手搓一个最小 Agent:从一次 API 调用到工具闭环
摘要:上一篇我们把 Agent 理解成"模型 + 运行时 + 工具 + 观察"的行动闭环。这一篇开始落到代码:先调通一次模型 API,再加对话循环、history、system prompt、tool use 和 skills。你会看到,一个最小 Agent 不是从框架里变出来的,而是从几层非常朴素的控制流里长出来的。
标签:Agent、Python、LLM API、Tool Use、Skills

为什么要先手搓
很多人学习 Agent,会直接从框架开始:安装依赖、创建 agent、注册工具、跑一个 demo。这当然很快,但也容易让人不知道每一层到底在解决什么问题。
如果先手搓一次,你会发现 Agent 的基础骨架并不复杂。项目里的教学代码从 step01_single_call.py 到 step06_skills.py,每一步只增加一个能力:
text
单次调用 → 对话循环 → history → system prompt → tool_use → skills这条链路非常适合用来理解 Agent 的"生长过程"。不是一开始就有完整系统,而是一层一层把运行时补出来。

第一步:一次模型调用
最小代码只有一个目标:把电话打通。用户输入一句话,程序调用模型,打印回答。
关键代码在 build-agent-example/code/step01_single_call.py:
python
message = client.messages.create(
model=MODEL,
max_tokens=1000,
messages=[{"role": "user", "content": user_input}]
)这一版还不是 Agent。它没有循环,没有记忆,没有工具,也没有角色设定。它只是一次 API 请求。
但这一步非常重要。你必须先知道 messages 怎么传,模型返回的 content 怎么读,文本 block 怎么取出来。所有复杂能力最终都会回到这条调用链上。
可以把它理解成:
text
input → messages.create() → content blocks → print如果这一步跑不通,后面所有 Agent 能力都没有意义。
第二步:循环不等于记忆
step02_loop_no_memory.py 加了一个 while True,让程序可以持续对话:
python
while True:
user_input = input("你: ")
message = client.messages.create(
model=MODEL,
max_tokens=1000,
messages=[{"role": "user", "content": user_input}]
)这一步让交互变连续,但模型仍然失忆。因为每一轮传给模型的 messages 只有当前这一句。
你可以这样测试:
text
你:我叫张三
你:我叫什么名字?模型很可能答不上来。不是它不够聪明,而是程序没有把上一轮消息交给它。大模型 API 默认是无状态的,状态必须由调用方维护。
这个失败很有价值,因为它把一个常见误区打掉了:循环只是让程序不断调用模型,history 才让模型看到上下文。
第三步:history 才是上下文
step03_history.py 开始维护一个 history 列表:
python
history.append({"role": "user", "content": user_input})
message = client.messages.create(
model=MODEL,
max_tokens=1000,
messages=history
)
reply = next(b.text for b in message.content if b.type == "text")
history.append({"role": "assistant", "content": reply})这里有两个关键点。
第一,用户输入要 append。第二,模型回答也要 append。只记录用户说过什么是不够的,模型还需要知道自己上一轮答过什么、承诺过什么、已经解释过什么。
有了 history,模型就能"记住"前文。但这里的记住不是模型内部状态改变了,而是程序每轮把历史重新发给它。这个理解非常重要,因为它直接引出下一个工程问题:history 会越来越长。
第四步:system prompt 固定行为
step04_system_prompt.py 增加了 system 参数:
python
message = client.messages.create(
model=MODEL,
max_tokens=1000,
system=SYSTEM_PROMPT,
messages=history
)system prompt 适合放全局规则:角色、语气、回答语言、行为边界。它不应该和普通 user message 混在一起,否则用户每轮都要重复规则,后续对话也更容易冲淡设定。
