提示:Win11下给Codex配置 Jira MCP 的完整教程,codex读取wiki页面需求文档,并产出设计文档;codex读取观测云日志;claude+ccswitch读取数据库、claude+ccswitch读取wiki、jira、claude帮我读取日志扫描代码、cursor,claude,codex,minimax,right code使用分享心得,用 Docker 给 Codex 配置 Jira / Wiki MCP、MCP常见问题排查
文章目录
- 前言
- 一、效果图
- 二、概念介绍
- 三、前置操作
- 四、修改配置
-
- 1、找到codex配置文件
- [2、写入Jira MCP 配置(不要怕麻烦,文章末尾有我的配置,直接粘贴改一下即可)](#2、写入Jira MCP 配置(不要怕麻烦,文章末尾有我的配置,直接粘贴改一下即可))
- [3、解释Jira MCP各配置含义](#3、解释Jira MCP各配置含义)
-
- [3.1、`command` 和 `args`](#3.1、
command和args) - [3.2、`-e` 和 `mcp_servers.jira.env`](#3.2、
-e和[mcp_servers.jira.env]) - 3.3、`TOOLSETS`
- 3.4、`ENABLED_TOOLS`
- 3.5、`READ_ONLY_MODE`
- [3.1、`command` 和 `args`](#3.1、
- [4、同时配置 Confluence / Wiki](#4、同时配置 Confluence / Wiki)
- 5、重启codex并验证
- 五、常见问题排查
-
- [1. `/mcp` 显示 `Tools: (none)`](#1.
/mcp显示Tools: (none)) - [2. Docker 提示镜像拉取失败](#2. Docker 提示镜像拉取失败)
