15. 大模型量化是什么?INT8/INT4/AWQ/GPTQ 怎么选?
我理解量化(Quantization)的本质是把模型参数从「高精度浮点数 」(FP32 或 FP16)映射到「低精度整数」(INT8 或 INT4),用更少的比特表示同样的信息。
核心收益是显存和速度。一个 7B 模型 FP16 占 14GB,INT4 量化后只剩 4GB,显存压到 1/3.5;同时 INT4 计算比 FP16 快、访存压力也小,推理速度提升 2-4 倍。
主流量化方案分两个维度。
精度维度:FP16 -> INT8 -> INT4 -> 更激进的 NF4 / FP8 等。位数越少越省,但精度损失越大。INT4 是当前的甜蜜点,效果接近 FP16,体积只有 1/4。
算法维度:
- GPTQ(GPT Quantization):基于「误差补偿」的逐层量化。每量化一层权重,用一小批校准数据测出量化误差,把误差补偿到下一层去。优点是数学严谨、支持 INT3 这种极端精度
- AWQ(Activation-aware Weight Quantization) :基于「激活感知」的权重保护。核心洞见是「不是所有权重都同样重要」,那些和激活值大的输入相关的权重要保护好,其他的可以激进压缩。优点是推理速度快、效果稳
- QLoRA 里的 NF4:NormalFloat 4-bit,专为权重的近高斯分布设计的非均匀量化,配合 LoRA 微调用,让 24GB 消费级显卡能微调 7B 模型
怎么选:
- 部署生产环境、看重推理速度:优先评估 AWQ / GPTQ / FP8 / 框架原生 INT4,具体看 vLLM、SGLang、TensorRT-LLM 当前版本支持哪种 kernel,不能简单说某个框架默认就是 AWQ
- 部署生产环境、追求最高精度:GPTQ INT4 或 FP16
- 个人微调、消费级 GPU:QLoRA NF4
- 极端压缩(边缘设备):INT3 GPTQ 或 GGUF 的 Q4_K_M
实测精度损失要看模型、任务和校准数据。一般经验是:FP16 -> INT8 通常损失很小;INT4 是部署甜蜜点,但数学推理、长代码、长上下文任务可能明显掉点;INT3 / INT2 就要非常谨慎,通常只适合极端压缩或边缘场景。
最关键的认知是,量化算法(GPTQ/AWQ)和文件格式(GGUF/safetensors)是两层东西 。GPTQ 和 AWQ 是「怎么把高精度变低精度」的算法,GGUF 是 llama.cpp 用的「怎么存这些低精度权重」的文件格式。两者经常被混淆,理清这层关系是答好这道题的基本功。
回到开头那段对话,问到大模型量化,最重要的是先把量化的本质讲清楚:把高精度浮点(FP16)映射到低精度整数(INT8/INT4),用更少的比特表示同样的信息,核心机制是「scale + zero_point 的线性映射」。收益是显存压到 1/4、推理快 2-4 倍,这是为什么所有大模型部署几乎都开量化。
接下来讲精度边界。INT8 通常损失很小,INT4 是甜蜜点但要看任务,INT3 开始明显冒险,INT2 一般不推荐。这种「位数越低损失越大但不是线性,而且不同任务敏感度不同」的认知能讲出来,比单纯说「量化会有精度损失」深刻得多。
然后把 GPTQ、AWQ、QLoRA NF4 这三个主流算法的核心思路讲清。GPTQ 是「逐层量化 + 误差补偿」,数学严谨支持极端低位;AWQ 是「激活感知 + 重要权重保护」(1% 关键权重承担 99% 输出贡献),推理速度快;QLoRA NF4 是非均匀量化 + LoRA 微调,让消费级 GPU 能微调大模型。能用一两句话点出每个算法的核心创新,就比纯背名字要强很多。
最关键的是选型经验 :生产部署先看框架和 GPU kernel 支持,再在 AWQ、GPTQ、FP8、INT4 里压测;追求精度选 FP16 / INT8 / FP8;个人微调选 QLoRA NF4;边缘设备选 GGUF。还要特别明确指出 GGUF 是文件格式,不是量化算法,避免和 AWQ/GPTQ 混淆。这一句能讲出来,面试官就知道你真的在工程上做过量化,不是只看过论文。
如果还想再加分,可以提一句量化的常见陷阱(outlier 会破坏精度、KV Cache 量化是研究热点、不同任务的精度敏感度差异巨大、业务上量化前必须自己评测),让面试官知道你不是在背工具,是真的踩过量化的坑。
16. 如何写好 Prompt?分享下 Prompt 工程实践经验?
