在日常的开发中,我们最熟悉的数据库莫过于 MySQL 或是常规的 PostgreSQL 了。但在面对某些特定的业务场景时,你可能会发现传统的数据库开始变得"力不从心",尤其是当你需要疯狂记录带时间戳的数据时,数据量一大,查询和写入就卡得怀疑人生。这时候,"时序数据库(Time-Series Database, TSDB)"就该闪亮登场了。
今天这篇内容,我将带大家从零开始搞懂什么是时序数据库,它和传统的 MySQL 到底有什么区别,并且手把手教大家如何用 Docker 一键部署带有 TimescaleDB 插件的 PostgreSQL,稍微带大家简单跑个实战,感受一下时序数据库的降维打击!
一、 什么是时序数据库?
简单来说,时序数据库是专门为处理带有时间标签(Time-stamped)的数据而设计的数据库。
想象一下,日常生活中有很多数据是随着时间不断产生且不可变的。比如:
- 气象站每秒记录一次的温度和湿度;
- 你服务器每分钟的 CPU 和内存占用率;
- 股票市场里每毫秒都在变动的价格。
这类数据的核心特征只有一个:数据 = 时间戳 + 测量值。时序数据库就是为了这种"高频写入、按时间段查询、按时间老化淘汰"的场景量身定制的顶级武器。
二、 时序数据库 vs 普通关系型数据库(如 MySQL)
很多朋友会问:"我用 MySQL 加一个 datetime 字段,然后建个索引,不也能存时间数据吗?为什么要单独搞个时序数据库?"
能存是能存,但当数据量来到千万甚至亿级别,两者就会有天壤之别:
-
写入性能的差异
- MySQL:普通关系型数据库的数据往往存在复杂的更新(Update)操作,底层用的是 B+ 树等结构。当表里有几亿条数据时,再往里疯狂插入新数据,维护索引的成本极高,写入速度会断崖式下跌。
- 时序数据库 :时序数据基本是追加写入,很少去修改历史数据(比如你不可能去修改昨天上午10点的温度)。时序数据库底层针对持续追加做了深度优化,单机就能轻松扛住每秒数万甚至数十万的并发写入。
-
查询与聚合的能力
- MySQL :如果要查"过去一个月每天最高温度的平均值",你需要写繁琐的
GROUP BY和时间转换函数,且查询极慢。 - 时序数据库 :原生提供时间窗口函数。以我们今天要讲的 TimescaleDB 为例,只需一个自带的
time_bucket()函数,就能秒级对海量数据进行按分钟、按小时的降采样聚合查询。
- MySQL :如果要查"过去一个月每天最高温度的平均值",你需要写繁琐的
-
数据清理(生命周期管理)
- MySQL :想删除半年前的数据?
DELETE FROM table WHERE time < ...。这会导致巨大的磁盘 I/O,容易锁表,还会产生大量磁盘碎片。 - 时序数据库:通常会将数据按时间"分块(Chunk)"物理存储。删除半年前的数据,直接把那个时间段的"块"物理文件丢弃(Drop)即可,瞬间完成,毫无负担。
三、 什么场景下会用到时序数据库?
- MySQL :想删除半年前的数据?
如果你的项目符合以下几个场景,请果断放弃单表 MySQL,拥抱时序数据库:
- 物联网(IoT)设备监控:智能家居状态上报、工厂传感器数据收集、车联网轨迹与车况上报。
- IT 基础设施监控:服务器指标(CPU、内存、网络 IO)、微服务链路追踪日志。
- 金融与加密货币:实时的股票分时图、K线图数据,量化交易的行情记录。
- 业务埋点监控:APP 日活分析中的高频用户行为打点记录。
四、 实战:用 Docker 一键部署 PGSQL + TimescaleDB
这里必须要科普一个冷知识:TimescaleDB 本质上是 PostgreSQL 的一个超级插件(Extension)。这意味着你不仅能拥有强大的时序处理能力,还能毫无保留地使用 PostgreSQL 丰富的关系型数据库特性(比如联表 JOIN查询、甚至 PostGIS 地理空间处理)。
根据 Timescale 官方的 Docker 部署文档,最爽的安装方式就是直接拉取官方镜像!