- [3. Codex 能看到 MCP Server,但调用工具时报 401 / 403](#3. Codex 能看到 MCP Server,但调用工具时报 401 / 403)
- [4. 调用工具一直超时](#4. 调用工具一直超时)
- [5. 不要把日志写到 stdout](#5. 不要把日志写到 stdout)
- [1. `/mcp` 显示 `Tools: (none)`](#1.
- [六、MCP 能做什么,不能做什么](#六、MCP 能做什么,不能做什么)
-
- [1、MCP 能做什么](#1、MCP 能做什么)
- [2、MCP 不能做什么](#2、MCP 不能做什么)
- [七、从 0 到 1 配置 MCP 的完整流程总结](#七、从 0 到 1 配置 MCP 的完整流程总结)
- 八、我个人的完整配置文件
- 总结
前言
现在 AI 工具已经从"聊天助手"逐渐变成"研发助手"。普通聊天模型只能根据你输入的文本回答问题,但研发工作里的真实上下文往往分散在 Jira、Confluence / Wiki、数据库、日志平台、代码仓库、内部 API 里。
如果每次都靠人工复制粘贴,效率很低,也容易漏信息。MCP 的价值就在这里:它把外部系统包装成 AI 客户端可以调用的工具,让 Codex、Claude、Cursor 等客户端能够在授权范围内读取业务系统的数据。
举几个常见场景:
- 让 Codex 读取 Jira 需求单,然后生成设计文档。
- 让 Codex 读取 Confluence / Wiki 页面,理解业务背景。
- 让 Codex 查询日志系统,定位线上报错。
- 让 Claude / Cursor 查询数据库,辅助分析问题。
- 让 AI 调用内部 API,完成研发流程中的固定动作。
