文章目录
迭代器模式
提供一种解决方案使其能够顺序访问一个集合对象中的各个元素,而又不暴露该集合底层的表现形式(列表、栈、树、图等),这种行为设计模式就叫迭代器模式,其中迭代器用于遍历容器并访问容器的元素。
集合中需要解决的问题
无论集合的构成方式如何, 它都必须提供某种访问元素的方式 , 便于其他代码使用其中的元素。集合应提供一种能够遍历元素的方式, 且保证它不会周而复始地访问同一个元素。
如果集合基于列表,遍历实现非常简单,如果是复杂的数据结构(如树),那就不是那么容易,比如:
- 今天需要深度优先算法来遍历树结构;
- 明天需要广度优先算法来遍历树结构;
- 下周则可能会需要其他方式 (比如随机存取树中的元素)。
不断向集合中添加遍历算法会模糊其 "高效存储数据 " 的主要职责。 此外, 有些算法可能是根据特定应用订制的, 将其加入泛型集合类中会显得非常奇怪。
另一方面, 使用多种集合的客户端代码可能并不关心存储数据的方式。 不过由于集合提供不同的元素访问方式, 你的代码将不得不与特定集合类进行耦合。
解决方案:将集合的遍历行为抽取为单独的 迭代器对象。
场景
比如大家想要去某个城市去旅游,这个城市有许多旅游景点,旅游方式可以采用下面的方法。
- 采用自由漫步的方式,一个景点一个景点的去旅游,中途可能会出现绕了很大一个圈子找不到某个旅游景点的情况;
- 也可以买一个便宜的智能虚拟导游程序;
- 还可以雇佣一个对本城市了如指掌的导游,帮你安排行程以及景点激动人心的故事讲解。
自由漫步、虚拟导游、真人导游就是这个由众多景点组合成的集合的迭代器。
迭代器模式又称为游标(Cursor)模式,可以让你能在不暴露集合底层表现形式 (列表、 栈和树等) 的情况下遍历集合中所有的元素。
结构
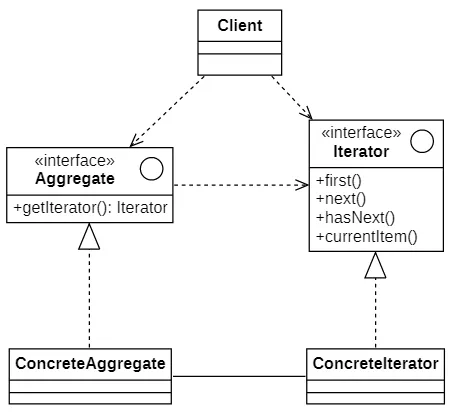
在迭代器模式结构图中包含如下几个角色:
- Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,在具体迭代器中将实现这些方法。
- Concrete Iterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。
- Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个getIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。
- Concrete Aggregate(具体聚合类):它实现了在抽象聚合类中声明的getIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例。
实现
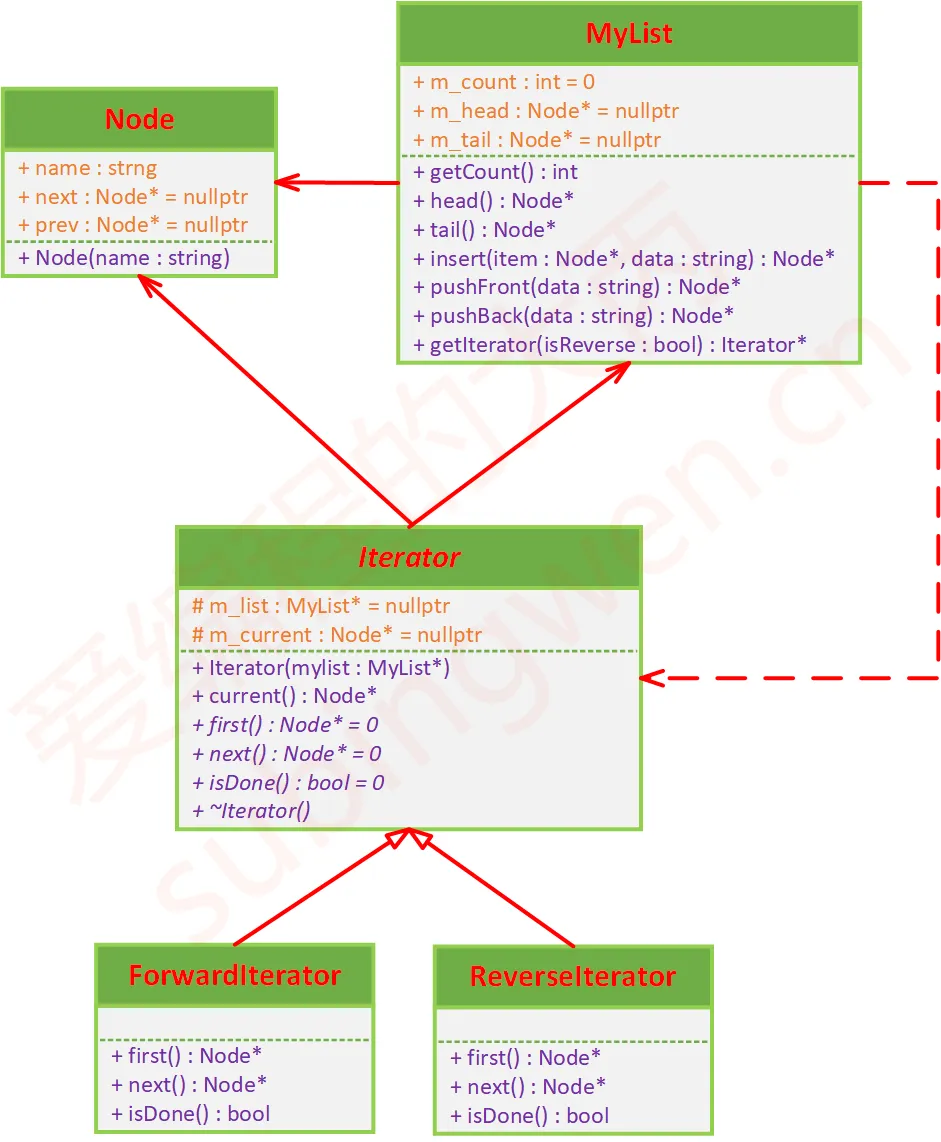
cpp
// 抽象的迭代器类
class Iterator
{
public:
Iterator(MyList* mylist) : m_list(mylist) {}
Node* current()
{
return m_current;
}
/*
*正向遍历的时候:
* 通过first()函数得到链表的头结点
* 通过next()函数得到当前节点的后继节点
*在进行逆向遍历的时候:
* 通过first()函数得到链表的尾结点
* 通过next()函数得到当前节点的前驱节点
*/
virtual Node* first() = 0;
virtual Node* next() = 0;
//判断遍历是否结束了
virtual bool isDone() = 0;
virtual ~Iterator() {}
protected:
//双向链表的实例对象
MyList* m_list = nullptr;
//得到遍历到的当前节点
Node* m_current = nullptr;
};
cpp
// 正向迭代器
class ForwardIterator : public Iterator
{
public:
