总有业务部门的人过来说:"系统又卡了,打开一个页面要10秒。"
每次看了监控大盘------所有指标绿色。服务器CPU 30%,内存60%,磁盘IO正常。网络监控显示各节点在线,带宽利用率40%。没有任何告警。
ping了一下业务系统的服务器,通的。延迟5ms,看起来完全正常。
但用户确实在卡。
这就是运维最头疼的一类故障------灰色故障(Grey Failure):系统没有完全挂掉,监控没有报警,但业务确实受影响。
一、什么是灰色故障
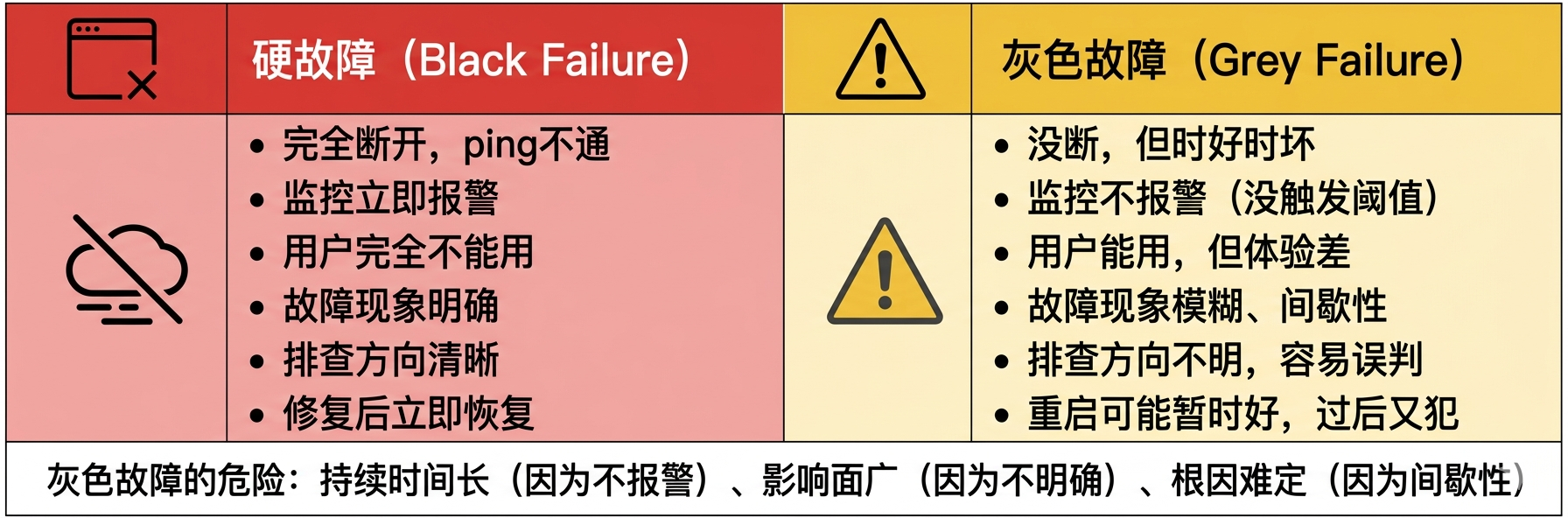
先区分两种故障:
| 维度 | 硬故障 | 灰色故障 |
|---|---|---|
| 网络状态 | 完全断开 | 没断,但不稳定 |
| 监控表现 | 立即报警 | 不报警(没触发阈值) |
| 用户感知 | 完全不能用 | 能用,但卡/慢/偶尔出错 |
| 持续时间 | 通常较短(因为被发现快) | 通常较长(因为不容易被发现) |
| 排查难度 | 方向明确 | 方向不明,容易误判 |
| 典型表现 | 设备宕机、线缆断裂、端口down | 丢包2-5%、DNS偶尔超时、TCP重传、延迟抖动 |
灰色故障的危险不在于严重程度,在于持续时间。 因为监控不报警,IT可能一两天都不知道有问题。用户觉得"就是网不太好",忍一忍也能用,但工作效率实际下降了30-50%。
我在中小企业IT运维中遇到的灰色故障,最常见的5种根因:
- 链路质量劣化:光纤老化、连接器脏、网线接口氧化------丢包1-5%
- DNS间歇性超时:DNS服务器偶尔响应慢或不响应------页面加载慢
- TCP重传风暴:链路质量差导致大量重传------吞吐量骤降
- 端口协商异常:千兆口被协商成百兆或半双工------带宽降90%
- MTU不匹配:VPN/隧道环境下MTU设置不当------大包丢失
二、灰色故障为什么难排
难点一:故障不持续。 你去查的时候可能正好是"好"的时段。用户说卡,你ping一下通了、traceroute没丢包,然后告诉用户"我这边正常"。过一会用户又来说卡。
难点二:监控阈值设太宽。 大部分监控的丢包告警阈值设的是5%甚至10%。但实际上,对于Web应用来说,丢包2%就会导致明显的页面加载变慢(TCP每丢一个包就要重传,延迟翻倍增长)。
难点三:多因素叠加。 单独一个问题可能不严重------丢包1%、DNS偶尔慢200ms、MTU导致偶尔大包失败。但三个问题叠在一起,用户体验就是"系统很卡"。逐个排查时每个都"不严重",但组合起来就过了体验阈值。
难点四:2个人的IT团队没有时间持续抓包。 灰色故障需要长时间监控才能捕捉到异常瞬间。但你不可能盯着tcpdump看一下午------还有其他工作要做。
应对思路:用脚本持续采集,事后分析
灰色故障排查的核心思路不是"实时盯",而是后台持续采集数据,等故障复现时去分析那个时间段的数据。
bash
#!/bin/bash
# 灰色故障持续探测脚本(后台运行,每30秒采集一次)
# 用法:nohup bash grey_fault_probe.sh &
TARGET="192.168.1.1" # 被测目标IP