注意:这个官方镜像已经把 PostgreSQL 引擎和 TimescaleDB 插件打包在一起了!你不需要先下载 PGSQL 再去装插件,一行命令直接搞定全套!
确保你的电脑已经安装了 Docker,在终端中直接运行以下命令:
bash
docker pull timescale/timescaledb:latest-pg16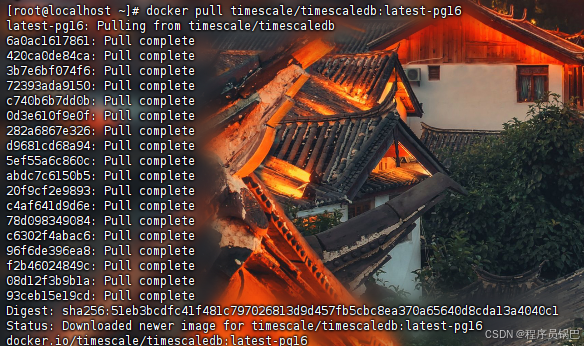
bash
docker run -d \
--name timescaledb \
-p 5432:5432 \
-e POSTGRES_PASSWORD=123456 \
timescale/timescaledb:latest-pg16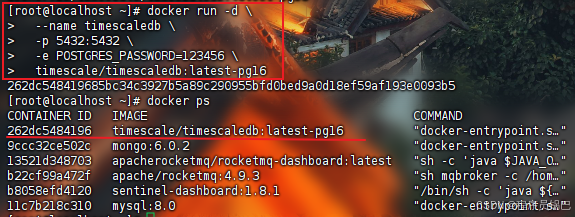
参数大白话解释:
-d:让容器在后台安静地运行。--name timescaledb:给咱们的容器起个好记的名字。-p 5432:5432:将容器的 5432 端口映射到你本地电脑的 5432 端口。-e POSTGRES_PASSWORD=...:设置超级管理员postgres的密码(千万记得修改为你自己的密码)。timescale/timescaledb:latest-pg15:核心所在!直接拉取官方提供的包含 PostgreSQL 15 及其对应 TimescaleDB 插件的最新镜像。
跑完这个命令,你的带有 TimescaleDB 基因的重装甲 PostgreSQL 数据库就已经在后台稳稳运行了!
五、 如何激活 TimescaleDB 插件?
虽然镜像里自带了插件,但出于 PostgreSQL 的规范,我们还需要在具体的数据库里面把它"激活"。
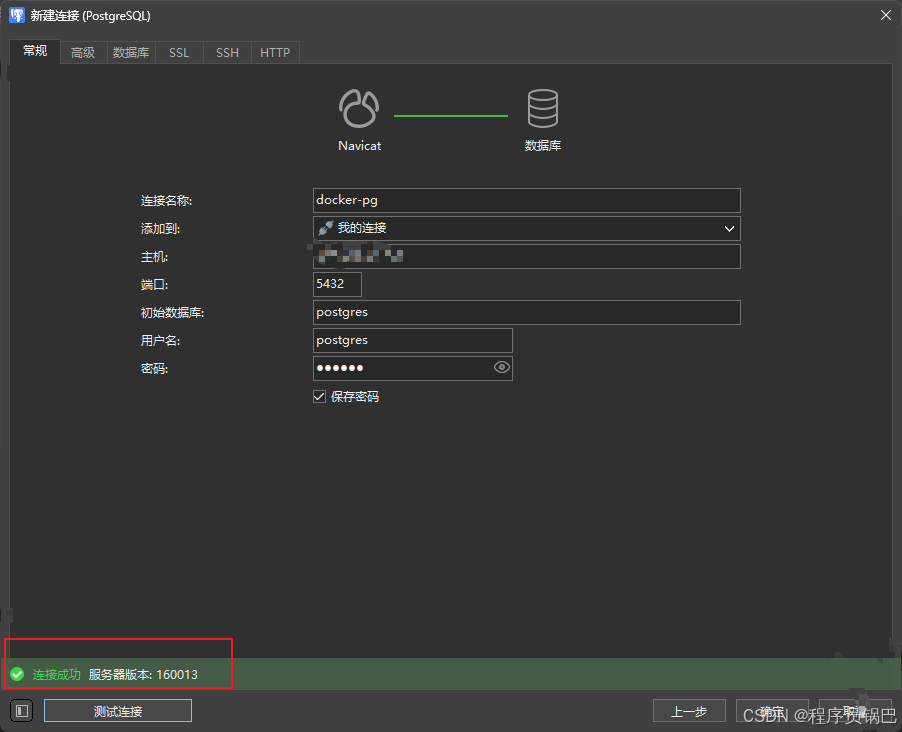
你可以使用任何你习惯的数据库连接工具(如 Navicat、DBeaver、DataGrip 等)连接到 localhost:5432,用户名 postgres,密码为你刚才设置的 123456。
