大家好,我是码歌,今天聊聊 OpenSpec 规格驱动开发:一套把"要做什么、为什么做、怎么做"先固化成规格,再让 AI 和团队按规格推进的协作方法。
很多团队已经在用 AI 辅助开发,但真正难的不是"写得快",而是"别跑偏"。常见问题包括:
• 需求边界反复变;
• 设计写到一半开始改目标;
• 实现阶段临时加需求;
• 交付后没人能说清这次到底改了什么。
这篇文章会带你看清 OpenSpec 解决的到底是什么、它为什么值得关注、以及怎么按 Explore → Propose → Design → Tasks → Apply → Archive 六阶段把一次变更走完整。
这篇文章你会看到
-
OpenSpec 到底是什么;
-
它为什么能减少返工;
-
值不值得在团队里落地。
背景说明
OpenSpec 适合那些需求会变、协作链路长、又希望 AI 能稳定按规格执行的团队。它不是替你写代码,而是先把协作契约定下来。
核心观点
一句话结论:先对齐规格,再让 AI 和团队一起执行。
OpenSpec 的意义,不是增加流程,而是让 AI、产品、研发、测试都站在同一份规格上说话。
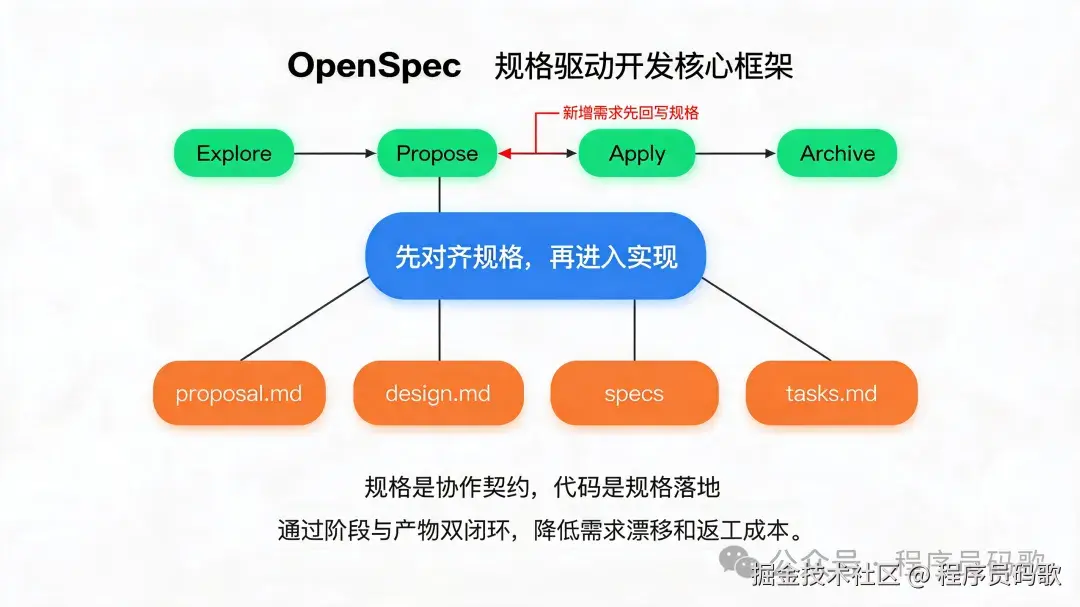
一、概念:OpenSpec 到底在解决什么
OpenSpec 的核心是:先对齐规格,再进入实现。
一次变更通常会产出四类资产:
-
proposal.md:为什么做、要做什么、影响什么。 -
design.md:怎么做、有什么取舍、为什么这么设计。 -
specs/:变化后的行为规格。 -
tasks.md:可执行任务清单。
它们不是孤立文件,而是一个闭环:
Explore → Propose → Design → Tasks → Apply → Archive OpenSpec 的意义,不是增加流程,而是让 AI、产品、研发、测试都站在同一份规格上说话。
二、安装说明:先把环境准备好
OpenSpec 的官方安装前提是 Node.js 20.19.0 或更高版本。先确认环境:
css
node --version openspec --version 安装方式可以按你的包管理器选择:
css
npm install -g @fission-ai/openspec@latest 或者:
sql
pnpm add -g @fission-ai/openspec@latest 安装后,进入项目目录并初始化:
bash
cd your-project openspec init 
这一步的目标很简单:先能跑起来,再谈流程重构。
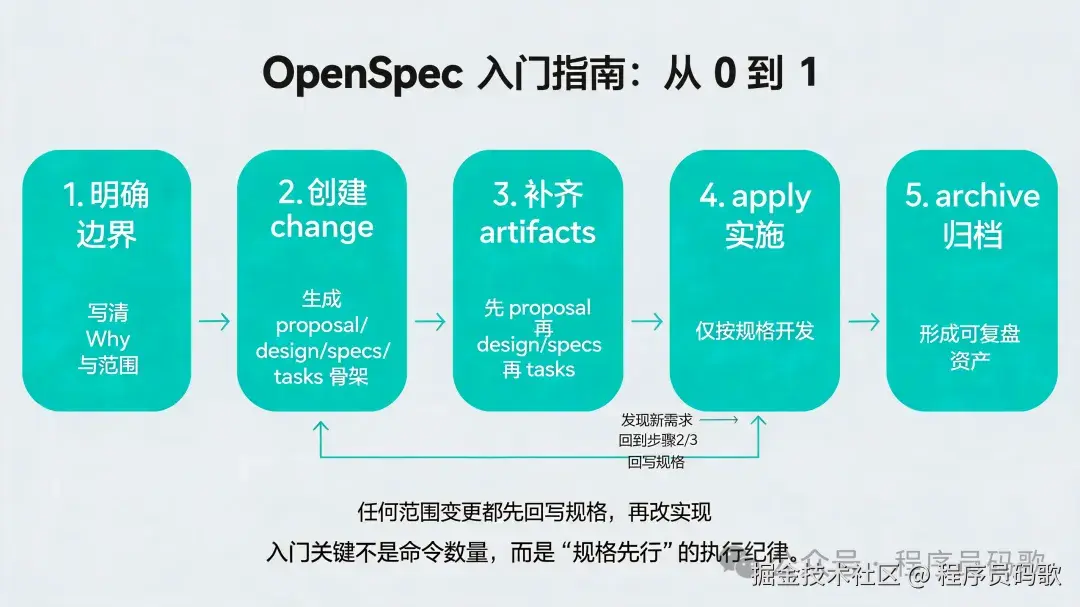
三、入门指南:从 0 到 1 的最短路径
如果你今天就要开始用 OpenSpec,先走最小可行流程。
最短路径
-
用
/opsx:explore把问题说清楚; -
用
/opsx:propose创建变更并产出规划资产; -
用
/opsx:apply按任务推进实现; -
用
/opsx:sync和/opsx:archive收尾。
bash