本文不只贴配置,还会解释为什么要这么配。读完之后,你应该能知道:
- MCP 是什么。
- MCP Client、MCP Server、业务系统分别是什么角色。
stdio传输方式是什么意思。- Win11 下如何给 Codex 配置一个 Jira / Wiki MCP。
- 如何验证 MCP 是否配置成功。
- 常见错误如何排查。
目前已经使用过:claude、codex、cursor、minimax、kimi、right code。。。我个人认为,目前,最好用的,无疑是claude,但是claude封的过快,导致几乎不可用。(刚用完没两天就不能用了),其次便是codex。本次便是分享的codex。
截止到目前为止,我仅保留了2种AI:right Code、miniMax。right Code无疑是"真香",甩国产几条街,没有对比就没有伤害。(感兴趣的话,可以点击这个按钮,这个按钮对应的文章就是right code自动生成的)。nimiMax是国产的,保留它是因为它的优势很明显:量大管饱且便宜。一年12个月才399,399对应的miniMax是每5小时1500条,无疑是非常适合高频问简单问题的,针对于程序员日常开发,这个流量绰绰有余,甚至一个团队的日常开发也能满足。如果大家有需要的话,可以访问。
rightcode的地址:地址(按流量计费)
minimax的地址:地址(399一年)
话不多说,咱们上干货。
一、效果图
俗话说,有图有真相,没图没朋友。放两张图大家看一下:
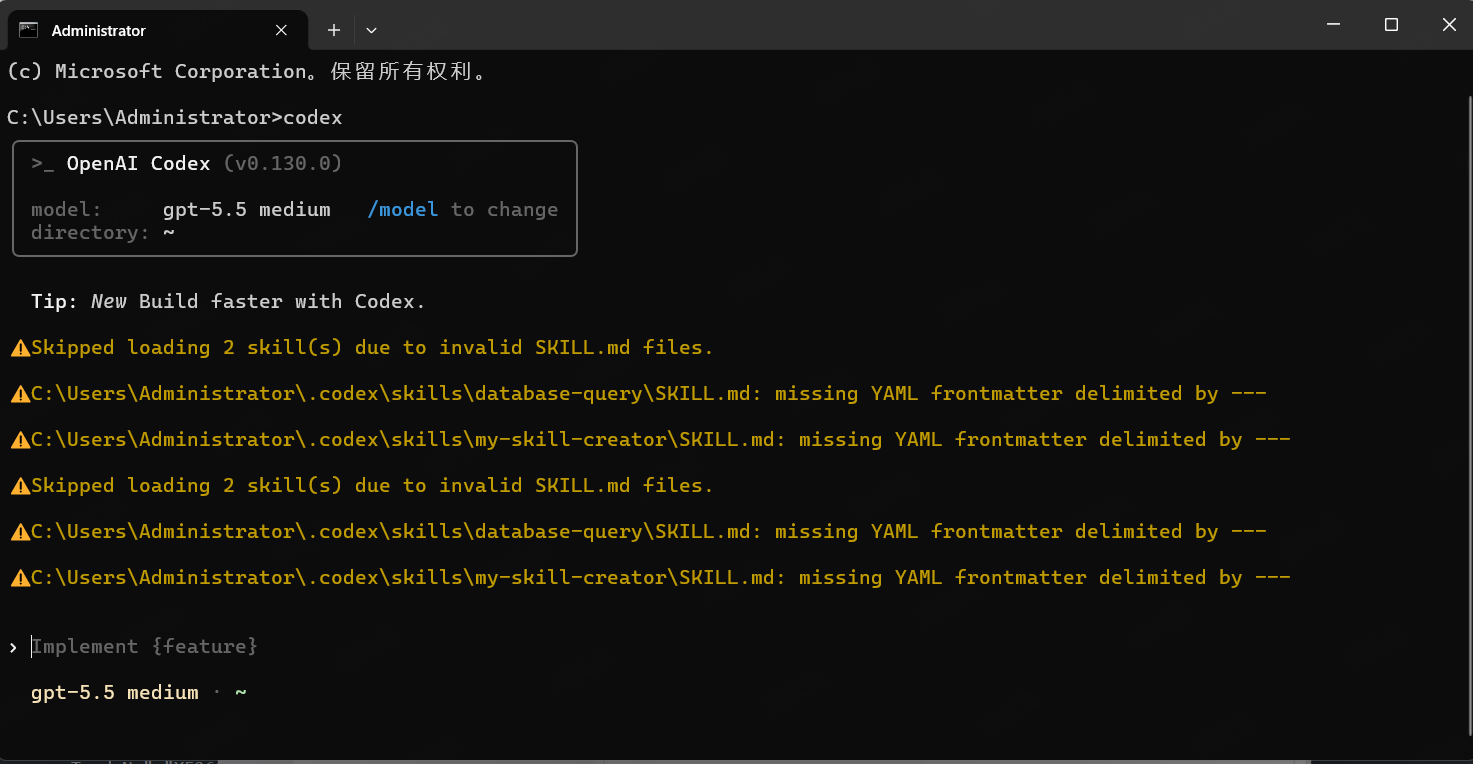
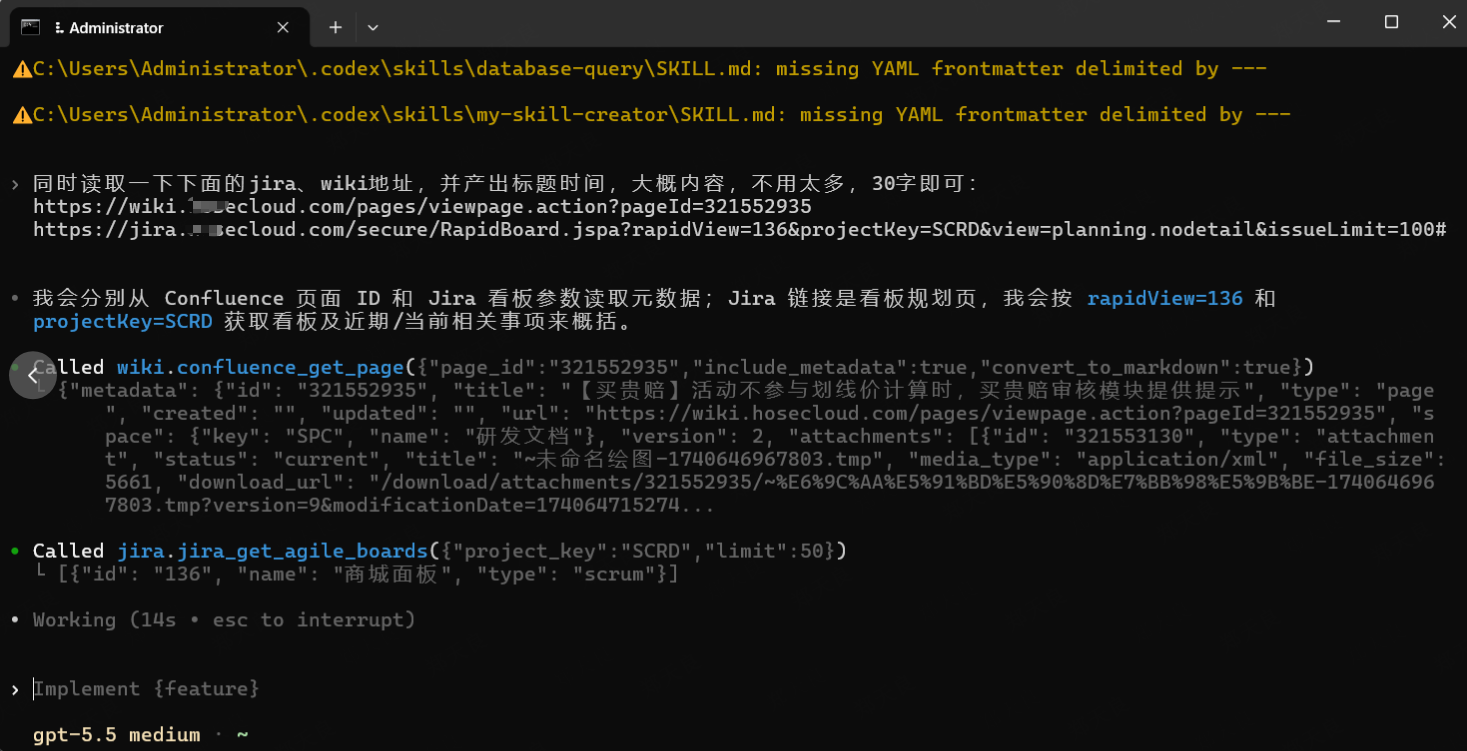
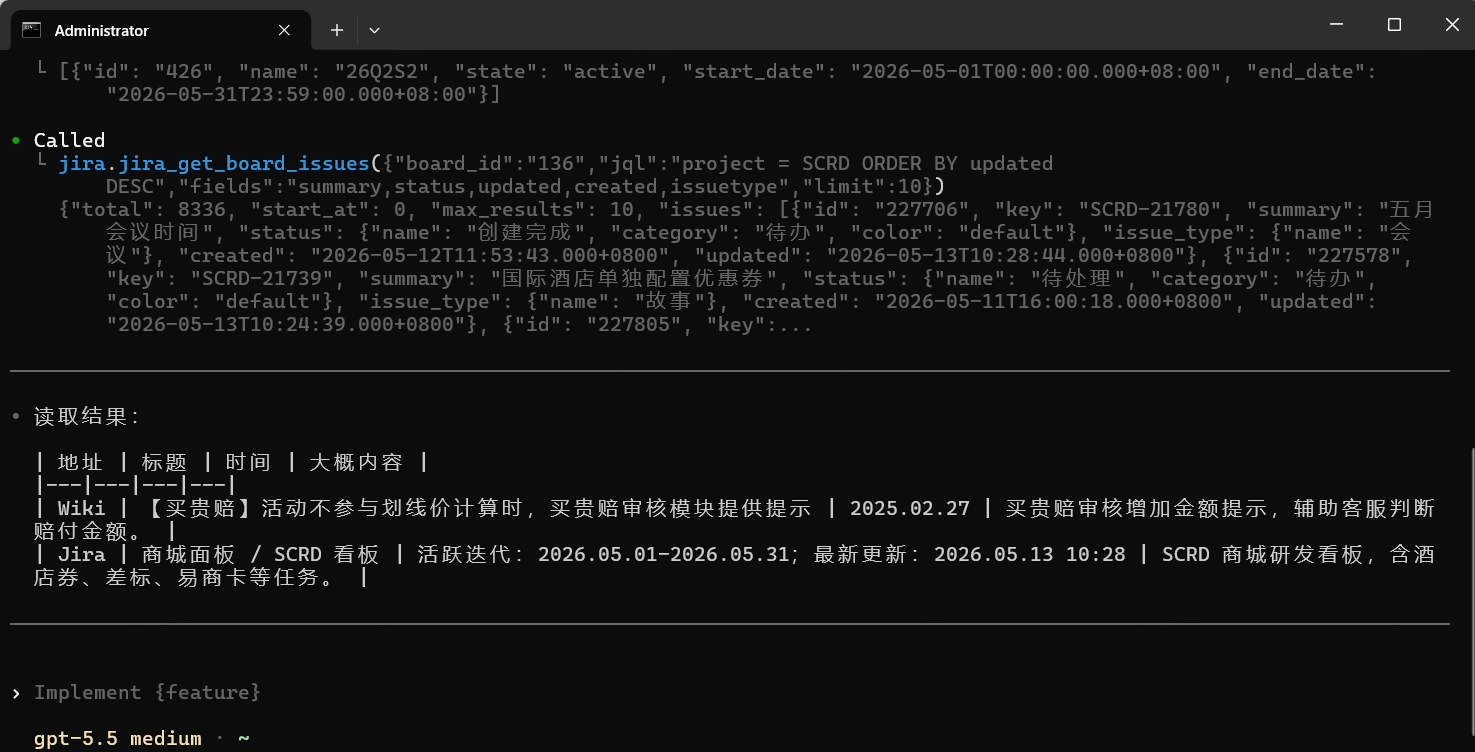
二、概念介绍
1、MCP是什么?