LOG_FILE="/var/log/grey_fault_probe.log"
INTERVAL=30 # 采集间隔(秒)
while true; do
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
# 1. Ping检测(连续10包,统计丢包和延迟)
PING_RESULT=$(ping -c 10 -W 3 $TARGET 2>/dev/null | tail -2)
LOSS=$(echo "$PING_RESULT" | grep -oP '\d+(?=% packet loss)')
RTT=$(echo "$PING_RESULT" | grep -oP 'avg.*?(\d+\.\d+)' | grep -oP '\d+\.\d+' | head -1)
# 2. DNS检测(解析关键域名)
DNS_TIME=$(dig @8.8.8.8 your-business-domain.com +stats 2>/dev/null | grep "Query time" | awk '{print $4}')
# 3. TCP连接检测(连接业务端口,测量响应时间)
TCP_TIME=$(echo | timeout 5 bash -c "time (echo > /dev/tcp/$TARGET/443) 2>&1" 2>&1 | grep real | awk '{print $2}')
# 4. 记录结果
echo "$TIMESTAMP | loss=${LOSS}% | rtt=${RTT}ms | dns=${DNS_TIME}ms | tcp=$TCP_TIME" >> $LOG_FILE
# 5. 异常标记(丢包>1% 或 延迟>50ms 或 DNS>200ms)
if [ "${LOSS:-0}" -gt 1 ] || [ "${RTT%.*}" -gt 50 ] 2>/dev/null || [ "${DNS_TIME:-0}" -gt 200 ]; then
echo "$TIMESTAMP | ⚠️ ANOMALY | loss=${LOSS}% rtt=${RTT}ms dns=${DNS_TIME}ms" >> "${LOG_FILE}.alert"
fi
sleep $INTERVAL
done跑上一两天,等用户再报"系统卡"的时候,对照时间戳看日志------那个时段的数据就是证据。
三、灰色故障排查决策树
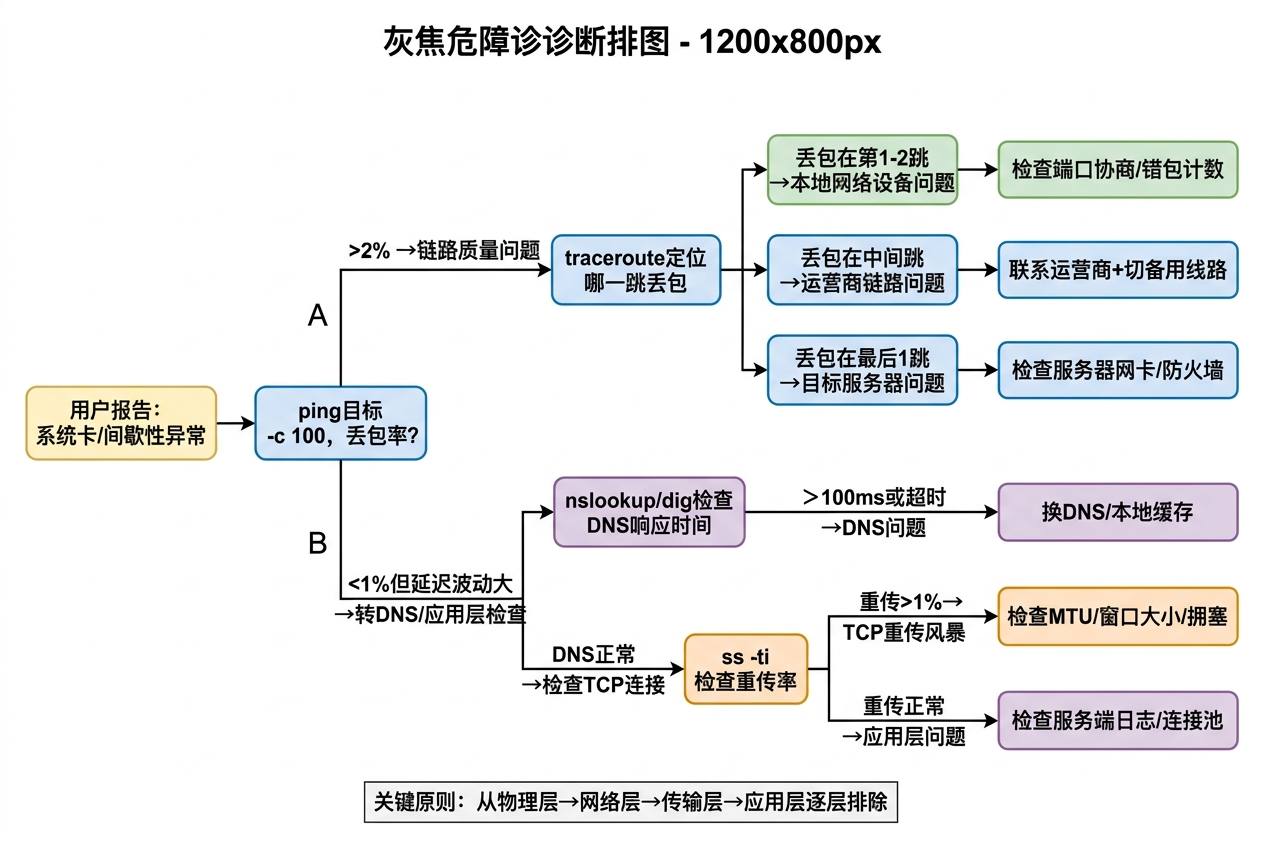
拿到用户报障后,按这个顺序逐层排查:
第一步:确认是网络问题还是应用问题
bash
# 快速判断:同时ping目标服务器 + curl业务接口
# 如果ping正常但curl慢 → 应用层问题
# 如果ping也有问题 → 网络层问题
# 连续ping 100包,看丢包和延迟波动
ping -c 100 -i 0.2 <目标IP> | tee /tmp/ping_result.txt
# 统计结果
echo "=== Ping统计 ==="
