回溯算法 知识点整理
一、回溯算法基础概念
- 什么是回溯算法
回溯算法是一种经典的递归搜索算法,常用于解决组合问题、排列问题和搜索问题等。
- 基本思想
从一个初始状态开始,按照一定的规则向前搜索;当搜索到某个状态无法前进时,回退到前一个状态,再按照其他的规则继续搜索。
回溯算法在搜索过程中维护一个状态树,通过遍历状态树实现对所有可能解的搜索。
- 核心思想:"试错"
在搜索过程中不断做出选择:如果选择正确,则继续向前搜索;否则,回退到上一个状态,重新做出选择。
回溯算法通常用于解决具有多个解,且每个解都需要搜索才能找到的问题。
二、回溯算法通用模板(C++)
cpp
void backtrack(vector<int>& path, vector<int>& choices, ...) {
// 1. 满足结束条件
if (/* 满足结束条件 */) {
// 将路径添加到结果集中
res.push_back(path);
return;
}
// 2. 遍历所有可做的选择
for (int i = 0; i < choices.size(); i++) {
// 做出选择
path.push_back(choices[i]);
// 做出当前选择后继续递归搜索
backtrack(path, choices);
// 撤销选择(回溯核心)
path.pop_back();
}
}关键参数说明
path:表示当前已经做出的选择,即当前的搜索路径。
choices:表示当前状态下可以做出的所有选择。
执行流程:做出选择 → 递归搜索 → 撤销选择,通过这三步实现状态树的遍历。
三、回溯算法复杂度分析
时间复杂度:通常较高,因为需要遍历所有可能的解(状态树的所有节点),最坏情况下为指数级 O(k^n)(k 为每个节点的选择数,n 为路径长度)。
空间复杂度:较低,因为只需要维护当前状态的路径和递归栈,空间复杂度为 O(n)(n 为递归深度/路径长度)。
优化方向:实际应用中,通常通过剪枝提前排除不可能的分支,减少搜索次数,提升效率。
四、回溯算法的典型应用场景
- 组合问题
定义:从给定的一组数(不重复)中,选取出所有可能的 k 个数的组合。
示例:给定数集 1,2,3,选取 k=2 个数的所有组合:1,2、1,3、2,3
- 排列问题
定义:从给定的一组数(不重复)中,选取出所有可能的 k 个数的排列(顺序不同视为不同结果)。
示例:给定数集 1,2,3,选取 k=2 个数的所有排列:1,2、2,1、1,3、3,1、2,3、3,2
- 子集问题
定义:从给定的一组数中,选取出所有可能的子集(包含空集,元素顺序不影响)。
示例:给定数集 1,2,3,所有可能的子集:\[\]、1、2、3、1,2、1,3、2,3、1,2,3
题目1:全排列(LeetCode 46)
- 题目描述
给定一个不含重复数字的数组 nums ,返回其所有可能的全排列(顺序任意)。
• 示例1:
输入:nums = 1,2,3
输出:\[1,2,3,1,3,2,2,1,3,2,3,1,3,1,2,3,2,1]
• 示例2:
输入:nums = 0,1
输出:\[0,1,1,0]
• 示例3:
输入:nums = 1
输出:\[1]
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
- 算法思路
这是典型的回溯问题,核心逻辑是:在每一个位置上,枚举所有未被使用过的数字,放入当前位置,递归处理下一个位置;当所有位置都处理完成时,记录当前排列;处理完成后撤销选择,枚举其他数字。
- 递归函数设计
void backtrack(vector<vector<int>>& res, vector<int>& nums, vector<bool>& visited, vector<int>& ans, int step, int len)
参数说明:
res:存储所有合法排列的二维数组。
nums:输入的不重复数字数组。
visited:标记数组,记录数字是否已被使用(避免重复)。
ans:存储当前状态下的排列路径。
step:当前需要填入数字的位置(递归深度)。
len:数组 nums 的长度(递归结束条件)。
函数作用:查找所有合法排列,并存储到 res 中。
- 递归执行流程
1) 初始化:定义结果集 res、当前路径 ans、标记数组 visited,从位置 step=0 开始递归。
2) 递归状态维护:用 step 表示当前已处理的数字个数(即路径长度)。
3) 结束条件:当 step == nums.size() 时,说明所有位置已填满,将 ans 存入 res 并返回。
4) 遍历与选择:
对数组的每个下标 i,若 visitedi 为 false(未被使用):
a. 将 visitedi 标记为 true(标记已使用)。
b. 将 numsi 放入 ansstep(做出选择)。
c. 递归调用 backtrack,处理下一个位置 step+1。
d. 回溯:将 visitedi 重置为 false,撤销 ans 中的选择。
5) 返回结果:递归完成后,返回 res。
- C++ 完整代码实现
cpp
class Solution {
public:
vector<vector<int>> ret; // 存储所有排列的结果集
vector<int> path; // 存储当前的排列路径
bool check[7]; // 标记数组,记录数字是否已被使用(nums长度≤6,故大小为7)
vector<vector<int>> permute(vector<int>& nums) {
// 初始化标记数组为false(所有数字未被使用)
memset(check, false, sizeof(check));
dfs(nums);
return ret;
}
void dfs(vector<int>& nums) {
// 递归结束条件:路径长度等于数组长度,说明找到一个完整排列
if (path.size() == nums.size()) {
ret.push_back(path);
return;
}
// 遍历所有数字,尝试未被使用的数字
