前言
前一段时间学习redis的主从和哨兵搭建的时候,博主真的是在部署这一块踩了一堆坑,但最终结果是好的,部署成功了。现在,就把完整原理以及生产化部署方式告诉大家,让大家在redis的学习之路上越走越远~
本文的阅前提示
-
可能出现的专业术语介绍:
- fsync:是操作系统的强制落盘指令 ,正常情况下,数据需要先暂存到缓冲区再写入磁盘,fsync可以把数据强制写入磁盘中
- fork:作为操作系统的一个分身术 ,主进程fork后,会复制出一个与自身一模一样的子线程,然后它会把持久化的脏活累活全交给子进程做,主线程安心接收和处理用户的请求
-
本文所有配置均为基于docker容器部署,需要有一定的docker部署基础
一、redis持久化配置
1. RDB持久化
1.1 什么是RDB?
RDB即redis数据备份文件,又叫做redis数据快照。当redis挂掉之后,可以利用该文件快速回复数据
1.2 触发RDB的时机
Redis内部有触发RDB的机制,在redis停机的一刻,会自动保存当前数据的快照,保存到指定文件dump.rdb文件中(ps:该文件可以自己改名,但并不建议,容易导致数据丢失);在redis服务重启的时候,redis又会重新读取rdb文件中的数据
1.3 保存RDB的形式
保存数据时,有两种形式:save和bgsave,其中,save会占用主线程进行rdb保存,bgsave会fork一个新的线程进行保存
1.4 RDB相关配置
- 修改触发rdb的时间与次数:
save x y,即在x秒内有y个键被修改,则执行一次bgsave - 压缩配置:
rdbcompression yes,但是不建议开启,会对磁盘造成一定压力 - rdb的文件名称:
dbfilename xxx.rdb - 文件保存路径:
dir /xxx/xxx(自定义)
1.5 RDB的bgsave的流程
- fork主进程得到一个子进程,共享内存空间
- 利用子进程读取数据从保存到rdb文件中
- 替换旧的rdb文件
1.6 RDB的缺点
- RDB间隔时间长
- 具有数据丢失的风险
2. AOF持久化
2.1 什么是AOF
AOF全称数据追加文件
它不会把数据直接进行保存在文件中,而是会把执行过的命令保存到指定aof文件中,如图:
 当redis重启恢复数据的时候,就会读取aof文件中的命令并依次执行,进而达到恢复数据的目的
当redis重启恢复数据的时候,就会读取aof文件中的命令并依次执行,进而达到恢复数据的目的
2.2 相关命令
开启AOF
需要修改redis.conf配置文件(docker部署的直接创建一个新的conf文件,里面写入这一段即可完成覆盖修改):
bash
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"修改AOF的频率
bash
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
#写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no三种频率的作用:
 但是,由于AOF记录的是大量的指令,而RDB记录的是二进制数据 。同时,在加载方面,RDB中的二进制数据可以一步到位,直接加载到内存中,但是,AOF中的命令却需要一条条来执行,在数据量、操作量总量较大的时候,需要的时间会成倍增加。
但是,由于AOF记录的是大量的指令,而RDB记录的是二进制数据 。同时,在加载方面,RDB中的二进制数据可以一步到位,直接加载到内存中,但是,AOF中的命令却需要一条条来执行,在数据量、操作量总量较大的时候,需要的时间会成倍增加。
为了解决这个问题,AOF提供了一套解决方案:AOF文件重写
2.2 优化方法------自动重写AOF文件
因为AOF是对命令的记录,所以其实在最后一次命令执行前的大量的命令意义并不大,甚至可以说是毫无意义的。Redis会通过执行bgrewriteaof命令,对命令内容进行重写,删减大量无效命令,用最少的命令达到相同的效果 
这个重写的阈值是可以自己去设置的: 
2.3 RDB与AOF的对比
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 对整个内存定时做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次数据备份之间存在数据丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会压缩,文件很小 | 记录命令,文件很大 |