tail -3 /tmp/ping_result.txt
# 同时测HTTP响应时间
curl -o /dev/null -s -w "DNS: %{time_namelookup}s\nTCP: %{time_connect}s\nTTFB: %{time_starttransfer}s\nTotal: %{time_total}s\n" https://your-business-url.com判断标准:
- ping丢包>1% 或 延迟波动>20ms → 网络层有问题,继续往下
- ping完全正常,但curl的TTFB>2s → 应用/数据库层面,不在本文范围
- curl的DNS时间>200ms → DNS问题,跳到第四步
第二步:定位丢包发生在哪一跳
bash
# 用mtr代替traceroute(mtr = traceroute + ping的组合,持续探测)
# 运行60秒,看每一跳的丢包率
mtr -r -c 60 <目标IP>
# 输出示例:
# Loss% Snt Last Avg Best Wrst
# 1. 192.168.1.1 (网关) 0.0% 60 1.2 1.5 0.8 3.1
# 2. 10.0.0.1 (运营商) 0.0% 60 5.3 5.8 4.1 8.2
# 3. 218.x.x.x (骨干网) 3.3% 60 12.1 15.3 8.2 45.6 ← 这一跳开始丢包
# 4. 116.x.x.x (目标段) 3.3% 60 14.2 16.8 10.1 52.3
# 关键看法:
# - 如果丢包从第1跳就开始 → 本地网络设备/线缆问题
# - 如果丢包从中间某跳开始且之后所有跳都丢 → 那个节点有问题
# - 如果只有中间某一跳丢包但最终目标不丢 → 可能是ICMP限速,不是真丢包根据丢包位置判断:
| 丢包位置 | 最可能原因 | 下一步动作 |
|---|---|---|
| 第1跳(本地网关) | 本地交换机/路由器端口问题 | 检查端口错包计数、协商状态 |
| 第2-3跳(接入段) | 运营商接入线路质量差 | 联系运营商报修 |
| 中间跳(骨干网) | 运营商骨干拥塞 | 联系运营商或切备线 |
| 最后1跳(目标) | 目标服务器/防火墙 | 检查对端网卡、防火墙连接数 |
第三步:检查本地网络设备
如果丢包在第1跳,大概率是本地设备问题:
bash
# 登录交换机查看端口状态(以华为交换机为例)
display interface GigabitEthernet 0/0/1
# 重点关注这几个计数器:
# Input errors: → 入方向错包数(CRC错误、帧校验错误)
# Output errors: → 出方向错包数
# CRC: → CRC校验错误(通常=网线/光模块问题)
# Collisions: → 冲突(通常=半双工协商问题)
# Input rate: → 入流量
# Output rate: → 出流量
# 如果CRC错误持续增长 → 网线或光模块有问题,换线/换模块
# 如果看到半双工 → 端口协商异常,手动配置全双工+速率端口协商异常是灰色故障的高频原因。 一个千兆口如果被协商成了100M半双工,带宽直接降90%,而且半双工下高负载必然冲突丢包。但监控只看端口up/down,不看协商结果------所以不会报警。
bash