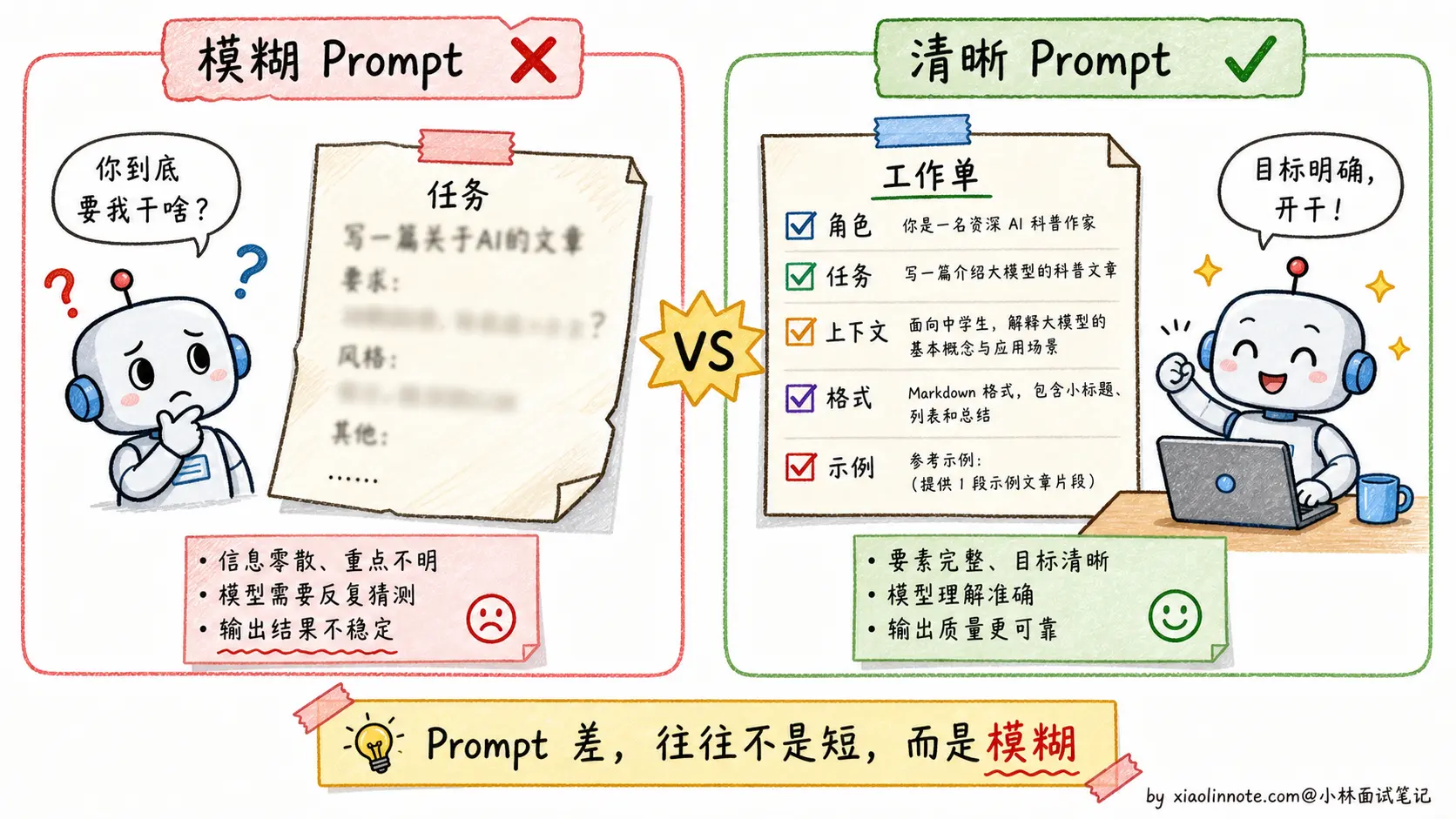
我在实际做项目时踩过不少坑,发现 Prompt 写不好通常不是因为太短,而是因为「模糊」,模型根本不知道你想要什么格式、什么风格、给谁看的。后来总结下来,写好 Prompt 核心就是做好五件事:给模型设定角色、说清楚任务、交代背景上下文、约定输出格式、提供示例。其中格式约束是最容易忽略、但对程序解析影响最大的。而且 Prompt 不是写完就完了,我们项目里一定要建测试集、每次改动都跑一遍,才知道改好了还是改坏了。
为什么 Prompt 的好坏能决定效果的上限
同一个模型,同一个任务,一个好 Prompt 和一个差 Prompt 输出的质量差距可以有一个数量级。这不是夸张,而是在实际项目中反复验证的结论。原因很简单:模型没有读心术,它只能根据你给它的信息来推断你想要什么。你的 Prompt 越模糊,模型的理解空间就越大,输出就越随机。
新手写 Prompt 最常见的三个问题是:指令不清晰(「帮我写一篇文章」vs「写一篇面向高中生的 800 字科普文章,解释黑洞是如何形成的」)、缺少关键上下文(模型不知道你是什么行业、你的用户是谁)、没有格式约束(模型自由发挥格式,导致下游解析出错)。这三类问题对应的是 Prompt 设计中最重要的五个要素,逐一来看。