/opsx:explore → /opsx:propose → /opsx:apply → /opsx:sync → /opsx:archive 什么时候先 Explore
如果你还不确定范围、方案或约束,先探索,不要急着开工。
什么时候直接 Propose
如果需求已经明确,且你知道大致边界,可以直接进入提案。
最小可行实践
团队落地时,先只要求三件事:
-
中等以上需求必须先有 proposal;
-
进入开发前必须有 design 和 tasks;
-
实现阶段禁止口头改需求,变更必须回写规格。
只要这三条执行稳了,协作质量就会明显上一个台阶。
四、工作流程:六阶段闭环怎么跑
1)Explore
输入: 问题背景、初始想法、未确定边界。
关键动作: 澄清目标、识别未知项、收敛范围。
输出: 探索结论、候选方向、是否进入提案的判断。
退出条件: 问题清晰到可以写提案。
2)Propose
输入: Explore 的结论。
关键动作: 写清背景、目标、范围、影响面。
输出: proposal.md。
退出条件: 提案可以评审,也可以被拒绝。
常用命令示例:
bash
/opsx:propose rewrite-openspec-full-process-article /opsx:explore 3)Design
输入: 已确认的 proposal。
关键动作: 解释方案结构、约束、边界和取舍。
输出: design.md。
退出条件: 设计足以指导任务拆解。
4)Tasks
输入: design.md。
关键动作: 拆成可执行任务,并写清依赖顺序。
输出: tasks.md。
退出条件: 任务可逐条执行和验收。
5)Apply
输入: tasks.md。
关键动作: 按任务推进实现,必要时同步修正文档。
输出: 完成后的变更资产。
退出条件: 任务完成,且文档与实现一致。
强约束:
在 Apply 阶段,不允许临时改需求 。
如果发现新需求、范围变化或方向偏差,必须先回写
proposal.md、design.md、tasks.md,再继续实现。
这条规则用于区分三种情况:
• 需求变更:先回写规格;
• 实现偏差:先修正实现,再同步文档;
• 缺陷修复:属于当前实现修正,不应包装成新需求。
常用命令示例:
bash
/opsx:apply rewrite-openspec-full-process-article /opsx:sync rewrite-openspec-full-process-article 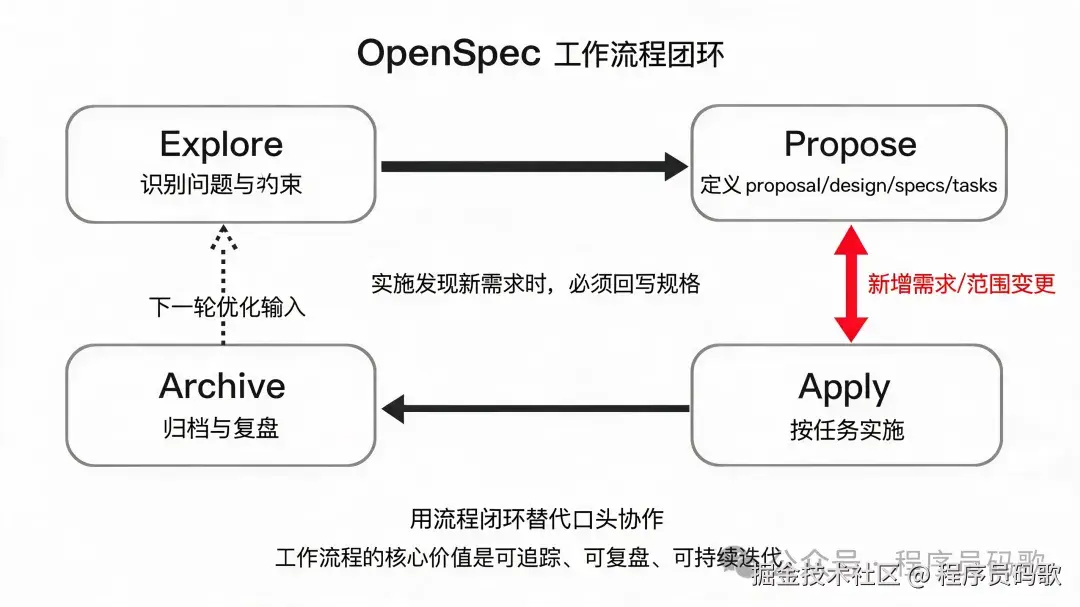
6)Archive
输入: 已完成的变更。
关键动作: 归档、同步规格、保留复盘信息。
输出: 可追溯的归档记录。
退出条件: 变更可查、可回看、可复用。
常用命令示例:
arduino
/opsx:archive rewrite-openspec-full-process-article 五、常用命令:按阶段记忆,不要死记硬背
| 阶段 | 命令 | 作用 |
|---|---|---|
| Explore | /opsx:explore |