# 修复端口协商问题(华为交换机)
interface GigabitEthernet 0/0/1
undo negotiation auto
speed 1000
duplex full
# Cisco交换机
interface GigabitEthernet0/1
speed 1000
duplex full第四步:检查DNS
很多"系统卡"的真正原因是DNS解析慢。用户感受到的"打开页面慢",可能是DNS查询花了2-3秒。
bash
# 检查DNS解析时间
dig your-business-domain.com | grep "Query time"
# 正常应该<50ms,超过200ms就有问题
# 连续测试10次,看是否有间歇性超时
for i in {1..10}; do
echo -n "第${i}次: "
dig your-business-domain.com +stats 2>/dev/null | grep "Query time"
sleep 1
done
# 如果有个别查询超过1000ms或超时:
# 1. DNS服务器可能过载或不稳定
# 2. 解决方案:配置多个DNS + 本地DNS缓存
# 部署本地DNS缓存(dnsmasq,Ubuntu/CentOS通用)
apt install dnsmasq # 或 yum install dnsmasq
# /etc/dnsmasq.conf 关键配置
cat >> /etc/dnsmasq.conf << 'EOF'
# 上游DNS(配置2-3个,一个挂了自动切)
server=223.5.5.5
server=119.29.29.29
server=8.8.8.8
# 缓存大小(条目数)
cache-size=10000
# 否定缓存TTL(查不到的域名缓存时间,防止反复查询不存在的域名)
neg-ttl=60
EOF
# 重启后本地DNS查询走缓存,响应时间<1ms
systemctl restart dnsmasq第五步:检查TCP重传
丢包1-2%看起来不严重,但对TCP影响巨大。TCP每丢一个包,需要等待RTO超时后重传,延迟指数级增长。
bash
# 查看系统TCP重传统计
ss -ti dst <目标IP> | grep -i retrans
# 或查看全局TCP重传计数
netstat -s | grep -i retrans
# 输出示例:
# 12543 segments retransmitted ← 过去一段时间的重传总数
# 834 fast retransmits ← 快速重传次数
# 持续监控重传率(每5秒输出一次)
watch -n 5 'netstat -s | grep retrans'
# 如果重传数在快速增长,说明链路确实在丢包
# 结合mtr结果定位丢包位置后修复链路
# 查看具体连接的重传情况
ss -ti | grep -A2 "retrans"