五要素拆解
Role(角色设定) 是告诉模型「你是谁」。设定角色能让模型在回答时采用对应的知识框架和表达风格。角色越具体,模型的「人设」越稳定,输出的专业程度也越高。
第一版只告诉模型它是「助手」,什么背景都没有,模型只能泛泛而谈。第二版明确了专业方向(Python 后端)、经验年限(10 年)、关注点(性能 + 安全),模型输出的深度和针对性会有明显提升。
Task(任务描述) 是告诉模型「做什么」。关键是用清晰的动词,把任务边界说明白,避免歧义。复杂任务要拆成子步骤,不要让模型一步做完所有事。
「帮我写一篇文章」给了模型太多自由度:写什么风格?多长?给谁看?没有约束,结果就是模型自由发挥,很可能不是你想要的。好的写法把受众、字数、主题、风格、结构都点清楚了。
Context(背景信息) 是告诉模型「你需要知道的前提」。模型不了解你的业务场景,你需要把关键背景主动塞进 Prompt。有了正确的上下文,模型的表达方式会完全不同。
第一版没有交代任何背景,模型不知道这段话是什么用途,翻译出来可能是很日常的英文。第二版告诉了模型受众(海外投资者)、用途(商业计划书)和具体要求,输出质量会有本质区别。
Format(输出格式) 是告诉模型「以什么形式输出」。这是很多人忽略但最影响实用性的要素,尤其是当输出要被程序解析的时候。