| 宕机恢复速度 | 很快,直接将二进制数据写入内存 | 很慢,需要逐个执行命令 |
| 数据恢复优先级 | 较低,因为数据完整性不如AOF | 高,数据完整性高 |
| 系统资源占用 | 高,会占用大量CPU和内存消耗 | 低,主要是磁盘IO,但是对命令进行重写的时候会占用大量CPU和内存消耗 |
| 使用场景 | 对数据完整性要求不高,追求更高的启动速度 | 对数据完整性要求高的场景 |
二、redis主从搭建及原理
3. redis主从搭建
3.1 搭建redis主从的目的
redis中的写操作较少,但是读操作较多 ,因此,可以把读操作交给从节点进行完成,需要查询数据的时候让主节点将请求转给从节点进行获取,进而提高redis的并发能力。
从节点的数据是通过主节点进行数据同步获得的
主从节点中,主节点可读可写,从节点只允许读,写会报错
3.2 搭建方式
- 使用命令在docker中创建几个redis实例,然后创建一个共享网络,让这些实例共享同一个docker网络。创建redis的方式:
bash
docker run -d --name redis -p 6379:6379 -v redis-data:/data -e REDIS_PASSWORD=xxxxxx --restart=always redis:8.2.1 redis-server --requirepass xxxxxx- 进入其中一个实例容器内部(
docker exec -it redis /bin/bash),使用命令redis-cli进入与redis的交互界面 - 把该实例设置为主节点:
bash
replicaof no one- 其他几个实例采取相同的方式,但是要设置为从节点:
bash
replicaof 主节点ip 主节点port注意:这里的ip是内网ip,千万不要写成宿主机ip了,可以使用docker inspect xxx进行查看
4.主从同步原理
4.1 数据同步原理
通过比对主从两节点的数据集replid和偏移量offset来判断应该使用rdb进行数据全量复制的全量同步 还是使用实时的命令传播机制进行数据追加的增量同步
3个重要概念:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一个数据集,每个master都一个唯一的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
- repl_backlog(复制积压缓冲区): Redis 主节点上的一个固定大小的环形缓冲区,用于暂存主节点执行bgsave命令期间执行的新命令
4.2 主从全量同步原理
即:使用rdb进行数据全量复制的全量同步
主从节点进行数据同步的时候,从节点必须向主节点声明自己的replid和offset,主节点会进行replid的对比:
-
如果replid不一致,说明这是一个新的从节点,主节点会返回它目前的replid和offset给从节点,并进行一次全量数据同步;
-
replid一致的情况下,分两种情况:
- 从节点的 offset 在主节点 repl_backlog 的有效覆盖范围时,会进行增量同步(4.3);
- 从节点的 offset 不在主节点 repl_backlog 的有效覆盖范围时,会进行一次全量同步
图示如下:
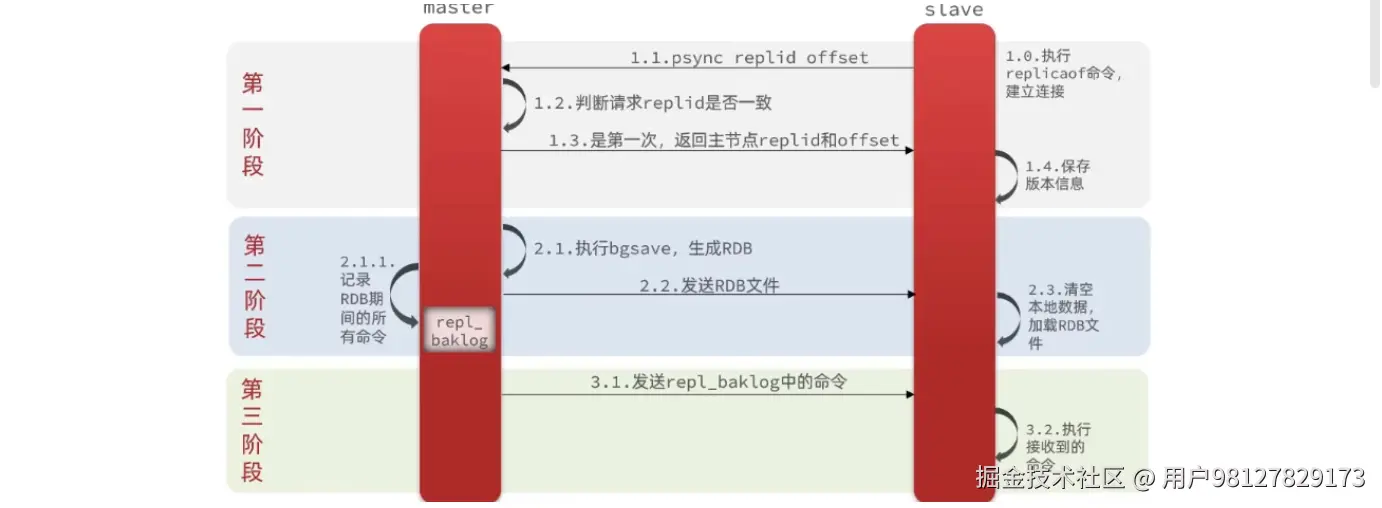 总结:全量同步执行时机为主从第一次建立联系时以及从节点的offset不在主节点的repl_backlog的有效覆盖范围时
总结:全量同步执行时机为主从第一次建立联系时以及从节点的offset不在主节点的repl_backlog的有效覆盖范围时
4.3 主从增量同步原理
即:实时的命令传播机制进行数据追加的增量同步
主要使用到的是repl_backlog
- repl_backlog本质上是一个环形数组 ,slave和master会进行追逐,slave宕机之后,master比slave超出的部分就是master比slave多执行的命令。在slave节点恢复宕机之后,就会执行repl_backlog里面的命令进行增量同步