# 输出中关注:
# retrans:0/3 ← 当前重传0次/历史重传3次
# rto:204 ← 重传超时时间(ms)
# 如果rto很大(>1000ms),说明连接经历过严重丢包第六步:检查MTU问题
特别常见于VPN/IPSEC隧道环境。MTU设置不当会导致大包被丢弃,而小包(如ping)完全正常。用户体验就是"ping通但传文件卡"。
bash
# 测试路径MTU(逐步增大包大小,找到不通的临界值)
# -M do = 不允许分片(设置DF位)
# -s = 数据大小(加上28字节ICMP头 = 实际包大小)
ping -M do -s 1472 <目标IP> # 1472+28=1500(标准MTU)
# 如果不通 → MTU小于1500
ping -M do -s 1400 <目标IP> # 尝试更小的值
# 如果通了 → MTU在1400-1500之间
# 二分法逐步缩小范围,找到最大可通过值
ping -M do -s 1450 <目标IP>
ping -M do -s 1430 <目标IP>
# ...直到找到刚好能通过的最大值
# VPN环境常见MTU值:
# IPSEC隧道:1400-1420
# GRE隧道:1476
# PPPoE:1492
# 标准以太网:1500
# 修复方案1:在服务器端调小MTU
ip link set eth0 mtu 1400
# 修复方案2:在路由器/防火墙上做MSS Clamping
# 比调MTU更好,不影响局域网内通信
# Cisco路由器:
interface GigabitEthernet0/1
ip tcp adjust-mss 1360
# Linux iptables:
iptables -t mangle -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1360四、5种灰色故障的快速对照表
| 症状 | 最可能原因 | 验证命令 | 修复方案 |
|---|---|---|---|
| ping偶尔丢1-3包 | 链路质量劣化(线缆/光模块) | mtr -r -c 100; 交换机show errors | 换网线/光模块/清洁接头 |
| 页面打开慢但ping正常 | DNS间歇性超时 | dig连续10次看耗时 | 加本地DNS缓存(dnsmasq) |
| 传文件卡但网页还行 | MTU不匹配(VPN环境) | ping -M do -s 1472 | 调MTU或做MSS Clamping |
| 带宽只用了一半就卡 | 端口协商成半双工/百兆 | show interface看duplex/speed | 手动配置全双工千兆 |
| 监控正常但SSH经常断 | TCP keepalive被中间设备丢 | ss -ti看连接状态 | 调keepalive间隔/加应用层心跳 |
五、建一个灰色故障监控基线
灰色故障的根本解决方法不是"等用户报了再查",而是把监控阈值调低到能发现灰色区域。
需要调整的监控阈值
标准告警阈值(大部分企业默认的):
├── 丢包告警:>5%
├── 延迟告警:>100ms
├── 端口流量告警:>80%利用率