没有格式约束时,模型会自由发挥,可能输出一大段叙述性文字,程序根本没法解析。加上 JSON 约束之后,输出结构固定,下游处理就变得可靠。
Examples(示例) 是 Few-shot 学习,也是提升效果最明显的技巧之一。与其花很多时间描述你想要什么风格,不如直接给 1-3 个输入/输出的例子,模型会自动对齐你的期望。
对于格式复杂或风格特殊的任务,Few-shot 几乎是必备的。比如你想让模型生成特定格式的 SQL 注释,与其描述「注释要包含哪些字段、用什么符号分隔」,不如直接给一个范例,模型看懂范例比看懂一大段描述要快得多,也准确得多。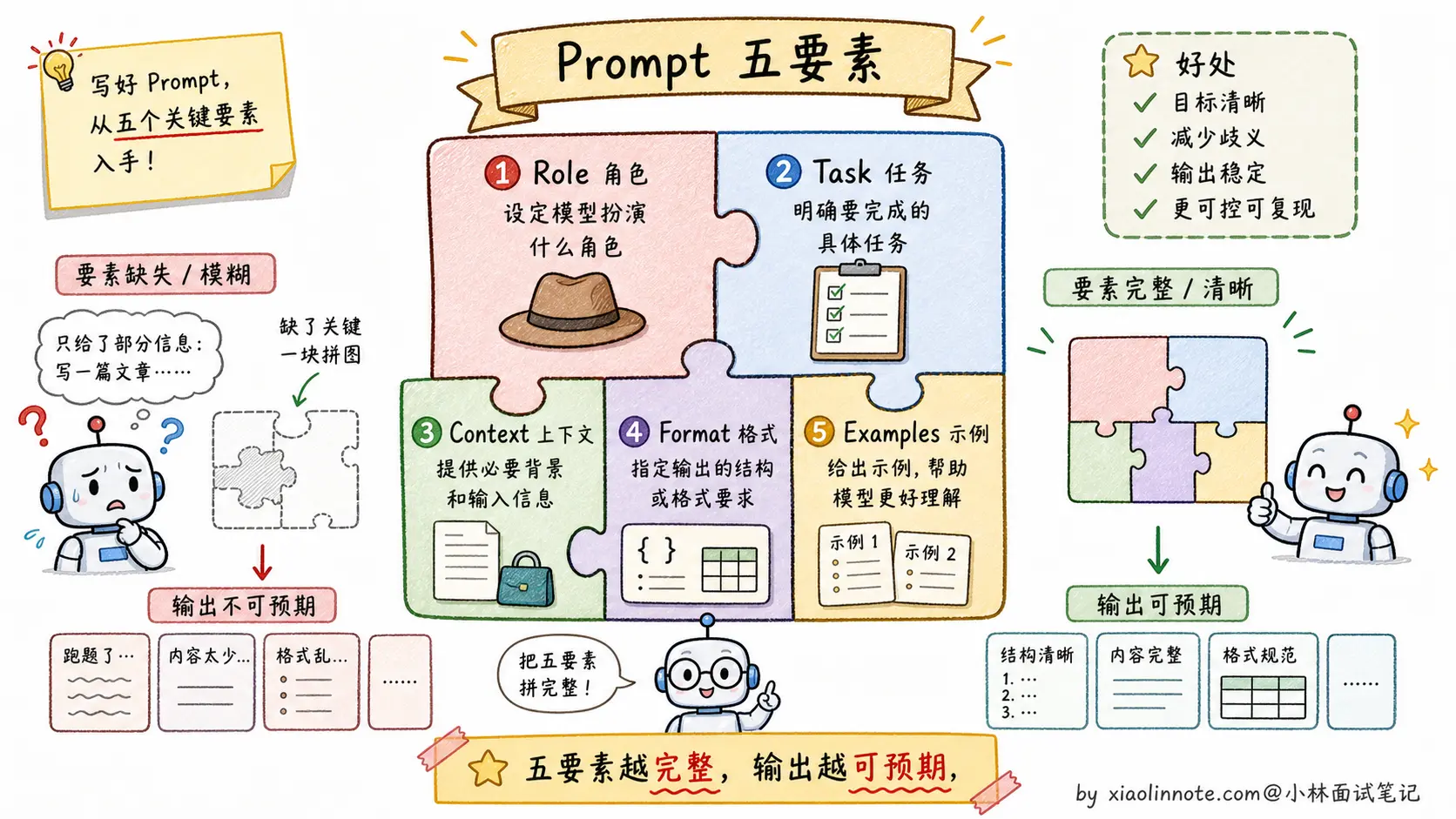
这一版把五个要素都补全了:角色(技术内容编辑)、任务(摘要提炼)、背景(后端工程师受众)、格式(三段式固定结构)、长度约束(100-150 字)。交给不同模型、在不同时间执行,输出格式和质量都会高度稳定。这就是好 Prompt 的核心价值,可预期、可复用、可迭代 。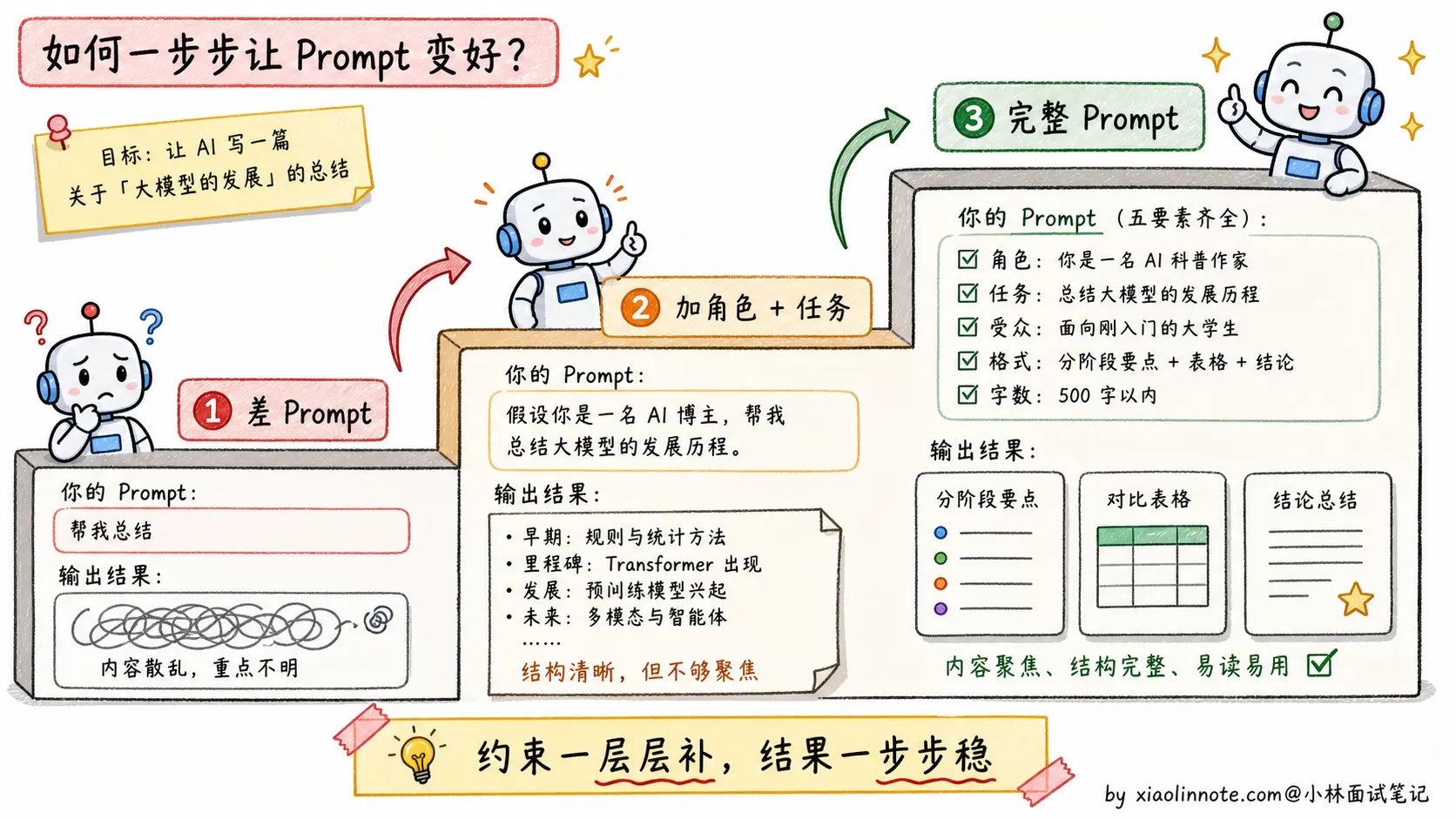
为什么 Prompt 的好坏能决定效果的上限
掌握了五要素之后,还有几个进阶技巧能进一步提升 Prompt 的可靠性和推理质量。