MCP,全称 Model Context Protocol,可以理解为"让 AI 助手连接外部系统的一套标准协议"。一句话解释: MCP 是一套标准协议,用来让 AI 客户端安全、统一地连接外部系统和工具 。这里的"AI 客户端"可以是:
- Codex
- Claude Desktop / Claude Code
- Cursor
- Cline
- 其他支持 MCP 的 IDE 或 Agent 工具
这里的"外部系统"可以是:
- Jira
- Confluence / Wiki
- GitLab / GitHub
- 数据库
- 日志平台
- 文件系统
- 内部业务 API
- 浏览器自动化工具
- 任何可以被程序访问的系统
没有 MCP 时,不同 AI 工具要接 Jira、接数据库、接日志平台,都要各写一套私有插件。MCP 做的事情,就是把这类连接方式标准化。简单总结,你可以把 MCP 想象成 AI 世界里的"USB-C 接口"
2、MCP原理
MCP 的整体链路可以这样理解:
bash
AI Client
例如 Codex / Claude / Cursor
|
| MCP 协议
v
MCP Server
例如 Jira MCP / GitHub MCP / 数据库 MCP / 日志 MCP
|
| HTTP / JDBC / SDK / RPC / 文件系统 / 数据库协议
v
业务系统
例如 Jira / Wiki / MySQL / 日志平台 / 内部服务各角色的职责如下。
3、各角色职责
3.1、AI Client
AI Client 是你正在使用的 AI 工具,比如 Codex。
它负责:
- 读取 MCP 配置。
- 启动或连接 MCP Server。
- 获取 MCP Server 暴露了哪些工具。
- 在模型需要时调用这些工具。
- 把工具返回的结果交给模型继续推理。
你在 Codex 里看到的 /mcp,本质上就是查看当前客户端已经连接了哪些 MCP Server,以及这些 Server 暴露了哪些工具。
3.2、MCP Server
MCP Server 是一个普通程序,可以用 Node.js、Python、Go、Java、Rust 等语言实现。
它负责:
- 对外遵守 MCP 协议。
- 对内调用真实业务系统。
- 把业务系统能力包装成一个个工具。
例如 Jira MCP Server 可能暴露这些工具:
jira_get_issuejira_searchjira_get_project_issuesjira_get_agile_boardsjira_get_board_issuesjira_get_sprints_from_boardjira_get_sprint_issues
这些工具背后真正调用的是 Jira 的 REST API。
3.3、业务系统
业务系统就是 MCP Server 最终要访问的数据源或服务。
例如:
- Jira MCP Server 访问 Jira API。
- Confluence MCP Server 访问 Confluence API。
- MySQL MCP Server 访问 MySQL。
- 日志 MCP Server 访问日志平台 API。
所以 MCP 不是替代业务系统,也不是让模型直接连数据库。更准确地说,MCP Server 是一个"受控代理层":它决定 AI 能访问什么、怎么访问、是否只读、是否需要鉴权。
4、MCP 通信方式
MCP 协议使用 JSON-RPC 来编码请求和响应。官方协议中常见的传输方式主要有两类:
stdioStreamable HTTP
4.1、stdio
stdio 是 standard input / standard output 的缩写,也就是标准输入和标准输出。
在 stdio 模式下,AI Client 会启动一个本地 MCP Server 子进程,然后:
- Client 往 Server 的
stdin写入 MCP 请求。 - Server 从
stdin读取请求。 - Server 把 MCP 响应写到
stdout。 - Client 从
stdout读取响应。 - Server 的日志一般写到
stderr。
在 stdio 模式下:
bash
Codex
|
| 启动本地子进程
v
docker run -i --rm ghcr.io/sooperset/mcp-atlassian:latest --transport stdio
|
| stdin / stdout
v
MCP Server
|
| Jira REST API / Confluence REST API
v
Jira / Confluencestdio 的特点:
- 适合本地工具。
- 不需要单独开放端口。
- 生命周期通常由客户端管理。
- Client 关闭后,Server 子进程也会退出。
- Server 的
stdout必须只输出合法 MCP 消息,普通日志不要写到stdout。
这就是为什么 Docker 命令里经常能看到 -i,因为 MCP Server 需要通过标准输入持续读取客户端发来的协议消息。
4.2、Streamable HTTP
Streamable HTTP 更适合远程服务。
这种方式下,MCP Server 是一个独立运行的 HTTP 服务,客户端通过 HTTP endpoint 访问它。适合这些场景:
- 团队共用一个 MCP Server。
- Server 部署在内网服务器或 Kubernetes 中。
- 需要统一网关、鉴权、审计、限流。
- 不希望每个客户端都本地启动一个进程。
本文使用 Docker + stdio,因为它最适合个人本地配置,步骤也最简单。
三、前置操作
1、安装docker
