使用 TiDB 的过程中,写入、查询、扩容这些环节通常不会出太大问题。真正的挑战往往出现在 TiDB 的数据迁移与同步。无论是给数仓提供实时数据,还是为搜索引擎构建索引,或者将变更日志推送到消息队列,如何把 TiDB 的数据高效、稳定地向外传送,其实比想象中复杂得多。
本文将从 TiDB 同步的难点出发,梳理现有方案的边界,并介绍更成熟的平台化解决方案,帮助你做出更合适的选择。
为什么同步 TiDB 比同步 MySQL 难
说到 TiDB 同步,很多人第一反应是,TiDB 兼容 MySQL 协议,同步方案应该差不多吧?
但实际上并不相同,而且差距不小。
在单实例 MySQL 中,binlog 本身是一条天然有序的变更流,解析起来路径清晰。而 TiDB 是分布式的,数据打散到多个 TiKV 节点,不同 Region 的事件会并发产生和到达,下游需要自行处理顺序整理。
这就带来几个具体的难点。
一是乱序,同一张表的数据分布在多个 Region,事件到达的顺序不代表事务发生的顺序,下游如果没有处理好,数据一致性就会出问题。
二是断点恢复,分布式场景下,任务中断之后怎么接着跑、从哪里继续,要比单机复杂得多。如果处理不当,很容易造成大面积的数据重复或者缺失。
三是 GC safe point,TiDB 有自己的垃圾回收机制,历史变更不会永久保留。如果同步任务的位点落到安全点之前,原有增量位点将无法继续追赶,只能重新进行全量同步。
这三件事,是 TiDB 数据同步真正难的地方。
官方方案:TiCDC
要实现 TiDB 同步,很多人会自然想到 TiCDC,这是 TiDB 官方推出的 CDC 组件,也是目前最常见的 TiDB 数据导出方案。
TiCDC 的工作方式是订阅 TiKV 的数据变更事件,经过排序和合并后,将变更以 changelog 的形式推送给下游。它原生支持 Kafka、MySQL 和 TiDB 作为下游目标,对于标准的数据同步链路来说,这套机制成熟可靠,社区维护也比较活跃。
但它的边界也比较明确。TiCDC 更偏向于提供底层 CDC 能力,而不是完整的数据集成与同步平台,不具备生产级的功能,比如多目标分发、复杂的字段映射、跨异构数据库写入、任务级别的运维治理。对于有多条同步链路、需要统一管理、或者下游目标类型多样的团队,TiCDC 在生产场景落地过程中会遇到不少难题。
平台化解决方案:CloudCanal
CloudCanal 是专业的数据迁移与同步平台,支持多种数据库和消息队列之间的实时同步。
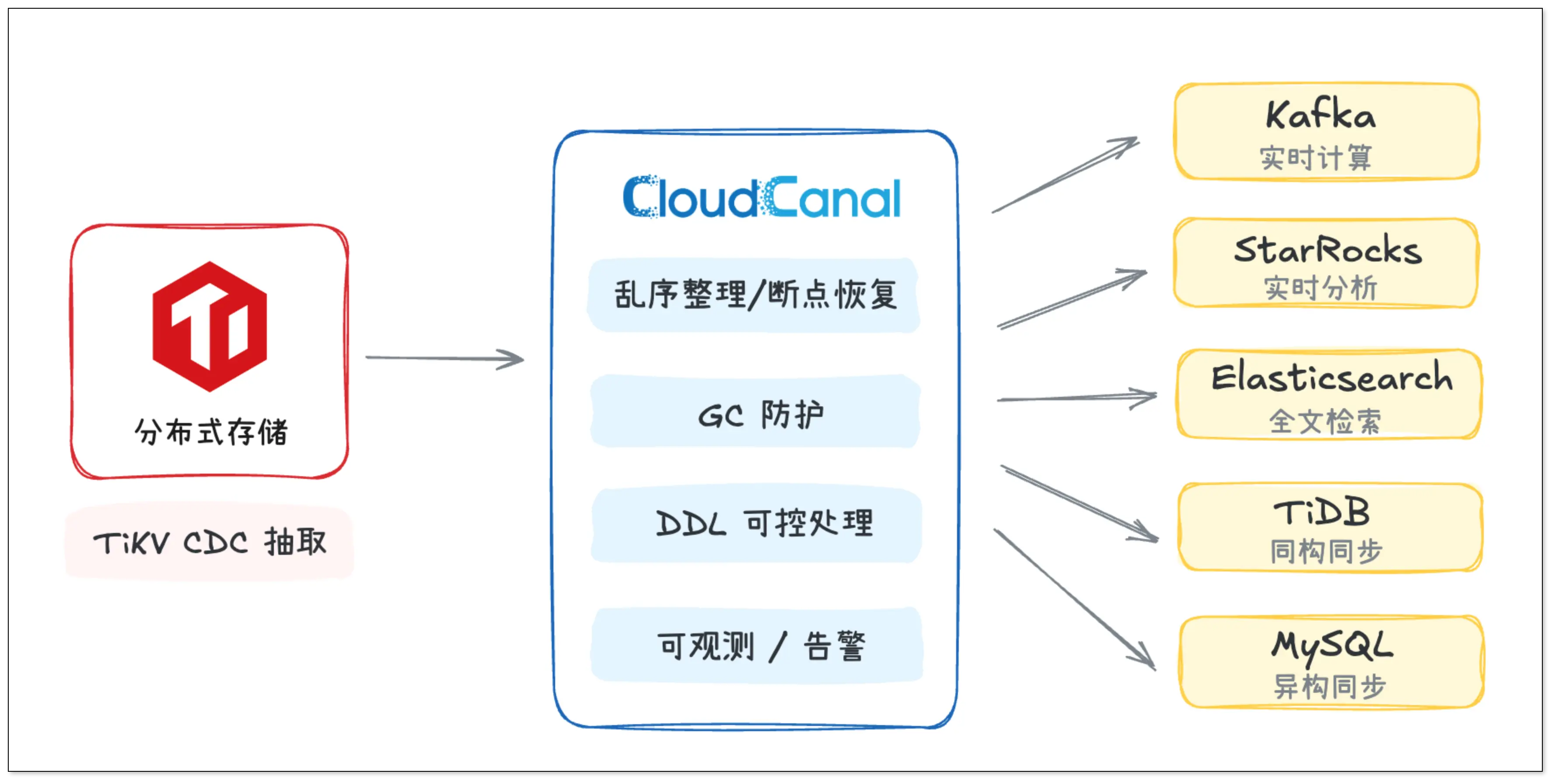
在 TiDB 链路上,CloudCanal 采用 TiKV CDC 的 gRPC eventFeed 机制,从存储层直接接收变更事件,在跨分片并发和数据迁移同步场景下具备很强的适应性。
针对 TiDB 的同步难点,CloudCanal 也做了相应的优化设计。
乱序整理/断点恢复
针对乱序和断点恢复的难题,CloudCanal 会等上游确认某个时间戳之前的变更已经全部到齐,再推进同步进度,同时在内部整理乱序到达的事件,向下游输出稳定有序的变更。任务中断后,续跑有明确的起点,不会出现大面积重复或数据缺失。