CoT 触发词 是让模型先组织推理再回答的简单方式。在 Prompt 末尾加上「请先分步分析,再给出结论」这类指令,往往能提升涉及逻辑推理和计算的任务准确率。
不过 2026 年的工程实践里,不建议默认把完整推理链原样展示给最终用户。一方面会多花 token,另一方面完整思考链里可能有不稳定或不该暴露的内容。更稳的做法是:让模型内部先分析,最终只输出简洁的依据、关键步骤或可核查的结论。
XML 标签包裹内容 是 Claude 特别推荐的做法。当 Prompt 中包含多个部分时,用 XML 标签明确区分,模型理解起来更准确。
先思考后回答 的结构对需要多步推理的任务效果很好。内部链路里可以让模型先分析,再把最终答案单独放出来;对外展示时,建议输出「简要理由」或「检查清单」,而不是完整的 hidden reasoning。掌握了这些结构技巧,还有一件事同样重要:Prompt 不是写完就完,需要持续迭代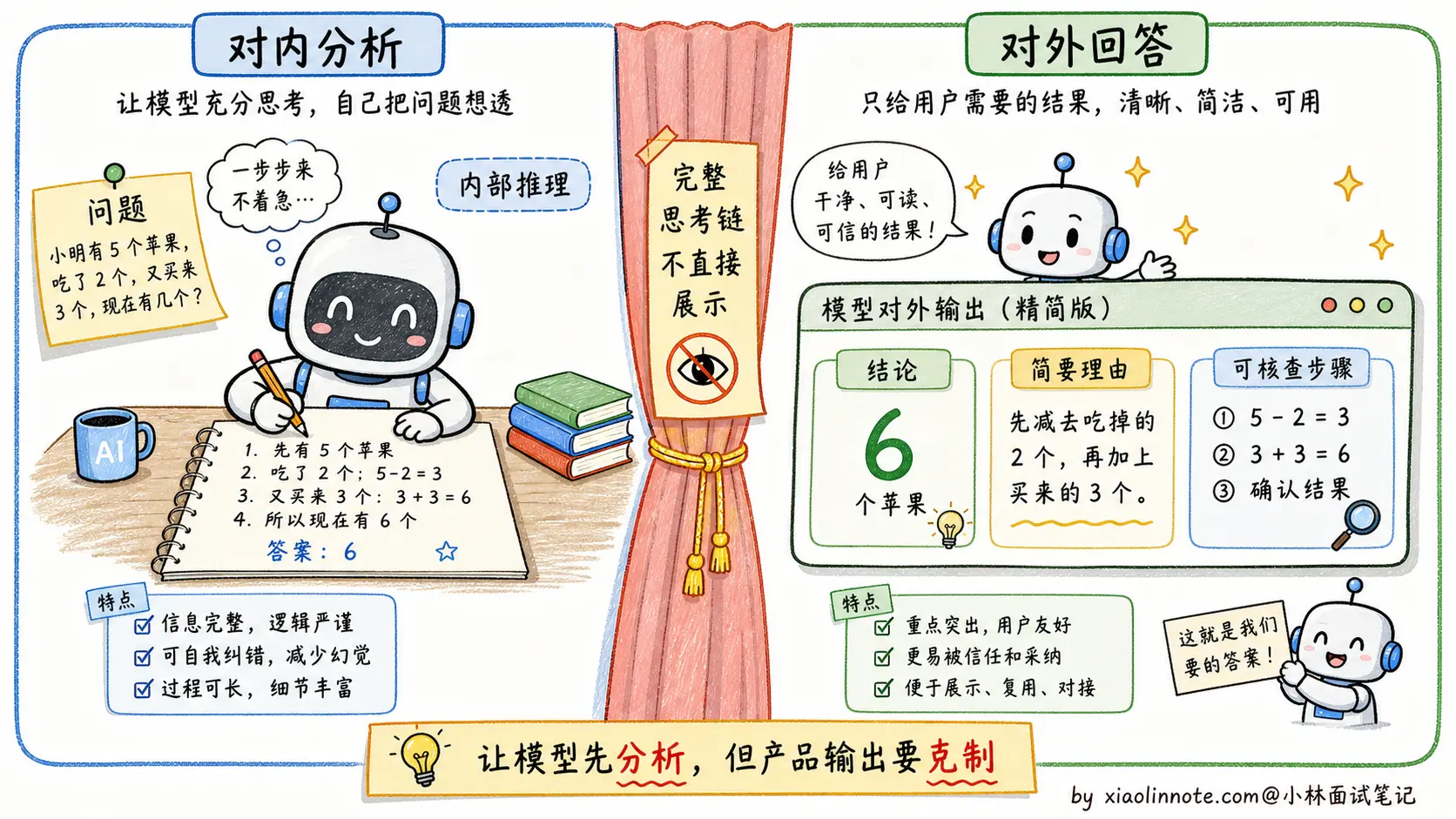
迭代方法论
Prompt 工程本质上是一个「提出假设 -> 测试 -> 优化」的循环,不是一次写完就完事的。
实践中我们的做法是:先整理 30-50 条有代表性的测试用例,覆盖正常情况和边缘情况;每次改 Prompt,在整个测试集上跑一遍,看通过率的变化;如果改动让某些用例变好了但另一些变差了,就继续拆分,针对不同类型的输入写不同的 Prompt 分支。
