1、问题
最近又又又再项目中遇到这样奇奇怪怪的写法
c
select count(1)
from t1
where exists (select 1
from (select case t1.state when 1
then sum(sum(t3.ll*0.5)+nvl(max(t2.ll),0)) over(partition by t3.c1) end as bstate
from t2,
t3
where t2.id=t3.c1 and t2.id=t1.id
group by t3.c1)
where bstate>10 );计划:
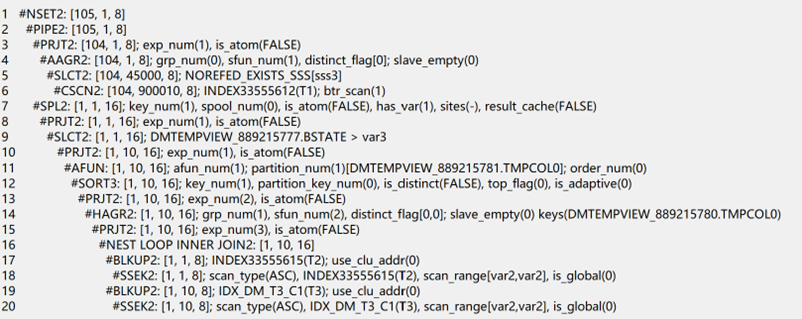
从计划上看只能做非相关子查询,即每次获取主查询一条记录去子查询根据条件判断过滤获取结果。为什么会这样?原因是因为exists中select存在主查询条件作为查询项得出结果后还要通过where去过滤,因此只能主查询一条一条去判断,主查询数据量增加,效率急剧下降。这种写法需要转换成相关子查询,即做成相关关联,将子查询做成结果集与主查询关联。
思路拆解
获取子查询结果集,
子查询查询项
sum(sum(t3.ll*0.5)+nvl(max(t2.ll),0)) over(partition by t3.c1)是子查询中获取的
因此可以先把这一部分求出来
c
select t3.c1,sum(t3.ll*0.5)+nvl(max(t2.ll),0) as bstate
from t2, t3 where t2.id=t3.c1
group by t3.c1然后与主查询关联条件是t2.id=t1.id,而t2.id=t3.c1那么t3.c1=t1.id,
Exists:是判断子查询中是否存在与主查询相匹配的结果。如果相匹配就返回主查询相匹配的结果。它只是判断主查询是否有相匹配的记录,因此exsits只做判断,如果转换成inner join,inner join是获取相匹配的记录,如果子查询结果有重复,与主查询做关联,那会重复输出结果,因此需要子查询去重才能成功转换成inner join。而group by t3.c1(关联列)达到去重效果。
因此可以改写成
c
select t1.*,case t1.state when 1 then bstate end bstate
from t1,
(select t3.c1,sum(t3.ll*0.5)+nvl(max(t2.ll),0) as bstate
from t2, t3 where t2.id=t3.c1
group by t3.c1) b where t1.id=b.c1然后再把查询项获取出来再where处理,最终完成改写。
2、改写
c
select count(1) from (
select t1.*,case t1.state when 1 then bstate end bstate
from t1,
(select t3.c1,sum(t3.ll*0.5)+nvl(max(t2.ll),0) as bstate
from t2, t3 where t2.id=t3.c1
group by t3.c1) b where t1.id=b.c1 ) tt
where bstate>10;计划:

计划上达到预期的效果,做成关联。
执行时间从 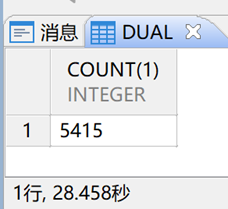
下降至 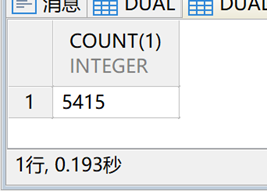
3、小结
对于这种写法,主要思路是拆解,子查询能获取的先获取,然后找与主查询的关联关系关联主查询,最后做条件过滤。