在教学项目里,system prompt 把助手设定成"大内太监总管",这是为了让行为变化更明显。你可以看到模型不只是回答内容变了,整体称呼、口吻和输出格式也被固定下来。
工程上要记住的是:system prompt 是运行时的一部分。 它不负责执行工具,但会影响模型什么时候调用工具、如何解释结果、如何收口。
第五步:tool_use 让模型开始行动
step05_tool_use.py 是真正进入 Agent 的一步。它声明了一个 run_command 工具:
python
TOOLS = [{
"name": "run_command",
"description": "在终端执行一条 shell 命令并返回输出",
"input_schema": {
"type": "object",
"properties": {
"command": {"type": "string"}
},
"required": ["command"]
}
}]当模型返回 tool_use 时,程序不直接结束,而是执行工具,把结果作为 tool_result 再放回 history:
python
if message.stop_reason != "tool_use":
break
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output
})
history.append({"role": "user", "content": tool_results})这就是最小工具闭环。
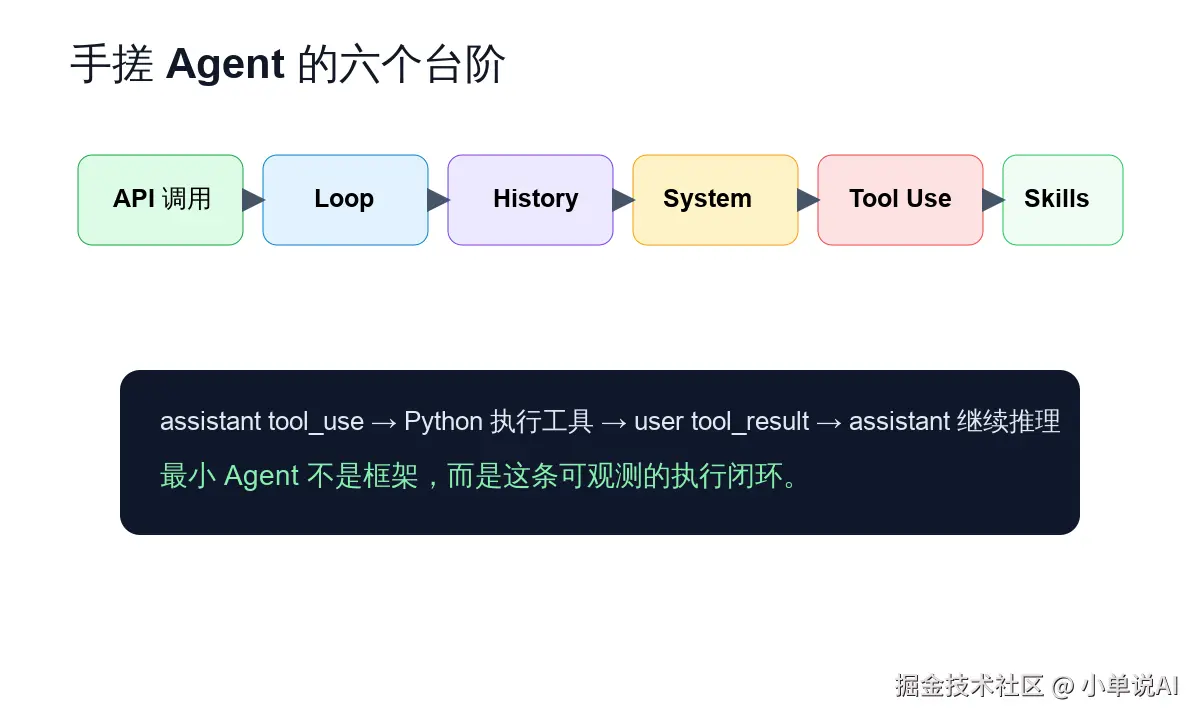
模型不是直接运行 shell。它只是输出一个结构化请求:我要调用 run_command,参数是什么。真正执行命令的是 Python 程序。执行完后,模型看到命令输出,再判断任务是否完成。
如果你只记住一个核心结构,就记住这个:
text
assistant: tool_use
Python: execute tool
user: tool_result
assistant: continue第六步:skills 让知识按需加载
当工具越来越多、规则越来越多时,另一个问题会出现:system prompt 不能无限变长。
step06_skills.py 用 skills 解决这个问题。启动时扫描 skills/**/SKILL.md,只把技能名称和简介放进 system prompt;真正需要时,模型再调用 load_skill 读取完整内容。
核心加载逻辑大概是:
python
for f in sorted(self.skills_dir.rglob("SKILL.md")):
text = f.read_text()
meta, body = self._parse_frontmatter(text)
name = meta.get("name", f.parent.name)
self.skills[name] = {"meta": meta, "body": body}这是一种很实用的 progressive disclosure:先告诉模型"有什么",需要时再给它"全部内容"。这样既节省上下文,也避免大量无关知识稀释当前任务。
六层能力合在一起
这六步看起来简单,但已经把一个最小 Agent 的核心骨架搭出来了:

text
step01:会调用模型
step02:能持续交互
step03:能带上下文
step04:有固定规则
step05:能调用工具
step06:能按需加载知识后面如果要把代码变成更工程化的项目,就会把这些逻辑拆成更清晰的模块:Runner 负责模型循环,Registry 负责工具注册,Tool 负责参数和执行,SkillsLoader 负责按需加载知识。
但抽象背后的控制流没有变。看懂这个版本,再看复杂框架,你会知道每一层包装到底在包什么。
跟着写时怎么验收
每一步都应该有一个明确的测试。
step01:输入一句话,确认能得到模型回答。重点检查 API key、base url、model 环境变量。
step02:连续问两轮,确认程序不会退出。然后故意测试"我叫张三 / 我叫什么名字",观察模型失忆。
step03:重复同样测试,确认 history 生效。
step04:检查模型是否稳定遵守 system prompt,比如语言、称呼、前缀。
step05:让模型查看当前目录或运行一个简单命令,确认终端里真的出现工具执行日志。
step06:新增一个简单 SKILL.md,重启程序,问相关问题,看模型是否会调用 load_skill。
这些验收都不复杂,但它们能确认每一层能力是真的跑通了,而不是只停留在"看懂代码"。
工程取舍:为什么先不抽象
你可能会觉得 step01 到 step06 有很多重复:每个文件都创建 client,每个文件都写循环,每个文件都处理输入输出。作为生产代码,这当然不优雅。但作为学习代码,它非常合适。
因为每一个文件都只展示一个变化点。step02 只证明循环,step03 只证明 history,step05 只证明 tool_use。读者可以用 diff 的方式理解"新增这几行之后,系统能力发生了什么变化"。