改 Prompt 要遵循「每次只改一处」的原则,这样才能判断是哪个改动起了作用,避免互相干扰。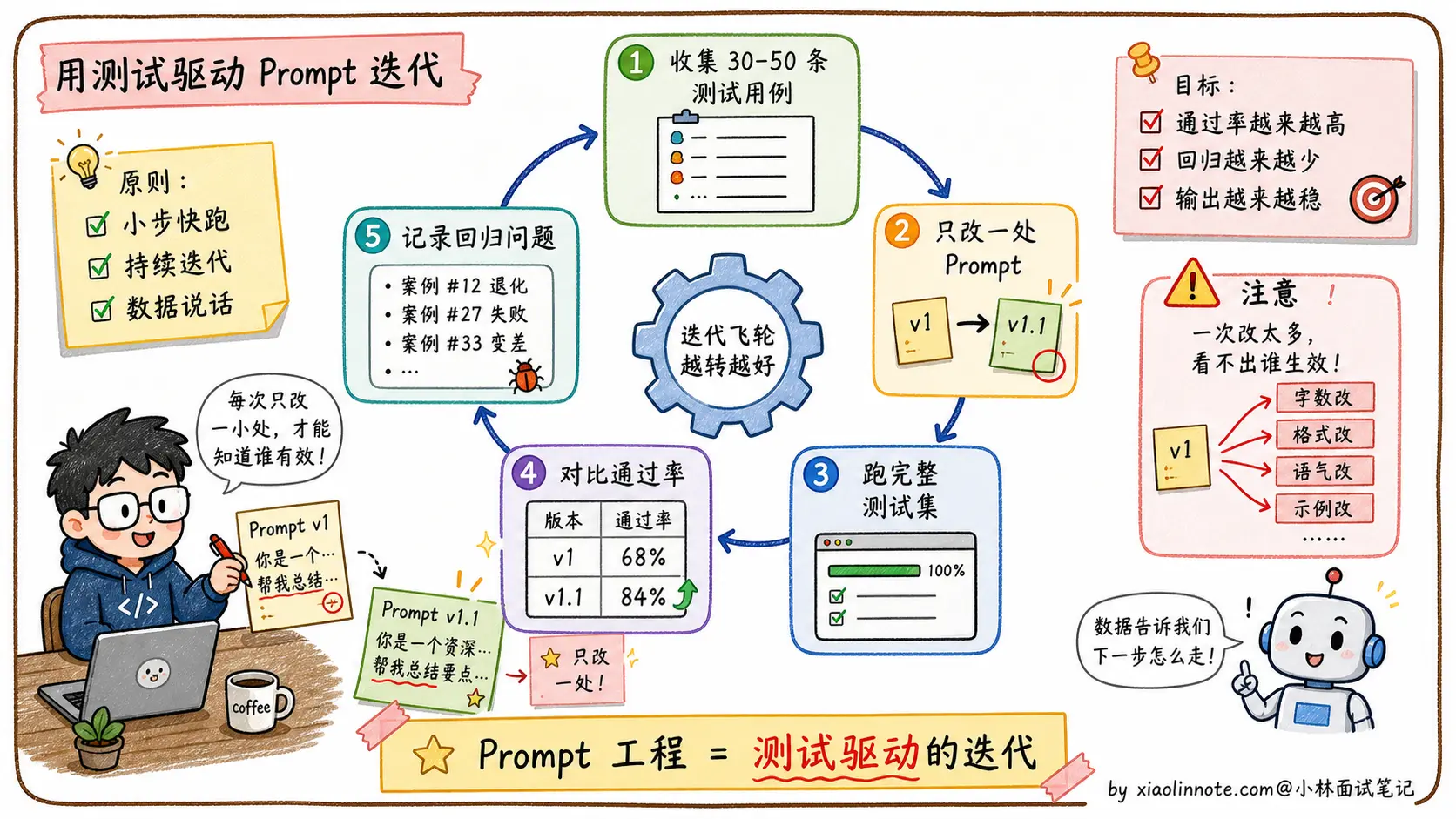
进阶:Prompt 压缩
写好 Prompt 之后,还有一个工程优化点容易被忽略:Prompt 压缩。
为什么需要压缩 Prompt?两个原因。第一,长 Prompt 贵,token 费用直接和长度成正比。第二,长 Prompt 慢,每多 1000 token,首 token 延迟可能多几十 ms,影响用户体验。
但你写好的 Prompt 里其实有大量「冗余信息」。比如「请你认真仔细地一步一步分析这个问题」其实可以压成「认真分步分析」;20 个 Few-shot 示例里很多重复的模式可以挑代表性的几个就够;System Prompt 里反复强调「不要做 X」的句子也是浪费 token。
主流的 Prompt 压缩方案有两类:
1. LLMLingua(微软提出)
用一个小模型(比如 LLaMA 7B)评估 Prompt 中每个 token 的「信息含量」,删掉信息量低的 token。原 Prompt 5000 token 压到 1000 token,效果损失只有 1-3%。这是当前最主流的工程方案,HuggingFace 上有现成的实现。