连上之后,打开查询控制台,执行下面这一行 SQL 代码:
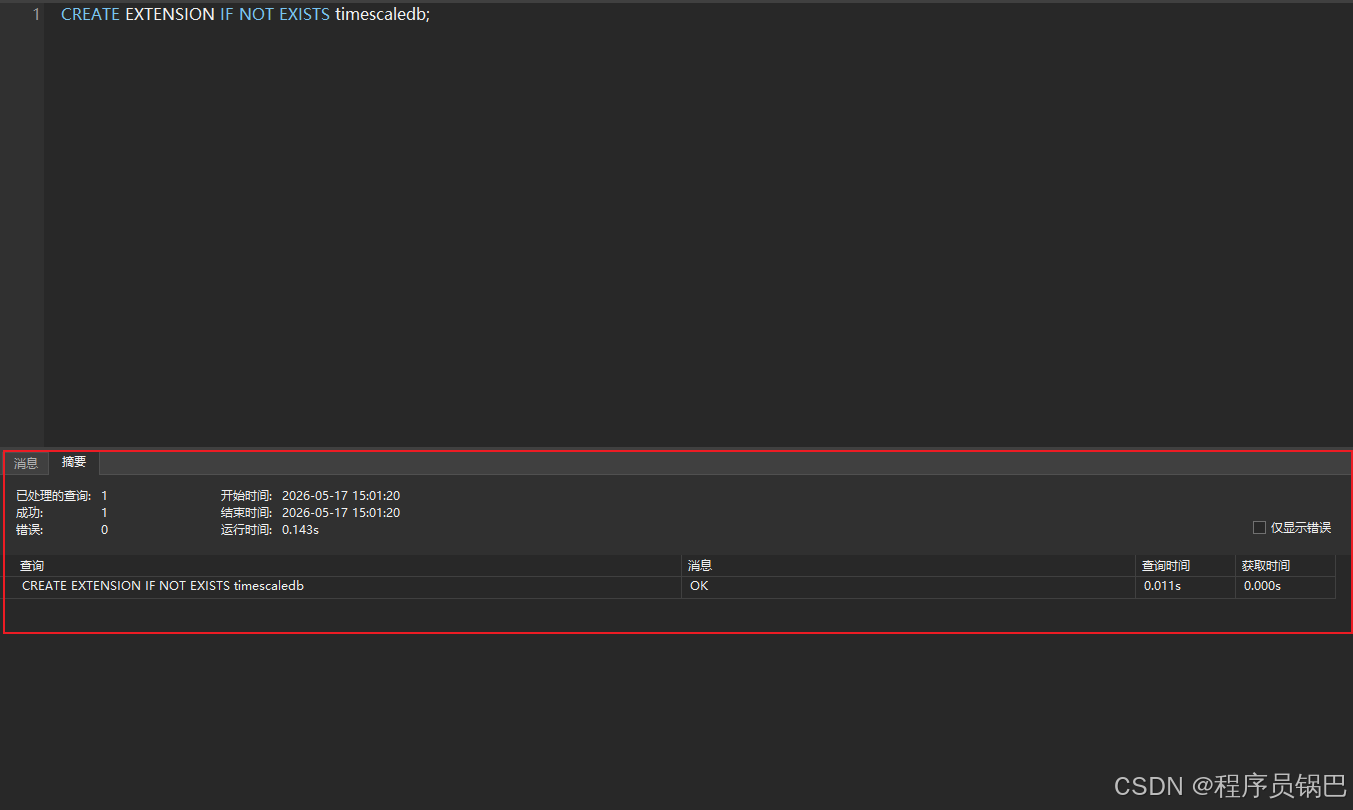
sql
-- 激活 TimescaleDB 核心能力
CREATE EXTENSION IF NOT EXISTS timescaledb;如果提示成功,恭喜你!你的这台普通的 PostgreSQL 已经正式觉醒为时序数据库了。
六、 趁热打铁:简单感受一下时序查询的魅力
光说不练假把式。我们用一个"记录机房服务器 CPU 温度"的场景来演示一下。
第一步:创建一张普通表
起初,它和我们平时建普通数据表没有任何区别:
sql
CREATE TABLE server_metrics (
time TIMESTAMPTZ NOT NULL, -- 必须有时间戳字段
server_id INT NOT NULL, -- 服务器编号
cpu_temp DOUBLE PRECISION -- CPU温度
);第二步:一键变身"超表(Hypertable)"
这是 TimescaleDB 的核心黑科技。我们要告诉数据库:"请帮我把这张表转成按时间自动分区的时序表!"
sql
-- 将普通表转为超表,以 'time' 字段作为时间轴
SELECT create_hypertable('server_metrics', 'time');执行完之后,在你的逻辑代码看来,这还是原来那张表;但在底层,TimescaleDB 已经会根据时间自动帮你把数据分块(Chunk)存放在不同的物理空间了,你根本不需要去配置复杂的表分区。
第三步:插入几条模拟数据
使用正常的 INSERT 语法写入数据,完全没有学习成本:
sql
INSERT INTO server_metrics (time, server_id, cpu_temp) VALUES
(NOW() - INTERVAL '2 hours', 1, 45.5),
(NOW() - INTERVAL '1 hours', 1, 48.2),