└── 结果:灰色故障完全不报警
建议的灰色故障阈值(加一层"预警"级别):
├── 丢包预警:>1%(告警仍保留5%)
├── 延迟预警:>30ms 或 抖动>20ms
├── DNS响应预警:>100ms
├── TCP重传率预警:>0.5%
├── 端口错包预警:每小时新增>10个CRC错误
└── 结果:灰色故障能被提前发现需要补充监控的指标
大部分中小企业的监控只看"通断+CPU+内存+带宽"。灰色故障需要这些额外指标:
灰色故障监控补充清单:
├── 网络层
│ ├── 丢包率(每5分钟统计一次,阈值1%预警)
│ ├── 延迟+抖动(不只看平均值,要看P95/P99)
│ ├── 端口CRC错误计数(持续增长=物理层问题)
│ └── 端口协商状态(speed/duplex变化=告警)
├── DNS层
│ ├── DNS响应时间(超过100ms预警)
│ └── DNS查询失败率(任何失败都告警)
├── 传输层
│ ├── TCP重传率(超过0.5%预警)
│ ├── TCP连接超时次数
│ └── 半开连接数(SYN_SENT堆积=对端或链路问题)
└── 业务层
├── HTTP响应时间(TTFB超过2秒预警)
├── HTTP 5xx错误率
└── 业务探针成功率(模拟用户访问)我们在客户那里实际做的时候,把这些灰色故障指标和常规监控放在同一个运维平台上跑。一个大盘页面左边是传统监控(通断、CPU、带宽),右边是"链路质量"面板(丢包趋势、延迟P95、DNS响应、TCP重传率)。90%的灰色故障在用户感知之前就能被发现------因为丢包从0%开始爬升到1%的时候,平台已经发预警了,不用等到用户来投诉。
工具选型是后面的事。用开源方案也能做:Smokeping做链路质量监控、Zabbix做端口错包/协商检测、自定义脚本做DNS和TCP检测。关键是意识到传统监控看不到灰色故障,需要补充一层更敏感的探测。
六、给中小企业IT团队的3条建议
第一,把ping探测间隔缩短到1分钟以内。 很多监控默认5分钟ping一次,灰色故障往往是"偶尔丢几个包",5分钟一次的采样根本捕捉不到。改成每30秒ping一次、每次10包,才能反映真实链路质量。
第二,灰色故障优先查物理层。 经验告诉我,中小企业80%的灰色故障最终都是物理层问题------网线老化、水晶头氧化、光模块脏、交换机端口接触不良。不是什么高深的协议问题。先摸线、换线、换口试试。
第三,维护一张"链路健康基线表"。 每条专线/每个核心链路的正常延迟、正常丢包率是多少,记下来。有基线才能发现"变化"------延迟从5ms变成12ms,可能就是劣化的开始。没有基线,你看到12ms也不知道是不是有问题。
灰色故障是中小企业IT运维最容易被忽视的"慢性病"。它不会让系统崩溃(所以没人重视),但会让所有用户的效率持续下降(所以人人都在抱怨)。治好它,不需要加带宽、不需要换设备------需要的是一套更敏感的探测体系和一条清晰的排查路径。
📦 文中的灰色故障持续探测脚本、排查决策树高清版、MTU检测工具、灰色故障监控阈值配置模板已整理成可直接用的工具包,需要的在评论区留言。