引言
今天我们来学习线程池相关的内容。那么以一个基于实际的 Java 多线程统计案例为学习切入点,让我们详细分析线程池的使用方式、任务拆分思想、并发统计原理,以及代码中涉及到的重要知识点
案例引入
现在有一个长度为100万的字符串数组(都是字母) 我们想要统计其中每个字符串,最后输出字母a的个数(后续可扩展到每一个字母)
首先我们来分析一下,为什么这个案例题目需要用到线程池:
线程池原理
如果按照常规思路,每次执行统计任务的时候都
new Thread().start();创建一个线程,那么会出现以下几个问题:
1.为什么需要线程池
1).线程创建开销十分巨大:因为线程属于系统资源,每次创建线程都需要分配内存,创建线程对象同时调用系统内核。那么面对大数据时,频繁创建销毁线程非常的消耗性能。
2).线程数量太多导致不可控:面对大数据时大量线程的瞬间创建,直接会导致内存暴涨、系统卡死。
3).线程无法复用:每次任务执行完线程自然死亡,新的任务又要重新创建线程,导致资源浪费十分严重。
2.线程池的核心原理
本质:
- 提前创建好线程
- 任务来了直接复用线程
(就比如工厂提前招聘工人,在有订单时直接干活而不用临时招人)
那么这样的方式就会有其明显的优点:
优点:
- 降低线程创建开销
- 控制线程数量
- 提高系统稳定性
- 提高并发性能
了解后使用原因后,我们可以为解决案例设计以下整体流程
主线程
↓
创建 NetworkService
↓
创建线程启动 service.run()
↓
创建线程监控线程池状态
↓
线程池执行多个 Handler 任务
↓
每个 Handler 统计一部分字符串中的 a
↓
使用 AtomicInteger 汇总结果
↓
线程池关闭
↓
输出最终统计结果
(而该设计的核心思路本质上是并行计算的经典思想,即
将大任务拆分为多个小任务,通过线程池并发执行,最后汇总结果)
好的下面我们逐步分析整个流程
首先让我们
创建线程池
pool = new ThreadPoolExecutor(
poolSize,
poolSize * 2,
30,
java.util.concurrent.TimeUnit.MILLISECONDS,
new java.util.concurrent.ArrayBlockingQueue<>(100)
);1. ThreadPoolExecutor 构造参数
构造方法:
ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue
)2. 参数解析
(1)corePoolSize
poolSize//核心线程数
new NetworkService(10);因此:
核心线程数 = 10含义:
- 线程池最少保留10个线程
- 即使空闲也不会销毁
(2)maximumPoolSize
poolSize * 2即
最大线程数 = 20含义:
- 当任务很多时
- 线程池最多扩展到20个线程
(3)keepAliveTime
30含义:
非核心线程空闲30ms后销毁(4)TimeUnit.MILLISECONDS
时间单位:
毫秒(5)ArrayBlockingQueue
new ArrayBlockingQueue<>(100)阻塞队列。
作用:存储等待执行的任务
容量:最多100个任务
测试数据初始化
为了方便测试,我们先设置小数据
String[] str = new String[10];初始化:
// 测试数据
str[0] = "aaa";
str[1] = "abc";
str[2] = "bbb";
str[3] = "aac";
str[4] = "ddd";
str[5] = "a";
str[6] = "xyz";
str[7] = "aa";
str[8] = "hello";
str[9] = "javaaaaaaaaaaaaa";作用:用于模拟待处理的数据。
run() 方法核心分析
1. CPU核心数
int cpuNums = 32;这里模拟:
CPU 有 32 个核心2. 为什么任务数是 cpuNums * 2?