Win11 推荐安装 Docker Desktop。
安装完成后,打开 PowerShell 或 CMD,执行:
powershell
docker --version
docker run hello-world能正常输出版本号,并且 hello-world 能运行,说明 Docker 基本可用。
2、安装Node.js和npm
Codex CLI 通常通过 npm 安装,因此需要先安装 Node.js。
验证命令:
powershell
node -v
npm -v如果能输出版本号,说明 Node.js 和 npm 已安装成功。
node -v
npm -v
docker --version3、安装或更新Codex
执行:
powershell
npm install -g @openai/codex安装完成后验证:
powershell
codex --version
codex如果能进入 Codex 命令行界面,说明安装成功。
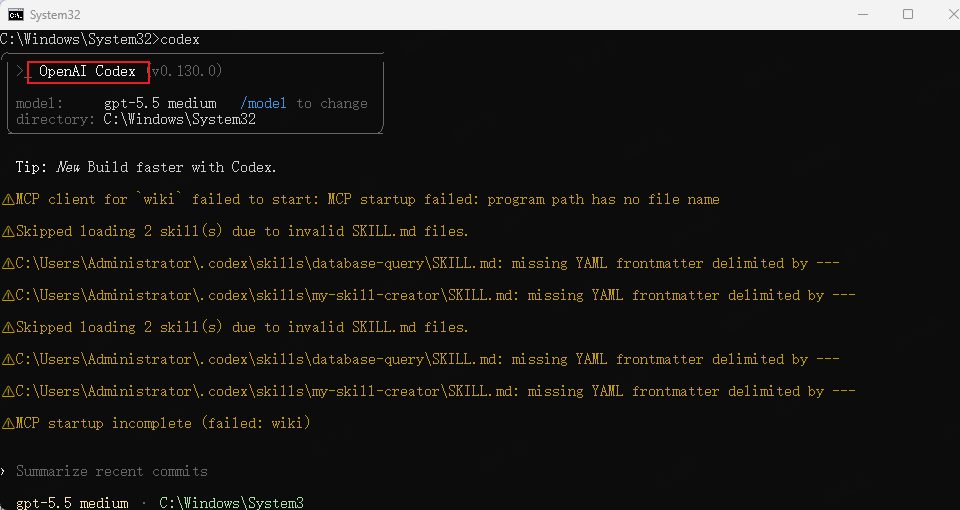
如果你是第一次安装codex,直接执行上面的命令就行,如果你不是第一次安装,就需要删除旧的codex的缓存,不然一些配置可能是旧的,会影响你后续的mcp配置。删除很简单: 将 C:\Users\Administrator 下的 (用户的文件夹,不一定是Administrator ).codex 文件夹整个删除。
效果是,win+r输入cmd按回车弹出来的命令行中,输入codex,看到的效果是 openAI Codex,如下图:
4、准备Jira/Confluence凭证
至少需要准备:
text
JIRA_URL
JIRA_USERNAME
JIRA_API_TOKEN 或 JIRA_PERSONAL_TOKEN示例:
text
JIRA_URL=https://jira.example.com
JIRA_USERNAME=your-name@example.com
JIRA_API_TOKEN=xxxxxxxx如果你还要读取 Confluence / Wiki,通常还需要:
text
CONFLUENCE_URL
CONFLUENCE_USERNAME
CONFLUENCE_API_TOKEN 或 CONFLUENCE_PERSONAL_TOKEN具体字段以所使用的 MCP Server 文档为准。文章末尾我会贴上我的配置文件,防止大家写错。
5、拉取、验证wiki的Mcp镜像
先拉取镜像:
powershell
docker pull ghcr.io/sooperset/mcp-atlassian:latest再检查镜像是否存在:
powershell
docker image inspect ghcr.io/sooperset/mcp-atlassian:latest这一步的意义是先排除网络、Docker、镜像拉取问题。不要一上来就改 Codex 配置,否则排错范围会很大。
6、ccswitch
ccswitch是方便你切换AI工具的,可安装可不安装。简单的说,ccswitch其实是方便你管理你的配置文件的。不安装也不影响后续的操作,我为了方便管理,就安装了。如果安装的话,可以这么配置:
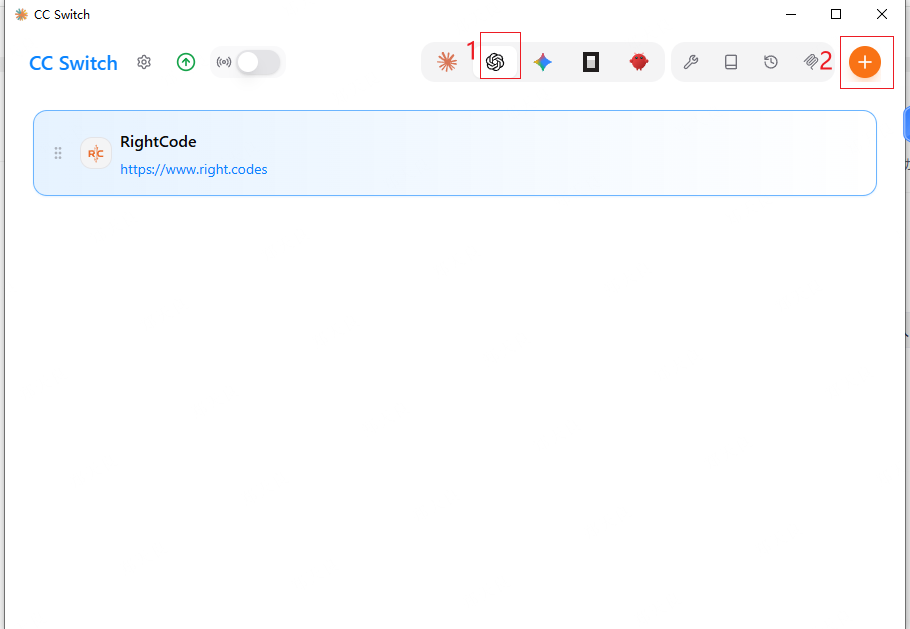
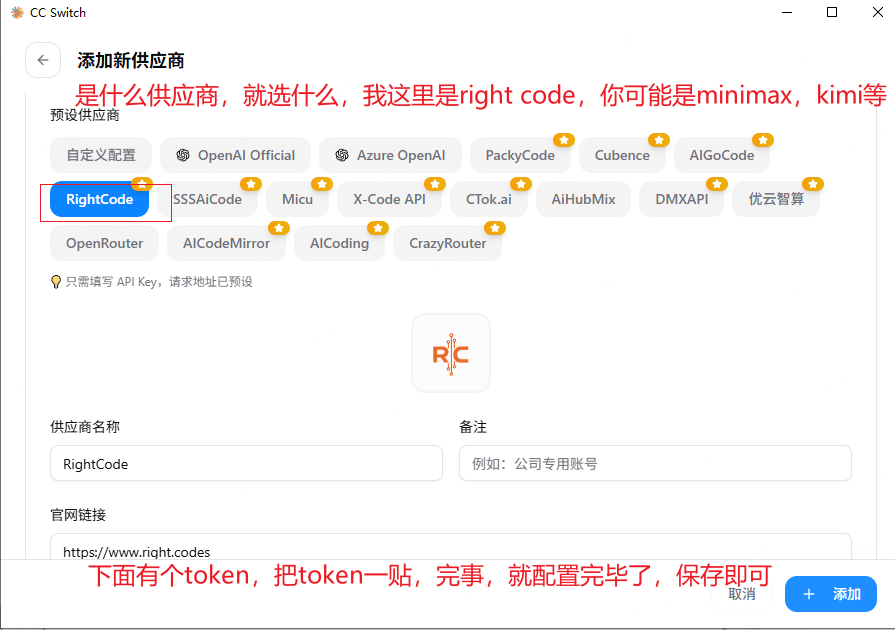
配置后的效果:
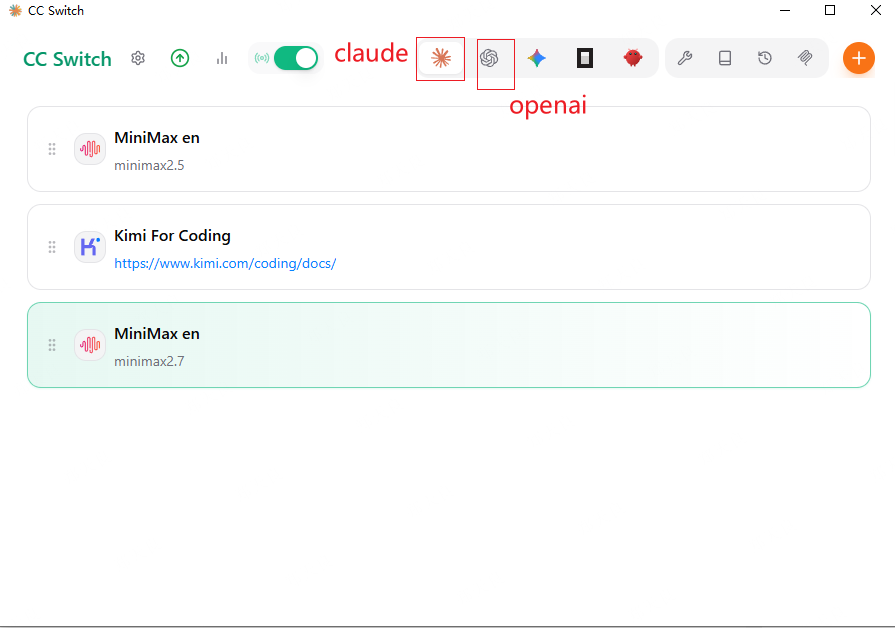
四、修改配置
运行方式依赖 Docker,所以需要先确认:
- Win11 已安装 Docker Desktop
- Docker Desktop 正常运行
- 当前机器能访问 Jira 地址
- 已准备好 Jira 访问凭据
1、找到codex配置文件
修改前建议先备份,如果改错了,可以用备份文件恢复。
在 Win11 上,Codex 的全局配置文件一般在当前用户目录下:
text
C:\Users\<你的用户名>\.codex\config.toml本次机器上的实际路径是:
text
C:\Users\Administrator\.codex\config.toml这是全局配置,不是当前聊天窗口的临时配置。也就是说,只要改的是这个文件,关闭当前 Codex 窗口后,新开 Codex 仍然会读取这份配置。
2、写入Jira MCP 配置(不要怕麻烦,文章末尾有我的配置,直接粘贴改一下即可)
推荐配置如下:
bash
[mcp_servers.jira]
command = "docker"
args = [
"run",
"-i",
"--rm",
"-e", "JIRA_URL",
"-e", "JIRA_USERNAME",
"-e", "JIRA_API_TOKEN",
"-e", "JIRA_PERSONAL_TOKEN",
"-e", "TOOLSETS",
"-e", "ENABLED_TOOLS",
"-e", "READ_ONLY_MODE",
"ghcr.io/sooperset/mcp-atlassian:latest",
"--transport",
"stdio"
]
[mcp_servers.jira.env]
JIRA_URL = "https://jira.example.com"
JIRA_USERNAME = "your-name@example.com"
JIRA_API_TOKEN = "your-api-token"
JIRA_PERSONAL_TOKEN = "your-personal-token"
TOOLSETS = "jira_issues,jira_agile,jira_projects,jira_fields"