using Iterator::Iterator;
Node* first() override
{
m_current = m_list->head();
return m_current;
}
Node* next() override
{
m_current = m_current->next;
return m_current;
}
bool isDone() override
{
return m_current == m_list->tail()->next;
}
};
// 逆向迭代器
class ReverseIterator : public Iterator
{
public:
using Iterator::Iterator;
Node* first() override
{
m_current = m_list->tail();
return m_current;
}
Node* next() override
{
m_current = m_current->prev;
return m_current;
}
bool isDone() override
{
return m_current == m_list->head()->prev;
}
};
cpp
//MyList.h
#pragma once
#include <string>
using namespace std;
// 定义一个链表节点
struct Node
{
Node(string n) : name(n) {}
string name = string();
Node* next = nullptr;
Node* prev = nullptr;
};
//由于迭代器类Iterator和链表类MyList是相互包含的关系,所以尽量不要让这两个类的头文件互相包含
//只是对 Iterator 迭代器类进行了声明,保证编译器能够识别出返回值类型即可
class Iterator;
// 双向链表
class MyList
{
public:
inline int getCount()
{
return m_count;
}
inline Node* head()
{
return m_head;
}
inline Node* tail()
{
return m_tail;
}
Node* insert(Node* item, string data);
Node* pushFront(string data);
Node* pushBack(string data);
Iterator* getIterator(bool isReverse = false);
private:
Node* m_head = nullptr;
Node* m_tail = nullptr;
int m_count = 0;
};
//MyList.cpp
#include "MyList.h"
#include "Iterator.h"
Node* MyList::insert(Node* item, string data)
{
Node* node = nullptr;
if (item == m_head)
{
node = pushFront(data);
}
else
{
node = new Node(data);
node->next = item;
node->prev = item->prev;
// 重新连接
item->prev->next = node;
item->prev = node;
m_count++;
}
return node;
}
Node* MyList::pushFront(string data)
{
Node* node = new Node(data);
// 空链表
if (m_head == nullptr)
{
m_head = m_tail = node;
}
else
{
node->next = m_head;
m_head->prev = node;