2. Embedding 表示
把整段 Prompt(特别是 Few-shot 部分)编码成一个固定长度的 embedding 向量,让模型直接读 embedding 而不是 token 序列。这种方案需要模型支持「软 Prompt」(Soft Prompt)输入,目前还在研究阶段,没普及。
实际工程里 Prompt 压缩适合两类场景。一类是长上下文 RAG ,检索到的文档内容很长,压一压能省大量 token 成本。另一类是大量 Few-shot 示例,示例池有 50+ 个时,压缩对延迟改善特别明显。
需要注意的是,压缩对效果有损失 。压得越狠损失越大,工程上要在「省钱省时间」和「效果衰减」之间找平衡点。建议在自己的测试集上评测,找到「压到多少 token 效果还能接受」的甜蜜点。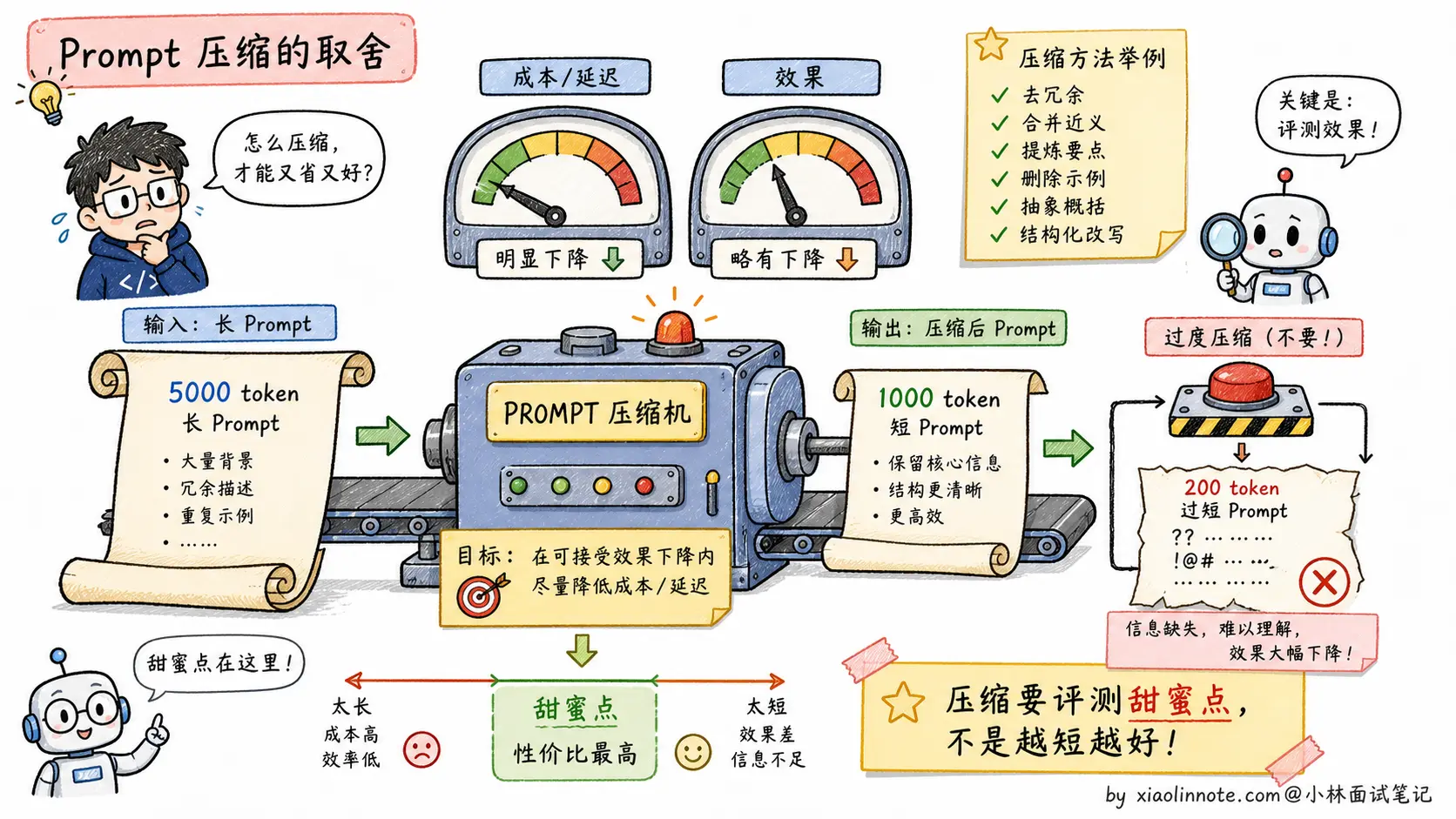
回到开头那段对话,问到怎么写好 Prompt,最重要的是先把新手最容易踩的雷 讲出来:Prompt 写不好通常不是因为太短,而是因为「模糊」,没说清楚角色、任务、上下文、格式、示例。这一句先点出来,面试官就知道你抓到了核心问题。