for (int i = 0; i < nums.size(); i++) {
if (!check[i]) {
// 做出选择:将nums[i]加入路径,标记为已使用
path.push_back(nums[i]);
check[i] = true;
// 递归处理下一个位置
dfs(nums);
// 回溯:撤销选择,恢复现场
path.pop_back();
check[i] = false;
}
}
}
};- 回溯算法核心总结
1)回溯算法的本质是暴力搜索+剪枝优化,通过递归遍历状态树,枚举所有可能的解。
2)核心流程固定:做出选择 → 递归搜索 → 撤销选择,通过路径和标记数组维护状态。
3)典型应用场景:组合、排列、子集、N皇后、数独、单词搜索等问题,核心都是"枚举+剪枝"。
4)优化关键:通过剪枝(如提前排除重复分支、过滤无效路径)降低时间复杂度,避免不必要的搜索。
题目2:子集(LeetCode 78)
- 题目描述
给你一个整数数组 nums,数组中的元素互不相同。返回该数组所有可能的子集(幂集)。
幂集不能包含重复的子集;可以按任意顺序返回解集。
• 示例1:
输入:nums = 1,2,3
输出:\[,1,2,1,2,3,1,3,2,3,1,2,3]
• 示例2:
输入:nums = 0
输出:\[,0]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
- 算法思路
核心逻辑:为了获得 nums 数组的所有子集,需要对每个元素进行"选"或"不选"的操作,因此长度为 n 的数组一定存在 2^n 个子集。
回溯核心思想
定义一个数组记录当前的状态(当前子集),并对其进行递归:
1) 对于每个元素,有两种选择:
不选择当前元素,直接递归处理下一个元素;
选择当前元素,将其添加到当前子集,递归处理下一个元素,递归结束后通过回溯撤销添加操作,恢复现场。
2) 递归结束条件:当处理的元素下标越界(即处理完所有元素)时,将当前状态(子集)记录到结果集中并返回。
- 递归函数设计
void dfs(vector<vector<int>>& res, vector<int>& ans, vector<int>& nums, int step)
参数说明:
res:存储所有子集的结果集;
ans:存储当前递归过程中的子集(路径);
nums:输入的整数数组;
step:当前需要处理的元素下标(递归深度)。
函数作用:递归查找集合的所有子集,并存储到结果集中。
- 两种回溯解法
解法一:"选/不选"分支法(二叉树式回溯)
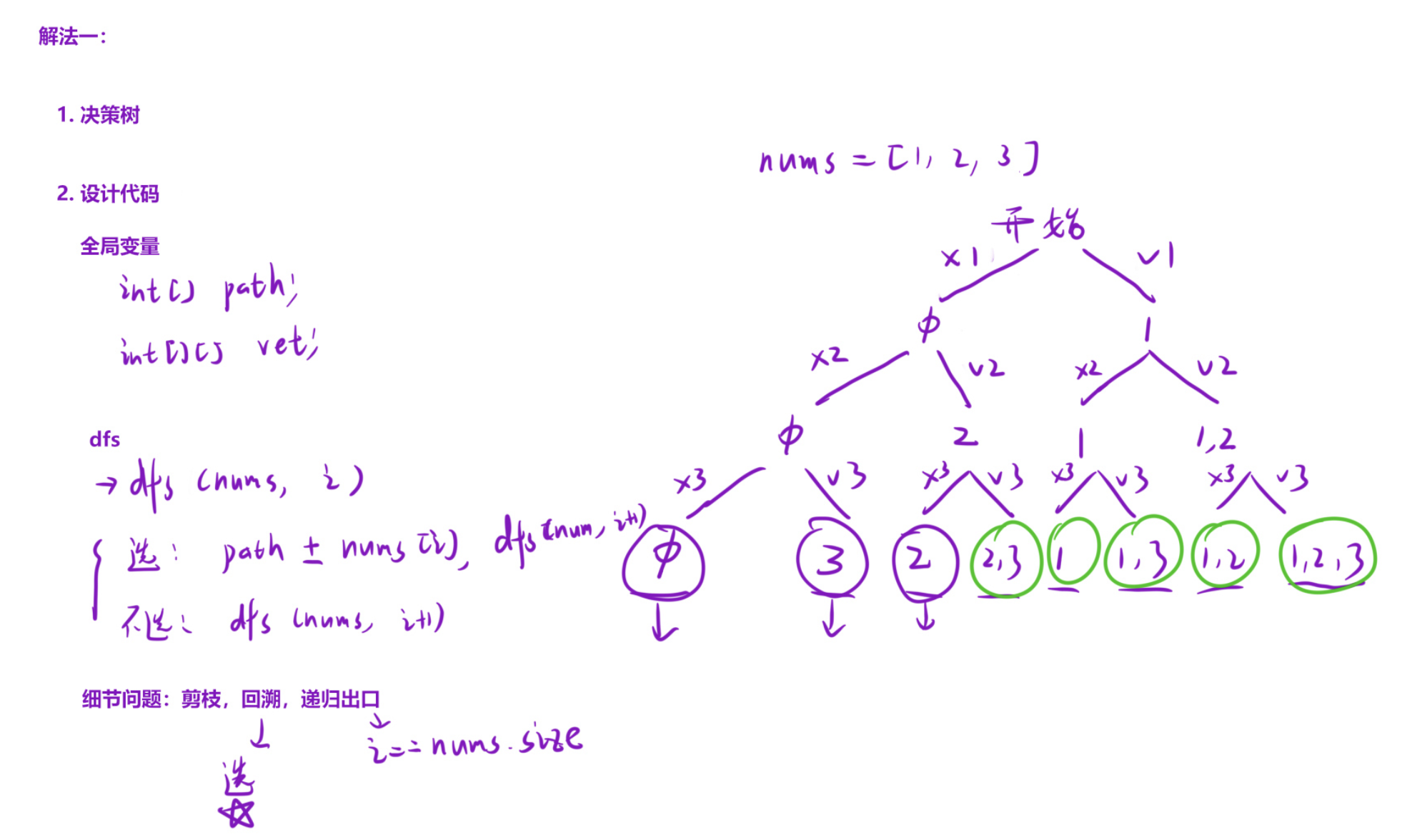
cpp
class Solution {
vector<vector<int>> ret; // 存储所有子集的结果集
vector<int> path; // 存储当前递归过程中的子集(路径)
public:
// 入口函数:接收数组nums,返回所有子集
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0); // 从下标0开始递归
