce Task处理。
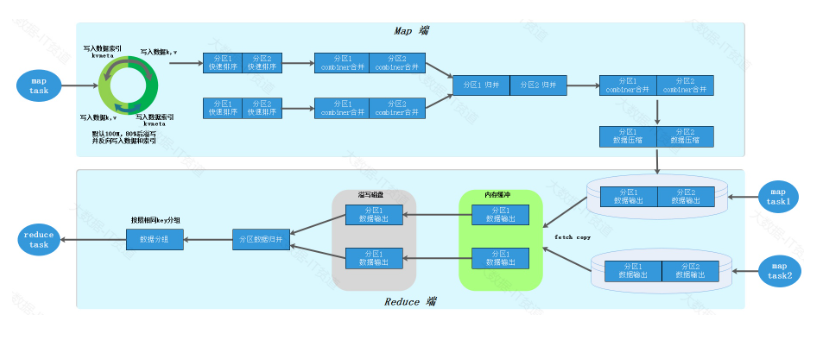
Shuffle阶段包括如下几个步骤:
分区(Partitioning):根据键值对的键,将中间键值对划分到不同的分区。每个分区对应一个Reduce任务,这样可以确保相同键的键值对被发送到同一个Reduce任务上进行处理。
排序(Sorting):对每个分区内的中间键值对按键进行排序(快排)。通过排序,相同键的键值对会相邻存放,以便后续的合并操作更高效。
合并(Merging):对多次溢写的结果按照分区进行归并排序合并溢写文件,每个maptask最终形成一个磁盘一些文件,减少后续Reduce阶段的输入数据量。
Combiner(局部合并器):Combiner是一个可选的优化步骤,在Map任务输出结果后、Reduce输入前执行。其作用是对Map任务的输出进行局部合并,将具有相同键的键值对合并为一个,以减少需要传输到Reduce节点的数据量,降低网络开销,并提高整体性能。Combiner实际上是一种轻量级的Reduce操作,用于减少数据在网络传输过程中的负担。需要注意的是,Combiner的执行并不是强制的,而是由开发人员根据具体情况决定是否使用。
拷贝(Copying):将各分区内的数据复制到各自对应的Reduce任务节点上,会先向内存缓冲区中存放数据,内存不够再溢写磁盘,当所有数据复制完毕后,Reduce Task统一对内存和磁盘数据进行归并排序并交由Redcue方法并行处理。
以上过程共同构成了Shuffle过程,在MapReduce中起着重要的作用,用于重新组织和准备数据,并在Reduce阶段进行最终的计算和处理。