澄清问题、探索方案 |
| Propose | /opsx:propose |
创建变更并产出规划资产 |
| Apply | /opsx:apply |
按任务实施变更 |
| Sync | /opsx:sync |
合并 delta specs 到主规格 |
| Archive | /opsx:archive |
归档完成的变更 |
| 扩展工作流 | /opsx:new / /opsx:continue / /opsx:ff / /opsx:verify |
分步或快速生成规划、校验实现 |
命令怎么记
不要先背命令,再找场景。正确顺序是:
-
先判断你在什么阶段;
-
再选对应命令;
-
最后看要不要同步、验证或归档。

六、实战案例分析:为什么规格驱动能少返工
拿"新增文章发布流水线"这个例子来说。
没有规格时
你说"加个发布流程",AI 可能会补出一整套你没要的逻辑:
• 草稿状态怎么流转;
• 谁能审核;
• 审核失败怎么回退;
• 线上发布怎么回滚。
结果就是:
• 你以为在做功能;
• 别人在做猜测;
• 最后大家对齐的不是目标,而是返工。
有规格时
OpenSpec 会先把问题拆成六段:
-
Explore:确认要解决什么;
-
Propose:写清变更意图;
-
Design:决定状态机、数据模型、权限和回滚;
-
Tasks:拆成顺序明确的任务;
-
Apply:按规格实施;
-
Archive:保留复盘结果。
这个例子里最关键的收益
• 需求不会在实现里偷偷变;
• 任务之间有依赖顺序;
• 任何偏差都能回到文档;
• 上线后还能说清楚"这次到底改了什么"。

常见坑位
-
把 OpenSpec 当成"写文档任务";
-
proposal 写得太抽象;
-
design 只写怎么做,不写为什么;
-
tasks 没有依赖关系;
-
上线后不归档。
这些坑,本质上都是同一个问题:规格没有真正成为协作契约。
七、总结:一套可直接复制的落地清单
如果你只想记住最少的事,记这 7 条就够了:
-
先探索,再提案;
-
proposal 说清为什么做、做什么、影响什么;
-
design 说清怎么做和为什么这么做;
-
tasks 要按依赖顺序拆;
-
Apply 阶段不临时改需求;
-
变更完成后先 sync,再 archive;
-
归档不是形式,是团队知识沉淀。

OpenSpec 不是为了增加流程,而是为了减少返工。
它把"模糊需求"变成"可执行规格",把"个人经验"变成"团队资产"。
结论
如果你们团队已经在用 AI 写需求、写设计、写实现,那 OpenSpec 值得尽早引入;如果你们还在靠口头对齐,也可以先从最小变更开始,把这套流程跑起来。
相关链接
• OpenSpec 官方 docs:https://github.com/Fission-AI/OpenSpec/tree/main/docs
我是"程序员码歌 ",全网昵称统一 ,10+年大厂程序员,专注AI工具落地与AI编程实战输出,在职场,玩转副业,目标副业年收入百万,探索可复利、可复制的一人企业成长模式,可去gzh围观