如果一开始就把所有东西抽成 AgentRunner、ToolRegistry、SkillLoader,代码会更干净,但学习曲线会更陡。你会看到一堆类,却不知道它们为什么存在。
所以更好的节奏是:
text
先写重复代码,看清控制流
再发现重复点,抽出模块
最后用模块承载更复杂的能力这也是手搓的意义:不是为了永远不用框架,而是为了以后用框架时知道它替你做了什么。
常见错误:漏掉 assistant 消息
初学者写 history 时,最容易犯的错误是只 append 用户消息。这样模型确实能看到用户说过什么,但看不到自己回答过什么。对简单问答影响不大,对工具调用影响很大。
比如模型上一轮已经承诺"我会先读取文件",下一轮如果看不到自己的承诺,就更容易重复、跳步或改口。完整 history 必须包含 user 和 assistant 两边,工具调用也要保留对应的 tool_use 和 tool_result。
另一个常见错误是工具执行完后直接把输出打印给用户,而不是回灌给模型。这样模型并不知道工具结果,自然无法基于结果继续推理。Agent 的关键不是"程序能执行工具",而是"模型能观察工具结果"。
最小工具也要考虑边界
教学里只有一个 run_command,看起来万能。你让模型列目录、运行脚本、查看 git 状态都可以。但真实项目里,shell 工具是最需要小心的工具之一。
至少要考虑:
text
命令是否超时
输出是否过长
是否允许写文件
是否允许访问工作区外目录
失败时返回 stdout 还是 stderr
是否记录执行过的命令这些边界在最小示例里先不展开,但你要从一开始就知道它们存在。Agent 能力越强,运行时越要负责把危险动作框住。模型负责提出行动,代码负责决定行动是否允许、如何执行、如何记录。
为什么 history 要保持"原样"
有些人写最小 Agent 时,会想把 history 简化成一串字符串:用户说了什么、模型答了什么,都拼在一个 prompt 里。这样短期能跑,但很快会遇到问题。
第一,工具调用本来就是结构化事件。模型发出的不是普通文本,而是"我要调用哪个工具、参数是什么"。如果把它拍平成字符串,程序就很难稳定恢复工具名和参数。
第二,工具结果也需要和对应的 tool_use 对上。模型先请求读取文件,程序返回文件内容;如果中间关系乱了,模型会误以为某个结果来自另一个动作。
第三,后续调试会很痛苦。结构化 history 可以直接看每一轮消息、每一次工具调用、每一段工具返回;字符串 prompt 只能靠肉眼猜分隔符是否正确。
所以最小实现里虽然代码朴素,但消息结构要尽量尊重 API 本身。不要为了少写几行代码,把后面最难排查的状态搞丢。
System Prompt 不要写成愿望清单
system prompt 的价值是给模型稳定规则,而不是堆满口号。比如"你要聪明、严谨、主动、不要犯错"帮助不大,因为这些词没有可执行边界。
更有用的写法是把行为写清楚:
text
回答前先判断是否需要工具
如果需要工具,优先读取真实信息
工具失败时解释失败原因并尝试替代路径
不知道时不要编造文件或命令输出这些规则能直接影响循环行为。模型看到问题时,会更倾向于先拿事实;工具失败时,也更容易把失败当成观察结果,而不是直接编一个圆满结论。
写 Agent 的 prompt,重点不是让模型"性格更像助手",而是让它在循环里的决策更稳定。
Skills 解决的是上下文选择问题
skills 看起来只是把 Markdown 文件加载进来,但它解决了一个很实际的问题:不是所有知识都应该常驻 prompt。
如果你把所有项目约定、所有工具说明、所有写作规范都塞进 system prompt,模型每一轮都要读一遍,注意力会被稀释,token 成本也会上升。Skills 的思路是先给模型一个索引,需要时再加载具体内容。
这和人工作很像:你不会把所有手册都背下来,而是知道"遇到某类问题时该查哪份手册"。最小 Agent 加上 load_skill 后,已经开始具备这种按需取用上下文的能力。
小结
一个最小 Agent 不是一开始就复杂。它从一次 API 调用开始,逐步加上循环、history、system prompt、tool use 和 skills。
这篇最重要的结论是:Agent 的基础不是框架对象,而是工具闭环。只要模型能请求工具,程序能执行工具,结果能回到上下文,模型能继续判断,一个 Agent 的骨架就已经出现。
但这也留下了新的问题:history 会随着对话和工具结果不断增长。一个能长期工作的 Agent,不能永远把所有原始消息都塞回模型。下一步,就要给它设计记忆系统。
视频与源码
如果你想看完整演示,可以在主页的《从零手搓 Agent》合集里按顺序观看视频版:
文章里的示例代码和完整项目也放在这里:
- 📦 教学仓库:github.com/TheSyart/cl...
- ⚔️ 实战项目:github.com/TheSyart/em...
我会持续更新 Agent 教学与实战内容。觉得有用的话,欢迎给项目点个 Star ⭐,也谢谢你一路看到这里。