GC safe point 防护
TiDB 的 GC safe point 是 CDC 稳定性的硬约束。针对这一点,CloudCanal 也做了相应的优化。在任务运行中,CloudCanal 会持续跟踪 GC 清理进度,主动保持安全距离,避免长时间积压或故障恢复后发现历史数据已被清理、任务无法续跑的情况。
DDL 可控处理
生产环境里,DDL 往往比 DML 更容易引发事故。结构变更一旦在错误的时机落地,大概率会导致下游写入失败、数据错乱。CloudCanal 把结构变更和数据变更分开处理,确保 DDL 在合适的时机落地,从而降低下游写入失败、元数据不一致等问题。
可观测与治理能力
相比 TiCD,CloudCanal 把 TiDB 链路纳入统一的任务引擎体系,接收量、同步延迟等关键数据都可以实时观测,异常情况可以配置多种形式的告警。出了问题,日志和监控有足够的上下文帮助快速定位。这些生产级功能,对于需要长期运行、多条链路并行、有明确 SLA 要求的团队来说,往往是不可或缺的能力。
这几重设计,让 TiDB 数据同步更稳定、更准确。
如何选择
TiCDC 和 CloudCanal 面向的场景并不完全重叠,不是非此即彼的关系。
如果链路比较单一,就是 TiDB 到 Kafka 或者 TiDB 到 MySQL,TiCDC 完全可以胜任,不需要额外引入一个组件。
但如果场景更复杂一些,CloudCanal 的优势就开始显现。
同一份 TiDB 变更,可能要同时进 Kafka 做实时计算、进 StarRocks 做分析、进 ES 做检索。如果每个目标端都围绕 TiCDC 单独搭一套消费写入体系,维护成本会快速增长。CloudCanal 把这些复杂过程统一到一个任务引擎里,源端负责抽取,目标端负责写入,映射、过滤、异常处理都在同一套框架内完成,不需要在 TiCDC 之后再单独搭消费框架。
表级别的精细控制也是生产中的实际诉求。临时下线一张表,或者新增一批表,这类操作在日常运维里很常见。CloudCanal 在任务创建时可以筛选需要的表、列,同步过程中还可以按需增减,不需要在多个地方分散维护。
稳定性上,CloudCanal 本身就内置了大量生产级功能,异常判定、任务并行与拆分,告警机制,加上前面提到的 GC 防护,这些能力叠加起来,让 TiDB 同步可以长期稳定地运行。
总结下来,如果需要多目标分发、异构数据库落地、表级别精细控制,或者对稳定性和可观测性有较高要求,CloudCanal 是更适合的选择。
总结
选对工具,是让数据流转持续可靠的第一步。
TiDB 的数据同步,难点不在接口兼容,而在分布式架构带来的乱序、断点恢复和 GC 约束。TiCDC 解决了同步能力的问题,适合链路单一、目标明确的场景。CloudCanal 在此基础上,把抽取、映射、写入、治理整合进一个任务引擎,更适合有多条链路、多个下游目标、对长期稳定运行有较高要求的团队。
如果感兴趣,不妨试一下 CloudCanal 免费社区版,五分钟内快速上手 👉 www.clougence.com