ENABLED_TOOLS = "jira_get_issue,jira_search,jira_get_project_issues,jira_get_agile_boards,jira_get_board_issues,jira_get_sprints_from_board,jira_get_sprint_issues,jira_get_project_versions,jira_get_all_projects,jira_search_fields,jira_get_field_options,jira_batch_get_changelogs"
READ_ONLY_MODE = "true"3、解释Jira MCP各配置含义
3.1、command 和 args
toml
command = "docker"
args = ["run", "-i", "--rm", ...]意思是:Codex 启动 MCP Server 时,实际执行的是:
powershell
docker run -i --rm ...其中:
docker是启动命令。args是传给docker的参数。-i表示保持标准输入打开,stdio 模式必须要有。--rm表示容器退出后自动删除,避免残留大量临时容器。
3.2、-e 和 [mcp_servers.jira.env]
Docker 命令里的:
toml
"-e", "JIRA_URL"表示把环境变量 JIRA_URL 传给容器。
下面这段:
toml
[mcp_servers.jira.env]
JIRA_URL = "https://jira.example.com"表示 Codex 启动进程时,先设置环境变量,再让 Docker 把这些变量传进容器。
所以完整链路是:
text
Codex config.toml
-> Codex 启动 docker run
-> Docker 把环境变量传入容器
-> 容器里的 MCP Server 读取环境变量
-> MCP Server 调用 Jira API3.3、TOOLSETS
TOOLSETS 用来指定启用哪些工具集合。
示例:
toml
TOOLSETS = "jira_issues,jira_agile,jira_projects,jira_fields"不要简单写成:
toml
TOOLSETS = "jira"很多 MCP Server 对 toolset 名称有严格要求,写错后可能出现 /mcp 能看到 server,但 tools 为空。
3.4、ENABLED_TOOLS
ENABLED_TOOLS 用来显式指定暴露哪些工具。
好处是:
- 减少无关工具。
- 降低误操作风险。
- 让模型可用工具更清晰。
- 出问题时更容易排查。
3.5、READ_ONLY_MODE
建议先设置:
toml
READ_ONLY_MODE = "true"这表示只读模式。也就是 AI 可以读取 Jira,但不能创建、修改、删除 Jira 内容。
第一次配置 MCP 时,不建议直接开放写能力。等你确认工具行为稳定、权限范围明确、团队安全规范允许后,再考虑开放写操作。
4、同时配置 Confluence / Wiki
如果你要让 Codex 读取 Wiki,可以在同一个 mcp-atlassian 中开启 Confluence 相关配置。示例:
toml
[mcp_servers.atlassian]
command = "docker"
args = [
"run",
"-i",
"--rm",
"-e", "JIRA_URL",
"-e", "JIRA_USERNAME",
"-e", "JIRA_API_TOKEN",
"-e", "CONFLUENCE_URL",
"-e", "CONFLUENCE_USERNAME",
"-e", "CONFLUENCE_API_TOKEN",
"-e", "TOOLSETS",
"-e", "ENABLED_TOOLS",
"-e", "READ_ONLY_MODE",
"ghcr.io/sooperset/mcp-atlassian:latest",
"--transport",
"stdio"
]
[mcp_servers.atlassian.env]
JIRA_URL = "https://jira.example.com"
JIRA_USERNAME = "your-name@example.com"
JIRA_API_TOKEN = "your-jira-token"
CONFLUENCE_URL = "https://wiki.example.com"
CONFLUENCE_USERNAME = "your-name@example.com"
CONFLUENCE_API_TOKEN = "your-confluence-token"
TOOLSETS = "jira_issues,jira_agile,jira_projects,jira_fields,confluence_search,confluence_pages"
ENABLED_TOOLS = "jira_get_issue,jira_search,jira_get_project_issues,jira_get_agile_boards,jira_get_board_issues,jira_get_sprints_from_board,jira_get_sprint_issues,confluence_search,confluence_get_page"
READ_ONLY_MODE = "true"注意:不同版本的 mcp-atlassian 支持的 toolset 和 tool 名称可能不同。如果 /mcp 中没有看到 Confluence 工具,需要回到该 MCP Server 的 README 或启动日志里确认具体名称。