- 当slave挂机时间过长 ,并且master在此期间执行了大量命令 ,记录量一旦超出了该数组最大容量(转满一圈) ,就会从头开始重新记录,导致之前的命令记录被覆盖,无法进行增量同步
- 当slave检测到命令被覆盖时,就会采用全量同步进行数据恢复
4.4 主从同步优化方法(参数设置以及节点调整)
- 在master中配置
repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。 - redis单节点内存占用不要太大,避免RDB占用大量磁盘IO
- 适量提高repl_backlog的大小,尽可能减少RDB的次数,以增量同步为主,在主节点的conf文件中修改或添加
repl_backlog_size 100mb - 限制一个master上的从节点数量,如果从节点确实是太多了,可以采取主-从-从的形式,让一级从节点变成主节点,管理二级从节点
redis哨兵搭建
5. 哨兵的工作原理
5.1 介绍
哨兵,就相当于是上帝、监控,可以监视主从节点的运行,对不健康的主从节点提供一定的补救措施
5.2 作用
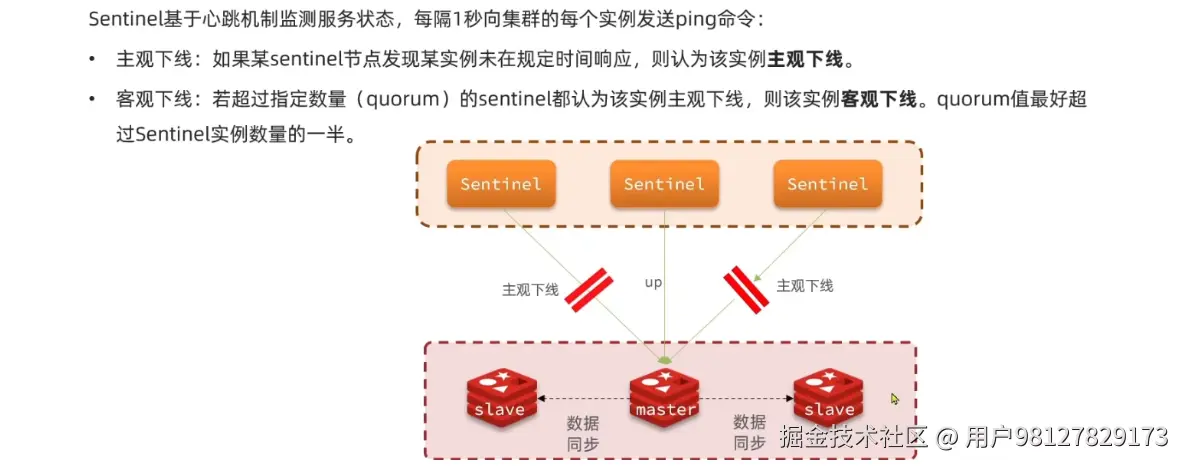
- 监控:会实时监测redis所有的主从节点的健康状态
- 自动故障恢复:在主节点宕机的时候,会马上扶持一个从节点作为新的主节点,即便在旧的主节点恢复好之后,主节点业依然是被那个扶持的从节点
- 通知:当redis集群出现故障时,会马上将故障信息发送给客户端
5.3 心跳机制
 master的选举机制:
master的选举机制:
主节点突然因为某种原因挂了之后,哨兵需要在从节点中重新投票选举出一个新的主节点,这个选举是有规则的:
- 根据slave与master断开时间,超过指定值的将不再拥有被选举权
- 判断slave-privority值,越小越优先,但是为0时不参加
- 优先级一样,则会判断slave的offset,越大说明数据越新,优先度越高
- 如果offset也一样,最后就会判断id大小,哪个小选哪个
6. 哨兵的docker搭建
完整步骤:
- 满足:
- 有一个共享docker网络(
docker network create redis-network) - Redis 主节点:假设容器名
redis-master,端口6379 - Redis 从节点 1:
redis-slave1,端口6380 - Redis 从节点 2:
redis-slave2,端口6381 - 哨兵节点 1:
redis-sentinel1,端口26379 - 哨兵节点 2:
redis-sentinel2,端口26380 - 哨兵节点 3:
redis-sentinel3,端口26381
- 创建哨兵配置文件(以 sentinel1.conf 为例): bash
bash
# 哨兵端口(每个哨兵节点端口不同)
port 26379
# 守护进程模式(Docker 中建议关闭,用容器前台运行)
daemonize no
# 日志文件
logfile "/var/log/redis/sentinel1.log"
# 工作目录
dir /tmp
# 核心配置:监控主节点
# 格式:sentinel monitor <主节点名称> <主节点IP/容器名> <主节点端口> <投票数>
# 说明:mymaster 是主节点别名,redis-master 是主节点容器名(同一网络下可直接用),6379是端口,2表示至少2个哨兵同意才触发故障切换
sentinel monitor mymaster redis-master 6379 2
# 主节点无响应超时时间(毫秒),超过则判定主节点宕机
sentinel down-after-milliseconds mymaster 30000
# 故障切换超时时间
sentinel failover-timeout mymaster 180000
# 每次同步从节点的数量(避免同时同步消耗过多带宽)
sentinel parallel-syncs mymaster 1
# 密码
sentinel auth-pass mymaster 123456
# 禁止保护模式(Docker 环境建议关闭)
protected-mode no其他两个哨兵的配置文件修改port和日志文件目录即可
- 创建数据卷挂载:
bash
# 创建3个哨兵配置数据卷(也可以只创建1个卷,放入3个配置文件)
docker volume create redis-sentinel1-conf