代码:
int taskNum = Math.min(cpuNums * 2, str.length);即:
任务数 = CPU核心数 × 2原因:
CPU执行线程时,线程可能需要计算,io流等待,sleep,阻塞等,
如果只创建:
//任务数
int taskNum = cpuNums * 2;
CPU核心数 = 32
线程数 = 32那么可能部分线程在等待。
因此通常,我们使线程数>CPU核心数来提高CPU利用率。
问题1:
但是我一开始在小数据情况下仅考虑
//任务数
int taskNum = cpuNums * 2;×
**错误描述:**运行跑起来后发现卡卡的,且有好多用于输出的代码上,前面提到的参数corePoolSize以及maximumPoolSize疯狂跑0,只发现最后一次出现较为有效的输出。
解决方案:
需要对分片任务数做出以下限制:
//分片任务数不能超过字符串数组的长度
int taskNum = Math.min(cpuNums * 2, str.length);因为小字符字符串只有10个,没必要创建64个任务导致空跑,浪费资源
任务拆分思想(重点)
1. 分片大小计算
很好理解,分片大小的计算就=总字符串的长度/任务数呗,于是我直接
问题2又来了:
//分片大小
int chunkSize = str.length / taskNum;×
**错误描述:**导致所有的参数都少跑或直接跑0。。。。。
解决方案:注意向上取整。。不然极容易取到0;
//分片大小向上取整
int chunkSize = (str.length + taskNum - 1) / taskNum;使用经典的向上取整公式
任务区间划分
for (int i = 0; i < taskNum; i++) {每轮创建一个任务。
1. start计算
int start = i * chunkSize;例如:
| i | start |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
2. end计算
if (i == taskNum - 1) {
end = str.length;
} else {
end = (i + 1) * chunkSize;
}最后一个任务负责处理剩余所有数据
因此我们得到实际划分结果:
| 任务 | 区间 |
|---|---|
| 0 | [0,1) |
| 1 | [1,2) |
| 2 | [2,3) |
| ... | ... |
| 9 | [9,10) |
线程池提交任务
pool.execute(new Handler(str, start, end, totalCount));含义:将任务提交给线程池,那么线程池就会从线程池中取出空闲的线程执行任务
shutdown() 原理
pool.shutdown();注意:
shutdown() ≠ 立即关闭线程池它的本质其实是不再接收新任务但是会执行完接收到的已有任务
因此程序依旧会继续执行。
Handler 类分析
1. Handler 的作用
每个 Handler负责处理一部分字符串
统计 a 的核心逻辑
for (int i = start; i < end; i++) {遍历当前任务负责的数据。
字符遍历
for (int j = 0; j < s.length(); j++) {遍历字符串字符。
判断字符
if (s.charAt(j) == 'a')判断是否为 'a'。
局部统计
count++;注意:
这里使用局部变量:
int count = 0;原因:
局部变量属于线程私有,不会导致线程冲突
AtomicInteger 线程安全原理(重点)
1. 为什么不用普通 int?
如果:
int totalCount;多个线程同时:
totalCount++;肯定会产生线程安全问题:
- 因为totalCount++不是原子操作
- 多个线程同时操作读写,计数++,肯定会导致数据覆盖,最终统计错误。
2. AtomicInteger 原理
AtomicInteger totalCount = new AtomicInteger(0);它基于**CAS(Compare And Swap)**实现无锁原子操作。
3. addAndGet()
totalCount.addAndGet(count);作用:实现原子性的累加,即多个线程同时操作也不会出错
监控线程池状态
pool.getActiveCount()获取:当前活跃线程数
pool.getPoolSize()获取:当前线程池总数
pool.getTaskCount()获取:总任务数
pool.getCompletedTaskCount()获取:已完成任务数
本案例并发思想总结
本案例体现了经典:
"分治 + 并发"思想。
即:
大任务
→ 拆分成多个小任务
→ 多线程并发执行
→ 汇总结果涉及核心知识点
并发相关
- 多线程
- Runnable
- 线程池
- ThreadPoolExecutor
- 阻塞队列
- 原子类
- CAS
- 线程安全
算法思想
- 分片处理
- 向上取整
- 分治思想
程序最终统计结果分析
运行结果:
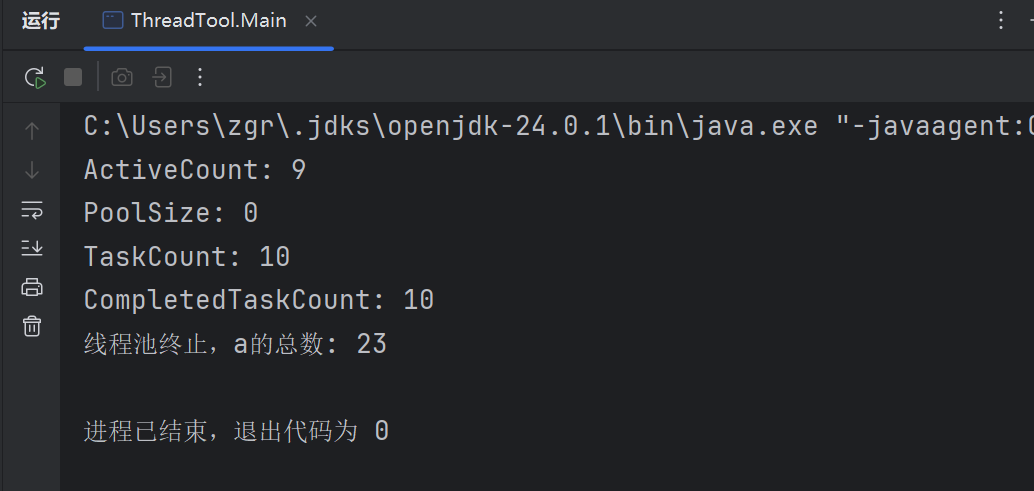
统计所有字符串中的 'a':
"aaa" → 3
"abc" → 1
"bbb" → 0
"aac" → 2
"ddd" → 0
"a" → 1
"xyz" → 0
"aa" → 2
"hello" → 0
"javaaaaaaaaaaaaa" → 14最终:
总数 = 23总结
这个案例虽然规模不大,但让我完整学习了:
- 线程池使用
- 任务拆分
- 并发处理
- 原子操作
- 线程池监控
等核心并发知识。