5、重启codex并验证
修改 config.toml 后,关闭当前 Codex 会话,重新打开 Codex。
进入新会话后执行:
text
/mcp成功时应该能看到:
text
jira
Tools: jira_get_issue, jira_search, ...然后可以做一次真实验证:
text
请读取 Jira 单 SCRD-19749,并总结它的标题、状态、负责人、需求背景和验收标准。如果要验证搜索能力:
text
请在 Jira 中搜索 project = SCRD AND status != Done 的最近 10 个需求单。如果要验证 Wiki:
text
请搜索标题包含"订单调度"的 Wiki 页面,并总结最相关的一篇。五、常见问题排查
1. /mcp 显示 Tools: (none)
这是最常见问题。
优先检查:
TOOLSETS是否写错。ENABLED_TOOLS里的工具名是否真实存在。- Docker 镜像版本是否支持这些工具。
- 容器启动后是否因为鉴权失败退出。
stdout是否被普通日志污染。
排查思路:
text
先确认 Docker 能运行
再确认 MCP Server 能启动
再确认环境变量正确
最后确认 toolset / tool 名称正确2. Docker 提示镜像拉取失败
可能原因:
- 网络无法访问
ghcr.io。 - 公司网络代理限制。
- Docker Desktop 没有启动。
- DNS 解析失败。
可以先执行:
powershell
docker pull ghcr.io/sooperset/mcp-atlassian:latest如果这一步失败,说明问题还没到 Codex 层。
3. Codex 能看到 MCP Server,但调用工具时报 401 / 403
这是鉴权问题。
检查:
JIRA_URL是否正确。- 用户名是否正确。
- Token 是否过期。
- Token 是否有权限访问目标项目。
- 公司 Jira 是否需要 VPN 或内网环境。
- Jira Cloud 和 Jira Server / Data Center 的认证方式是否混用了。
4. 调用工具一直超时
可能原因:
- 本机访问不了 Jira / Wiki。
- VPN 未连接。
- Jira 地址需要代理。
- Docker 容器内网络访问不到公司内网。
- MCP Server 启动慢或被防火墙拦截。
可以先在宿主机验证:
powershell
curl https://jira.example.com如果宿主机能访问,但容器访问不了,需要重点检查 Docker Desktop 网络、代理和 VPN。
5. 不要把日志写到 stdout
stdio 模式下,stdout 是 MCP 协议通道,必须输出合法 JSON-RPC 消息。
如果 MCP Server 把普通日志写到 stdout,客户端可能解析失败。日志应该写到 stderr。
如果你自己写 MCP Server,这一点非常重要。
六、MCP 能做什么,不能做什么
1、MCP 能做什么
MCP 能让 AI:
- 读取外部系统数据。
- 调用被授权的工具。
- 基于真实上下文回答问题。
- 把多个系统的信息串起来分析。
- 自动化部分研发流程。
例如:
text
读取 Jira 需求 -> 读取 Wiki 背景 -> 扫描代码 -> 生成技术方案再比如:
text
读取线上报错日志 -> 根据 traceId 定位链路 -> 扫描相关代码 -> 给出修复建议2、MCP 不能做什么
MCP 不是万能的。
它不能绕过权限:
text
用户没有权限访问 Jira 项目,MCP 也不应该访问到。它不能保证模型一定理解正确:
text
MCP 只负责把数据取回来,最终怎么推理仍然取决于模型能力和提示词质量。它也不能替代安全治理:
text
该审计的要审计,该脱敏的要脱敏,该只读的要只读。七、从 0 到 1 配置 MCP 的完整流程总结
完整流程可以按下面顺序走:
text
1. 明确你要接入什么系统
例如 Jira / Wiki / 数据库 / 日志平台
2. 找到或开发对应的 MCP Server
例如 mcp-atlassian
3. 确认运行方式
本地个人使用优先 stdio
团队共享服务优先 Streamable HTTP
4. 准备运行环境
Node.js / npm / Docker / VPN / 网络代理
5. 准备访问凭证
URL / username / token / personal access token
6. 单独验证 MCP Server 能启动
先排除 Docker、镜像、网络问题
7. 修改 AI Client 配置
例如 Codex 的 config.toml
8. 重启 AI Client
让配置生效
9. 使用 /mcp 验证工具是否注册成功
10. 用真实问题验证工具调用
例如读取一个 Jira 单
11. 做安全收敛
只读模式、最小权限、最小工具集八、我个人的完整配置文件
C:\Users\Administrator.codex 下的 config.toml 文件:
bash
model_provider = "rightcode"
model = "gpt-5.4"
model_reasoning_effort = "medium"
disable_response_storage = true
[model_providers.rightcode]
name = "rightcode"
base_url = "https://right.codes/codex/v1"