docker volume create redis-sentinel2-conf
docker volume create redis-sentinel3-conf
docker volume create redis-sentinel1-log
docker volume create redis-sentinel2-log
docker volume create redis-sentinel3-log- 复制conf文件到数据卷中:
bash
# 1. 查看哨兵1配置卷的「宿主机实际路径」(复制输出的Mountpoint路径)
docker volume inspect redis-sentinel1-conf | grep Mountpoint
# 2. 把本地sentinel1.conf 复制到 上一步查到的宿主机卷路径(示例路径,替换成你的)
cp /本地/你的/sentinel1.conf /var/lib/docker/volumes/redis-sentinel1-conf/_data/sentinel.conf
# 其余两节点也照做- 启动三个哨兵:
bash
# 启动哨兵1
docker run -d \
--name redis-sentinel1 \
--net redis-network \
--restart always \
-p 26379:26379 \
-v redis-sentinel1-conf:/etc/redis \
-v redis-sentinel1-log:/var/log/redis \
redis:8.2.1 \
redis-sentinel /etc/redis/sentinel.conf
# 启动哨兵2
docker run -d \
--name redis-sentinel2 \
--net redis-network \
--restart always \
-p 26380:26380 \
-v redis-sentinel2-conf:/etc/redis \
-v redis-sentinel2-log:/var/log/redis \
redis:8.2.1 \
redis-sentinel /etc/redis/sentinel.conf
# 启动哨兵3
docker run -d \
--name redis-sentinel3 \
--net redis-network \
--restart always \
-p 26381:26381 \
-v redis-sentinel3-conf:/etc/redis \
-v redis-sentinel3-log:/var/log/redis \
redis:8.2.1 \
redis-sentinel /etc/redis/sentinel.conf- 启动三个主从redis:
bash
# 主节点
docker run -d \
--name redis-master \
--net redis-network \
--restart always \
-p 6379:6379 \
redis:8.2.1 \
redis-server --requirepass 123456 --repl_backlog_size 100mb --protected-mode no
# 从节点1
docker run -d \
--name redis-slave1 \
--net redis-network \
--restart always \
-p 6380:6380 \
redis:8.2.1 \
redis-server --replicaof redis-master 6379 --masterauth 123456 --protected-mode no
# 从节点2
docker run -d \
--name redis-slave2 \
--net redis-network \
--restart always \
-p 6381:6381 \
redis:8.2.1 \
redis-server --replicaof redis-master 6379 --masterauth 123456 --protected-mode no结尾
以上就是redis主从原理及哨兵搭建的主要内容了,如果大家觉得文章有用的话,别忘了点赞 + 收藏 + 关注支持一下博主,下期再见~