接下来讲五要素拆解:Role(角色设定,让模型有专业人设)、Task(任务描述,用清晰动词把任务边界说明白)、Context(背景信息,把业务场景塞给模型)、Format(输出格式,特别是要程序解析的场景必须强约束)、Examples(Few-shot 示例,比纯文字描述效果好得多)。能把这五要素逐个讲清楚 + 给具体例子,比单纯说「Prompt 要写清楚」深刻得多。
然后讲进阶技巧:CoT 触发词能帮助模型先组织推理,但最终用户侧最好只展示简要依据;XML 标签包裹内容(特别是 Claude 推荐)让模型理解结构更准;「先分析后回答」的结构对多步推理有效。这些技巧能在面试里点一两个出来,会让面试官觉得你真的写过项目级 Prompt。
最关键的是讲Prompt 是工程问题,不是一次写完就完事的。要建测试集(30-50 条覆盖正常和边缘情况)、每次改动都跑一遍看通过率、遵循「每次只改一处」原则避免多变量干扰。这种工程化视角是面试拉差距的地方。
如果还想再加分,可以提一句 Prompt 压缩(LLMLingua 用小模型评估 token 重要性删冗余、Embedding 表示压缩 Few-shot)作为长 Prompt 场景的进阶优化,让面试官知道你跟得上 Prompt 工程的最新实践。能讲到这一层,已经是面试里很难追问的水平了。