wire_api = "responses"
requires_openai_auth = true
[mcp_servers.wiki]
type = "stdio"
command = "docker"
args = ["run", "-i", "--rm", "-e", "CONFLUENCE_URL", "-e", "CONFLUENCE_USERNAME", "-e", "CONFLUENCE_API_TOKEN", "-e", "CONFLUENCE_PERSONAL_TOKEN", "-e", "TOOLSETS", "ghcr.io/sooperset/mcp-atlassian:latest", "--transport", "stdio"]
[mcp_servers.wiki.env]
CONFLUENCE_API_TOKEN = "NjkyODgyO------后面我给去掉了,是你个人对应的token"
CONFLUENCE_PERSONAL_TOKEN = "NjkyOD------后面我给去掉了,是你个人对应的token"
CONFLUENCE_URL = "https://wiki.hoxxcloud.com"
CONFLUENCE_USERNAME = "zhengxxxxx@xxcloud.com"
TOOLSETS = "confluence_pages"
[mcp_servers.jira]
type = "stdio"
command = "docker"
args = ["run", "-i", "--rm", "-e", "JIRA_URL", "-e", "JIRA_USERNAME", "-e", "JIRA_API_TOKEN", "-e", "JIRA_PERSONAL_TOKEN", "-e", "TOOLSETS", "-e", "ENABLED_TOOLS", "-e", "READ_ONLY_MODE", "ghcr.io/sooperset/mcp-atlassian:latest", "--transport", "stdio"]
[mcp_servers.jira.env]
ENABLED_TOOLS = "jira_get_issue,jira_search,jira_get_project_issues,jira_get_agile_boards,jira_get_board_issues,jira_get_sprints_from_board,jira_get_sprint_issues,jira_get_project_versions,jira_get_all_projects,jira_search_fields,jira_get_field_options,jira_batch_get_changelogs"
JIRA_API_TOKEN = "MjI3ODA------后面我给去掉了,是你个人对应的token"
JIRA_PERSONAL_TOKEN = "MjI3ODA------后面我给去掉了,是你个人对应的token"
JIRA_URL = "https://jira.xxxcloud.com"
JIRA_USERNAME = "zhengtxxg@hxxcloud.com"
READ_ONLY_MODE = "true"
TOOLSETS = "jira_issues,jira_agile,jira_projects,jira_fields"
[projects.'c:\users\administrator']
trust_level = "trusted"
[projects.'c:\windows\system32']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-flight-6']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-train-3-master']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-flight-9-master']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-flight-3-dev']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-sms-3-kaifa']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-train-2-merge']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-hotel']
trust_level = "trusted"
[projects.'d:\ruanjian\java\idea\file\mall-hotel-order-merge']
trust_level = "trusted"
[tui.model_availability_nux]
"gpt-5.5" = 4
[windows]
sandbox = "elevated"总结
MCP 的核心不是"某个配置文件怎么写",而是把外部系统能力标准化地暴露给 AI 客户端。对个人开发者来说,最容易落地的方式是:
text
Codex + Docker + stdio MCP Server + 只读 Token先用 Jira / Wiki 这种低风险读操作跑通,再逐步扩展到日志、数据库、内部 API。只要理解了 AI Client -> MCP Server -> 业务系统 这条链路,后面接入任何 MCP 都是同一套思路。