m_head = node;
}
m_count++;
return node;
}
Node* MyList::pushBack(string data)
{
Node* node = new Node(data);
// 空链表
if (m_tail == nullptr)
{
m_head = m_tail = node;
}
else
{
m_tail->next = node;
node->prev = m_tail;
m_tail = node;
}
m_count++;
return node;
}
Iterator* MyList::getIterator(bool isReverse)
{
Iterator* iterator = nullptr;
if (isReverse)
{
iterator = new ReverseIterator(this);
}
else
{
iterator = new ForwardIterator(this);
}
return iterator;
}
cpp
int main()
{
vector<string> nameList{
"烬", "奎因", "杰克", "福兹·弗", "X·德雷克",
"黑色玛利亚", "笹木", "润媞", "佩吉万",
"一美", "二牙", "三鬼", "四鬼", "五鬼",
"六鬼", "七鬼", "八茶", "九忍","十鬼"
};
MyList mylist;
for (int i = 0; i < nameList.size(); ++i)
{
mylist.pushBack(nameList.at(i));
}
// 遍历
Iterator* it = mylist.getIterator(true);
cout << "检阅开始, 凯多: 同志们辛苦啦~~~~~" << endl;
for (auto begin = it->first(); !it->isDone(); it->next())
{
cout << " " << it->current()->name << "say: 为老大服务!!! " << endl;
}
cout << endl;
delete it;
return 0;
}特点
主要优点
- 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足"开闭原则"的要求。
主要缺点
- 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
- 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如JDK内置迭代器 Iterator就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类ListIterator等来实现,而ListIterator迭代器无法用于操作Set类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是件很容易的事情。
适用环境
- 当集合背后为复杂的数据结构,且你希望对客户端隐藏其复杂性时(出于使用便利性或安全性的考虑),可以使用迭代器模式。
- 迭代器封装了与复杂数据结构进行交互的细节,为客户端提供多个访问集合元素的简单方法。 这种方式不仅对客户端来说非常方便, 而且能避免客户端在直接与集合交互时执行错误或有害的操作, 从而起到保护集合的作用。
- 想要减少程序中重复的遍历代码。
- 重要迭代算法的代码往往体积非常庞大。 当这些代码被放置在程序业务逻辑中时, 它会让原始代码的职责模糊不清, 降低其可维护性。 因此, 将遍历代码移到特定的迭代器中可使程序代码更加精和简洁。
- 希望代码能够遍历不同的甚至是无法预知的数据结构,可以使用迭代器模式。
- 该模式为集合和迭代器提供了一些通用接口。 如果你在代码中使用了这些接口, 那么将其他实现了这些接口的集合和迭代器传递给它时, 它仍将可以正常运行。