(NOW() - INTERVAL '30 minutes', 1, 52.1),
(NOW() - INTERVAL '2 hours', 2, 60.0),
(NOW() - INTERVAL '1 hours', 2, 62.5);第四步:体验逆天的时序降采样查询
假设你的老板让你统计**"过去几小时内,每台服务器每小时的平均温度"**。
如果用 MySQL 写,时间格式化函数能把你绕晕。但在 Timescale 里面,直接调用自带的 time_bucket 函数:
sql
SELECT
time_bucket('1 hour', time) AS bucket, -- 按1小时为"桶"切分时间轴
server_id,
AVG(cpu_temp) AS avg_temp -- 求平均温度
FROM
server_metrics
GROUP BY
bucket, server_id
ORDER BY
bucket DESC;你可以直观地看到,time_bucket 就像一个筛子,精准地帮你把杂乱无章的时间戳按照"1小时"的粒度归拢在一起,再配合 GROUP BY 进行聚合计算。这对前端画 Echarts 折线图简直不要太爽!
结语
简单总结一下,如果你的项目未来会遇到极高频的日志写入或者海量的物联网数据,千万别再拿普通的单表 MySQL 死磕了。PostgreSQL + TimescaleDB 这套组合拳,既能保留传统 SQL 的便利,又能享受时序架构带来的极致性能。最关键的是,官方 Docker 镜像直接打包了全部环境,部署极其傻瓜化。
今天讲的仅仅是冰山一角,TimescaleDB 里面还有类似"持续聚合(Continuous Aggregates)"、"高压数据压缩(Compression)"和"自动化数据保留策略(Data Retention)"等神仙特性。感兴趣的小伙伴赶紧用 Docker 跑一个自己去折腾看看吧!
码字不易,如果你觉得这篇教程对你有帮助,欢迎点赞、收藏、转发!你的支持是我持续输出硬核技术干货的最大动力!我们下期再见!