return ret;
}
// 核心回溯函数:step表示当前处理的元素下标
void dfs(vector<int>& nums, int pos) {
// 递归结束条件:下标越界(处理完所有元素)
if (pos == nums.size()) {
ret.push_back(path); // 将当前子集加入结果集
return;
}
// 分支1:选择当前元素nums[pos]
path.push_back(nums[pos]); // 做出选择:将元素加入路径
dfs(nums, pos + 1); // 递归处理下一个元素
path.pop_back(); // 回溯:撤销选择,恢复现场
// 分支2:不选择当前元素nums[pos],直接递归处理下一个元素
dfs(nums, pos + 1);
}
};特点
每个元素对应2个分支,整体结构是一棵满二叉树;
递归深度等于数组长度,时间复杂度 O(2^n),空间复杂度 O(n)(递归栈+路径存储)。
解法二:遍历枚举法(多叉树式回溯)
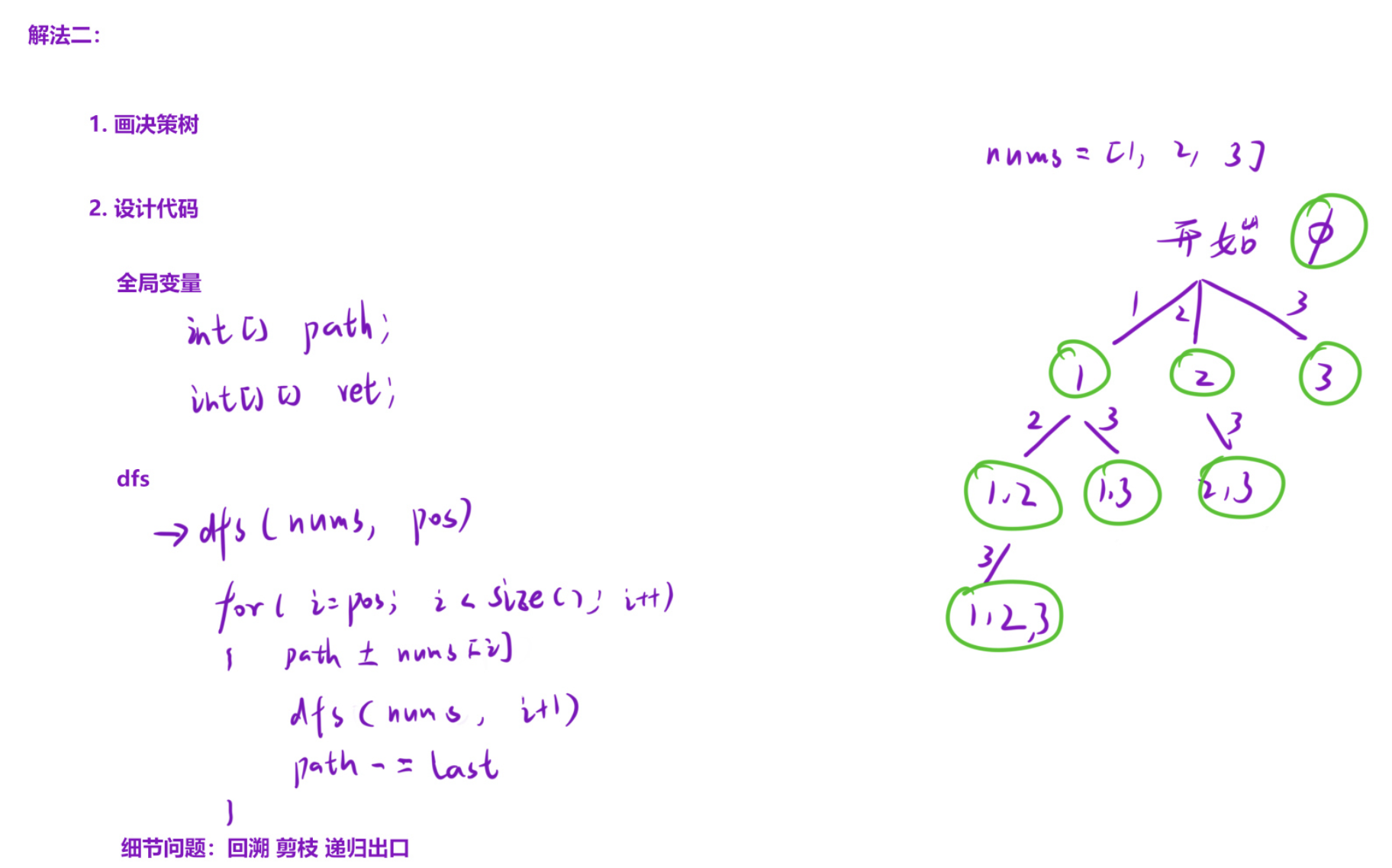
cpp
class Solution {
vector<vector<int>> ret; // 存储所有子集的结果集
vector<int> path; // 存储当前递归过程中的子集(路径)
public:
// 入口函数:接收数组nums,返回所有子集
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0); // 从下标0开始递归
return ret;
}
// 核心回溯函数:pos表示当前处理的起始下标
void dfs(vector<int>& nums, int pos) {
// 每进入一次递归,就将当前路径(子集)加入结果集
ret.push_back(path);
// 从pos开始遍历后续所有元素,尝试加入路径
for (int i = pos; i < nums.size(); i++) {
path.push_back(nums[i]); // 做出选择:将元素加入路径
dfs(nums, i + 1); // 递归处理下一个元素(避免重复)
path.pop_back(); // 回溯:撤销选择,恢复现场
}
}
};特点
每个节点对应一个子集,结构是一棵多叉树;
递归过程中每一步都记录当前路径,无需等到下标越界,逻辑更直观;
时间复杂度 O(2^n),空间复杂度 O(n)。
- 核心知识点总结
1) 子集问题的本质:对每个元素进行"选/不选"的决策,所有决策组合构成幂集,共 2^n 个子集。
2) 回溯的核心流程:做出选择 → 递归处理 → 撤销选择(恢复现场),两种解法都遵循这一流程。
3) 避免重复的关键:
解法一:通过下标递增保证不重复选择同一元素;
解法二:从 pos 开始遍历,避免重复枚举相同组合。
4) 递归结束条件的差异:
解法一:下标越界时记录子集;
解法二:每进入一次递归就记录当前路径,无需等待下标越界。